Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Remarque
L’organisation de cet article suppose que vous utilisez l’interface utilisateur de calcul de formulaire simple. Pour obtenir une vue d’ensemble des mises à jour de formulaire simples, consultez Utiliser le formulaire simple pour gérer le calcul.
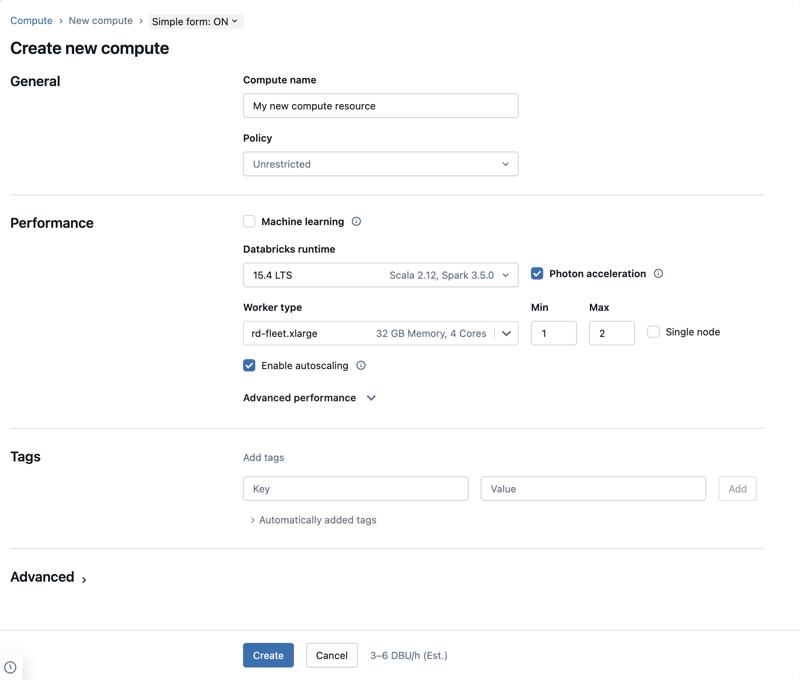
Cet article explique les paramètres de configuration disponibles lors de la création d’une ressource de calcul à usage unique ou de travail. La plupart des utilisateurs créent des ressources de calcul à l’aide de leurs stratégies attribuées, ce qui limite les paramètres pouvant être configurés. Si vous ne voyez pas de paramètre particulier dans votre interface utilisateur, c’est parce que la stratégie que vous avez sélectionnée ne vous permet pas de configurer ce paramètre.
Pour obtenir des recommandations sur la configuration du calcul pour votre charge de travail, consultez les recommandations de configuration de calcul.
Les configurations et outils de gestion décrits dans cet article s’appliquent aussi bien au calcul à usage général qu’au calcul de travaux. Pour plus d’informations sur la configuration du calcul des travaux, consultez Configurer le calcul pour les travaux.
Créer une ressource de calcul à usage général
Pour créer une ressource de calcul à usage général :
- Dans la barre latérale de l’espace de travail, cliquez sur Calcul.
- Cliquez sur le bouton Créer un calcul .
- Configurez la ressource de calcul.
- Cliquez sur Créer.
La nouvelle ressource de calcul démarre automatiquement et est prête à être utilisée après quelques instants.
Stratégie de calcul
Les stratégies sont un ensemble de règles qui permettent de limiter les options de configuration à disposition des utilisateurs lorsqu’ils créent une ressource de calcul. Si un utilisateur n’a pas le droit de création de cluster illimité , il peut uniquement créer des ressources de calcul à l’aide de ses stratégies accordées.
Pour créer des ressources de calcul en fonction d’une stratégie, sélectionnez une stratégie dans le menu déroulant Stratégie .
Par défaut, tous les utilisateurs ont accès à la stratégie de calcul personnel , ce qui leur permet de créer des ressources de calcul à ordinateur unique. Si vous avez besoin d’accéder à Personal Compute ou à des stratégies supplémentaires, contactez l’administrateur de votre espace de travail.
