Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les administrateurs d’espace de travail et les utilisateurs suffisamment privilégiés peuvent configurer et gérer des entrepôts SQL. Cet article explique comment créer, modifier et superviser les entrepôts SQL existants.
Vous pouvez également créer des entrepôts SQL à l’aide de l’API d’entrepôt SQL ou de Terraform.
Databricks recommande d’utiliser des entrepôts SQL serverless, le cas échéant.
Remarque
La plupart des utilisateurs ne peuvent pas créer d’entrepôts SQL, mais peuvent redémarrer tout entrepôt SQL auquel ils peuvent se connecter. Consultez Se connecter à un entrepôt SQL.
Exigences
Les entrepôts SQL ont les exigences suivantes :
- Pour créer un entrepôt SQL, vous devez être un administrateur d’espace de travail ou un utilisateur disposant d’autorisations de création de cluster illimitées.
- Avant que vous puissiez créer un entrepôt SQL serverless dans une région qui prend en charge la fonctionnalité, des étapes peuvent être nécessaires. Consultez Configurer des entrepôts SQL serverless.
- Pour les entrepôts SQL classiques ou professionnels, votre compte Azure doit disposer d’un quota de processeurs virtuels adéquat. Le quota de processeurs virtuels par défaut est généralement adéquat pour créer un entrepôt SQL serverless, mais peut ne pas être suffisant pour mettre à l’échelle l’entrepôt SQL ou créer des entrepôts supplémentaires. Consultez Quota de processeurs virtuels Azure requis pour les entrepôts SQL classiques et professionnels. Vous pouvez demander un quota de processeurs virtuels supplémentaires. Votre compte Azure peut avoir des limitations sur le quota de processeurs virtuels que vous pouvez demander. Contactez votre équipe de compte Azure pour en savoir plus.
Créer un entrepôt SQL
Pour créer un entrepôt SQL à l’aide de l’IU web, procédez comme suit :
- Cliquez sur Entrepôts SQL dans la barre latérale.
- Cliquez sur Créer un entrepôt SQL.
