Concepts
Cette section décrit les concepts permettant d’utiliser des tables de caractéristiques dans Databricks.
Magasin de fonctionnalités
Un magasin de caractéristiques est un référentiel centralisé qui permet aux scientifiques Données de rechercher et de partager des caractéristiques, et qui garantit aussi que le même code utilisé pour calculer les valeurs des caractéristiques est utilisé pour l’entraînement et l’inférence du modèle. L’implémentation d’un magasin de caractéristiques dans Databricks dépend du fait que votre espace de travail est activé pour le catalogue Unity ou non. Dans les espaces de travail activés pour le catalogue Unity, toute table Delta sert de table de caractéristiques et Unity Catalog agit comme une étape distincte pour inscrire une table en tant que table de caractéristiques. Les espaces de travail qui ne sont pas activés pour le catalogue Unity ont accès au magasin de caractéristiques d’espace de travail.
Le machine learning utilise des données existantes pour créer un modèle afin de prédire les résultats futurs. Dans presque tous les cas, les données brutes nécessitent un prétraitement et une transformation avant de pouvoir être utilisées pour créer un modèle. Ce processus est appelé ingénierie des caractéristiques, et les sorties de ce processus sont appelées « caractéristiques » : ce sont les composants du modèle.
Le développement de caractéristiques est complexe et demande du temps. Une complication supplémentaire est que pour le machine learning, les calculs de caractéristiques doivent être effectués pour l’entraînement du modèle, puis à nouveau quand le modèle est utilisé pour faire des prédictions. Ces implémentations peuvent ne pas être effectuées par la même équipe ou à l’aide du même environnement de code, ce qui peut entraîner des retards et des erreurs. En outre, différentes équipes d’une organisation auront souvent des besoins de caractéristiques similaires, mais peuvent ne pas être au courant du travail effectué par d’autres équipes. Un magasin de caractéristiques est conçu pour résoudre ces problèmes.
Tables de caractéristiques
Les caractéristiques sont organisées sous forme de tables de fonctionnalités. Chaque table doit avoir une clé primaire et est soutenue par une table Delta et des métadonnées supplémentaires. Les métadonnées de la table de caractéristiques assurent le suivi des sources de données à partir desquelles une table a été générée et des notebooks et travaux qui ont été créés ou écrits dans la table.
Avec Databricks Runtime 13.3 LTS et versions ultérieures, si votre espace de travail est activé pour Unity Catalog, vous pouvez utiliser n’importe quelle table Delta dans Unity Catalog avec une clé primaire comme table de fonctionnalités. Consultez Utiliser des tables de caractéristiques. Les tables de fonctionnalités qui sont stockées dans le magasin de fonctionnalités de l'espace de travail local sont appelées « tables de fonctionnalités de l'espace de travail ». Consultez Utiliser des tables de caractéristiques dans le magasin de caractéristiques de l’espace de travail.
Les caractéristique d’une table de caractéristiques sont généralement calculées et mises à jour à l’aide d’une fonction de calcul commune.
Vous pouvez publier une table de caractéristiques dans un magasin en ligne pour une inférence de modèle en temps réel.
FeatureLookup
De nombreux modèles différents peuvent utiliser les fonctionnalités d’un tableau de fonctionnalités particulier, et tous les modèles n’auront pas besoin de toutes les fonctionnalités. Pour entraîner un modèle à l'aide de fonctionnalités, vous créez une FeatureLookup pour chaque table de fonctionnalités. Le FeatureLookup spécifie les fonctionnalités à utiliser à partir de la table et définit également les clés à utiliser pour joindre la table de fonctionnalités aux données d'étiquette transmises à create_training_set.