Paramètres de performances
Les paramètres suivants s’affichent sous la section Performances de l’interface utilisateur de calcul de formulaire simple :
- Versions de Databricks Runtime
- Utiliser l’accélération photon
- Type de nœud de travail
- Calcul à nœud unique
- Activer la mise à l’échelle automatique
- Paramètres de performances avancés
Versions de Databricks Runtime
Databricks Runtime constitue l’ensemble des composants de base qui s’exécutent sur votre calcul. Sélectionnez le runtime à l’aide du menu déroulant Version Databricks Runtime. Pour plus d’informations sur les versions spécifiques de Databricks Runtime, consultez les versions des notes de publication et la compatibilité de Databricks Runtime. Toutes les versions incluent Apache Spark. Databricks recommande les éléments suivants :
- Pour les calculs à usage général, l’utilisation de la version la plus récente vous permet de bénéficier des dernières optimisations et de la compatibilité la plus à jour entre votre code et les packages préchargés.
- Pour un calcul de tâches permettant d'exécuter des charges de travail opérationnelles, envisagez d’utiliser la version Long Term Support (LTS) de Databricks Runtime. L’utilisation de la version LTS garantit que vous ne rencontrez pas de problèmes de compatibilité et que vous pouvez tester soigneusement votre charge de travail avant la mise à niveau.
- Pour les cas d’usage dans les domaines de la science des données et du Machine Learning, considérez la version ML de Databricks Runtime.
Utiliser l’accélération Photon
Photon est activé par défaut sur les calculs exécutant Databricks Runtime 9.1 LTS et versions ultérieures.
Pour activer ou désactiver l’accélération photon, cochez la case Utiliser l’accélération photon . Pour en savoir plus sur Photon, voir Qu’est-ce que Photon ?.
Type de nœud Worker
Une ressource de calcul se compose d'un nœud maître et d'aucun ou plusieurs nœuds travailleurs. Vous pouvez choisir des types d’instances de fournisseur de Cloud distincts pour les nœuds de pilote et de travail, bien que le nœud de pilote utilise par défaut le même type d’instance que le nœud Worker. Le paramètre de nœud de pilote se trouve sous la section Performances avancées .
Différentes familles de types d'instances correspondent à différents cas d'utilisation, tels que les charges de travail à forte intensité de mémoire ou de calcul. Vous pouvez également sélectionner un pool à utiliser comme nœud de travail ou nœud driver.
Important
N’utilisez pas un pool avec des instances spot comme type de pilote. Sélectionnez un type de pilote à la demande pour empêcher que votre pilote ne soit récupéré. Consultez Se connecter aux pools.
Dans un calcul multinœud, les nœuds Worker exécutent les exécuteurs Spark et d’autres services requis pour le bon fonctionnement de la ressource de calcul. Lorsque vous distribuez votre charge de travail avec Spark, tout le traitement distribué se produit sur les nœuds Worker. Azure Databricks exécute un exécuteur par nœud Worker. Par conséquent, les termes exécuteur et Worker sont utilisés de manière interchangeable dans le contexte de l’architecture Azure Databricks.
Conseil
Pour exécuter un travail Spark, vous avez besoin d’au moins un nœud Worker. Si la ressource de calcul ne possède aucun Worker, vous pouvez exécuter des commandes non-Spark sur le nœud de pilote, mais les commandes Spark échouent.
Types de nœuds flexibles
Si le type de nœuds flexibles est activé dans votre espace de travail, vous pouvez utiliser des types de nœuds flexibles pour votre ressource informatique. Les types de nœuds flexibles permettent à votre ressource de calcul de revenir à d’autres types d’instances compatibles lorsque votre type d’instance spécifié n’est pas disponible. Ce comportement améliore la fiabilité du lancement de calcul en réduisant les défaillances de capacité pendant les lancements de calcul. Consultez Améliorer la fiabilité du lancement de calcul à l’aide de types de nœuds flexibles.
