Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment lire et écrire dans des tables Google BigQuery dans Azure Databricks.
Important
La documentation de fédération de requête héritée a été supprimée et peut ne pas être mise à jour. Les configurations mentionnées dans ce contenu ne sont pas officiellement approuvées ou testées par Databricks. Si Lakehouse Federation prend en charge votre base de données source, Databricks recommande d’utiliser cela à la place.
Vous devez vous connecter à BigQuery à l’aide de l’authentification basée sur des clés.
Autorisations
Vos projets doivent disposer d’autorisations Google spécifiques pour lire et écrire à l’aide de BigQuery.
Remarque
Cet article parle des vues matérialisées BigQuery. Pour plus d’informations, consultez l’article Google Présentation des vues matérialisées. Pour découvrir d’autres terminologies BigQuery et le modèle de sécurité BigQuery, consultez la documentation de Google BigQuery.
La lecture et l’écriture de données avec BigQuery dépendent de deux projets Google Cloud :
- Projet (
project) : ID du projet Google Cloud à partir duquel Azure Databricks lit ou écrit la table BigQuery. - Projet parent (
parentProject) : ID du projet parent, qui est l’ID de projet Google Cloud à facturer pour la lecture et l’écriture. Définissez-le sur le projet Google Cloud associé au compte de service Google pour lequel vous allez générer des clés.
Vous devez fournir explicitement les valeurs project et parentProject dans le code qui accède à BigQuery. Utilisez du code similaire à ce qui suit :
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Les autorisations requises pour les projets Google Cloud dépendent de si project et parentProject sont identiques. Les sections suivantes répertorient les autorisations requises pour chaque scénario.
Autorisations requises si project et parentProject correspondent
Si les ID de project et parentProject sont identiques, utilisez le tableau suivant pour déterminer les autorisations minimales.
| Tâche Azure Databricks | Autorisations Google requises dans le projet |
|---|---|
| Lire une table BigQuery sans vue matérialisée | Dans le project projet :
|
| Lire une table BigQuery avec une vue matérialisée | Dans le project projet :
Dans le projet de matérialisation :
|
| Écrire une table BigQuery | Dans le project projet :
|
Autorisations requises si project et parentProject sont différentes
Si les identifiants de votre project et de votre parentProject sont différents, utilisez le tableau suivant pour déterminer les autorisations minimales :
| Tâche Azure Databricks | Autorisations Google requises |
|---|---|
| Lire une table BigQuery sans vue matérialisée | Dans le parentProject projet :
Dans le project projet :
|
| Lire une table BigQuery avec une vue matérialisée | Dans le parentProject projet :
Dans le project projet :
Dans le projet de matérialisation :
|
| Écrire une table BigQuery | Dans le parentProject projet :
Dans le project projet :
|
Étape 1 : Configurer Google Cloud
Activer l’API Stockage BigQuery
L’API Stockage BigQuery est activée par défaut dans les nouveaux projets Google Cloud dans lesquels BigQuery est activé. Toutefois, si vous avez un projet existant et que l’API Stockage BigQuery n’est pas activée, suivez les étapes décrites dans cette section pour l’activer.
Vous pouvez activer l’API Stockage BigQuery à l’aide de l’interface CLI Google Cloud ou de la console Google Cloud.
