Utiliser des caractéristiques dans le magasin de caractéristiques d’un espace de travail
Remarque
Cette documentation couvre le magasin de fonctionnalités de l’espace de travail. Databricks recommande d’utiliser l’ingénierie de caractéristiques dans Unity Catalog. Le magasin de fonctionnalités de l’espace de travail sera déconseillé à l’avenir.
Cette page décrit comment créer et utiliser des tables de fonctionnalités dans Workspace Feature Store.
Remarque
Si votre espace de travail est activé pour Unity Catalog, toute table gérée par Unity Catalog qui possède une clé primaire est automatiquement une table de fonctionnalités que vous pouvez utiliser pour la formation et l'inférence de modèles. Toutes les fonctionnalités du catalogue Unity, telles que la sécurité, le lignage, le balisage et l'accès inter-espaces de travail, sont automatiquement disponibles pour la table des fonctionnalités. Pour plus d'informations sur l'utilisation des tables de fonctionnalités dans un espace de travail compatible avec Unity Catalog, consultez Ingénierie des fonctionnalités dans Unity Catalog.
Pour plus d’informations sur la traçabilité et l’actualisation des fonctionnalités de suivi, consultez Découvrir des fonctionnalités et suivre la traçabilité des fonctionnalités.
Remarque
Les noms de bases de données et de tables de fonctionnalités ne peuvent contenir que des caractères alphanumériques et des traits de soulignement (_).
Créer une base de données pour les tables de caractéristiques
Avant de créer des tables de caractéristiques, vous devez créer une base de données pour les stocker.
%sql CREATE DATABASE IF NOT EXISTS <database-name>
Les tables de caractéristiques sont stockées sous forme de tables delta. Lorsque vous créez une table de caractéristiques avec create_table (client du magasin de caractéristiques v0.3.6 et versions ultérieures) ou create_feature_table (v0.3.5 et versions antérieures), vous devez spécifier le nom de la base de données. Par exemple, cet argument crée une table Delta nommée customer_features dans la base de données recommender_system.
name='recommender_system.customer_features'
Quand vous publiez une table de caractéristiques dans un magasin en ligne, les noms de la table et de la base de données par défaut sont ceux spécifiés lors de la création de la table. Vous pouvez spécifier des noms différents avec la méthode publish_table.
L’interface utilisateur du magasin de caractéristiques Databricks affiche le nom de la table et de la base de données dans le magasin en ligne ainsi que d’autres métadonnées.
Créer une table de caractéristiques dans le magasin de caractéristiques Databricks
Notes
Vous pouvez également inscrire une table Delta existante en tant que table de caractéristiques. Consultez Inscrire une table Delta existante en tant que table de caractéristiques.
Les étapes de base de la création d’une table de caractéristiques sont les suivantes :
- Écrivez les fonctions Python pour calculer les caractéristiques. La sortie de chaque fonction doit être un DataFrame Apache Spark avec une clé primaire unique. La clé primaire peut être constituée d’une ou de plusieurs colonnes.
- Créez une table de caractéristiques en instanciant un
FeatureStoreClientet en utilisantcreate_table(v0.3.6 et versions ultérieures) oucreate_feature_table(v0.3.5 et versions antérieures). - Remplissez la table de caractéristiques en utilisant
write_table.
Pour plus d’informations sur les commandes et les paramètres utilisés dans les exemples suivants, consultez la informations de référence sur l’API Python du Magasin de fonctionnalités.
v0.3.6 et versions ultérieures
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
v0.3.5 et versions antérieures
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
Inscrire une table Delta existante en tant que table de caractéristiques
Avec la version v0.3.8 et les versions ultérieures, vous pouvez inscrire une table Delta existante en tant que table de caractéristiques. La table Delta doit exister dans le metastore.
Notes
Pour mettre à jour une table de caractéristiques inscrite, vous devez utiliser l’API Python du magasin de caractéristiques.
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
Contrôler l’accès aux tables de caractéristiques
Consultez Contrôler l’accès aux tables de caractéristiques.
Mettre à jour une table de caractéristiques
Vous pouvez mettre à jour une table de caractéristiques en ajoutant de nouvelles caractéristiques ou en modifiant des lignes spécifiques en fonction de la clé primaire.
Les métadonnées de la table de caractéristiques suivantes ne peuvent pas être mises à jour :
- Clé primaire
- Clé de partition
- Nom ou type d’une caractéristique existante
Ajouter de nouvelles caractéristiques à une table de caractéristiques existante
Vous pouvez ajouter de nouvelles caractéristiques à une table de caractéristiques existante de l’une des deux manières suivantes :
- Mettez à jour la fonction de calcul de caractéristique existante et exécutez
write_tableavec le DataFrame retourné. Cette opération met à jour le schéma de la table de caractéristiques et fusionne les nouvelles valeurs de caractéristiques en fonction de la clé primaire. - Créez une fonction de calcul de caractéristique pour calculer les nouvelles valeurs de caractéristiques. Le DataFrame retourné par cette nouvelle fonction de calcul doit contenir les clés primaires et les clés de partition des tables de caractéristiques (si elles sont définies). Exécutez
write_tableavec le DataFrame pour écrire les nouvelles caractéristiques dans la table de caractéristiques existante, en utilisant la même clé primaire.