Adresses IP du nœud Worker
Azure Databricks lance des nœuds Worker avec deux adresses IP privées chacune. L'adresse IP privée principale du nœud héberge le trafic interne d'Azure Databricks. L’adresse IP privée secondaire est utilisée par le conteneur Spark pour la communication intra-cluster. Ce modèle permet Azure Databricks fournir une isolation entre plusieurs ressources de calcul dans le même espace de travail.
Types d’instances GPU
Pour les tâches nécessitant des performances élevées, telles que celles associées au Deep Learning, Azure Databricks prend en charge les ressources de calcul accélérées avec les unités de traitement graphique (GPU). Pour plus d’informations, consultez le calcul avec GPU.
machines virtuelles d’informatique confidentielle Azure
Les types de machines virtuelles confidentielles Azure empêchent l'accès non autorisé aux données lorsqu'elles sont utilisées, y compris à partir de l'opérateur du cloud. Ce type de machine virtuelle est bénéfique pour les secteurs et les régions hautement réglementés, ainsi que pour les entreprises disposant de données sensibles dans le cloud. Pour plus d'informations sur l'informatique confidentielle de Azure, consultez Azure l'informatique confidentielle.
Pour exécuter vos charges de travail à l'aide des machines virtuelles Azure d'informatique confidentielle, sélectionnez les types de machines virtuelles de la série DC ou EC dans les listes déroulantes des nœuds de travail et de pilote. Consultez options de machines virtuelles confidentielles Azure.
calcul à nœud unique
La case à cocher Nœud unique vous permet de créer une ressource de calcul à nœud unique.
Le calcul mononœud est destiné aux travaux qui utilisent de petites quantités de données ou des charges de travail non distribuées, telles que les bibliothèques de Machine Learning mononœuds. Le calcul multinœud doit être utilisé pour les travaux plus importants avec des charges de travail distribuées.
Propriétés du nœud unique
Une ressource de calcul mononœud a les propriétés suivantes :
- Il exécute Spark localement.
- Le pilote agit à la fois comme maître et comme Worker, sans nœuds Worker.
- Il génère un thread d’exécuteur par cœur logique dans la ressource de calcul, moins un cœur pour le pilote.
- Enregistre toutes les sorties des journaux
stderr,stdoutetlog4jdans le journal du pilote. - Impossible de convertir en ressource de calcul à plusieurs nœuds.
Choisir entre nœud unique et nœuds multiples
Pour choisir entre un calcul à nœud unique et à plusieurs nœuds, tenez compte de votre cas d’utilisation :
Le traitement de données à grande échelle épuise les ressources sur une ressource de calcul à nœud unique. Pour ces charges de travail, Databricks recommande d’utiliser un calcul multinœud.
Une ressource de calcul à plusieurs nœuds ne peut pas être ramenée à 0 travailleurs. Utilisez plutôt un calcul à nœud unique.
La planification GPU n’est pas activée sur les calculs à nœud unique.
Sur un calcul à nœud unique, Spark ne peut pas lire les fichiers Parquet avec une colonne UDT. Le message d’erreur suivant s’affiche :
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Pour contourner ce problème, désactivez le lecteur Parquet natif :
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Activer la mise à l’échelle automatique
Lorsque l’option Activer la mise à l’échelle automatique est cochée, vous pouvez fournir un nombre minimal et maximal de workers pour la ressource de calcul. Ensuite, Databricks détermine le nombre approprié de Workers nécessaires pour exécuter votre travail.
Pour définir le nombre minimum et maximum de travailleurs que votre ressource de calcul auto-élargira, utilisez les champs Min et Max à côté de la liste déroulante type de travailleur.
Si vous n’activez pas la mise à l’échelle automatique, vous devez entrer un nombre fixe de workers dans le champ Workers en regard de la liste déroulante type Worker .