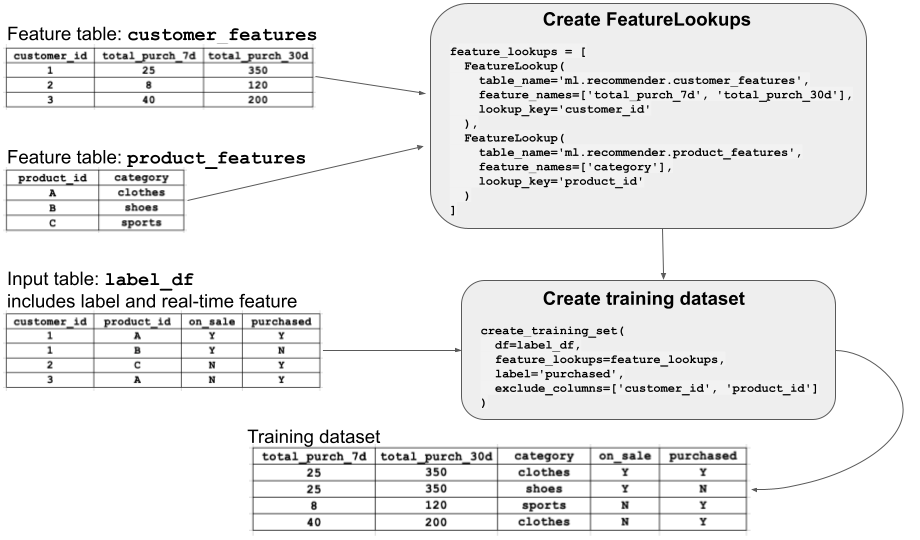
Le diagramme illustre le fonctionnement d'un FeatureLookup. Dans cet exemple, vous souhaitez entraîner un modèle à l'aide des fonctionnalités de deux tables de fonctionnalités, customer_features et product_features. Vous créez un FeatureLookup pour chaque table de fonctionnalités, en spécifiant le nom de la table, les fonctionnalités (colonnes) à sélectionner dans la table et la clé de recherche à utiliser lors de la jointure des fonctionnalités pour créer un ensemble de données d'entraînement.
Vous appelez ensuite create_training_set, également indiqué dans le diagramme. Cet appel d'API spécifie le DataFrame qui contient les données d'entraînement brutes (label_df), le FeatureLookups à utiliser et label, une colonne qui contient la vérité terrain. Les données d'entraînement doivent contenir une ou plusieurs colonnes correspondant à chacune des clés primaires des tables de fonctionnalités. Les données des tables de fonctionnalités sont jointes au DataFrame d'entrée en fonction de ces clés. Le résultat est affiché dans le diagramme sous le nom « Ensemble de données de formation ».
FeatureFunction
Une caractéristique peut dépendre des informations disponibles uniquement au moment de l’inférence. Vous pouvez spécifier un FeatureFunction qui combine des entrées en temps réel avec des valeurs de caractéristique pour calculer des valeurs de caractéristique à jour. Un exemple est illustré dans le diagramme. Pour plus d’informations, consultez fonctionnalités de calcul à la demande à l’aide de fonctions définies par l’utilisateur Python.

Jeu d’apprentissage
Un jeu d’apprentissage se compose d’une liste de caractéristiques et d’une table contenant des données d’apprentissage brutes, des étiquettes et des clés primaires selon lesquelles rechercher des caractéristiques. Vous créez le jeu d’apprentissage en spécifiant les caractéristiques à extraire de Feature Store et fournissez le jeu d’apprentissage en tant qu’entrée lors de l’entraînement du modèle.
Voir Créer un jeu de données d'apprentissage pour obtenir un exemple de création et d'utilisation d'un jeu d'apprentissage.
Lorsque vous entraînez et journalisez un modèle à l’aide de l’ingénierie de caractéristiques dans le catalogue Unity, vous pouvez afficher la traçabilité du modèle dans l’Explorateur de catalogues. Les tables et fonctions utilisées pour créer le modèle sont automatiquement suivies et affichées. Consultez gouvernance et traçabilité des fonctionnalités.
