Qu’est-ce qu’un magasin de caractéristiques ?
Cette page explique ce qu’est un magasin de caractéristiques et les avantages qu’il offre ainsi que les avantages spécifiques du Magasin de fonctionnalités Databricks.
Un magasin de caractéristiques est un référentiel centralisé qui permet aux scientifiques Données de rechercher et de partager des caractéristiques, et qui garantit aussi que le même code utilisé pour calculer les valeurs des caractéristiques est utilisé pour l’entraînement et l’inférence du modèle.
Le machine learning utilise des données existantes pour créer un modèle afin de prédire les résultats futurs. Dans presque tous les cas, les données brutes nécessitent un prétraitement et une transformation avant de pouvoir être utilisées pour créer un modèle. Ce processus est appelé ingénierie des caractéristiques, et les sorties de ce processus sont appelées « caractéristiques » : ce sont les composants du modèle.
Le développement de caractéristiques est complexe et demande du temps. Une complication supplémentaire est que pour le machine learning, les calculs de caractéristiques doivent être effectués pour l’entraînement du modèle, puis à nouveau quand le modèle est utilisé pour faire des prédictions. Ces implémentations peuvent ne pas être faites par la même équipe ou en utilisant le même environnement de codage, ce qui peut entraîner des retards et des erreurs. En outre, différentes équipes d’une organisation auront souvent besoin de caractéristiques similaires, mais peuvent ne pas être informées du travail que d’autres équipes ont déjà fait. Un magasin de caractéristiques est conçu pour résoudre ces problèmes.
Pourquoi utiliser le magasin de caractéristiques Databricks ?
Le magasin de caractéristiques Databricks est entièrement intégré à d’autres composants d’Azure Databricks.
- Découvrabilité. L’interface utilisateur du magasin de caractéristiques, accessible depuis l’espace de travail Databricks, vous permet de parcourir et de rechercher les caractéristiques existantes.
- Traçabilité. Quand vous créez une table de fonctionnalités dans Azure Databricks, les sources de données utilisées pour créer la table de fonctionnalités sont enregistrées et accessibles. Pour chaque caractéristique d’une table de caractéristiques, vous pouvez aussi accéder aux modèles, aux notebooks, aux travaux et aux points de terminaison qui utilisent la caractéristique.
- Intégration avec le scoring et le service des modèles. Quand vous utilisez des caractéristiques du magasin de caractéristiques pour entraîner un modèle, le modèle est empaqueté avec les métadonnées des caractéristiques. Quand vous utilisez le modèle pour du scoring par lot ou de l’inférence en ligne, il récupère automatiquement les caractéristiques auprès du magasin de caractéristiques. L’appelant n’a pas besoin d’en savoir plus sur les caractéristiques, ou d’inclure une logique pour rechercher ou joindre des caractéristiques pour calculer le score de nouvelles données. Ceci facilite le déploiement et les mises à jour des modèles.
- Recherches ponctuelles dans le temps. Le magasin de caractéristiques prend en charge les cas d’usage de série chronologique et basés sur des événements qui nécessitent une exactitude à un point dans le temps.
Ingénierie des fonctionnalités dans le catalogue Unity
Si votre espace de travail est activé pour Unity Catalog, celui-ci devient votre magasin de fonctionnalités avec Databricks Runtime 13.2 et versions ultérieures. Vous pouvez utiliser n'importe quelle table Delta ou Delta Live dans Unity Catalog avec une clé primaire comme table de caractéristiques pour la formation ou l’inférence de modèle. Unity Catalog fournit la détection, la gouvernance, la traçabilité et l’accès aux fonctionnalités dans plusieurs espaces de travail.
Comment fonctionne le magasin de fonctionnalités Databricks ?
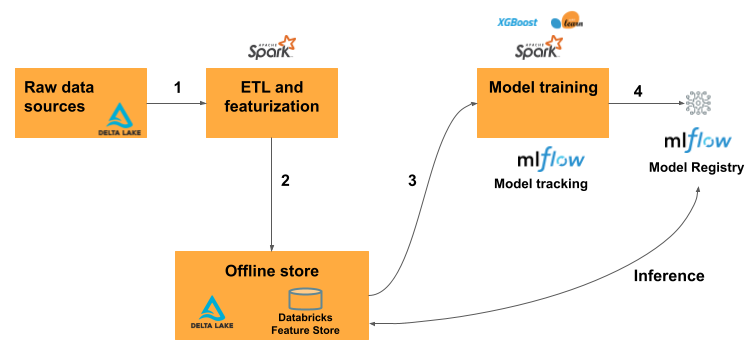
Le processus du workflow Machine Learning classique utilisant le magasin de caractéristiques est le suivant :
- Écrivez du code pour convertir des données brutes en caractéristiques et créez un DataFrame Spark contenant les caractéristiques souhaitées.
- Pour les espaces de travail activés pour Unity Catalog, écrivez le DataFrame en tant que table de fonctionnalités dans Unity Catalog. Si votre espace de travail n’est pas activé pour Unity Catalog, écrivez le DataFrame en tant que table de fonctionnalités dans l’espace de travail magasin de fonctionnalités.
- Entraînez un modèle en utilisant des caractéristiques du magasin de caractéristiques. Quand vous procédez ainsi, le modèle stocke les spécifications des caractéristiques utilisées pour l’entraînement. Lorsque le modèle est utilisé pour l’inférence, il joint automatiquement des caractéristiques à partir des tables de caractéristiques appropriées.
- Inscrivez le modèle dans le registre de modèles.
