Entraîner des modèles ML avec l’interface utilisateur Mosaïque AutoML
Cet article explique comment entraîner un modèle Machine Learning à l’aide d’AutoML et de l’interface utilisateur Databricks Mosaic AI. L’IU AutoML vous guide pas à pas dans la formation d’un modèle de classification, de régression ou de prévisions sur un jeu de données.
Consultez les conditions relatives aux expériences AutoML.
Ouvrir l’IU AutoML
Pour accéder à l’IU AutoML :
Dans la barre latérale, sélectionnez Nouveau > Expérience AutoML.
Vous pouvez également créer une nouvelle expérience AutoML à partir de la page expérimentations.
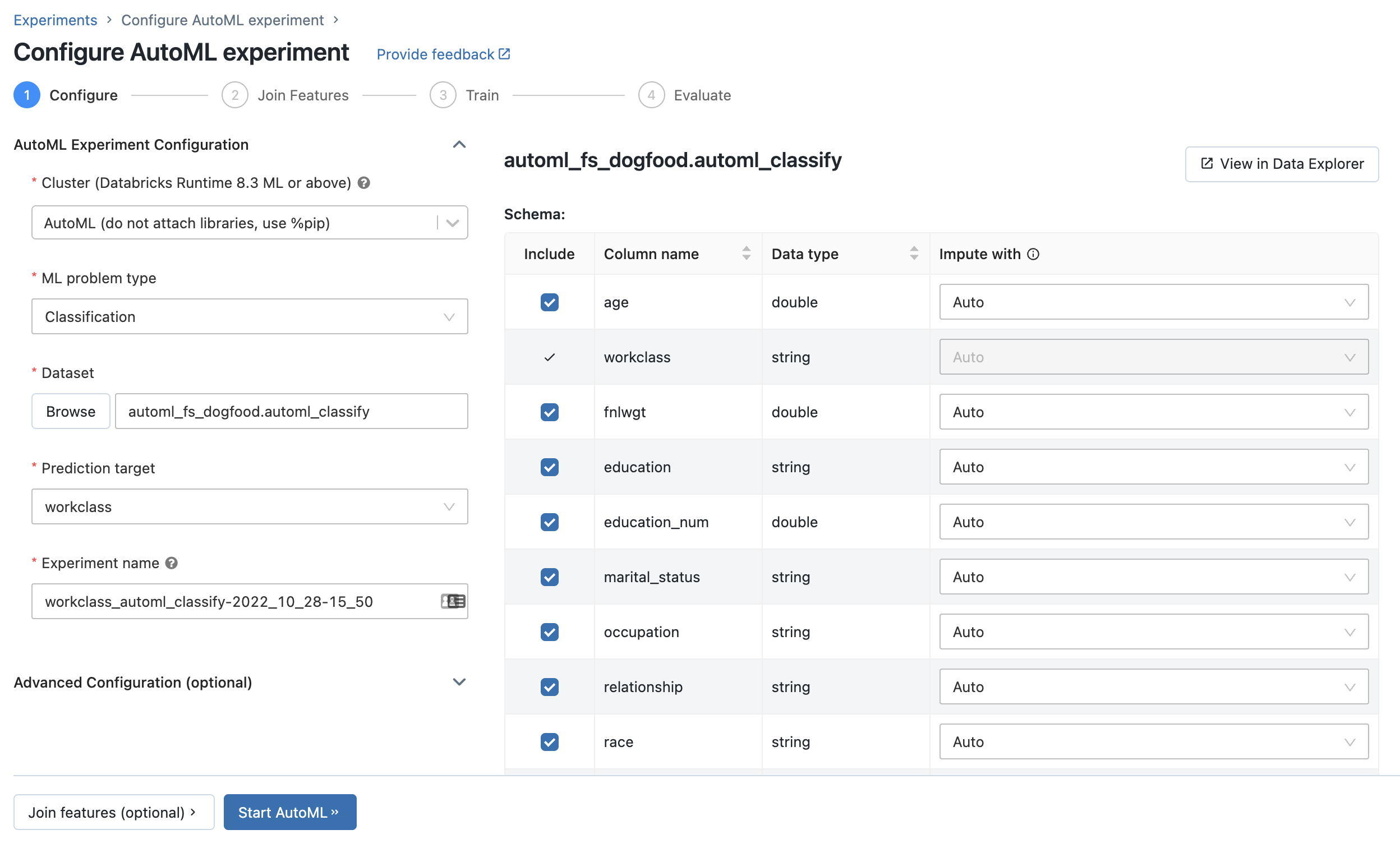
La page Configurer l’expérimentation AutoML s’affiche. Dans cette page, vous configurez le processus AutoML, en spécifiant le jeu de données, le type de problème, la cible ou la colonne d’étiquette à prédire, la mesure à utiliser pour évaluer et noter les exécutions d’expérimentation, ainsi que les conditions d’arrêt.