- Saisissez un Nom pour l’entrepôt.
- (Facultatif) Configurez les paramètres d’entrepôt. Consultez Configurer les paramètres d’entrepôt SQL.
- (Facultatif) Configurez les options avancées. Consultez Options avancées.
- Cliquez sur Créer.
- (Facultatif) Configurez l’accès à l’entrepôt SQL. Consultez Gérer un entrepôt SQL.
L’entrepôt que vous avez créé démarre automatiquement.
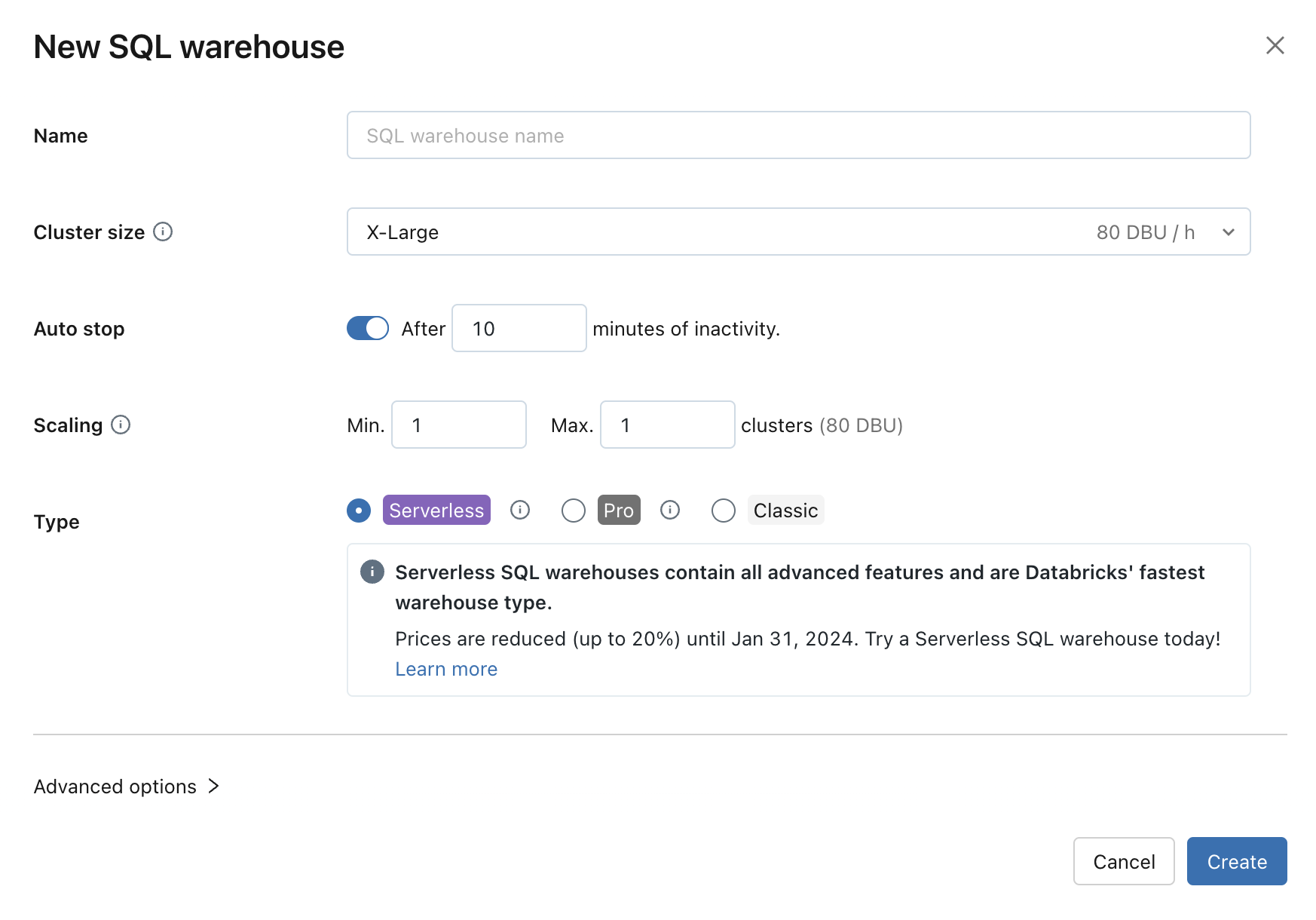
Configurer les paramètres d’entrepôt SQL
Vous pouvez modifier les paramètres suivants lors de la création ou de la modification d’un entrepôt SQL :
Taille du cluster représente la taille du nœud de pilote et le nombre de nœuds Worker associés au cluster. La valeur par défaut est X-Large. Pour réduire la latence des requêtes, augmentez la taille.
L’arrêt automatique détermine si l’entrepôt s’arrête s’il est inactif pendant le nombre de minutes spécifié. Les entrepôts SQL inactifs continuent à accumuler les frais liés aux DBU et à l’instance cloud jusqu’à ce qu’ils soient arrêtés.
- Entrepôts SQL professionnels et classiques : la valeur par défaut est 45 minutes, ce qui est recommandé pour une utilisation standard. La valeur minimale est 10 minutes.
- Entrepôts SQL serverless : la valeur par défaut est 10 minutes, ce qui est recommandé pour une utilisation standard. La valeur minimale est 5 minutes lorsque vous utilisez l’IU. Notez que vous pouvez créer un entrepôt SQL serverless à l’aide de l’API SQL Warehouses, auquel cas vous pouvez définir la valeur d’arrêt automatique aussi faible que 1 minute.
Mise à l’échelle définit le nombre minimal et maximal de clusters utilisés pour une requête. La valeur par défaut est d’un cluster au minimum et au maximum. Vous pouvez augmenter le nombre maximal de clusters si vous souhaitez gérer davantage d’utilisateurs simultanés pour une requête donnée. Azure Databricks recommande un cluster pour toutes les 10 requêtes simultanées.