Activer l’API Stockage BigQuery à l’aide de Google Cloud CLI
gcloud services enable bigquerystorage.googleapis.com
Activer l’API Stockage BigQuery à l’aide de Google Cloud Console
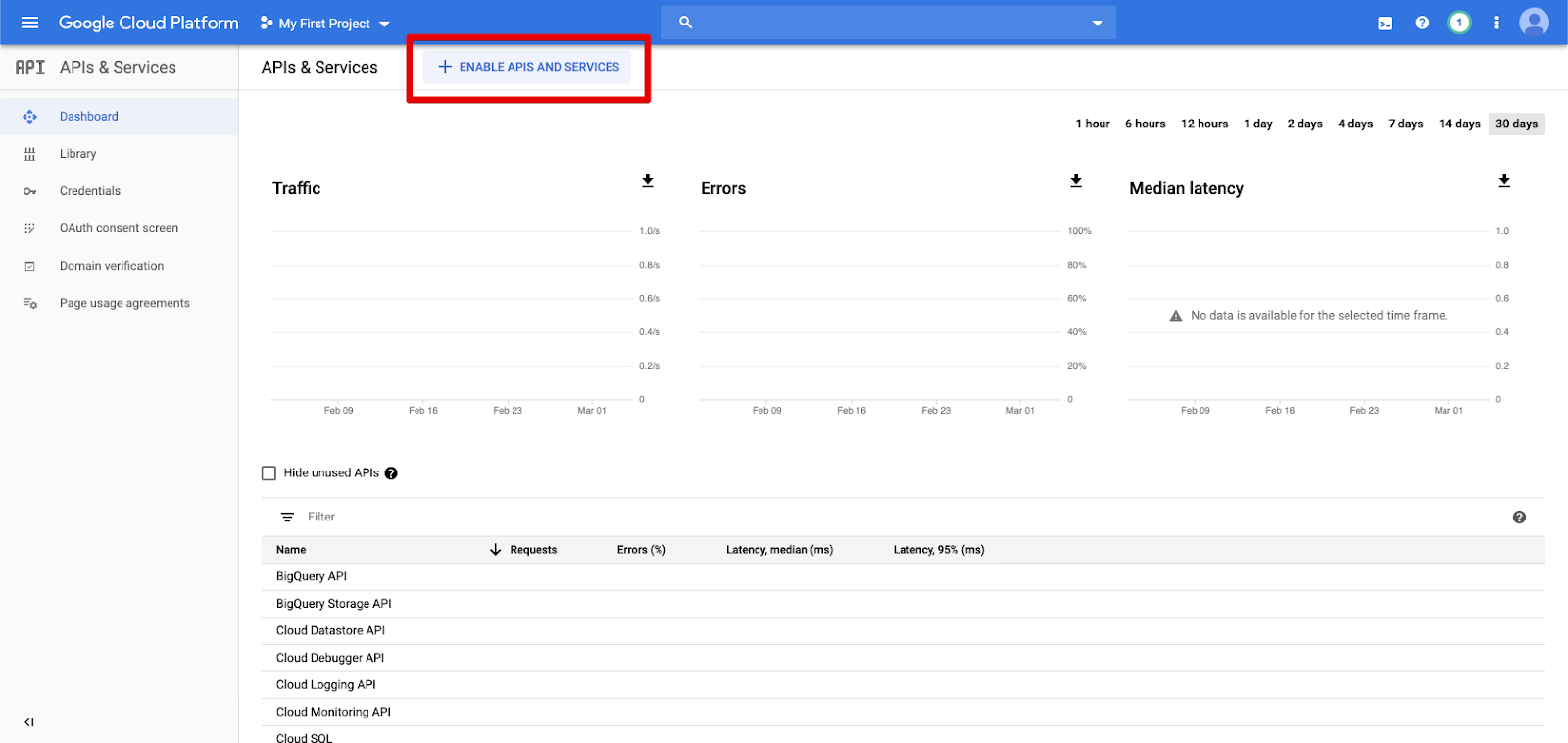
Cliquez sur API &Services dans le volet de navigation gauche.
Cliquez sur le bouton ACTIVER LES API ET SERVICES .