Configurer un problème de classification ou de régression
Vous pouvez configurer un problème de classification ou de régression à l’aide de l’interface utilisateur AutoML en procédant comme suit :
Dans le champ calcul, sélectionnez un cluster exécutant Databricks Runtime ML.
Dans le menu déroulant type de problème ML , sélectionnez régression ou Classification. Si vous essayez de prédire une valeur numérique continue pour chaque observation, telle que le revenu annuel, sélectionnez régression. Si vous essayez d’assigner chaque observation à l’un des ensembles discrets de classes, par exemple, un risque de crédit ou un risque de crédit incorrect, sélectionnez classification.
Sous Jeu de données, sélectionnez Parcourir.
Accédez à la table que vous souhaitez utiliser, puis cliquez sur Sélectionner. Le schéma de la table s’affiche.
- Dans Databricks Runtime 10.3 ML et les versions ultérieures, vous pouvez spécifier les colonnes qu’AutoML doit utiliser pour la formation. Vous ne pouvez pas supprimer la colonne sélectionnée en tant que cible de prédiction ou colonne de temps pour fractionner les données.
- Dans Databricks Runtime 10.4 LTS ML et les versions ultérieures, vous pouvez spécifier la façon dont les valeurs nulles sont imputées en effectuant une sélection dans la liste déroulante Imputer avec. Par défaut, AutoML sélectionne une méthode d’imputation en fonction du type et du contenu de la colonne.
Notes
Si vous spécifiez une méthode d’imputation autre que celle par défaut, AutoML n’effectue pas la détection de type sémantique.
Cliquez dans le champ cible de prédiction. Une liste déroulante apparaît et répertorie les colonnes affichées dans le schéma. Sélectionnez la colonne que le modèle doit prédire.
Le champ Nom de l'expérience affiche le nom par défaut. Pour le modifier, tapez le nouveau nom dans le champ.
Vous pouvez également :
- Spécifiez des options de configuration supplémentaires.
- Utilisez des tables de caractéristiques existantes dans le magasin de caractéristiques pour augmenter le jeu de données d’entrée d’origine.
Configurer des problèmes de prévision
Vous pouvez configurer un problème de prévision à l’aide de l’interface utilisateur AutoML en procédant comme suit :
Dans le champ calcul , sélectionnez un cluster exécutant Databricks Runtime 10.0 ML ou version ultérieure.
Dans le menu déroulant type de problème ML, sélectionnez prévisions.
Sous Jeu de données, cliquez sur Parcourir. Accédez à la table que vous souhaitez utiliser, puis cliquez sur Sélectionner. Le schéma de la table s’affiche.
Cliquez dans le champ cible de prédiction. Un menu déroulant apparaît et liste les colonnes affichées dans le schéma. Sélectionnez la colonne que le modèle doit prédire.
Cliquez dans le champ colonne d’heure. Une liste déroulante s’affiche avec les colonnes de jeu de données de type
timestampoudate. Sélectionnez la colonne contenant les périodes de la série chronologique.Pour les prévisions sur plusieurs séries, sélectionnez la ou les colonnes qui identifient les séries chronologiques individuelles dans la liste déroulante identificateurs de série chronologique. AutoML regroupe les données en fonction des différentes séries chronologiques et forme un modèle pour chaque série de manière indépendante. Si vous laissez ce champ vide, AutoML suppose que le jeu de données contient une seule série chronologique.
Dans les champs horizon de prévision et fréquence, spécifiez le nombre de périodes dans le futur pour lesquelles AutoML doit calculer les valeurs prévues. Dans la zone de gauche, entrez le nombre entier de périodes à prévoir. Dans la zone de droite, sélectionnez les unités.
Remarque
Pour utiliser la méthode ARIMA automatique, la série chronologique doit avoir une fréquence régulière. En d’autres termes, l’intervalle entre deux points doit être le même tout au long de la série chronologique. La fréquence doit correspondre à l’unité de fréquence spécifiée dans l’appel d’API ou dans l’interface utilisateur AutoML. AutoML gère les étapes de temps manquantes en remplissant ces valeurs avec la valeur précédente.
