Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Un data lakehouse est un système de gestion des données qui combine les avantages des lacs de données et des entrepôts de données. Cet article décrit le modèle architectural lakehouse et ce que vous pouvez faire avec lui sur Azure Databricks.
À quoi sert un data lakehouse ?
Un data lakehouse fournit des fonctionnalités de stockage et de traitement scalables pour les organisations modernes qui souhaitent éviter les systèmes isolés pour le traitement de différentes charges de travail, telles que le Machine Learning (ML) et la décisionnel (BI). Un data lakehouse peut aider à établir une source unique de vérité, à éliminer les coûts redondants et à garantir l’actualisation des données.
Les data lakehouses utilisent souvent un modèle de conception de données qui améliore, enrichit et affine les données de façon incrémentielle au fur et à mesure qu’elles passent par des couches de mise en lots et de transformation. Chaque couche de la lakehouse peut inclure une ou plusieurs couches. Ce modèle est souvent appelé architecture de médaillon. Pour en savoir plus, consultez En quoi consiste l’architecture de lakehouse en médaillon ?
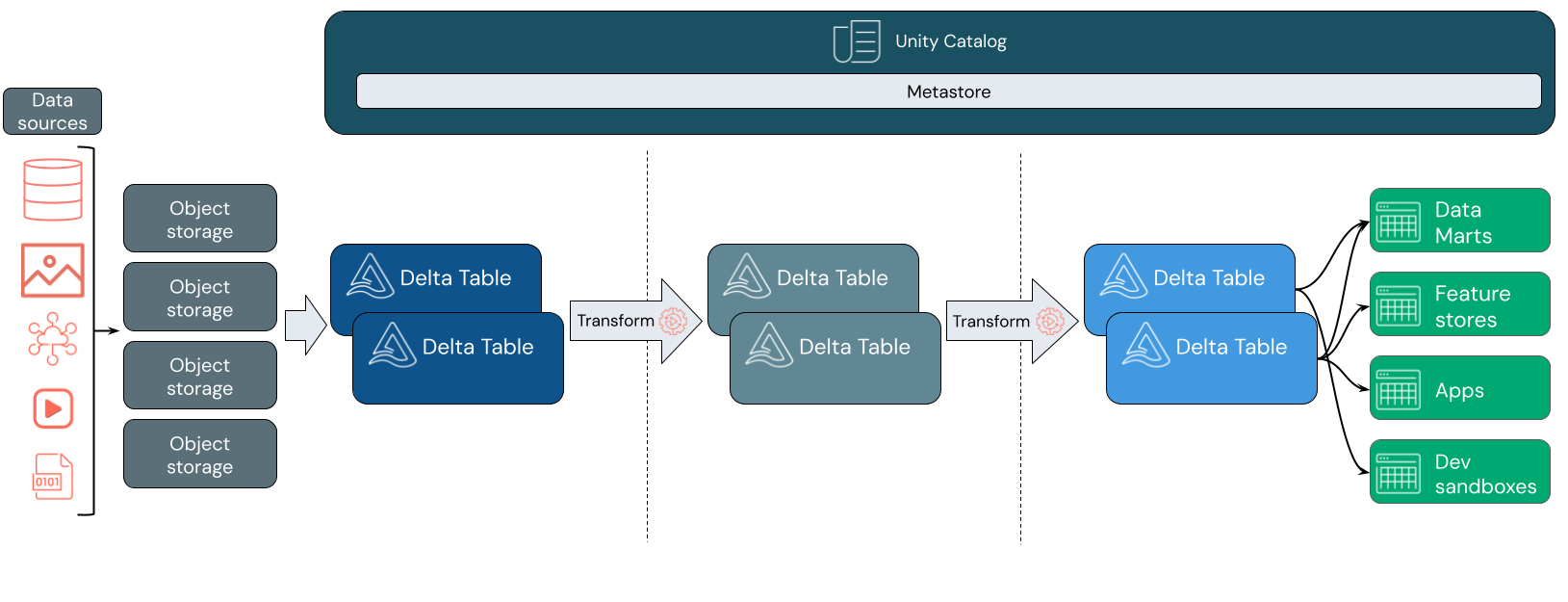
Comment fonctionne Databricks Lakehouse ?
Databricks est basé sur Apache Spark. Apache Spark permet un moteur massivement évolutif qui s’exécute sur des ressources de calcul découplées du stockage. Pour plus d’informations, consultez la vue d’ensemble d’Apache Spark
Databricks lakehouse utilise deux technologies clés supplémentaires :
- Delta Lake : couche de stockage optimisée qui prend en charge les transactions ACID et l’application du schéma.
- Catalogue Unity : solution de gouvernance unifiée et affinée pour les données et l’IA.
Ingestion des données
Au niveau de la couche d’ingestion, les données de traitement par lots ou de diffusion en continu arrivent à partir d’une variété de sources et dans divers formats. Cette première couche logique fournit un emplacement pour que ces données atterrissent dans son format brut. Lorsque vous convertissez ces fichiers en tables Delta, vous pouvez utiliser les fonctionnalités de validation de schéma de Delta Lake pour vérifier les données manquantes ou inattendues. Vous pouvez utiliser le catalogue Unity pour inscrire des tables en fonction de votre modèle de gouvernance des données et des limites d’isolation des données requises. Le catalogue Unity vous permet de suivre la traçabilité de vos données à mesure qu’elles sont transformées et affinées, ainsi que d’appliquer un modèle de gouvernance unifié pour conserver les données sensibles privées et sécurisées.