Tapez
bigquery storage apidans la barre de recherche et sélectionnez le premier résultat.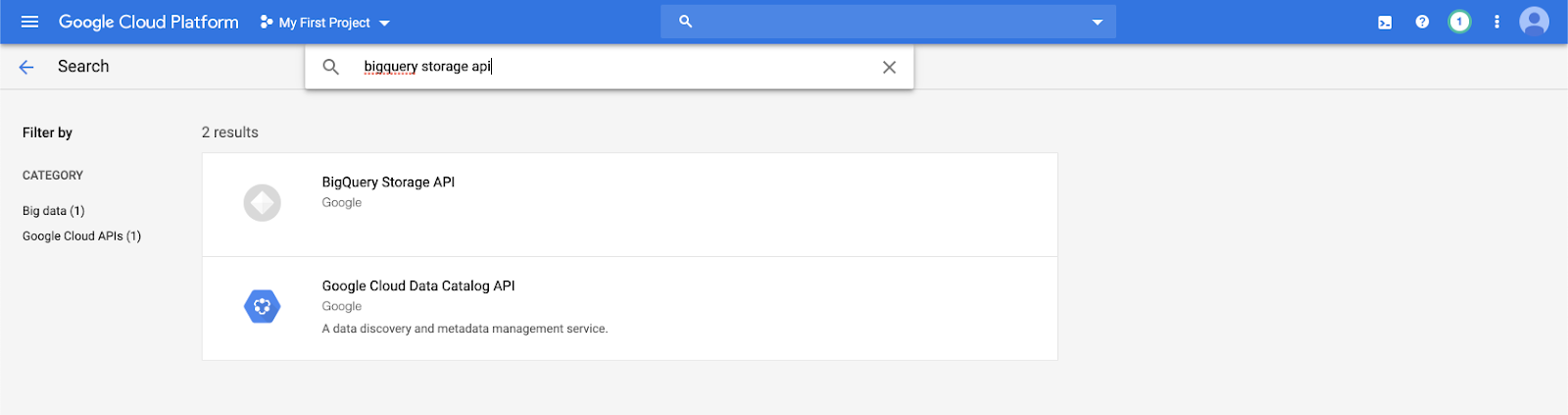
Vérifiez que l’API Stockage BigQuery est activée.
Créer un compte de service Google pour Azure Databricks
Créez un compte de service pour le cluster Azure Databricks. Databricks recommande de donner à ce compte de service les privilèges minimum nécessaires pour effectuer ses tâches. Consultez rôles et autorisations BigQuery.
Vous pouvez créer un compte de service à l’aide de l’interface CLI Google Cloud ou de la console Google Cloud.
Créer un compte de service Google à l’aide de Google Cloud CLI
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Créez les clés de votre compte de service :
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Créer un compte de service Google à l’aide de Google Cloud Console
Pour créer le compte :
Cliquez sur IAM et Administrateur dans le volet de navigation gauche.
Cliquez sur Comptes de service.
Cliquez sur + CRÉER UN COMPTE DE SERVICE.
Entrez le nom et la description du compte de service.
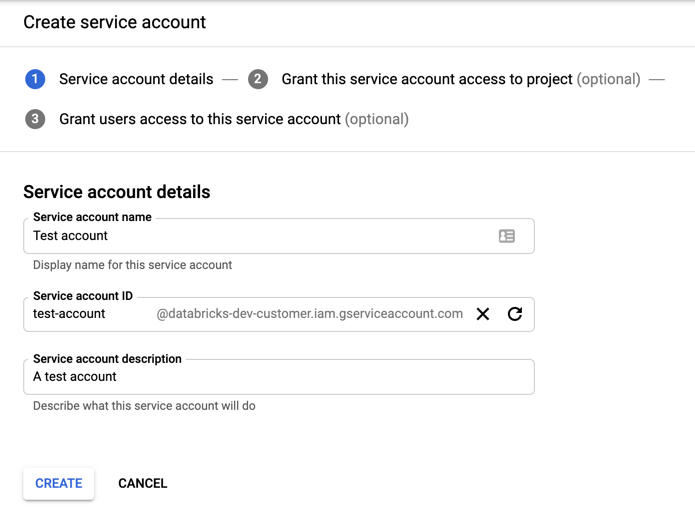
Cliquez sur CREATE (Créer).
