Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment configurer un connecteur à partir d’Azure Databricks pour lire et écrire des tables et des données stockées sur Google Cloud Storage (GCS).
Pour lire ou écrire à partir d’un compartiment GCS, vous devez créer un compte de service attaché et y associer le compartiment avec le compte de service. Vous vous connectez directement au compartiment avec une clé que vous générez pour le compte de service.
Accéder à un compartiment GCS directement avec une clé de compte de service Google Cloud
Pour lire et écrire directement dans un compartiment, vous configurez une clé définie dans votre Configuration Spark.
Étape 1 : configurer le compte de service Google Cloud à l’aide de la console Google Cloud
Vous devez créer un compte de service pour le cluster Azure Databricks. Databricks recommande de donner à ce compte de service les privilèges minimum nécessaires pour effectuer ses tâches.
Cliquez sur IAM et Administration dans le volet de navigation gauche.
Cliquez sur Comptes de service.
Cliquez sur + CRÉER UN COMPTE DE SERVICE.
Entrez le nom et la description du compte de service.
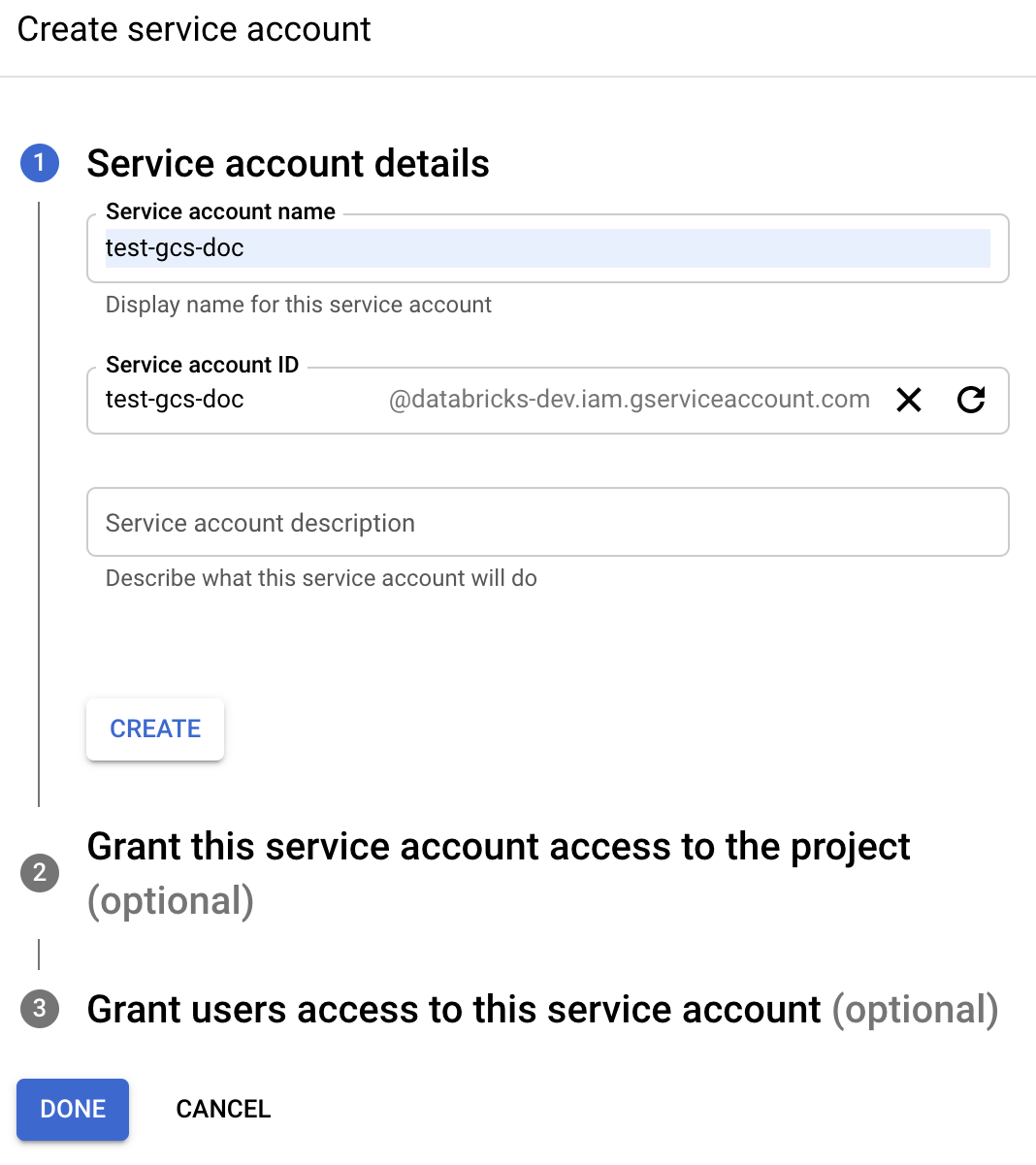
Cliquez sur CREATE (Créer).