Remarque
Lorsque la ressource de calcul fonctionne, la page de détails de calcul affiche le nombre de travailleurs alloués. Vous pouvez comparer le nombre de travailleurs alloués à la configuration des travailleurs et effectuer les ajustements nécessaires.
Avantages de la mise à l’échelle automatique
Avec la mise à l’échelle automatique, Azure Databricks réallouer dynamiquement les travailleurs pour tenir compte des caractéristiques de votre travail. Certaines parties de votre pipeline peuvent être plus exigeantes en calcul que d’autres, et Databricks ajoute automatiquement des workers supplémentaires pendant ces phases de votre travail (et les supprime lorsqu’ils ne sont plus nécessaires).
La mise à l’échelle automatique facilite l’utilisation élevée, car vous n’avez pas besoin de provisionner le calcul pour qu’il corresponde à une charge de travail. Cela s’applique en particulier aux charges de travail dont les exigences changent au fil du temps (comme l’exploration d’un jeu de données au cours d’une journée), mais elle peut également s’appliquer à une charge de travail unique plus rapide dont les exigences de provisionnement sont inconnues. La mise à l’échelle automatique offre donc deux avantages :
- Les charges de travail peuvent s’exécuter plus rapidement qu’avec une ressource de calcul sous-approvisionnée de taille constante.
- La mise à l’échelle automatique peut réduire les coûts globaux par rapport à une ressource de calcul de taille statique.
En fonction de la taille constante de la ressource de calcul et de la charge de travail, la mise à l’échelle automatique vous offre un de ces avantages ou les deux en même temps. La taille de calcul peut être inférieure au nombre minimal de travailleurs sélectionné lorsque le fournisseur de services cloud met fin aux instances. Dans ce cas, Azure Databricks réessaie en permanence de réapprovisionner les instances afin de maintenir le nombre minimal de nœuds de calcul.
Remarque
La mise à l’échelle automatique n’est pas disponible pour les tâches spark-submit.
Remarque
La mise à l’échelle automatique du calcul présente des limitations pour la réduction de la taille du cluster pour les charges de travail Structured Streaming. Databricks recommande d’utiliser des pipelines déclaratifs Spark Lakeflow avec une mise à l’échelle automatique améliorée pour les charges de travail de streaming. Consultez Optimiser l’utilisation du cluster des pipelines déclaratifs Spark Lakeflow avec mise à l’échelle automatique.
Comportement de la mise à l’échelle automatique
Les espaces de travail utilisant le plan Premium bénéficient d’une mise à l’échelle automatique optimisée. Les espaces de travail dans le plan tarifaire Standard utilisent la mise à l’échelle automatique standard.
La mise à l’échelle automatique optimisée présente les caractéristiques suivantes :
- Augmente de min à max en 2 étapes.
- Peut effectuer un scale-down, même si la ressource de calcul n’est pas inactive, en examinant l’état de lecture aléatoire des fichiers.
- Effectue un scale-down en fonction d’un pourcentage des nœuds actuels.
- Sur le calcul des travaux, effectue un scale-down si la ressource de calcul est sous-utilisée au cours des 40 dernières secondes.
- Sur le calcul à usage général, effectue un scale-down si la ressource de calcul est sous-utilisée au cours des 150 dernières secondes.
- La propriété de configuration Spark
spark.databricks.aggressiveWindowDownSspécifie, en secondes, la fréquence à laquelle le calcul prend les décisions de scale-down. Si vous augmentez la valeur, le scale-down du calcul est plus lent. La valeur maximale est 600.
La mise à l’échelle automatique standard est utilisée dans les espaces de travail de plan Standard. La mise à l’échelle automatique standard présente les caractéristiques suivantes :
- Commence par ajouter 8 nœuds. Elle augmente ensuite de façon exponentielle, en effectuant autant d'étapes que nécessaire pour atteindre le maximum.