Dans Databricks Runtime 11.3 LTS ML et versions ultérieures, vous pouvez enregistrer les résultats de prédiction. Pour ce faire, spécifiez une base de données dans le champ Base de données de sortie. Cliquez sur Parcourir et sélectionnez une base de données dans la boîte de dialogue. AutoML écrit les résultats de prédiction dans une table de cette base de données.
Le champ Nom de l'expérience affiche le nom par défaut. Pour le modifier, tapez le nouveau nom dans le champ.
Vous pouvez également :
- Spécifiez des options de configuration supplémentaires.
- Utilisez des tables de caractéristiques existantes dans le magasin de caractéristiques pour augmenter le jeu de données d’entrée d’origine.
Utiliser les tables de caractéristiques existantes de Databricks Feature Store
Dans Databricks Runtime 11.3 LTS ML et versions ultérieures, vous pouvez utiliser des tables de caractéristiques dans le magasin de caractéristiques Databricks pour développer le jeu de données d’apprentissage d’entrée pour vos problèmes de classification et de régression.
Dans Databricks Runtime 12.2 LTS ML et les versions ultérieures, vous pouvez utiliser les tables de caractéristiques de Databricks Feature Store afin de développer le jeu de données d’apprentissage d’entrée pour tous vos problèmes AutoML : classification, régression et prévisions.
Pour créer une table de fonctionnalités, consultez Créer une table de fonctionnalités dans Unity Catalog ou Créer une table de fonctionnalités dans Databricks Feature Store.
Une fois que vous avez configuré votre expérience AutoML, vous pouvez sélectionner une table de caractéristiques en suivant les étapes ci-dessous :
Cliquez sur Joindre des caractéristiques (facultatif).
Dans la page Joindre des caractéristiques supplémentaires, sélectionnez une table de caractéristiques dans le champ Table de caractéristiques.
Pour chaque clé primaire de table de caractéristiques, sélectionnez la clé de recherche correspondante. La clé de recherche doit être une colonne dans le jeu de données d’entraînement que vous avez fourni pour votre expérience AutoML.
Pour les tables de caractéristiques de série chronologique, sélectionnez la clé de recherche de timestamp correspondante. De même, la clé de recherche de timestamp doit être une colonne dans le jeu de données d’entraînement que vous avez fourni pour votre expérience AutoML.
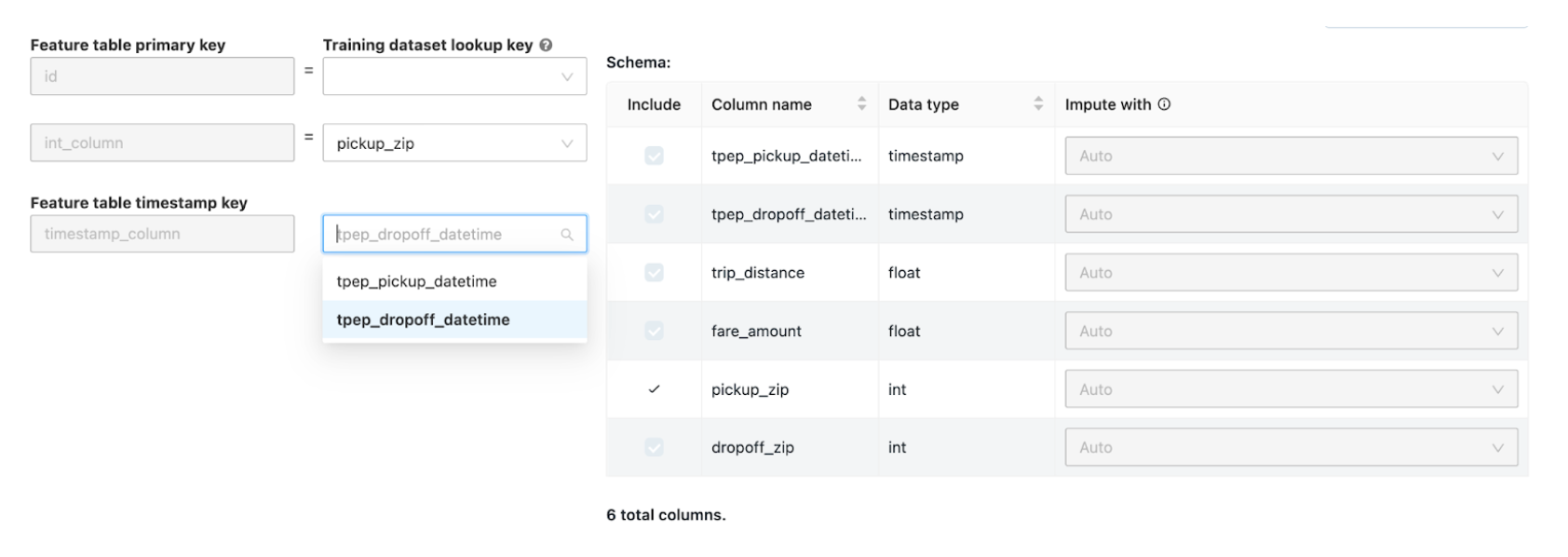
Pour ajouter d’autres tables de caractéristiques, cliquez sur Ajouter une autre table et répétez les étapes ci-dessus.