Vous pouvez maintenant utiliser ce modèle pour effectuer des prédictions sur de nouvelles données.
Pour les cas d’usage de traitement par lots, le modèle récupère automatiquement les caractéristiques dont il a besoin dans le magasin de caractéristiques.
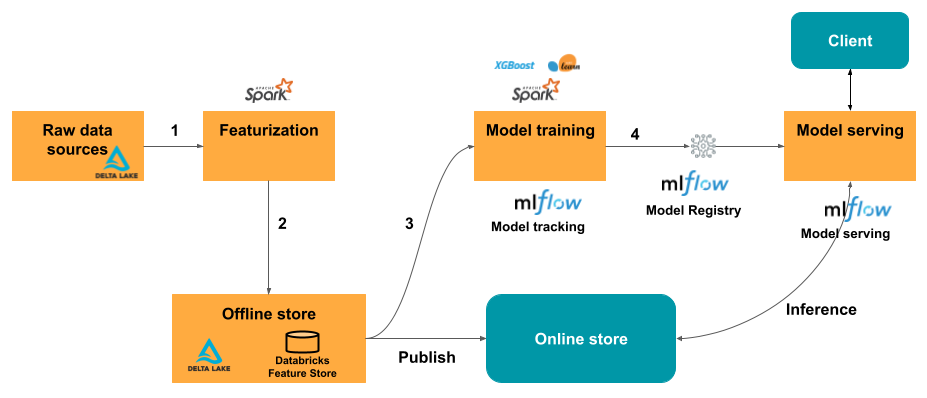
Pour les cas d’usage de mise en service en temps réel, publiez les fonctionnalités dans un magasin en ligne ou utilisez un tableau en ligne.
Au moment de l’inférence, le modèle lit les fonctionnalités précalculées du magasin en ligne et les joint aux données fournies dans la requête du client au point de terminaison de mise en service du modèle.
Commencer à utiliser le magasin de caractéristiques
Consultez les articles suivants pour bien démarrer avec le magasin de caractéristiques :
- Essayez l’un des exemples de notebooks qui illustrent les fonctionnalités du magasin de caractéristiques.
- Consultez le matériel de référence de l’API Python du magasin de caractéristiques.
- Apprenez-en davantage sur les modèles d’entraînement avec le magasin de caractéristiques.
- En savoir plus sur l'ingénierie des fonctionnalités dans Unity Catalog.
- En savoir plus sur la boutique de fonctionnalités Workspace.
- Utilisez des tables de caractéristiques de série chronologique et des recherches ponctuelles dans le temps pour récupérer les valeurs de caractéristiques les plus récentes à un moment donné en vue de l’entraînement ou du scoring d’un modèle.
- Découvrez comment publier des fonctionnalités sur des boutiques en ligne ou des tableaux en ligne pour un service en temps réel et une recherche automatique de fonctionnalités.
- Découvrez Mise en service de fonctionnalités, qui rend les fonctionnalités de la plateforme Databricks disponibles avec une faible latence pour les modèles ou les applications déployés en dehors de Databricks.
Lorsque vous utilisez Feature Engineering dans Unity Catalog, Unity Catalog se charge de partager les tables de caractéristiques entre les espaces de travail et vous utilisez les privilèges Unity Catalog pour contrôler l'accès aux tables de caractéristiques. Les liens suivants concernent uniquement Workspace Feature Store :
- Partager des tables de caractéristiques entre des espaces de travail.
- Contrôler l’accès aux tables de caractéristiques.
Types de données pris en charge
L’ingénierie de caractéristiques dans Unity Catalog et le magasin de caractéristiques de l’espace de travail prennent en charge les types de données PySpark suivantes :
IntegerTypeFloatTypeBooleanTypeStringTypeDoubleTypeLongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType[1]DecimalType[1]MapType[1]
[1] BinaryType, DecimalType et MapType sont prises en charge par toutes les versions de l’ingénierie de caractéristiques dans Unity Catalogue et par les versions 0.3.5 et ultérieures du magasin de caractéristiques de l’espace de travail.
Les types de données répertoriés ci-dessus prennent en charge les types de fonctionnalités courants dans les applications Machine Learning. Par exemple :
- Vous pouvez stocker des vecteurs denses, des tenseurs et des incorporations comme
ArrayType. - Vous pouvez stocker des vecteurs épars, des tenseurs et des incorporations comme
MapType. - Vous pouvez stocker du texte en tant que
StringType.
Quand elles sont publiées dans des magasins en ligne, les caractéristiques ArrayType et MapType sont stockées au format JSON.
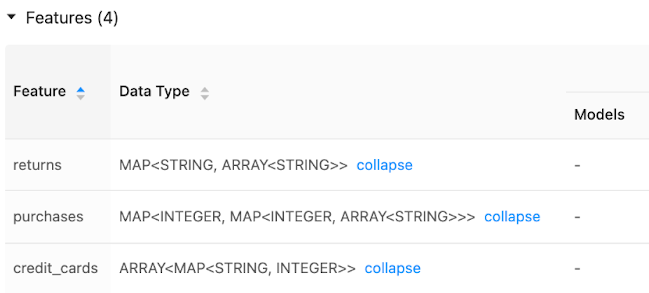
L’interface utilisateur du magasin de caractéristiques affiche des métadonnées sur les types de données des caractéristiques :
Plus d’informations
Pour plus d’informations sur les bonnes pratiques relatives à l’utilisation du magasin de caractéristiques, téléchargez le Guide complet des magasins de caractéristiques.