Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Remarque
Cet article présente Databricks Connect pour Databricks Runtime 13.3 LTS et les versions ultérieures.
Databricks Connect vous permet de connecter des IDE courants comme IntelliJ IDEA, des serveurs de notebook et d’autres applications personnalisées aux clusters Azure Databricks. Consultez Qu’est-ce que Databricks Connect ?.
Cet article explique comment démarrer rapidement avec Databricks Connect pour Scala à l’aide d’IntelliJ IDEA et du plug-in Scala.
- Pour accéder à la version Python de cet article, consultez Databricks Connect pour Python.
- Pour accéder à la version R de cet article, consultez Databricks Connect pour R.
Didacticiel
Dans le tutoriel suivant, vous créez un projet dans IntelliJ IDEA, installez Databricks Connect pour Databricks Runtime 13.3 LTS et versions ultérieures, puis exécutez du code simple sur le calcul dans votre espace de travail Databricks à partir d’IntelliJ IDEA. Pour plus d’informations et d’exemples, consultez Étapes suivantes.
Spécifications
Pour suivre ce tutoriel, vous devez répondre aux exigences suivantes :
Votre espace de travail et cluster Azure Databricks cible doivent répondre aux exigences de calcul pour Databricks Connect.
Vous devez disposer de votre ID de cluster. Pour obtenir votre ID de cluster, dans votre espace de travail, cliquez sur Calcul dans la barre latérale, puis sur le nom de votre cluster. Dans la barre d’adresses de votre navigateur web, copiez la chaîne de caractères entre
clustersetconfigurationdans l’URL.Votre environnement local et votre calcul répondent aux exigences de version d’installation de Databricks Connect pour Scala.
Vous avez le kit de développement Java (JDK) installé sur votre machine de développement. Databricks recommande que la version de votre installation JDK corresponde à la version JDK sur votre cluster Azure Databricks. Pour rechercher la version JDK du Runtime Databricks sur votre cluster, reportez-vous à la section Environnement système des notes de publication de Databricks Runtime ou à la matrice de prise en charge de la version.
Remarque
Si vous n’avez pas installé de JDK ou si vous avez plusieurs installations JDK sur votre machine de développement, vous pouvez installer ou choisir un JDK spécifique plus tard à l’étape 1. Le choix d’une installation JDK inférieure ou supérieure à la version JDK sur votre cluster peut produire des résultats inattendus, ou votre code peut ne pas s’exécuter du tout.
Vous avez IntelliJ IDEA installé. Ce tutoriel a été testé avec IntelliJ IDEA Community Edition 2023.3.6. Si vous utilisez une version ou une édition différente d’IntelliJ IDEA, les instructions suivantes peuvent varier.
Vous avez le plug-in Scala pour IntelliJ IDEA installé.
Étape 1 : configurer l’authentification Azure Databricks
Ce tutoriel utilise l’authentification U2M (utilisateur à machine) OAuth d’Azure Databricks et un profil de configuration Azure Databricks pour l’authentification auprès de votre espace de travail Azure Databricks. Pour utiliser un autre type d’authentification à la place, consultez Configurer les propriétés de connexion.
La configuration de l’authentification U2M OAuth nécessite l’interface CLI Databricks suivante :
Si elle n’est pas déjà installée, installez l’interface CLI Databricks de la manière suivante :
Linux, macOS
Utilisez Homebrew pour installer l’interface CLI Databricks en exécutant les deux commandes suivantes :
brew tap databricks/tap brew install databricksFenêtres
Vous pouvez utiliser winget, Chocolatey ou WSL (Sous-système Windows pour Linux) pour installer l’interface CLI Databricks. Si vous ne pouvez pas utiliser
wingetChocolatey ou WSL, vous devez ignorer cette procédure et utiliser l’invite de commande ou PowerShell pour installer l’interface CLI Databricks depuis la source à la place.Remarque
L’installation de l’interface CLI Databricks avec Chocolatey est Expérimentale.
