Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Vous créez un pipeline Lakeflow pour l’orchestration des données avec le chargeur automatique, puis étendez l’exemple de pipeline en nettoyant les données et en créant une requête pour rechercher les 100 premiers utilisateurs.
Dans ce tutoriel, vous allez apprendre à utiliser l’éditeur de pipelines Lakeflow pour :
- Créez un pipeline avec la structure de dossiers par défaut et commencez par un ensemble d’exemples de fichiers.
- Définissez des contraintes de qualité des données à l’aide des attentes.
- Utilisez les fonctionnalités de l’éditeur pour étendre le pipeline avec une nouvelle transformation pour effectuer une analyse sur vos données.
Spécifications
Avant de commencer ce tutoriel, vous devez :
- Connectez-vous à un espace de travail Azure Databricks.
- Activez le catalogue Unity pour votre espace de travail.
- Disposez de l’autorisation de créer une ressource de calcul ou d’accéder à une ressource de calcul.
- Disposez des autorisations nécessaires pour créer un schéma dans un catalogue. Les autorisations nécessaires sont
ALL PRIVILEGESouUSE CATALOGetCREATE SCHEMA. - Pour obtenir le jeu complet de privilèges requis pour créer, exécuter, actualiser et afficher des pipelines et leur sortie, consultez Gérer les identités, les autorisations et les privilèges des pipelines.
Étape 1 : Créer un pipeline
Dans cette étape, vous créez un pipeline à l’aide de la structure de dossiers et des exemples de code par défaut. Les exemples de code référencent la table users dans la source de données d'exemple wanderbricks.
Dans votre espace de travail Azure Databricks, cliquez sur
 New, puis
New, puis  ETL pipeline. Cela ouvre l’éditeur de pipeline avec un nom de pipeline par défaut comme
ETL pipeline. Cela ouvre l’éditeur de pipeline avec un nom de pipeline par défaut comme New Pipeline <date> <time>.(Facultatif) Sélectionnez le nom et entrez un nom descriptif pour le pipeline.
(Facultatif) À droite du nom, cliquez sur le catalogue et le schéma pour définir des valeurs par défaut différentes.
(Facultatif) Dans le fichier source
my_transformationcréé pour vous, sélectionnez Python ou SQL dans la liste déroulante de langue pour définir la langue du fichier.Cliquez sur
 Utilisez un exemple de code.
Utilisez un exemple de code.L’exemple de code dans votre langue sélectionnée apparaît dans le
my_transformationfichier source dutransformationsdossier. Les jeux de données de sortie n’ont pas encore été créés et le graphique pipeline sur le côté droit de l’écran est vide.Pour exécuter le code du pipeline (le code dans le
transformationsdossier), cliquez sur Exécuter le pipeline dans la partie supérieure droite de l’écran.Une fois l’exécution terminée, la partie inférieure de l’espace de travail affiche les deux nouvelles tables qui ont été créées,
sample_users_<date_time>etsample_aggregation_<date_time>. Le graphe de pipeline sur la droite de l’espace de travail affiche désormais les deux tables, indiquant quesample_usersest la source desample_aggregation. Notez le nom complet de lasample_users_<date_time>table ; vous le référencez à l’étape suivante.
Étape 2 : Appliquer des vérifications de qualité des données
Dans cette étape, vous ajoutez un contrôle de qualité des données à la sample_users table. Vous utilisez des contraintes de pipeline afin de limiter les données. Dans ce cas, vous supprimez tous les enregistrements utilisateur qui n’ont pas d’adresse e-mail valide et affichez la table nettoyée en tant que users_cleaned.
Dans le navigateur de ressources du pipeline à gauche, cliquez sur
puis sélectionnez Transformation.Dans la boîte de dialogue Créer un fichier de transformation , effectuez les sélections suivantes :
- Choisissez Python ou SQL pour le Language. Cela ne doit pas correspondre à votre sélection précédente.
- Donnez un nom au fichier. Dans ce cas, choisissez
users_cleaned. - Pour le chemin de destination, conservez la valeur par défaut.
- Pour le type de jeu de données, laissez-le en tant que Aucun sélectionné ou choisissez Affichage matérialisé. Si vous sélectionnez l’affichage Matérialisé, il génère un exemple de code pour vous.
Cliquez sur Créer pour créer le fichier de code de transformation.
Dans votre nouveau fichier de code, modifiez le code pour qu’il corresponde à ce qui suit (utilisez SQL ou Python, en fonction de votre sélection sur l’écran précédent). Remplacez
sample_users_<date_time>par le nom complet de votresample_userstable de la section précédente.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Cliquez sur Exécuter le pipeline pour mettre à jour le pipeline. Il doit maintenant avoir trois tables.
Étape 3 : Analyser les principaux utilisateurs
Obtenez ensuite les 100 premiers utilisateurs par le nombre de réservations qu’ils ont créées. Joignez la table wanderbricks.bookings à la vue matérialisée users_cleaned.
Dans le navigateur de ressources du pipeline à gauche, cliquez sur
, et sélectionnez Transformation.Dans la boîte de dialogue Créer un fichier de transformation , effectuez les sélections suivantes :
- Choisissez Python ou SQL pour le Language. Cela ne doit pas correspondre à vos sélections précédentes.
- Donnez un nom au fichier. Dans ce cas, choisissez
users_and_bookings. - Pour le chemin de destination, conservez la valeur par défaut.
- Pour le type de jeu de données, laissez-le comme Aucun sélectionné.
Cliquez sur Créer pour créer le fichier de code de transformation.
Dans votre nouveau fichier de code, modifiez le code pour qu’il corresponde à ce qui suit (utilisez SQL ou Python, en fonction de votre sélection sur l’écran précédent).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Cliquez sur Exécuter le pipeline pour mettre à jour les jeux de données. Une fois l’exécution terminée, vous pouvez voir dans pipeline Graph qu’il existe quatre tables, y compris la nouvelle
users_and_bookingstable.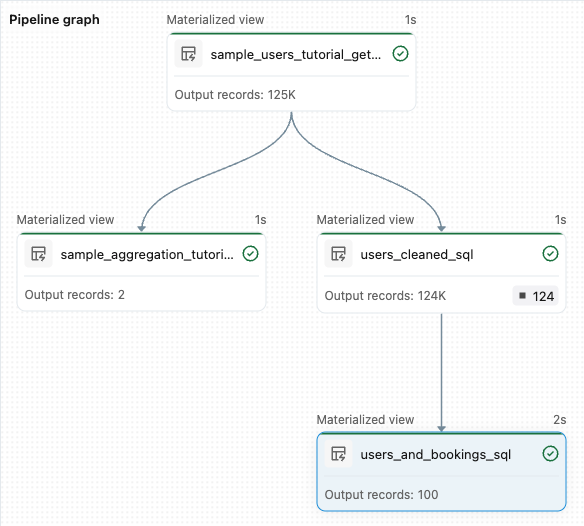
Ressources supplémentaires
Maintenant que vous avez appris à utiliser certaines des fonctionnalités de l’éditeur de pipelines Lakeflow et à créer un pipeline, voici quelques autres fonctionnalités pour en savoir plus sur :
Outils permettant d’utiliser et de déboguer des transformations lors de la création de pipelines :
- Exécution sélective
- Aperçus des données
- Graphique de pipeline interactif (graphe des jeux de données dans votre pipeline)
Intégration native des bundles d'automatisation déclarative pour une collaboration, un contrôle de version et une intégration CI/CD efficaces directement à partir de l'éditeur :