- Effectue un scale-down lorsque 90 % des nœuds ne sont pas occupés pendant 10 minutes et que le calcul est inactif depuis au moins 30 secondes.
- Réduction de l'échelle de manière exponentielle, à partir de 1 nœud.
Avertissement
N’activez pas Apache Spark Dynamic Allocation (spark.dynamicAllocation.enabled) sur les ressources de calcul qui utilisent la mise à l’échelle automatique Databricks. La mise à l’échelle automatique de Databricks gère les nœuds worker et le cycle de vie de l'exécuteur au niveau de la plateforme. L’activation de l’allocation dynamique Spark en parallèle peut entraîner des décisions de mise à l’échelle conflictuelles, ce qui provoque une rotation des exécuteurs, NODES_LOST des erreurs et des tâches qui ne sont jamais prises en charge.
Mise à l’échelle automatique avec des pools
Si vous attachez votre ressource de calcul à un pool, tenez compte des points suivants :
- Vérifiez que la taille de calcul demandée est inférieure ou égale au nombre minimal d’instances inactives dans le pool. S’il est plus grand, le temps de démarrage du calcul équivaut au calcul qui n’utilise pas de pool.
- Vérifiez que la taille maximale de calcul est inférieure ou égale à la capacité maximale du pool. Si elle est supérieure, la création du calcul échoue.
Exemple de mise à l’échelle automatique
Si vous reconfigurez une ressource de calcul statique en mise à l’échelle automatique, Azure Databricks redimensionne immédiatement la ressource de calcul dans les limites minimales et maximales, puis démarre la mise à l’échelle automatique. Par exemple, le tableau suivant montre ce qui arrive à une ressource de calcul avec une certaine taille initiale si vous la reconfigurez pour la mise à l’échelle automatique entre 5 et 10 nœuds.
| Taille initiale | Taille après reconfiguration |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
paramètres de performances avancés
Le paramètre suivant apparaît sous la section Performances avancées de l’interface utilisateur de calcul de formulaire simple.
Instances spot
Pour réduire les coûts, vous pouvez choisir d'utiliser des instances spot, également appelées machines virtuelles Spot Azure en cochant la case Instances Spot.

La première instance est toujours à la demande (le nœud pilote est toujours à la demande) et les instances suivantes sont des instances spot.
Si des instances sont supprimées en raison d’une indisponibilité, Azure Databricks tentera d’acquérir de nouvelles instances spot pour remplacer les instances supprimées. Si des instances spot ne peuvent pas être acquises, des instances à la demande sont déployées pour remplacer les instances évincées. Cette restauration automatique à la demande est prise en charge seulement pour les instances spot qui ont été entièrement acquises et qui sont en cours d’exécution. Les instances Spot qui échouent lors de l’installation ne sont pas remplacées automatiquement.
En outre, lorsque de nouveaux nœuds sont ajoutés aux ressources de calcul existantes, Azure Databricks tente d’acquérir des instances spot pour ces nœuds.
Arrêt automatique
Vous pouvez définir l’arrêt automatique pour le calcul dans la section Performances avancées . Lors la création du calcul, spécifiez une période d’inactivité en minutes après laquelle vous voulez que la ressource de calcul se termine.
Si la différence entre l’heure actuelle et la dernière commande exécutée sur la ressource de calcul est supérieure à la période d’inactivité spécifiée, Azure Databricks met automatiquement fin à cette ressource de calcul. Pour plus d’informations sur l’arrêt de calcul, consultez Arrêter un calcul.
Type de Pilote
Vous pouvez sélectionner le type de pilote dans la section Performances avancées . Le nœud de pilote conserve les informations d’état de tous les notebooks attachés à la ressource de calcul. Le nœud de pilote gère également le SparkContext, interprète toutes les commandes que vous exécutez à partir d’un notebook ou d’une bibliothèque sur la ressource de calcul et exécute le maître Apache Spark qui se coordonne avec les exécuteurs Spark.
