Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans Azure Databricks, vous pouvez contrôler un pipeline et tout le code associé. En contrôlant la source tous les fichiers associés à votre pipeline, les modifications apportées à votre code de transformation, le code d’exploration et la configuration du pipeline sont toutes versionnée dans Git et peuvent être testées en développement et déployées en toute confiance en production.
Un pipeline contrôlé par la source offre les avantages suivants :
- Traçabilité : capturez chaque modification dans l’historique Git.
- Test : validez les modifications de pipeline dans un espace de travail de développement avant de promouvoir vers un espace de travail de production partagé. Chaque développeur a son propre pipeline de développement sur sa propre branche de code dans un dossier Git et dans son propre schéma.
- Collaboration : lorsque des tests et des développements individuels sont terminés, les modifications de code sont envoyées au pipeline de production principal.
- Gouvernance : S'aligner sur les normes CI/CD et de déploiement de l’entreprise.
Azure Databricks permet aux pipelines et à leurs fichiers sources d’être contrôlés ensemble à l’aide de blocs d'automatisation déclarative. Avec les bundles, la configuration du pipeline est contrôlée par la source sous la forme de fichiers de configuration YAML en même temps que les fichiers sources Python ou SQL d’un pipeline. Une offre groupée peut avoir un ou plusieurs pipelines, ainsi que d’autres types de ressources, tels que des travaux.
Cette page montre comment configurer un pipeline sous contrôle de version avec des ensembles d'automatisation déclaratifs (anciennement appelés Databricks Asset Bundles). Pour plus d’informations sur les bundles, consultez Qu'est-ce que les Declarative Automation Bundles ?.
Spécifications
Pour créer un pipeline contrôlé par la source, vous devez déjà avoir :
- Un dossier Git créé dans votre espace de travail et configuré. Un dossier Git permet aux utilisateurs individuels de créer et de tester des modifications avant de les valider dans un dépôt Git. Consultez les dossiers Git Azure Databricks.
- Éditeur Lakeflow Pipelines. Pour plus d’informations, consultez Développer et déboguer des pipelines ETL avec l’éditeur de pipelines Lakeflow .
- Pour obtenir le jeu complet de privilèges requis pour créer, exécuter, actualiser et afficher des pipelines et leur sortie, consultez Gérer les identités, les autorisations et les privilèges des pipelines.
Créer un pipeline dans un bundle
Note
Databricks recommande de créer un pipeline contrôlé par la source à partir du début. Vous pouvez également ajouter un pipeline existant à un bundle déjà contrôlé par la source. Consultez Migrer des ressources existantes vers un bundle.
Pour créer un pipeline contrôlé par la source :
En haut de la barre latérale, cliquez sur
 Nouveau , puis sélectionnez
Nouveau , puis sélectionnez  Pipeline ETL.
Pipeline ETL.Apportez les modifications que vous souhaitez apporter au nom ou au schéma du pipeline. Consultez Créer un nouveau pipeline ETL.
Cliquez sur le menu
 (à droite du bouton
(à droite du bouton  Utiliser un exemple de code) et sélectionnez
Utiliser un exemple de code) et sélectionnez  Configurer comme contrôlé par le code source.
Configurer comme contrôlé par le code source.Cliquez sur Créer un projet, puis sélectionnez un dossier Git dans lequel vous souhaitez placer votre code et votre configuration :
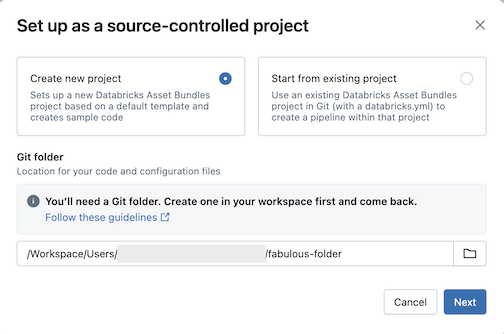
Cliquez sur Suivant.
