Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Importante
Ces instructions s’appliquent aux modèles d’accès aux données hérités. Databricks recommande d’utiliser des emplacements externes du catalogue Unity pour l’accès aux données. Consultez Se connecter au stockage d’objets cloud à l’aide du catalogue Unity.
Cet article explique comment gérer les propriétés d’accès aux données pour les entrepôts SQL dans un espace de travail.
Importante
La modification de ces paramètres a pour effet de redémarrer tous les entrepôts SQL en cours d’exécution.
Configurer un principal de service
Pour configurer l’accès de vos entrepôts SQL à un compte de stockage Azure Data Lake Storage à l’aide de principaux de service, procédez comme suit :
Inscrivez une application Microsoft Entra ID (anciennement Azure Active Directory) et enregistrez les propriétés suivantes :
- ID Application (client) : ID qui identifie de manière unique l’application Microsoft Entra ID.
- ID de répertoire (locataire) : ID unique de l’instance Microsoft Entra ID (appelé ID de répertoire (locataire) dans Azure Databricks).
- Clé secrète client : valeur d’une clé secrète client créée pour cette inscription d’application. L’application utilisera cette chaîne secrète pour prouver son identité.
Sur votre compte de stockage, ajoutez une attribution de rôle pour l’application inscrite à l’étape précédente pour lui donner accès au compte de stockage.
Créez une étendue secrète Azure Key Vault ou une étendue de secret d’étendue Databricks, voir Gérer les étendues de secrets, puis enregistrez la valeur de la propriété de nom d’étendue :
- Nom de la portée: nom de la portée secrète créée.
Si vous utilisez Azure Key Vault, créez un secret dans Azure Key Vault, en utilisant le secret Client dans le champ Value. Conservez un enregistrement du nom du secret que vous avez choisi.
- Nom du secret : nom du secret Azure Key Vault créé.
Si vous utilisez une étendue associée à Databricks, créez un secret à l’aide de la CLI Databricks et utilisez-le pour stocker la clé secrète client obtenue à l’étape 1. Conservez un enregistrement de la clé secrète que vous avez entrée à cette étape.
- Clé secrète : clé du secret associé à Databricks créé.
Note
Vous pouvez également créer un secret supplémentaire pour stocker l’ID client obtenu à l’étape 1.
Cliquez sur votre nom d’utilisateur dans la barre supérieure de l’espace de travail, puis sélectionnez Paramètres dans la liste déroulante.