La valeur par défaut du type de nœud du pilote est identique à celle du type de nœud Worker. Vous pouvez choisir un type de nœud de pilote plus grand avec davantage de mémoire si vous envisagez de collecter (collect()) une grande quantité de données auprès de Workers Spark et de les analyser dans le notebook.
Conseil
Étant donné que le nœud pilote conserve toutes les informations d’état des blocs-notes attachés, veillez à détacher les blocs-notes inutilisés du nœud pilote.
Balises
Les balises vous permettent de surveiller facilement le coût des ressources de calcul utilisées par différents groupes de votre organisation. Spécifiez des balises en tant que paires clé-valeur lorsque vous créez un calcul, et Azure Databricks applique ces balises aux ressources cloud telles que les machines virtuelles et les volumes de disque, ainsi que les journaux d’utilisation de Databricks.
Pour un calcul lancé à partir de pools, les étiquettes personnalisées sont appliquées uniquement aux rapports d’utilisation de DBU et ne se propagent pas aux ressources cloud.
Pour plus d’informations sur le fonctionnement des types de balises de pool et de calcul, consultez Utiliser des balises pour attribuer et suivre l’utilisation
Pour ajouter des étiquettes à votre ressource de calcul :
- Dans la section Balises , ajoutez une paire clé-valeur pour chaque balise personnalisée.
- Cliquez sur Ajouter.
Paramètres avancés
Les paramètres suivants s’affichent sous la section Avancé de l’interface utilisateur de calcul de formulaire simple :
- Modes d’accès
- Activer la mise à l’échelle automatique du stockage local
- Chiffrement de disque local
- Configuration Spark
- Livraison des journaux de calcul
- Accès SSH au calcul
- Variables d’environnement
Modes d’accès
Le mode d’accès est une fonctionnalité de sécurité qui détermine qui peut utiliser la ressource de calcul et les données accessibles en utilisant la ressource de calcul. Chaque ressource de calcul dans Azure Databricks a un mode d’accès. Les paramètres du mode d’accès se trouvent sous la section Avancé de l’interface utilisateur de calcul de formulaire simple.
La sélection du mode d’accès est automatiquement par défaut, ce qui signifie que le mode d’accès est automatiquement choisi pour vous en fonction de votre runtime Databricks sélectionné. La valeur par défaut automatique est Standard , sauf si un runtime Machine Learning ou un Databricks Runtimes inférieur à 14.3 est sélectionné, auquel cas Dedicated est utilisé.
Databricks vous recommande d’utiliser le mode d’accès standard, sauf si vos fonctionnalités requises ne sont pas prises en charge.
| Mode d’accès | Descriptif | Langues prises en charge |
|---|---|---|
| Norme | Peut être utilisé par plusieurs utilisateurs avec l’isolation des données entre les utilisateurs. | Python, SQL, Scala |
| Dedicated | Peut être affecté et utilisé par un seul utilisateur ou groupe. | Python, SQL, Scala, R |
Pour plus d’informations sur la prise en charge des fonctionnalités pour chacun de ces modes d’accès, consultez les exigences et limitations de calcul standard etles exigences et limitations de calcul dédiées.
Remarque
Dans Databricks Runtime 13.3 LTS et versions ultérieures, les scripts d’initialisation et les bibliothèques sont pris en charge par tous les modes d’accès. Les exigences et les niveaux de support varient. Consultez Où peut-on installer les scripts init ? et les Bibliothèques mises à l’échelle du calcul.
Activer la mise à l’échelle automatique du stockage local
Il est souvent difficile d'estimer l'espace disque que prendra une tâche particulière. Pour vous éviter d’avoir à estimer le nombre de gigaoctets de disque managé à attacher à votre calcul au moment de la création, Azure Databricks active automatiquement la mise à l’échelle automatique du stockage local sur tous les calculs Azure Databricks.