Mettre à jour uniquement des lignes spécifiques dans une table de caractéristiques
Utilisez mode = "merge" dans write_table. Les lignes dont la clé primaire n’existe pas dans le DataFrame envoyé dans l’appel write_table restent inchangées.
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
Planifier un travail pour mettre à jour une table de caractéristiques
Pour que les caractéristiques dans les tables de caractéristiques possèdent toujours les valeurs les plus récentes, Databricks recommande de créer un travail qui exécute un notebook afin de mettre à jour votre table de caractéristiques régulièrement, par exemple tous les jours. Si vous avez déjà créé un travail non planifié, vous pouvez le convertir en travail planifié pour vous assurer que les valeurs des caractéristiques sont toujours à jour.
Le code pour mettre à jour une table de caractéristiques utilise mode='merge', comme illustré dans l’exemple suivant.
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
Stocker les valeurs passées des caractéristiques quotidiennes
Définissez une table de caractéristiques avec une clé primaire composite. Incluez la date dans la clé primaire. Par exemple, pour une table de caractéristiques store_purchases, vous pouvez utiliser une clé primaire composite (date, user_id) et une clé de partition date afin d’effectuer des lectures efficaces.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
Vous pouvez ensuite créer du code pour effectuer des opérations de lecture dans la table de caractéristiques en filtrant date sur la période digne d’intérêt.
Vous pouvez également créer une table de fonctionnalités de séries chronologiques en spécifiant la colonne date comme clé d'horodatage à l'aide de l'argument timestamp_keys.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
Il permet d’effectuer des recherches à un instant dans le temps avec create_training_set ou score_batch. Le système effectue une jointure à partir de l’horodatage, à l’aide de la clé timestamp_lookup_key indiquée.
Pour tenir à jour la table de caractéristiques, configurez un travail régulièrement planifié pour écrire les caractéristiques ou envoyer en streaming les nouvelles valeurs de caractéristiques à la table de caractéristiques.
Créer un pipeline de calcul de caractéristique en streaming pour mettre à jour les caractéristiques
Pour créer un pipeline de calcul de caractéristique en streaming, transmettez un streaming DataFrame en tant qu’argument à write_table. La méthode retourne un objet StreamingQuery.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
Lire une table de caractéristiques
Utilisez read_table pour lire les valeurs de caractéristique.
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
Rechercher et parcourir des tables de caractéristiques
Utilisez l’interface utilisateur de Feature Store pour rechercher ou parcourir des tables de caractéristiques.
Pour afficher l’interface utilisateur du magasin de fonctionnalités, dans la barre latérale, sélectionnez Machine Learning > Magasin de fonctionnalités.
Dans la zone de recherche, vous pouvez entrer tout ou partie du nom d’une table de caractéristiques, d’une caractéristique ou d’une source de données utilisée pour le calcul des caractéristiques. Vous pouvez également entrer tout ou partie de la clé ou valeur d’une étiquette. Le texte de la recherche ne respecte pas la casse.

Obtenir des métadonnées de table de caractéristiques
L’API permettant d’obtenir des métadonnées de table de caractéristiques dépend de la version du runtime Databricks que vous utilisez. Avec la version v0.3.6 et versions ultérieures, utilisez get_table. Avec la version v0.3.5 et versions antérieures, utilisez get_feature_table.
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
Utiliser des étiquettes de table de caractéristiques
Les étiquettes sont des paires clé-valeur que vous pouvez créer et utiliser pour rechercher des tables de caractéristiques. Vous pouvez créer, modifier et supprimer des étiquettes à l’aide de l’interface utilisateur de Feature Store ou de l’API Python Feature Store.
Utiliser des étiquettes de table de caractéristiques dans l’interface utilisateur
Utilisez l’interface utilisateur de Feature Store pour rechercher ou parcourir des tables de caractéristiques. Pour accéder à l’interface utilisateur, dans la barre latérale, sélectionnez Machine Learning > Magasin de fonctionnalités.
Ajouter une étiquette avec l’interface utilisateur de Feature Store
Cliquez sur l’
 si elle n’est pas déjà ouverte. Le tableau Étiquettes s’affiche.
si elle n’est pas déjà ouverte. Le tableau Étiquettes s’affiche.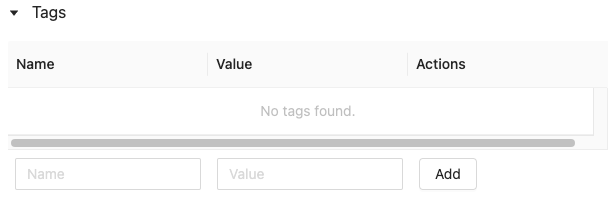
Cliquez dans les champs Nom et Valeur, puis entrez la clé et la valeur de votre étiquette.