Tables de caractéristiques de série chronologique (recherches ponctuelles dans le temps)
Les données utilisées pour effectuer l’apprentissage d’un modèle intègrent souvent des dépendances temporelles. Lorsque vous générez le modèle, vous ne devez prendre en compte que les valeurs de caractéristiques précédant l’heure de la valeur cible observée. Si vous effectuez l’apprentissage sur des caractéristiques basées sur des données mesurées après l’horodatage de la valeur cible, les performances du modèle peuvent s’en trouver dégradées.
Les tables de caractéristiques de séries chronologiques incluent une colonne d’horodatage qui garantit que chaque ligne du jeu de données d’apprentissage représente les dernières valeurs de caractéristiques connues à partir de l’horodatage de la ligne. Utilisez systématiquement des tables de caractéristiques de séries chronologiques si les valeurs de caractéristiques changent au fil du temps, par exemple avec des données de séries chronologiques, des données basées sur les événements ou des données agrégées dans le temps.
Lorsque vous créez une table de fonctionnalités de série chronologique, vous spécifiez des colonnes liées au temps dans vos clés primaires pour être des colonnes de série chronologique à l’aide de l’argument timeseries_columns (pour l’ingénierie des fonctionnalités dans le catalogue Unity) ou de l’argument timestamp_keys (pour le Magasin de fonctionnalités d’espace de travail). Il permet d’effectuer des recherches à un instant dans le temps avec create_training_set ou score_batch. Le système effectue une jointure à partir de l’horodatage, à l’aide de la clé timestamp_lookup_key indiquée.
Si vous n'utilisez pas l'argument timeseries_columns ou l’argument timestamp_keys et ne désignez qu'une colonne de série chronologique comme colonne de clé primaire, Feature Store n'applique pas de logique ponctuelle à la colonne de série chronologique lors des jointures. Au lieu d’établir une correspondance avec toutes les lignes antérieures à l’horodatage, il ne considère que les lignes présentant une correspondance temporelle exacte.
Stockage hors connexion
Le magasin de caractéristiques hors connexion est utilisé pour la découverte des caractéristiques, l’entraînement du modèle et l’inférence par lots. Il contient des tables de caractéristiques matérialisées sous forme de tables Delta.
Magasin en ligne
Une boutique en ligne est une base de données à faible latence utilisée pour l'inférence de modèle en temps réel. Pour obtenir la liste des magasins en ligne pris en charge par Azure Databricks, consultez Magasins tiers en ligne.
Diffusion en continu
En plus des écritures par lots, Databricks Feature Store prend en charge la diffusion en continu (streaming). Vous pouvez écrire les valeurs des caractéristiques dans une table de caractéristiques à partir d'une source de streaming, et le code de calcul des caractéristiques peut utiliser Structured Streaming pour transformer les flux de données brutes en caractéristiques.
Vous pouvez également diffuser en continu des tableaux de caractéristiques du magasin hors ligne vers un magasin en ligne.
Empaquetage de modèle
Lorsque vous entraînez un modèle Machine Learning à l’aide de l’ingénierie de caractéristiques dans le catalogue Unity ou le magasin de caractéristiques d’espace de travail et que vous le journalisez à l’aide de la méthode log_model() du client, le modèle conserve les références à ces caractéristiques. Au moment de l’inférence, le modèle peut éventuellement récupérer automatiquement des valeurs de caractéristique. L’appelant doit uniquement fournir la clé primaire des caractéristiques utilisées dans le modèle (par exemple, user_id), et le modèle récupère toutes les valeurs de caractéristique requises.
Dans l’inférence par lots, les valeurs des caractéristiques sont extraites du magasin hors connexion et jointes aux nouvelles données avant le scoring. Dans l’inférence en temps réel, les valeurs des caractéristiques sont récupérées à partir du magasin en ligne.
Pour empaqueter un modèle avec des métadonnées de fonctionnalité, utilisez FeatureEngineeringClient.log_model (pour l’ingénierie des fonctionnalités dans le catalogue Unity) ou FeatureStoreClient.log_model (pour le Magasin de fonctionnalités d’espace de travail).