Pour installer l’interface CLI Databricks via
winget, exécutez les deux commandes suivantes, puis redémarrez votre invite de commandes :winget search databricks winget install Databricks.DatabricksCLIPour utiliser Chocolatey pour installer l’interface CLI Databricks, exécutez la commande suivante :
choco install databricks-cliPour utiliser WSL pour installer l’interface CLI Databricks :
Installez
curletzipvia WSL. Pour plus d’informations, consultez la documentation de votre système d’exploitation.Utilisez WSL pour installer l’interface CLI Databricks en exécutant la commande suivante :
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Vérifiez que l’interface CLI Databricks est installée en exécutant la commande suivante, qui affiche la version actuelle de l’interface CLI Databricks installée. Cette version doit être la version 0.205.0 ou ultérieure :
databricks -vRemarque
Si vous exécutez
databricksmais que vous obtenez une erreur telle quecommand not found: databricks, ou si vous exécutezdatabricks -vet qu’un numéro de version 0.18 ou inférieur est affiché, votre ordinateur ne trouve pas la version correcte de l’exécutable de l’interface CLI Databricks. Pour résoudre ce problème, consultez Vérifier l’installation de votre interface CLI.
Lancez l’authentification U2M OAuth de la manière qui suit :
Utilisez l’interface CLI Databricks pour lancer la gestion des jetons OAuth localement en exécutant la commande suivante pour chaque espace de travail cible.
Dans la commande suivante, remplacez
<workspace-url>par votre URL d’espace de travail Azure Databricks, par exemplehttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>L’interface CLI Databricks vous invite à enregistrer les informations que vous avez entrées en tant que profil de configuration Azure Databricks. Appuyez sur
Enterpour accepter le nom de profil suggéré, ou entrez le nom d’un profil nouveau ou existant. Tout profil existant portant le même nom est remplacé par les informations que vous avez entrées. Vous pouvez utiliser des profils pour changer rapidement de contexte d’authentification entre plusieurs espaces de travail.Pour obtenir la liste des profils existants, dans un autre terminal ou une autre invite de commandes, utilisez l’interface CLI Databricks pour exécuter la commande
databricks auth profiles. Pour afficher les paramètres existants d’un profil spécifique, exécutez la commandedatabricks auth env --profile <profile-name>.Dans votre navigateur web, suivez les instructions à l’écran pour vous connecter à votre espace de travail Azure Databricks.
Dans la liste des clusters disponibles qui s’affiche sur votre terminal ou votre ligne de commandes, utilisez les flèches haut et bas pour sélectionner le cluster Azure Databricks cible dans votre espace de travail, puis appuyez sur
Enter. Vous pouvez également taper n’importe quelle partie du nom d’affichage du cluster pour filtrer la liste des clusters disponibles.Pour afficher la valeur actuelle du jeton OAuth d’un profil et l’horodatage d’expiration à venir du jeton, exécutez l’une des commandes suivantes :
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Si vous avez plusieurs profils présentant la même valeur pour
--host, il peut être nécessaire de spécifier les options--hostet-pensemble pour permettre à l’interface CLI Databricks de trouver les informations du jeton OAuth correspondant.
Étape 2 : Créer le projet
Démarrez IntelliJ IDEA.
Dans le menu principal, cliquez sur Fichier > Nouveau > Projet.
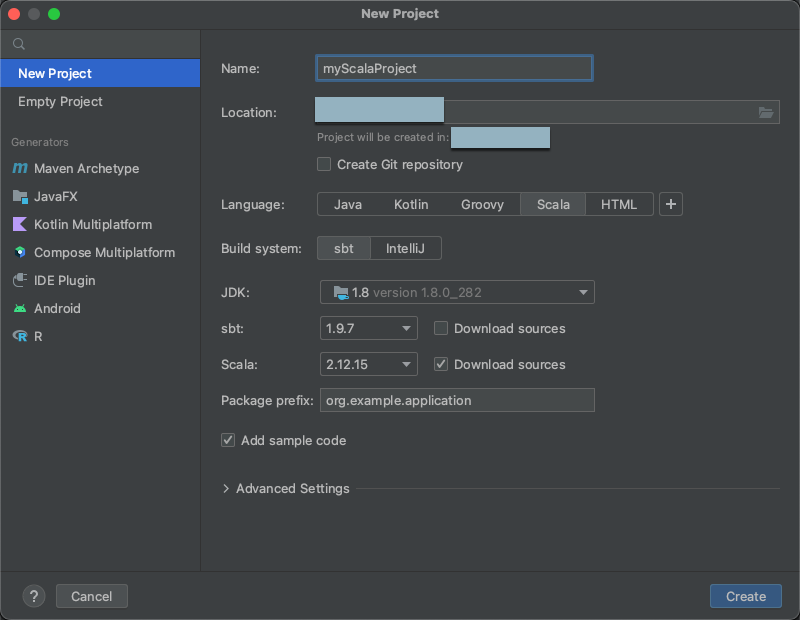
Donnez à votre projet un Nom significatif.