Entrez les éléments suivants dans la boîte de dialogue Créer un ensemble de ressources :
- Nom de l’offre groupée : nom de l’offre groupée.
- Catalogue initial : nom du catalogue qui contient le schéma à utiliser.
- Utilisez un schéma personnel : cochez cette case si vous souhaitez isoler les modifications apportées à un schéma personnel, afin que lorsque les utilisateurs de votre organisation collaborent sur le même projet, vous ne remplacez pas les modifications apportées par les autres dans le développement.
- Langage initial : langage initial à utiliser pour les exemples de fichiers de pipeline du projet, Python ou SQL.
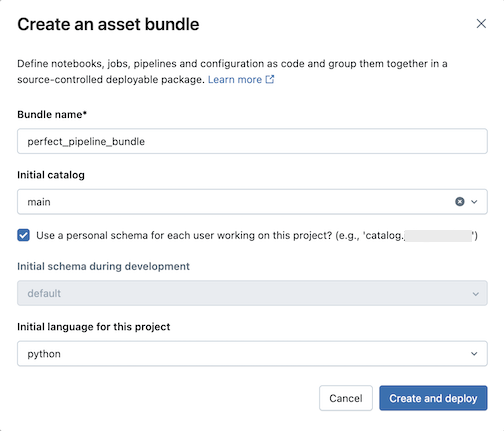
Cliquez sur Créer et déployer. Un bundle avec un pipeline est créé dans le dossier Git.
Explorer l’offre groupée de pipelines
Ensuite, explorez l'offre groupée de pipelines qui a été créée.
Le bundle, qui se trouve dans le dossier Git, contient des fichiers système groupés et le databricks.yml fichier, qui définit des variables, des URL et des autorisations d’espace de travail cibles et d’autres paramètres pour l’offre groupée. Étant donné que databricks.yml réside dans la racine de bundle (le parent de la racine du pipeline), basculez vers l’onglet Tous les fichiers du navigateur de ressources du pipeline pour le voir. Le resources dossier d’un bundle est l’endroit où les définitions des ressources telles que les pipelines et les travaux sont contenues.
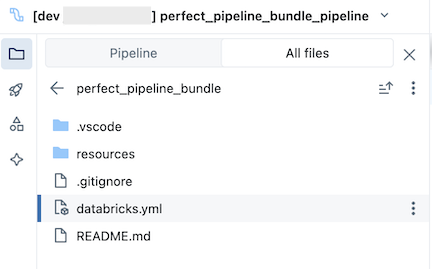
Ouvrez le resources dossier, puis cliquez sur le bouton de l’éditeur de pipeline pour afficher le pipeline contrôlé par la source :
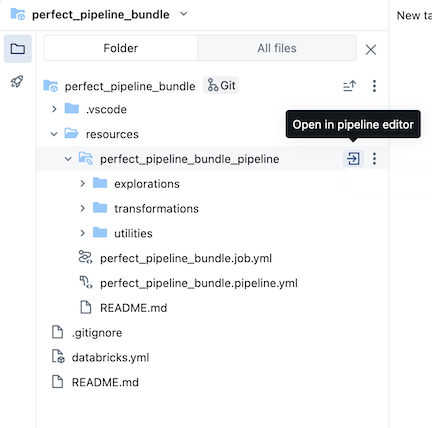
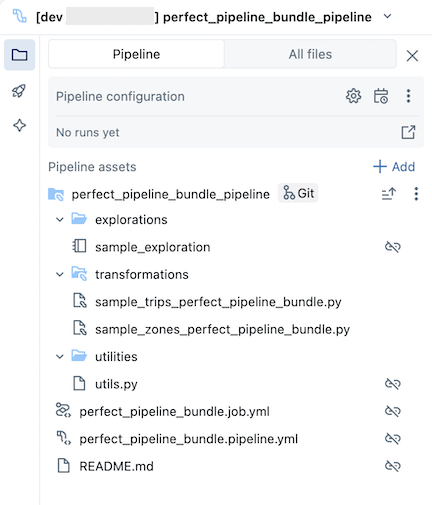
L’exemple de bundle de pipeline inclut les fichiers suivants :
Un exemple de notebook d’exploration
Deux exemples de fichiers de code qui effectuent des transformations sur des tables
Exemple de fichier de code qui contient une fonction utilitaire
Fichier YAML de configuration de travail qui définit le travail dans le bundle qui exécute le pipeline
Fichier YAML de configuration de pipeline qui définit le pipeline
Important
Vous devez modifier ce fichier pour conserver définitivement les modifications de configuration apportées au pipeline, y compris les modifications apportées via l’interface utilisateur, sinon les modifications apportées à l’interface utilisateur sont remplacées lorsque l’offre groupée est redéployée. Par exemple, pour définir un autre catalogue par défaut pour le pipeline, modifiez le
catalogchamp dans ce fichier de configuration.Fichier README avec des détails supplémentaires sur l’exemple de bundle de pipeline et des instructions sur l’exécution du pipeline
Pour plus d’informations sur les fichiers de pipeline, consultez le navigateur des ressources de pipeline.