Cliquez sur CONTINUE (Continuer).
Cliquez sur TERMINÉ.
Étape 2 : créer une clé pour accéder directement au compartiment GCS
Avertissement
La clé JSON que vous générez pour le compte de service est une clé privée qui doit être partagée uniquement avec les utilisateurs autorisés, car elle contrôle l’accès aux jeux de données et aux ressources de votre compte Google Cloud.
- Dans la console Google Cloud, dans la liste des comptes de service, cliquez sur le compte nouvellement créé.
- Dans la section Clés, cliquez sur AJOUTER CLÉ > Créer une clé.
- Acceptez le type de clé JSON.
- Cliquez sur CREATE (Créer). Le fichier clé est téléchargé sur votre ordinateur.
Étape 3 : configurer le compartiment GCS
Créer un compartiment
Si vous n’avez pas encore de compartiment, créez-en un :
Cliquez sur Stockage dans la colonne de navigation de gauche.
Cliquez sur CRÉER UN COMPARTIMENT.
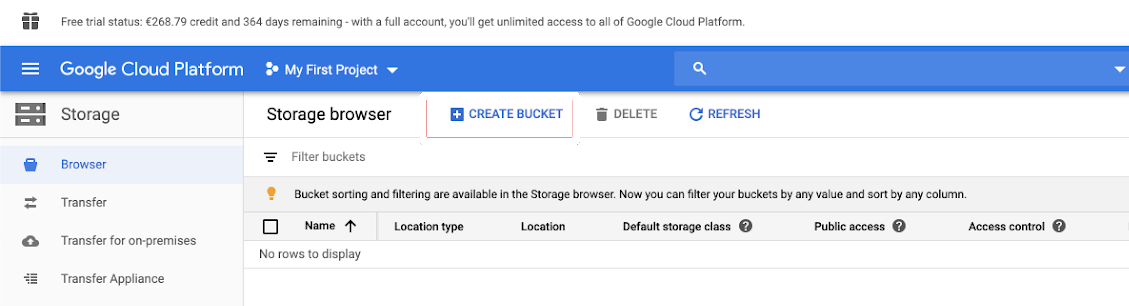
Cliquez sur CREATE (Créer).
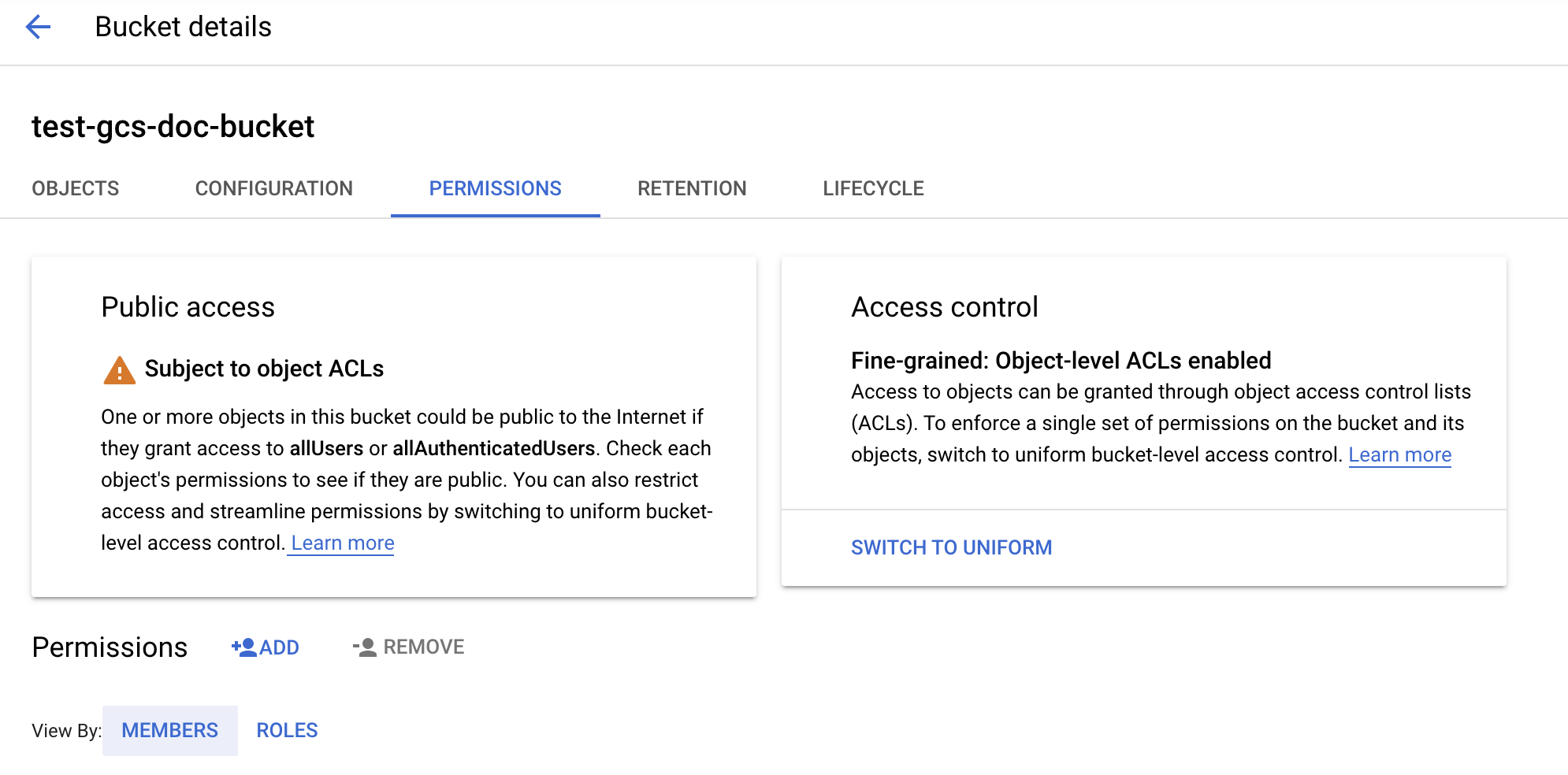
Configurer le compartiment
Configurez les détails du compartiment.
Cliquez sur l'onglet Permissions .
En regard de l’étiquette Autorisations, cliquez sur AJOUTER.
Fournissez l’autorisation Administrateur du stockage au compte de service sur le compartiment à partir des rôles stockage cloud.
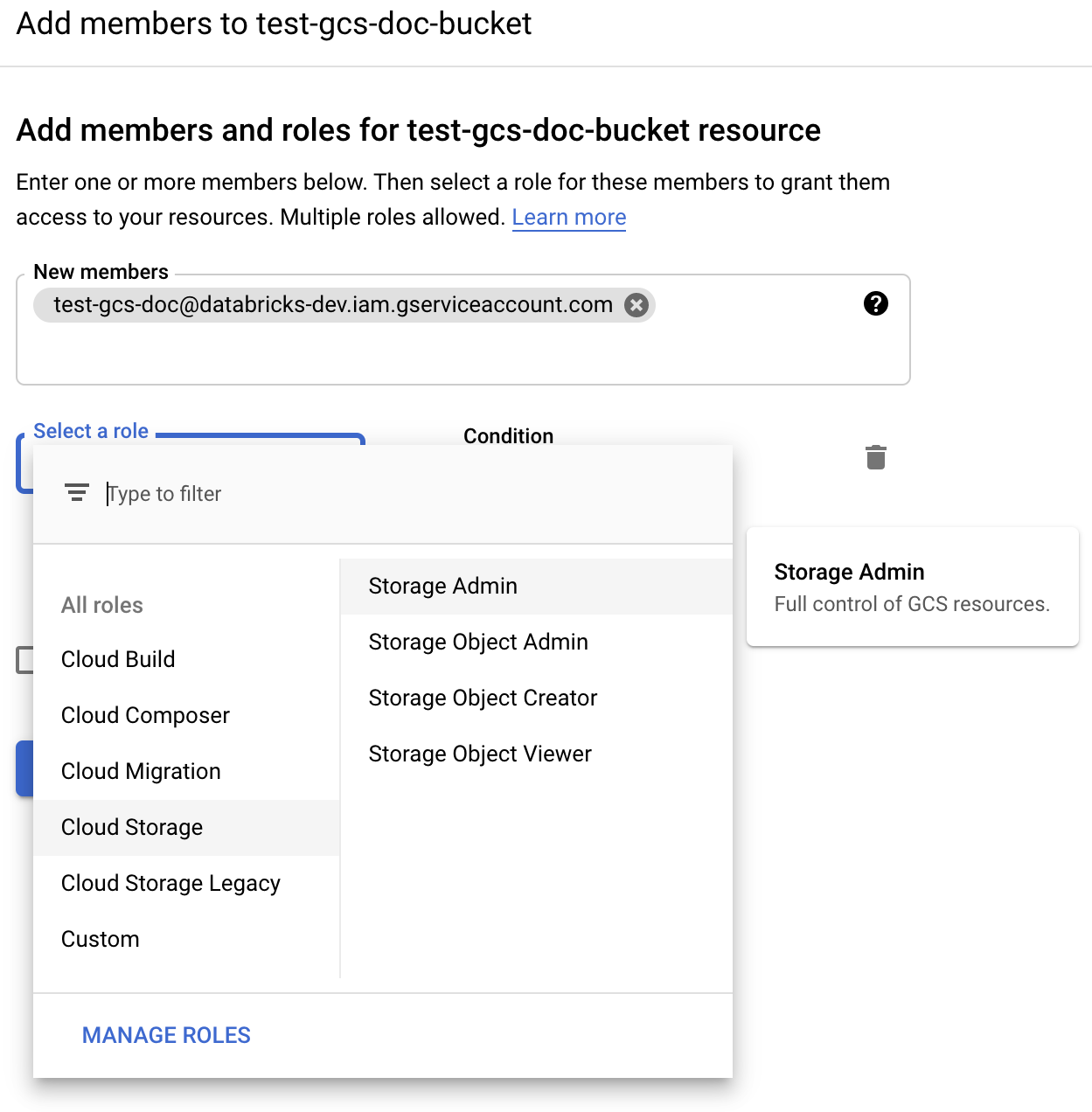