Pour Emplacement, cliquez sur l’icône de dossier, puis suivez les instructions à l’écran pour spécifier le chemin de votre nouveau projet Scala.
Pour Langage, cliquez sur Scala.
Pour Système de build, cliquez sur sbt.
Dans la liste déroulante JDK, sélectionnez une installation existante de JDK sur votre machine de développement qui correspond à la version du JDK de votre cluster, ou sélectionnez Télécharger JDK, puis suivez les instructions à l’écran pour télécharger un JDK qui correspond à la version du JDK de votre cluster. Consultez Configurations requises.
Remarque
Le choix d’une installation de JDK dont la version est supérieure ou inférieure à la version du JDK de votre cluster peut produire des résultats inattendus. Il se peut même que votre code ne s’exécute pas du tout.
Dans la liste déroulante sbt, sélectionnez la dernière version.
Dans la liste déroulante Scala, sélectionnez la version de Scala qui correspond à la version Scala sur votre cluster. Consultez Configurations requises.
Remarque
Le choix d’une version Scala inférieure ou supérieure à la version Scala sur votre cluster peut produire des résultats inattendus, ou votre code peut ne pas s’exécuter du tout.
Vérifiez que la case Télécharger les sources à côté de Scala est cochée.
Pour le préfixe de paquet, entrez une valeur de préfixe de paquet pour les sources de votre projet, par exemple
org.example.application.Vérifiez que la case Ajouter un exemple de code est cochée.
Cliquez sur Créer.
Étape 3 : Ajouter le package Databricks Connect
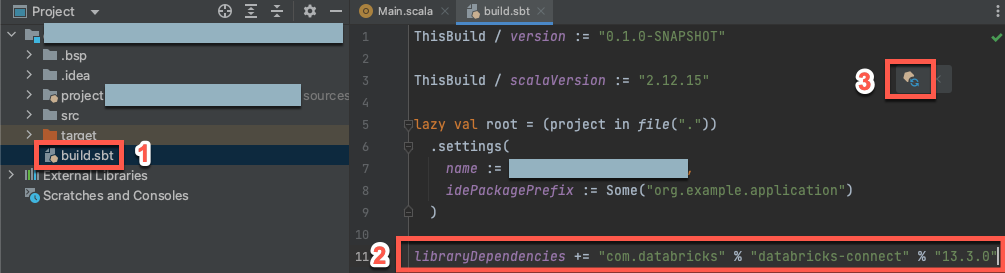
Une fois votre nouveau projet Scala ouvert, dans la fenêtre Outil Projet(Afficher > Fenêtres Outil > Projet), ouvrez le fichier nommé
build.sbt, dans project-name> cible.Ajoutez le code suivant à la fin du
build.sbtfichier, qui déclare la dépendance de votre projet sur une version spécifique de la bibliothèque Databricks Connect pour Scala, compatible avec la version Databricks Runtime de votre cluster :libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"Remplacez
14.3.1par la version de la bibliothèque Databricks Connect qui correspond à la version de Databricks Runtime sur votre cluster. Par exemple, Databricks Connect 14.3.1 correspond à Databricks Runtime 14.3 LTS. Vous trouverez les numéros de version de la bibliothèque Databricks Connect dans le dépôt central Maven.Cliquez sur l’icône de notification Charger les changements de sbt pour mettre à jour votre projet Scala avec le nouvel emplacement et la nouvelle dépendance de bibliothèque.
Attendez que l’indicateur de progression
sbtau bas de l’IDE disparaisse. Le processus de chargement desbtpeut prendre quelques minutes.
Étape 4 : Ajouter du code
Dans la fenêtre Outil Projet, ouvrez le fichier nommé
Main.scala, dans project-name> src > main > scala.Remplacez tout code existant dans le fichier par le code suivant, puis enregistrez le fichier en fonction du nom de votre profil de configuration.