Cliquez sur l'onglet Calculer.
Cliquez sur Gérer à côté d'entrepôts SQL.
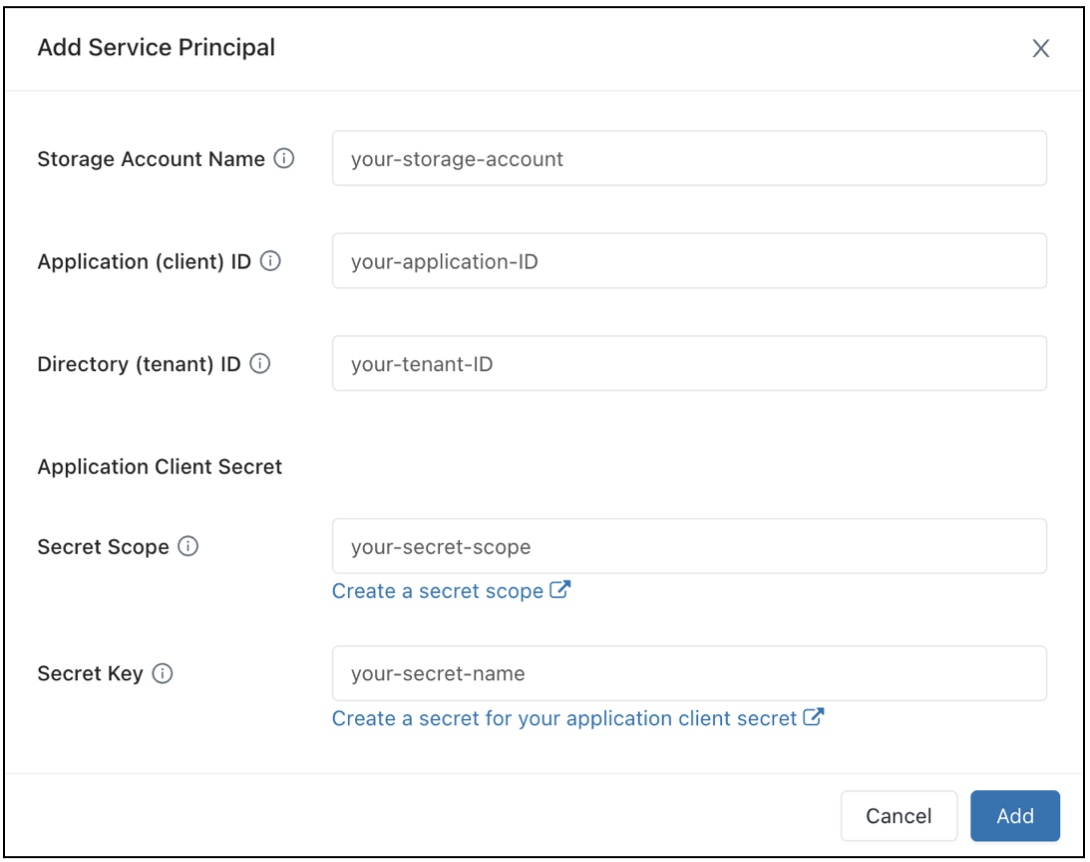
Dans le champ Configuration de l’accès aux données, cliquez sur le bouton Ajouter un principal de service.
Configurez les propriétés de votre compte de stockage Azure Data Lake Storage.
Cliquez sur Add.
Vous verrez que de nouvelles entrées ont été ajoutées à la zone de texte Configuration de l’accès aux données.
Cliquez sur Enregistrer.
Vous pouvez également modifier directement les entrées de la zone de texte Configuration de l’accès aux données.
Configurer les propriétés d’accès aux données pour les entrepôts SQL
Pour configurer tous les entrepôts avec des propriétés d’accès aux données :
Cliquez sur votre nom d’utilisateur dans la barre supérieure de l’espace de travail, puis sélectionnez Paramètres dans la liste déroulante.
Cliquez sur l'onglet Calculer.
Cliquez sur Gérer à côté d'entrepôts SQL.
Dans la zone de texte Configuration de l’accès aux données, spécifiez des paires clé-valeur contenant les propriétés du metastore.
Importante
Pour définir une propriété de configuration Spark sur la valeur d’un secret sans exposer la valeur du secret à Spark, affectez la valeur à
{{secrets/<secret-scope>/<secret-name>}}. Remplacez<secret-scope>par l’étendue du secret et<secret-name>par le nom du secret. La valeur doit commencer par{{secrets/et se terminer par}}. Pour plus d’informations sur cette syntaxe, consultez Gérer les secrets.Cliquez sur Enregistrer.
Vous pouvez également configurer des propriétés d’accès aux données à l’aide du fournisseur Databricks Terraform et databricks_sql_global_config.
Propriétés prises en charge
Pour une entrée qui se termine par
*, toutes les propriétés de ce préfixe sont prises en charge.Par exemple,
spark.sql.hive.metastore.*indique quespark.sql.hive.metastore.jarsetspark.sql.hive.metastore.versionsont pris en charge, ainsi que toutes les autres propriétés commençant parspark.sql.hive.metastore.Pour les propriétés dont les valeurs contiennent des informations sensibles, vous pouvez stocker les informations sensibles dans un secret et définir la valeur de la propriété sur le nom du secret à l’aide de la syntaxe suivante :
secrets/<secret-scope>/<secret-name>
Les propriétés suivantes sont prises en charge pour les entrepôts SQL :
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
Pour plus d’informations sur la façon de définir ces propriétés, consultez Metastore Hive externe.