Cliquez sur ENREGISTRER.
Étape 4 : placer la clé de compte de service dans des secrets Databricks
Databricks recommande d’utiliser des étendues de secret pour stocker toutes les informations d’identification. Vous pouvez placer la clé privée et l’ID de clé privée à partir de votre fichier JSON de clé dans des étendues de secrets Databricks. Vous pouvez accorder aux utilisateurs, aux principaux de service et aux groupes de votre espace de travail un accès pour lire les étendues de secret. Cela protège la clé de compte de service tout en permettant aux utilisateurs d’accéder à GCS. Pour créer une étendue de secret, consultez Gérer les secrets.
Étape 5 : configurer un cluster Azure Databricks
Sous l’onglet Configuration Spark, effectuez une configuration globale ou une configuration par compartiment. Les exemples suivants définissent les clés à l’aide de valeurs stockées comme secrets Databricks.
Remarque
Utilisez le contrôle d’accès au groupement et le contrôle d’accès au notebook pour protéger l’accès au compte de service et aux données dans le compartiment GCS. Consultez Autorisations de calcul et Collaborer à l’aide de notebooks Databricks.
Configuration globale
Utilisez cette configuration si les identifiants fournis doivent être utilisés pour accéder à tous les compartiments.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Remplacez <client-email>, <project-id> par les valeurs de ces noms de champs exacts de votre fichier JSON de clé.
Configuration par compartiment
Utilisez cette configuration si vous devez configurer les identifiants pour des compartiments spécifiques. La syntaxe de la configuration par compartiment ajoute le nom du compartiment à la fin de chaque configuration, comme dans l’exemple suivant.
Important
Les configurations par compartiment peuvent être utilisées en plus des configurations globales. Lorsqu’elles sont spécifiées, les configurations par compartiment l’emportent sur les configurations globales.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Remplacez <client-email>, <project-id> par les valeurs de ces noms de champs exacts de votre fichier JSON de clé.
Étape 6 : lecture à partir de GCS
Pour lire à partir du compartiment GCS, utilisez une commande de lecture Spark dans n’importe quel format pris en charge, par exemple :
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Pour écrire dans le compartiment GCS, utilisez une commande d’écriture Spark dans n’importe quel format pris en charge, par exemple :
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Remplacez <bucket-name> par le nom du compartiment créé à l’Étape 3 : configurer le compartiment GCS.