Spécifiez des rôles pour votre compte de service. Dans la liste déroulante Sélectionner un rôle , tapez
BigQueryet ajoutez les rôles suivants :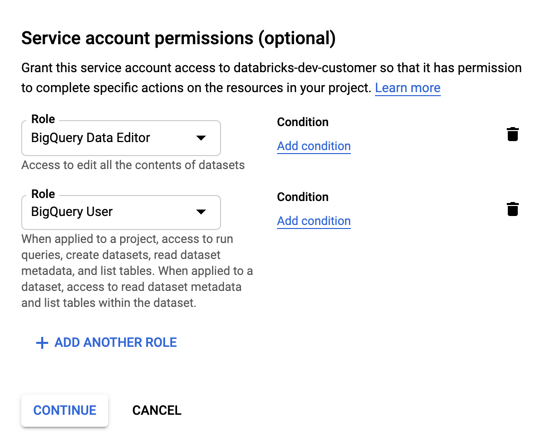
Cliquez sur CONTINUE (Continuer).
Cliquez sur TERMINÉ.
Pour créer des clés pour votre compte de service :
Dans la liste des comptes de service, cliquez sur votre compte nouvellement créé.
Dans la section Clés, sélectionnez BOUTON AJOUTER UNE > CLÉ Créer une clé .
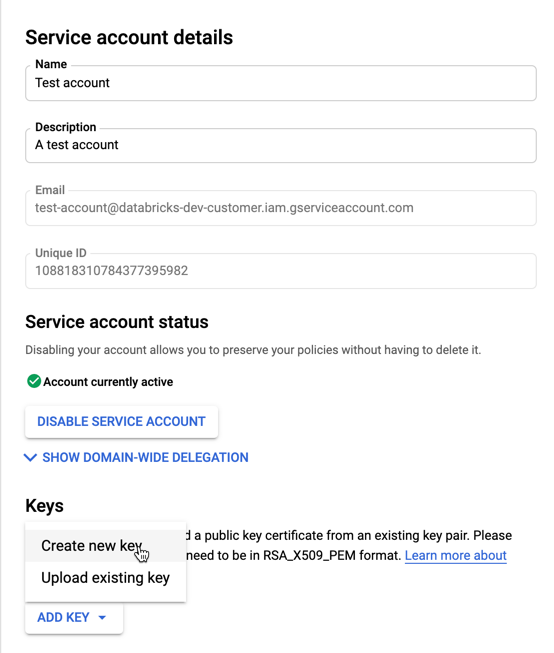
Acceptez le type de clé JSON .
Cliquez sur CREATE (Créer). Le fichier de clé JSON est téléchargé sur votre ordinateur.
Important
Le fichier de clé JSON que vous générez pour le compte de service est une clé privée qui doit être partagée uniquement avec les utilisateurs autorisés, car elle contrôle l’accès aux jeux de données et aux ressources de votre compte Google Cloud.
Créer un compartiment Google Cloud Storage (GCS) pour le stockage temporaire
Pour écrire des données dans BigQuery, la source de données doit accéder à un compartiment GCS.
Cliquez sur Stockage dans le volet de navigation gauche.
Cliquez sur CREATE BUCKET.
Configurez les détails du compartiment.
Cliquez sur CREATE (Créer).
Cliquez sur l’onglet Autorisations et ajoutez des membres.
Fournissez les autorisations suivantes au compte de service sur le compartiment.