Avec la mise à l'échelle automatique du stockage local, Azure Databricks surveille la quantité d'espace disque disponible sur les workers Spark de votre calcul. Si un worker commence à manquer d'espace disque, Databricks attache automatiquement un nouveau disque géré au worker avant que l'espace disque ne soit épuisé. Les disques sont attachés à une limite de 5 To d’espace disque total par machine virtuelle (y compris le stockage local initial de la machine virtuelle).
Les disques managés attachés à une machine virtuelle sont détachés uniquement lorsque la machine virtuelle est retournée à Azure. En d’autres termes, les disques managés ne sont jamais détachés d’une machine virtuelle tant qu’ils font partie d’un calcul en cours d’exécution. Pour réduire l’utilisation du disque managé, Azure Databricks recommande d’utiliser cette fonctionnalité dans le calcul configuré avec mise à l’échelle automatique ou fin automatique.
Chiffrement de disque local
Important
Cette fonctionnalité est disponible en préversion publique.
Certains types d’instances que vous utilisez pour exécuter des calculs peuvent avoir des disques attachés localement. Azure Databricks peut stocker des données aléatoires ou des données éphémères sur ces disques attachés localement. Pour vous assurer que toutes les données au repos sont chiffrées pour tous les types de stockage, y compris les données aléatoires stockées temporairement sur les disques locaux de votre ressource de calcul, vous pouvez activer le chiffrement de disque local.
Important
Vos charges de travail peuvent s’exécuter plus lentement en raison de l’impact sur les performances de la lecture et de l’écriture de données chiffrées vers et à partir des volumes locaux.
Lorsque le chiffrement de disque local est activé, Azure Databricks génère une clé de chiffrement localement unique à chaque nœud de calcul et est utilisée pour chiffrer toutes les données stockées sur des disques locaux. L’étendue de la clé est locale pour chaque nœud de calcul et est détruite en même temps que le nœud de calcul. Pendant sa durée de vie, la clé se trouve dans la mémoire pour le chiffrement et le déchiffrement et est stockée chiffrée sur le disque.
Pour activer le chiffrement de disque local, vous devez utiliser l’API Clusters. Lors de la création ou de la modification d’un calcul, définissez enable_local_disk_encryption sur true.
Configuration Spark
Pour affiner les travaux Spark, vous pouvez fournir des propriétés de configuration Spark personnalisées.
Dans la page de configuration du calcul, activez le basculateur Avancé.
Cliquez sur l’onglet Spark .
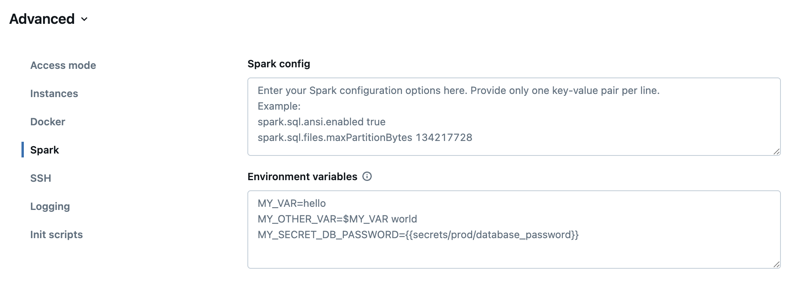
Dans la configuration Spark, entrez les propriétés de configuration sous forme de paires clé-valeur, une par ligne.
Lorsque vous configurez le calcul à l’aide de l’API Clusters, définissez les propriétés Spark dans le spark_conf champ dans l’API créer un cluster ou mettre à jour l’API de cluster.
Pour appliquer des configurations Spark sur le calcul, les administrateurs d’espace de travail peuvent utiliser des stratégies de calcul.
Récupérer une propriété de configuration Spark à partir d’un secret
Databricks recommande de stocker des informations sensibles, telles que des mots de passe, dans un secret plutôt que du texte en clair. Pour référencer une clé secrète dans la configuration Spark, utilisez la syntaxe suivante :
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Par exemple, pour définir une propriété de configuration Spark appelée password sur la valeur du secret stocké dans secrets/acme_app/password :
spark.password {{secrets/acme-app/password}}
Pour plus d’informations, consultez Gérer les secrets.