Pour maintenir des performances optimales, Azure Databricks recycle régulièrement les clusters qui s’exécutent depuis plus de 24 heures. Pendant le recyclage, Azure Databricks affiche un nouveau cluster et commence à y passer de nouvelles requêtes tout en désaffectant l’ancien cluster. Les requêtes existantes continuent à s’exécuter sur l’ancien cluster jusqu’à ce qu’elles soient terminées.
Pendant cette période de transition, vous pouvez voir temporairement un nombre de clusters qui dépasse le nombre maximal configuré. Par exemple, si votre nombre maximal de clusters est défini sur 1, vous pouvez voir 2 clusters actifs pendant le recyclage. Azure Databricks attend que toutes les requêtes sur l’ancien cluster se terminent avant de la terminer.
Importante
Si l’ancien cluster ne peut pas être arrêté dans les 4 heures en raison de requêtes longues, Azure Databricks met fin de manière forcée au cluster pour terminer le processus de recyclage. Concevez des charges de travail longues pour qu’elles se terminent dans cette fenêtre ou les décomposent en requêtes plus petites.
Type détermine le type d’entrepôt. Si l’option serverless est activée dans votre compte, serverless est la valeur par défaut. Consultez les types SQL Warehouse pour la liste.
Options avancées
Configurez les options avancées suivantes en développant la zone Options avancées lorsque vous créez un entrepôt SQL ou modifiez un entrepôt SQL existant. Vous pouvez également configurer ces options à l’aide de l’API d’entrepôt SQL.
Balises : les balises vous permettent de superviser facilement le coût des ressources cloud utilisées par des utilisateurs et des groupes de votre organisation. Vous spécifiez les balises sous forme de paires clé-valeur.
Catalogue Unity : si le catalogue Unity est activé pour l’espace de travail, il s’agit de la valeur par défaut pour tous les nouveaux entrepôts de l’espace de travail. Si le catalogue Unity n’est pas activé pour votre espace de travail, vous ne voyez pas cette option. Consultez Qu’est-ce que Unity Catalog ?.
Canal : le canal Préversion vous permet de tester une nouvelle fonctionnalité, y compris vos requêtes et tableaux de bord, avant qu’elle ne devienne la norme Databricks SQL.
Les notes de publication répertorient ce qui se trouve dans la dernière préversion.
Importante
Databricks déconseille d’utiliser une préversion pour les charges de travail de production. Étant donné que seuls les administrateurs d’espace de travail peuvent afficher les propriétés d’un entrepôt, y compris son canal, pensez à indiquer qu’un entrepôt Sql Databricks utilise une préversion dans le nom de cet entrepôt pour empêcher les utilisateurs de l’utiliser pour les charges de travail de production.
Azure Databricks prend également en charge les délais d’expiration des instructions par entrepôt que vous pouvez définir avec l’API SQL Warehouses. Cette option est API uniquement.
Importante
Les délais d’expiration des instructions au niveau de l’entrepôt sont en version bêta. Un administrateur d’espace de travail doit activer l’aperçu Warehouse Statement Timeout depuis la page Previews. Consultez Gérer les préversions d’Azure Databricks.
Pour plus d’informations, consultez le délai d’expiration au niveau de l’entrepôt.
Définir un entrepôt par défaut au niveau de l’utilisateur
Vous pouvez définir un entrepôt SQL par défaut à utiliser automatiquement lors de l’exécution de requêtes. Ce paramètre remplace l’entrepôt par défaut au niveau de l’espace de travail, s’il en existe un. Consultez Définir un entrepôt SQL par défaut pour l’espace de travail.
Utilisez le menu déroulant pour définir une nouvelle valeur par défaut à partir de n’importe quelle surface de création Sql Databricks, y compris l’éditeur SQL, les tableaux de bord IA/BI, Genie, Alertes et l’Explorateur catalogue.