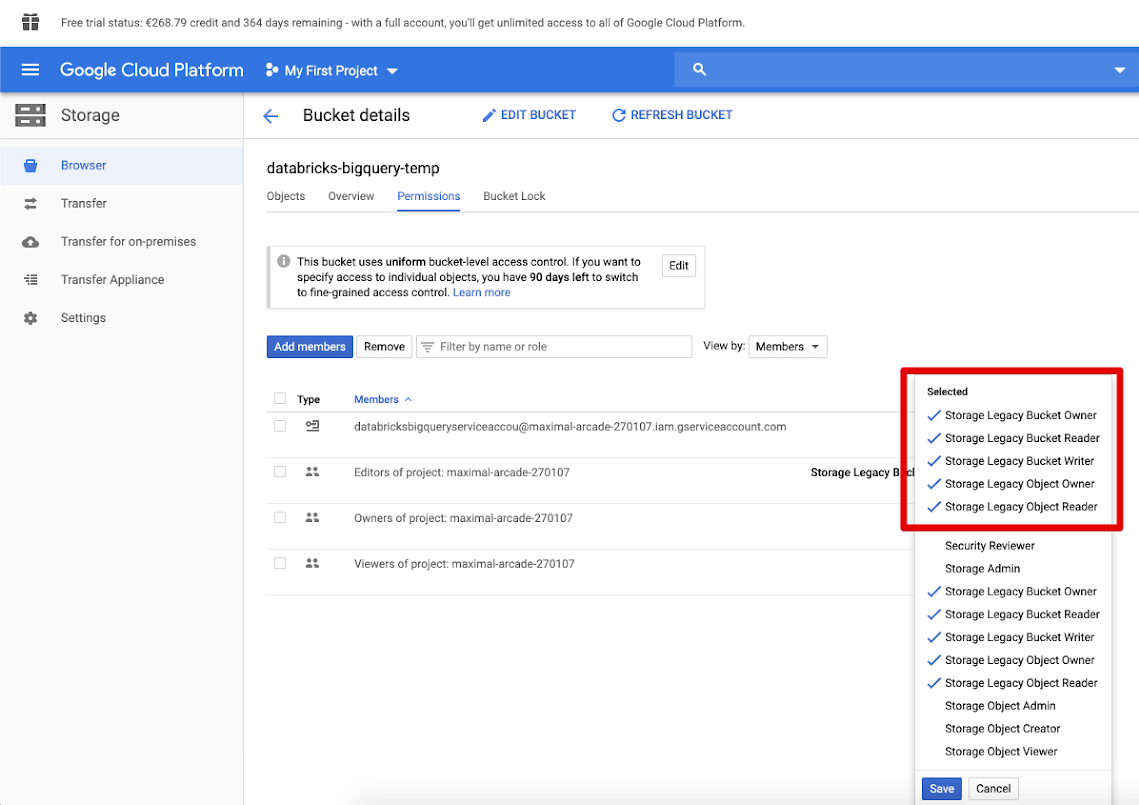
Cliquez sur Enregistrer.
Étape 2 : Configurer Azure Databricks
Pour configurer un cluster pour accéder aux tables BigQuery, vous devez fournir votre fichier de clé JSON en tant que configuration Spark. Utilisez un outil local pour encoder votre fichier de clé JSON en Base64. À des fins de sécurité, n’utilisez pas d’outil web ou distant qui pourrait accéder à vos clés.
Lorsque vous configurez votre cluster :
Dans l’onglet Configuration Spark , ajoutez la configuration Spark suivante. Remplacez <base64-keys> par la chaîne de votre fichier de clé JSON codée en Base64. Remplacez les autres éléments entre crochets (par exemple <client-email>) par les valeurs de ces champs à partir de votre fichier de clé JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Lire et écrire dans une table BigQuery
Pour lire une table BigQuery, spécifiez
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Pour écrire dans une table BigQuery, spécifiez
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
où <bucket-name> est le nom du compartiment que vous avez créé dans Créer un compartiment Google Cloud Storage (GCS) pour le stockage temporaire. Consultez Autorisations pour en savoir plus sur les exigences relatives aux valeurs de <project-id> et de <parent-id>.
Créer une table externe à partir de BigQuery
Important
Cette fonctionnalité n’est pas prise en charge par le catalogue Unity.
Vous pouvez déclarer une table non managée dans Databricks qui lit les données directement à partir de BigQuery :
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Exemple de notebook Python : Charger une table Google BigQuery dans un DataFrame
Le notebook Python suivant charge une table Google BigQuery dans un DataFrame d'Azure Databricks.
Exemple de notebook Python Google BigQuery
Obtenir un ordinateur portable
Exemple de notebook Scala : Charger une table de Google BigQuery dans un DataFrame
Le notebook Scala suivant charge une table Google BigQuery dans un DataFrame Azure Databricks.