Remise des journaux de calcul
Lorsque vous créez un calcul polyvalent ou de tâches, vous pouvez spécifier un emplacement pour les journaux de cluster, y compris les journaux provenant du pilote Spark, des nœuds Worker et des événements. Les journaux sont remis toutes les cinq minutes et archivés toutes les heures dans votre destination sélectionnée. Databricks continue de fournir des journaux jusqu'à ce que la ressource de calcul soit arrêtée.
Vous pouvez stocker les logs dans l’un des emplacements suivants :
- Volumes (recommandé) : stocker les journaux d'activité dans un chemin de volume de Unity Catalog. Il s’agit de l’option recommandée et la plus sécurisée lors de l’utilisation des ressources de calcul compatibles avec le catalogue Unity.
- DBFS (hérité) : stocke les journaux d’activité dans le chemin DBFS (Databricks File System). Cette option est disponible uniquement si la racine DBFS et les points de montage ne sont pas désactivés dans l’espace de travail. Consultez Désactiver l'accès à la racine DBFS et aux montures dans votre espace de travail Azure Databricks existant.
Pour configurer l’emplacement de remise des journaux :
- Dans la page du calcul, cliquez sur le bouton bascule Avancé.
- Cliquez sur l’onglet Journalisation .
- Sélectionnez un type de destination.
- Entrez le chemin du fichier de log .
Pour stocker les journaux, Databricks crée un sous-dossier dans votre chemin de journal choisi nommé selon l’instance cluster_id du calcul.
Par exemple, si le chemin d'accès au log spécifié est /Volumes/catalog/schema/volume, les logs de 06308418893214 sont livrés à /Volumes/catalog/schema/volume/06308418893214.
Remarque
La remise des journaux d’activité à un volume est prise en charge uniquement sur le calcul avec le catalogue Unity avec le mode d’accès Standard ou le mode d’accès dédié affecté à un utilisateur. Il n’est pas pris en charge avec le mode d’accès dédié affecté à un groupe. Si vous sélectionnez un volume comme chemin, vérifiez que le propriétaire de l’ordinateur ou l’utilisateur qui lui est affecté dispose des autorisations READ VOLUME et WRITE VOLUME sur le volume. Consultez les privilèges des volumes du catalogue Unity.
Accès SSH au calcul
Pour des raisons de sécurité, dans Azure Databricks le port SSH est fermé par défaut. Si vous souhaitez activer l’accès SSH à vos clusters Spark, consultez SSH sur le nœud de pilote.
Remarque
SSH ne peut être activé que si votre espace de travail est déployé dans votre propre Azure réseau virtuel.
Variables d’environnement
Configurez des variables d’environnement personnalisées auxquelles vous pouvez accéder à partir de scripts init s’exécutant sur la ressource de calcul. Databricks fournit également des variables d’environnement prédéfinies que vous pouvez utiliser dans des scripts init. Vous ne pouvez pas remplacer ces variables d’environnement prédéfinies.
Dans la page de configuration du calcul, cliquez sur Avancé.
Cliquez sur l’onglet Spark .
Définissez les variables d’environnement dans le champ Variables d’environnement .
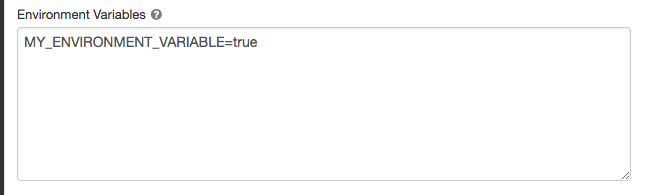
Vous pouvez également définir des variables d’environnement à l’aide du spark_env_vars champ dans l’API Créer un cluster ou mettre à jour l’API de cluster.