Cliquez sur Add.
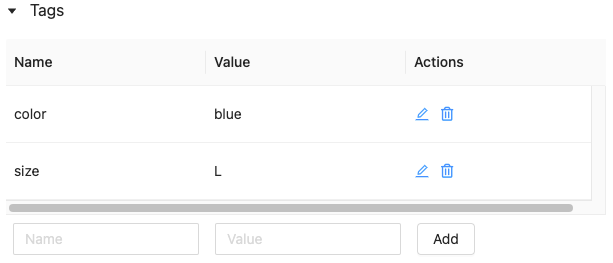
Modifier ou supprimer une étiquette à l’aide de l’interface utilisateur de Feature Store
Pour modifier ou supprimer une étiquette existante, utilisez les icônes de la colonne Actions.
Utiliser des étiquettes de table de caractéristiques à l’aide de l’API Python du magasin de caractéristiques
Sur les clusters exécutant la version v0.4.1 et versions ultérieures, vous pouvez créer, modifier et supprimer des étiquettes à l’aide de l’API Python du magasin de caractéristiques.
Spécifications
Client du magasin de caractéristiques v0.4.1 et versions ultérieures
Créer une table de caractéristiques avec une étiquette en utilisant l’API Python Feature Store
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
Ajouter, mettre à jour et supprimer des étiquettes à l’aide de l’API Python Feature Store
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
Mettre à jour les sources de données d’une table de caractéristiques
Le Feature Store suit automatiquement les sources de données utilisées pour calculer les fonctionnalités. Vous pouvez également mettre à jour manuellement les sources de données à l’aide de l’API Python du Feature Store.
Spécifications
Client du magasin de caractéristiques v0.5.0 et versions ultérieures
Ajouter des sources de données à l’aide de l’API Python du Feature Store
Voici quelques exemples de commandes. Pour plus d’informations, consultez la documentation sur les API.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
Supprimer des sources de données à l’aide de l’API Python du Feature Store
Pour plus d’informations, consultez la documentation sur les API.
Notes
La commande suivante supprime les sources de données de tous les types (« table », « chemin » et « personnalisé ») qui correspondent aux noms sources.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
Supprimer une table de caractéristiques
Vous pouvez supprime une table de caractéristiques à l’aide de l’interface utilisateur de Feature Store ou de l’API Python Feature Store.
Notes
- La suppression d’une table de caractéristiques peut entraîner des défaillances inattendues dans les producteurs en amont et les consommateurs en aval (modèles, points de terminaison et travaux planifiés). Vous devez supprimer les magasins en ligne publiés avec votre fournisseur cloud.
- Lorsque vous supprimez une table de caractéristiques à l’aide de l’API, la table Delta sous-jacente est également supprimée. Lorsque vous supprimez une table de caractéristiques de l’interface utilisateur, vous devez supprimer la table Delta sous-jacente séparément.
Supprimer une table de caractéristiques à l’aide de l’interface utilisateur
Dans la page de la table de caractéristiques, cliquez sur
 à droite du nom de la table de caractéristiques, puis sélectionnez Supprimer. Si vous n’avez pas l’autorisation PEUT GÉRER pour la table de caractéristiques, vous ne voyez pas cette option.
à droite du nom de la table de caractéristiques, puis sélectionnez Supprimer. Si vous n’avez pas l’autorisation PEUT GÉRER pour la table de caractéristiques, vous ne voyez pas cette option.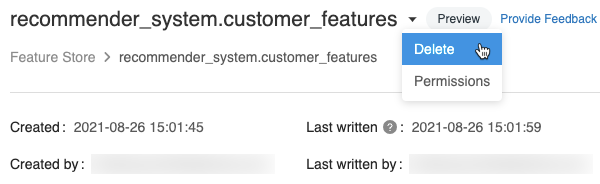
Dans la boîte de dialogue Supprimer la table de caractéristiques, cliquez sur Supprimer pour confirmer.
Si vous souhaitez également supprimer la table Delta sous-jacente, exécutez la commande suivante dans un notebook.
%sql DROP TABLE IF EXISTS <feature-table-name>;
Supprimer une table de caractéristiques en utilisant l’API Python Feature Store
Avec le client du magasin de caractéristiques v0.4.1 et versions ultérieures, vous pouvez utiliser drop_table pour supprimer une table de caractéristiques. Lorsque vous supprimez une table avec drop_table, la table Delta sous-jacente est également supprimée.
fs.drop_table(
name='recommender_system.customer_features'
)