Configurations avancées
Ouvrez la section Configuration avancée (facultative) pour accéder à ces paramètres.
- La mesure d’évaluation est la métrique principale utilisée pour noter les exécutions.
- Dans Databricks Runtime 10.4 LTS ML et versions ultérieures, vous pouvez exclure des infrastructures d’apprentissage. Par défaut, AutoML forme les modèles à l’aide d’infrastructures listées sous algorithmes AutoML.
- Vous pouvez modifier les conditions d’arrêt. Les conditions d’arrêt par défaut sont :
- Pour les expériences de prévision, arrêtez après 120 minutes.
- Dans Databricks Runtime 10.4 LTS ML et versions antérieures, pour les expériences de classification et de régression, arrêtez au bout de 60 minutes ou après avoir effectué 200 essais, selon la situation qui se produit en premier. Pour Databricks Runtime 11.0 ML et les versions ultérieures, le nombre d’essais n’est pas utilisé comme condition d’arrêt.
- Dans Databricks Runtime 10.4 LTS ML et versions ultérieures, pour les expériences de classification et de régression, AutoML intègre des arrêts précoces. il arrête les modèles d’apprentissage et d’ajustage si la mesure de validation ne s’améliore plus.
- Dans Databricks Runtime 10.4 LTS ML et versions ultérieures, vous pouvez sélectionner une colonne de temps pour fractionner les données d’apprentissage, de validation et de test dans l’ordre chronologique (s’applique uniquement à la classification et à la régression).
- Databricks recommande de ne pas remplir le champ répertoire de données. Cela déclenche le comportement par défaut qui consiste à stocker de manière sécurisée le jeu de données en tant qu’artefact MLflow. Un chemin d’accès DBFS peut être spécifié, mais dans ce cas, le jeu de données n’hérite pas des autorisations d’accès de l’expérience AutoML.
Exécuter l’expérience et vérifier les résultats
Pour démarrer l’expérience AutoML, cliquez sur Démarrer AutoML. L’expérimentation commence à s’exécuter et la page de formation AutoML s’affiche. Cliquez sur le  pour actualiser la liste.
pour actualiser la liste.
À partir de cette page, vous pouvez :
- Arrêtez l’expérience à tout moment.
- Ouvrez le bloc-notes d'exploration des données.
- Surveiller les exécutions.
- Accédez à la page d’exécution de toutes les exécutions.
Avec Databricks Runtime 10.1 ML et versions ultérieures, AutoML affiche des avertissements pour les problèmes potentiels liés au jeu de données, tels que les types de colonnes non pris en charge ou les colonnes de cardinalité élevée.
Notes
Databricks fait de son mieux pour indiquer des erreurs ou des problèmes potentiels. Toutefois, cela n’est peut-être pas complet. Il est possible que les problèmes ou les erreurs que vous recherchez ne soient pas pris en compte.
Pour voir les avertissements du jeu de données, cliquez sur l’onglet Avertissements dans la page de formation, ou dans la page d’expérience une fois l’expérience terminée.