Si votre profil de configuration de l’Étape 1 est nommé
DEFAULT, remplacez tout code existant dans le fichier par le code suivant, puis enregistrez le fichier :package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Si votre profil de configuration de l’Étape 1 n’est pas nommé
DEFAULT, remplacez tout code existant dans le fichier par le code suivant à la place. Remplacez l’espace réservé<profile-name>par le nom de votre profil de configuration de l’Étape 1, puis enregistrez le fichier :package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Étape 5 : Exécuter le code
- Démarrer le cluster cible dans votre espace de travail Azure Databricks distant.
- Une fois le cluster démarré, dans le menu principal, cliquez sur Exécuter « > Main ».
- Dans la fenêtre Outil Exécuter (Afficher > Fenêtres Outil > Exécuter), sous l’onglet Principal, les 5 premières lignes du tableau
samples.nyctaxi.tripss’affichent.
Étape 6 : déboguer le code
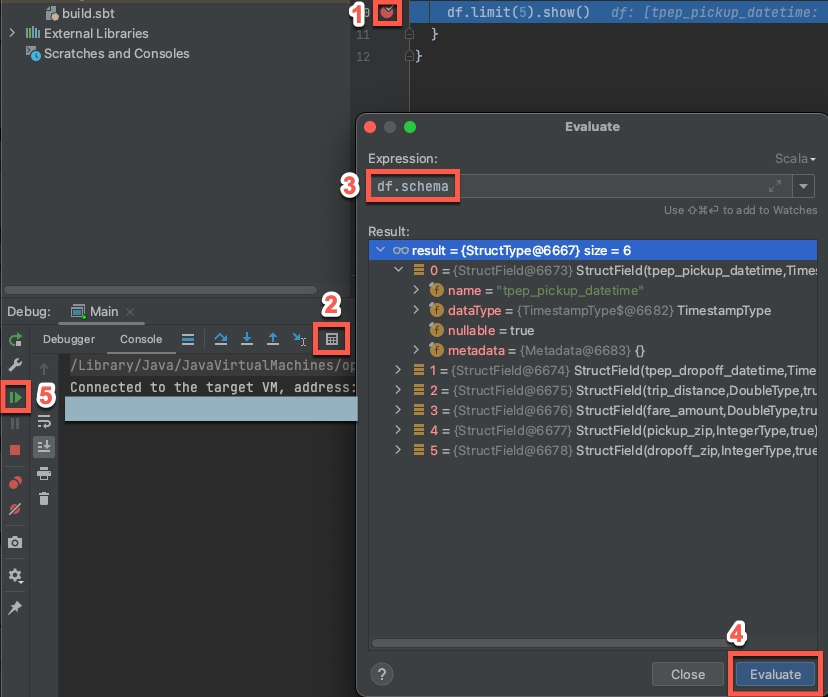
- Le cluster cible étant toujours en cours d’exécution, dans le code précédent, cliquez sur la gouttière à côté de
df.limit(5).show()pour définir un point d’arrêt. - Dans le menu principal, cliquez sur Exécuter > le débogage « Main ».
- Dans la fenêtre Outil Déboguer (Afficher > Fenêtres Outil > Déboguer), sous l’onglet Console, cliquez sur l’icône calculatrice (Évaluer l’expression).
- Entrez l’expression
df.schema, puis cliquez sur Évaluer pour afficher le schéma du DataFrame. - Dans la barre latérale de la fenêtre Outil Debug , cliquez sur l’icône flèche verte (Reprendre le programme).
- Dans le volet Console, les 5 premières lignes de la table
samples.nyctaxi.tripss’affichent.
Étapes suivantes
Pour en savoir plus sur Databricks Connect, consultez la sélection d’articles suivante :
- Pour utiliser des types d’authentification Azure Databricks autres qu’un jeton d’accès personnel Azure Databricks, consultez Configurer les propriétés de connexion.
- Pour voir d’autres exemples simples de code, consultez Exemples de code Databricks Connect pour Scala.
- Pour afficher des exemples de code plus complexes, consultez les exemples d’applications pour le référentiel Databricks Connect dans GitHub, en particulier :
- Pour migrer de Databricks Connect pour Databricks Runtime 12.2 LTS et versions inférieures vers Databricks Connect pour Databricks Runtime 13.3 LTS et versions supérieures, consultez Migrer vers Databricks Connect pour Scala.
- Consultez également les informations sur la résolution des problèmes et les limitations.