Pour plus d’informations sur la création et le déploiement des modifications apportées à l’offre groupée de pipelines, consultez Créer des bundles dans l’espace de travail et déployer des bundles et exécuter des flux de travail à partir de l’espace de travail.
Exécuter le pipeline
Vous pouvez exécuter des transformations individuelles ou l’ensemble du pipeline contrôlé par la source :
- Pour exécuter et afficher un aperçu d’une transformation unique dans le pipeline, sélectionnez le fichier de transformation dans l’arborescence du navigateur de l’espace de travail pour l’ouvrir dans l’éditeur de fichiers. En haut du fichier dans l’éditeur, cliquez sur le bouton Lire le fichier .
- Pour exécuter toutes les transformations dans le pipeline, cliquez sur le bouton Exécuter le pipeline en haut à droite de l’espace de travail Databricks.
Pour plus d’informations sur l’exécution de pipelines, consultez Exécuter le code du pipeline.
Mettre à jour le pipeline
Vous pouvez mettre à jour des artefacts dans votre pipeline ou ajouter des explorations et transformations supplémentaires, mais vous souhaiterez ensuite envoyer ces modifications à GitHub. Cliquez sur l'Icône ![]() Git associée au groupe de pipelines ou cliquez sur le menu kebab du dossier, puis sur Git... pour sélectionner les modifications à envoyer (push). Consultez Valider et envoyer (push) les modifications.
Git associée au groupe de pipelines ou cliquez sur le menu kebab du dossier, puis sur Git... pour sélectionner les modifications à envoyer (push). Consultez Valider et envoyer (push) les modifications.
En outre, lorsque vous mettez à jour les fichiers de configuration du pipeline ou ajoutez ou supprimez des fichiers du bundle, ces modifications ne sont pas propagées à l’espace de travail cible tant que vous n’avez pas déployé explicitement le bundle. Consultez Déployer des bundles et exécuter des flux de travail à partir de l’espace de travail.
Note
Databricks recommande de conserver la configuration par défaut pour les pipelines contrôlés par la source. La configuration par défaut est configurée afin que vous n’ayez pas besoin de modifier la configuration YAML du bundle de pipeline lorsque des fichiers supplémentaires sont ajoutés via l’interface utilisateur.
Ajouter un pipeline existant à un bundle
Pour ajouter un pipeline existant à un bundle, commencez par créer un bundle dans l’espace de travail, puis ajoutez la définition YAML du pipeline au bundle, comme décrit dans les pages suivantes :
- Tutoriel : Créer et déployer un bundle dans l’espace de travail
- Ajouter une ressource existante à un bundle
Pour plus d’informations sur la migration de ressources vers un bundle à l’aide de l’interface CLI Databricks, consultez Migrer des ressources existantes vers un bundle.
Ressources supplémentaires
Pour obtenir des tutoriels supplémentaires et de la documentation de référence sur les pipelines, consultez Spark Declarative Pipelines.