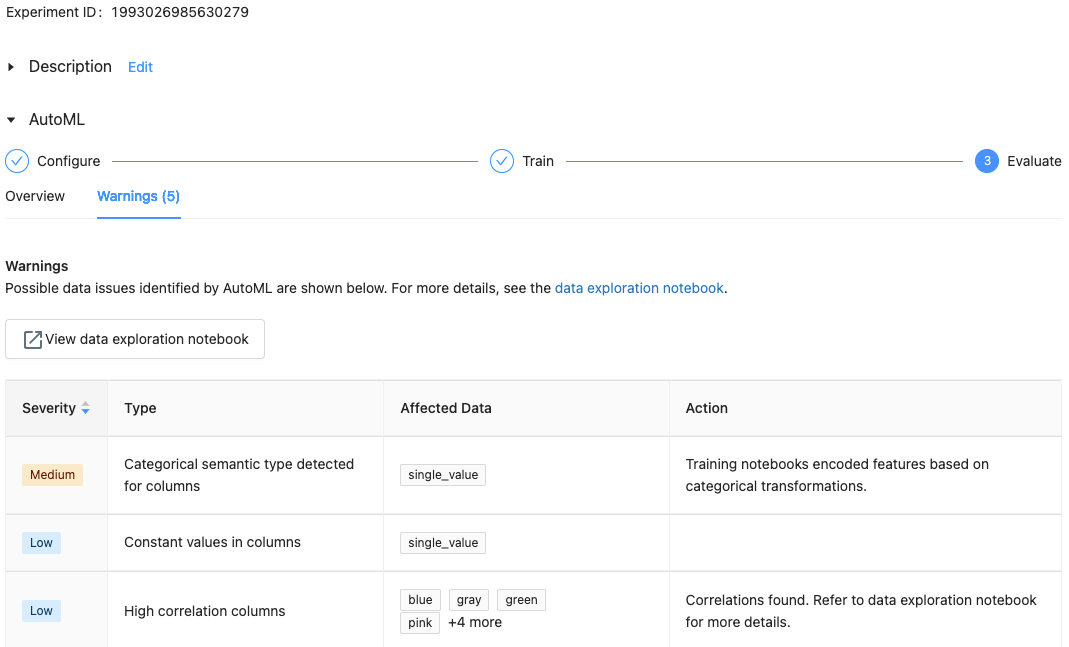
Une fois l’expérience terminée, vous pouvez :
- Enregistrer et déployez l’un des modèles avec MLflow.
- Sélectionnez Afficher le notebook pour obtenir le meilleur modèle pour vérifier et modifier le notebook qui a créé le meilleur modèle.
- Sélectionnez afficher le notebook d’exploration des données pour ouvrir le notebook exploration de données.
- Recherchez, filtrez et triez les exécutions dans le tableau des exécutions.
- Affichez les détails de toutes les exécutions :
- Le notebook généré contenant du code source pour une exécution d’évaluation est disponible en cliquant sur l’exécution de MLflow. Le notebook est enregistré dans la section Artefacts de la page d’exécution. Vous pouvez télécharger ce notebook et l’importer dans l’espace de travail, à condition que le téléchargement des artefacts soit activé par les administrateurs de votre espace de travail.
- Pour voir les résultats de l’exécution, cliquez sur la colonne Modèles ou la colonne Heure de début. La page d’exécution apparaît, et affiche des informations sur l’exécution d’essai (par exemple les paramètres, les métriques et les balises) ainsi que les artefacts créés par l’exécution, notamment le modèle. Cette page comprend également des extraits de code que vous pouvez utiliser pour faire des prédictions avec le modèle.
Pour revenir à cette expérience AutoML ultérieurement, recherchez-la dans le tableau de la page expérimentations. Les résultats de chaque expérience AutoML, y compris les carnets d'exploration des données et d'entraînement, sont stockés dans un dossierdatabricks_automl du dossier personnel de l'utilisateur qui a réalisé l'expérience.
Inscrire et déployer un modèle
Vous pouvez inscrire et déployer votre modèle avec l’interface utilisateur AutoML :
- Sélectionnez le lien dans la colonne modèles pour le modèle à inscrire. À la fin d’une exécution, la ligne supérieure représente le meilleur modèle (en fonction de la métrique principale).
- Sélectionnez le
 pour enregistrer le modèle dans le registre des modèles.
pour enregistrer le modèle dans le registre des modèles. - Sélectionnez
 Modèles dans la barre latérale pour accéder au registre des modèles.
Modèles dans la barre latérale pour accéder au registre des modèles. - Sélectionnez le nom de votre modèle dans la table modèle.
- À partir de la page du modèle enregistré, vous pouvez mettre en service le modèle avec Mise en service de modèles.
Aucun module nommé 'pandas.core.indexes.numeric
Lors de la distribution d’un modèle créé à l’aide d’AutoML avec le service de modèle, vous pouvez obtenir l’erreur suivante : No module named 'pandas.core.indexes.numeric.
Cela est dû à une version pandas incompatible entre AutoML et l’environnement de point de terminaison de service du modèle. Vous pouvez résoudre cette erreur en exécutant le script add-pandas-dependency.py. Le script modifie requirements.txt et conda.yaml pour que votre modèle journalisé inclue la version de dépendance appropriée pandas : pandas==1.5.3
- Modifiez le script pour inclure le
run_idde l’exécution MLflow où votre modèle a été journalisé. - Réinscrire le modèle dans le registre de modèles MLflow.
- Essayez de servir la nouvelle version du modèle MLflow.