Traitement, curation et intégration des données
Une fois vérifié, vous pouvez commencer à organiser et à affiner vos données. Les scientifiques des données et les praticiens du Machine Learning travaillent fréquemment avec des données à ce stade pour commencer à combiner ou à créer de nouvelles fonctionnalités et à nettoyer les données. Une fois vos données soigneusement nettoyées, elles peuvent être intégrées et réorganisées dans des tables conçues pour répondre à vos besoins métier particuliers.
Une approche de schéma en écriture, combinée aux fonctionnalités d’évolution du schéma Delta, signifie que vous pouvez apporter des modifications à cette couche sans nécessairement avoir à réécrire la logique en aval qui sert les données à vos utilisateurs finaux.
Service de données
La couche finale sert des données nettoyées et enrichies aux utilisateurs finaux. Les tables finales doivent être conçues pour servir des données pour tous vos cas d’usage. Un modèle de gouvernance unifié signifie que vous pouvez suivre la traçabilité des données à votre source unique de vérité. Les dispositions de données, optimisées pour différentes tâches, permettent aux utilisateurs finaux d’accéder aux données pour les applications Machine Learning, l’ingénierie des données et les rapports décisionnels.
Pour en savoir plus sur Delta Lake, consultez Qu’est-ce que Delta Lake dans Azure Databricks ? Pour en savoir plus sur le catalogue Unity, consultez Qu’est-ce que le catalogue Unity ?
Fonctionnalités d’un lac Databricks
Une lakehouse s’appuyant sur Databricks remplace la dépendance actuelle aux lacs et entrepôts de données pour les sociétés de données modernes. Voici quelques tâches clés que vous pouvez effectuer :
- traitement des données en temps réel : traiter les données de streaming en temps réel pour une analyse et une action immédiates.
- intégration des données : Unifier vos données dans un système unique pour permettre la collaboration et établir une source unique de vérité pour votre organisation.
- évolution du schéma : modifier le schéma de données au fil du temps pour s’adapter aux besoins métier changeants sans perturber les pipelines de données existants.
- transformations de données : l’utilisation d’Apache Spark et delta Lake apporte de la vitesse, de l’extensibilité et de la fiabilité à vos données.
- analyse et création de rapports de données : exécuter des requêtes analytiques complexes avec un moteur optimisé pour les charges de travail d’entreposage de données.
- Machine Learning et IA : appliquer des techniques d’analytique avancées à toutes vos données. Utilisez ML pour enrichir vos données et prendre en charge d’autres charges de travail.
- Mise en version et lignage des données : Maintenir l'historique des versions pour les ensembles de données et suivre le lignage pour garantir la provenance et la traçabilité.
- gouvernance des données : Utilisez un système unifié unique pour contrôler l’accès à vos données et effectuer des audits.
- partage de données : faciliter la collaboration en permettant le partage de jeux de données organisés, de rapports et d’insights entre les équipes.
- Analytique opérationnelle : Surveillez les métriques de qualité des données, les métriques de qualité des modèles et la dérive à l’aide de la supervision de la qualité des données.
Lakehouse vs Data Lake vs Data Warehouse
Les entrepôts de données ont été à l'origine des décisions de Business Intelligence (BI) depuis environ 30 ans, ayant évolué en suivant un ensemble de directives de conception pour les systèmes contrôlant le flux de données. Les entrepôts de données d’entreprise optimisent les requêtes pour les rapports BI, mais peuvent prendre des minutes ou même des heures pour générer des résultats. Conçues pour les données qui ne sont pas susceptibles de changer avec une fréquence élevée, les entrepôts de données cherchent à éviter les conflits entre les requêtes en cours d’exécution simultanée. De nombreux entrepôts de données s’appuient sur des formats propriétaires, ce qui limite souvent la prise en charge du Machine Learning. L’entreposage de données sur Azure Databricks tire parti des fonctionnalités d’un databricks lakehouse et de Databricks SQL. Pour plus d’informations, consultez Entreposage de données sur Azure Databricks.
Grâce aux avancées technologiques dans le stockage des données et à l’augmentation exponentielle des types et du volume de données, les lacs de données sont devenus largement utilisés au cours de la dernière décennie. Les lacs de données stockent et traitent les données de manière économique et efficace. Les lacs de données sont souvent définis en opposition aux entrepôts de données : un entrepôt de données fournit des données propres et structurées pour l’analytique BI, tandis qu’un lac de données stocke définitivement et à bon marché les données de toute nature dans n’importe quel format. De nombreuses organisations utilisent des lacs de données pour la science des données et le Machine Learning, mais pas pour la création de rapports décisionnels en raison de sa nature non valide.
Le data lakehouse combine les avantages des lacs de données et des entrepôts de données et fournit :
- Ouvrez un accès direct aux données stockées dans des formats de données standard.
- Protocoles d’indexation optimisés pour le Machine Learning et la science des données.
- Latence de requête faible et fiabilité élevée pour l’intelligence d'affaires et l’analytique avancée.
En combinant une couche de métadonnées optimisée avec des données validées stockées dans des formats standard dans le stockage d’objets cloud, Data Lakehouse vous permet de travailler à partir des mêmes données et dans la même plateforme dans différents cas d’usage.
Étape suivante
Pour en savoir plus sur les principes et les bonnes pratiques pour implémenter et exploiter une lakehouse à l’aide de Databricks, consultez Présentation d'un data lakehouse bien conçu