Pour définir un entrepôt par défaut au niveau de l’utilisateur :
Cliquez sur le menu déroulant pour sélectionner le calcul SQL Warehouse.
Cliquez sur Personnaliser votre entrepôt par défaut.
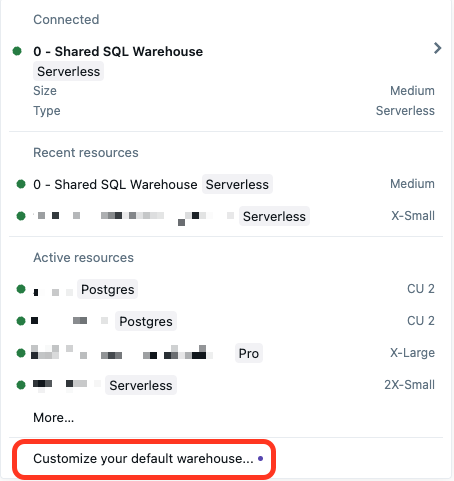
Choisissez une des options suivantes :
- Espace de travail par défaut : Conservez ce paramètre pour utiliser l’ensemble d’entrepôts par défaut pour l’espace de travail.
- Dernière sélection : la sélection par défaut affiche le dernier entrepôt que vous avez sélectionné comme ressource de calcul.
- Valeur par défaut personnalisée : Choisissez un nouvel entrepôt SQL comme entrepôt par défaut. Cela remplace un paramètre par défaut au niveau de l’espace de travail. Après la configuration, l’entrepôt sélectionné est automatiquement utilisé comme ressource de calcul. Vous pouvez remplacer manuellement ce paramètre en choisissant un autre entrepôt SQL dans le menu déroulant.
Gérer un entrepôt SQL
Les administrateurs d’espace de travail et les utilisateurs disposant de privilèges CAN MANAGE sur un entrepôt SQL peuvent effectuer les tâches suivantes sur un entrepôt SQL existant :
Pour arrêter un entrepôt en cours d’exécution, cliquez sur l’icône d’arrêt en regard de l’entrepôt.
Pour démarrer un entrepôt arrêté, cliquez sur l’icône de démarrage en regard de l’entrepôt.
Pour modifier un entrepôt, cliquez sur l'icône de
 , puis cliquez sur Modifier.
, puis cliquez sur Modifier.Pour ajouter et modifier des autorisations, cliquez sur l'icône de menu Kebab
, puis cliquez sur Autorisations.- Affecter peut afficher pour permettre aux utilisateurs d’afficher les entrepôts SQL, y compris l’historique des requêtes et les profils de requête. Ces utilisateurs ne peuvent pas exécuter de requêtes sur l’entrepôt.
- Affectez Peut utiliser aux utilisateurs devant exécuter des requêtes sur l’entrepôt.
- Affectez Peut superviser aux utilisateurs avancés pour résoudre des problèmes et optimiser les performances des requêtes. Peut surveiller l’autorisation permet aux utilisateurs d’exécuter des requêtes et de surveiller des entrepôts SQL, notamment l’historique des requêtes et les profils de requête.
- Affectez Peut gérer aux utilisateurs chargés du dimensionnement d’entrepôts SQL et des décisions en matière de limites de dépenses.
- Le statut de propriétaire s’applique automatiquement au créateur de l’entrepôt SQL.
Pour en savoir plus sur les niveaux d’autorisation, consultez Listes de contrôle d’accès aux entrepôts SQL.
Pour mettre à niveau un entrepôt SQL vers sans serveur, cliquez sur
puis cliquez sur Mettre à niveau vers Serverless.Pour supprimer un entrepôt, cliquez sur l’icône de
, puis cliquez sur Supprimer.
Remarque
Contactez votre représentant Databricks pour restaurer les entrepôts supprimés dans les 14 jours.