Objets de base de données dans Azure Databricks
Azure Databricks utilise deux objets sécurisables principaux pour stocker les données et y accéder.
- Les tables régissent l’accès aux données tabulaires.
- Les volumes régissent l’accès aux données non tabulaires.
Cet article décrit comment ces objets de base de données sont liés aux catalogues, schémas, vues et autres objets de base de données dans Azure Databricks. Cet article fournit également une présentation générale du fonctionnement des objets de base de données dans le contexte de l’architecture globale de la plateforme.
Que sont les objets de base de données dans Azure Databricks ?
Les objets de base de données sont des entités qui vous aident à organiser, à accéder et à régir les données. Azure Databricks utilise une hiérarchie à trois niveaux pour organiser les objets de base de données :
- Catalogue : conteneur de niveau supérieur qui contient des schémas. Consultez En quoi consistent les catalogues dans Azure Databricks ?
- Schéma ou base de données : contient des objets de données. Consultez En quoi consistent les schémas dans Azure Databricks ?
- Les objets de données pouvant être contenus dans un schéma :
- Volume : volume logique de données non tabulaires dans le stockage d’objets cloud. Consultez Présentation des volumes Unity Catalog.
- Table : collection de données organisées par lignes et colonnes. Consultez Qu’est-ce qu’une table ?.
- Vue : requête enregistrée sur une ou plusieurs tables. Qu’est-ce qu’une vue ?
- Fonction : logique enregistrée qui retourne une valeur scalaire ou un ensemble de lignes. Consultez les Fonctions définies par l’utilisateur (UDF) dans Unity Catalog.
- Modèle : modèle Machine Learning empaqueté avec MLflow. Consultez Gérer le cycle de vie des modèles dans Unity Catalog.
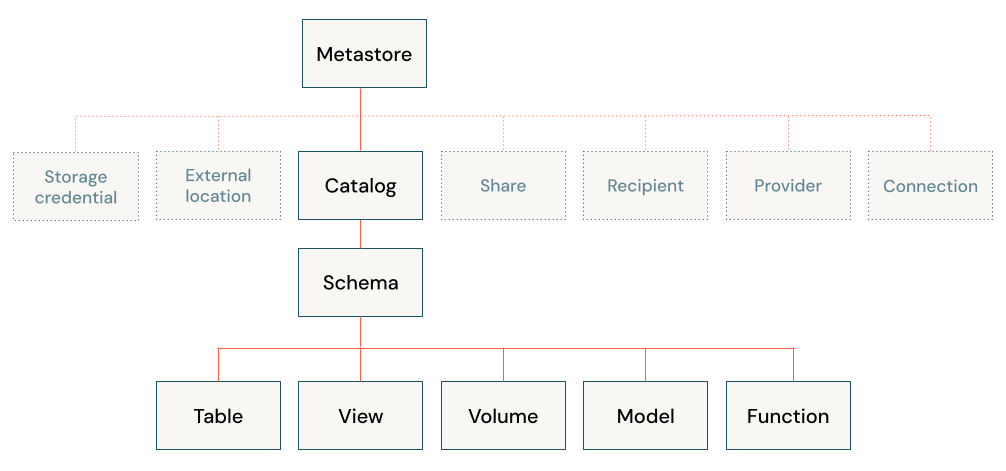
Les catalogues sont inscrits dans un metastore géré au niveau du compte. Seuls les administrateurs interagissent directement avec le metastore. Voir Metastores.
Azure Databricks fournit des ressources supplémentaires pour l’utilisation des données, qui sont toutes régies à l’aide de contrôles d’accès au niveau de l’espace de travail ou de Unity Catalog, la solution de gouvernance des données Databricks :
- Ressources de données au niveau de l’espace de travail, telles que les notebooks, les travaux et les requêtes.
- Objets sécurisables Unity Catalog, tels que les informations d’identification de stockage et les partages Delta Sharing, qui contrôlent principalement l’accès au stockage ou au partage sécurisé.
Pour plus d’informations, consultez Objets de base de données et ressources de données sécurisables de l’espace de travail et Informations d’identification sécurisables Unity Catalog.
Gestion de l’accès aux objets de base de données à l’aide de Unity Catalog
Vous pouvez accorder et révoquer l’accès aux objets de base de données à n’importe quel niveau de la hiérarchie, y compris le metastore lui-même. L’accès à un objet accorde implicitement le même accès à tous les enfants de cet objet, sauf si l’accès est révoqué.
Vous pouvez utiliser les commandes SQL ANSI classiques pour accorder et révoquer l’accès aux objets dans Unity Catalog. Vous pouvez également utiliser l’Explorateur de catalogues pour la gestion pilotée par l’interface utilisateur des privilèges d’objet de données.
Pour plus d’informations sur la sécurisation des objets dans Unity Catalog, consultez Objets sécurisables dans Unity Catalog.
Autorisations d’objet par défaut dans Unity Catalog
Selon la façon dont votre espace de travail a été créé et activé pour Unity Catalog, vos utilisateurs peuvent disposer d’autorisations par défaut sur des catalogues approvisionnés automatiquement, y compris le catalogue main ou le catalogue d’espaces de travail (<workspace-name>). Pour plus d’informations, consultez la section Privilèges utilisateur par défaut.
Si votre espace de travail a été activé manuellement pour Unity Catalog, il inclut un schéma par défaut nommé default, dans le catalogue main, accessible à tous les utilisateurs de votre espace de travail. Si votre espace de travail a été activé automatiquement pour Unity Catalog et inclut un catalogue <workspace-name>, celui-ci contient un schéma nommé default, accessible à tous les utilisateurs de votre espace de travail.
Objets de base de données et ressources de données sécurisables de l’espace de travail
Azure Databricks vous permet de gérer plusieurs ressources d’engineering données, d’analyse, ML et IA en même temps que vos objets de base de données. Vous n’inscrivez pas ces ressources de données dans Unity Catalog. Au lieu de cela, ces ressources sont gérées au niveau de l’espace de travail, à l’aide de listes de contrôle pour régir les autorisations. Ces ressources de données incluent les éléments suivants :
- Blocs-notes
- Tableaux de bord
- Tâches
- Pipelines
- Fichiers d’espace de travail
- Requêtes SQL
- Expériences
La plupart des ressources de données contiennent une logique qui interagit avec des objets de base de données pour interroger des données, utiliser des fonctions, inscrire des modèles ou d’autres tâches courantes. Pour en savoir plus sur la sécurisation des ressources de données d’espace de travail, consultez Listes de contrôle d’accès.
Remarque
L’accès au calcul est régi par les listes de contrôle d’accès. Vous configurez le calcul avec un mode d’accès et pouvez ajouter des autorisations cloud, qui contrôlent la façon dont les utilisateurs peuvent accéder aux données. Databricks recommande d’utiliser des stratégies de calcul et de restreindre les privilèges de création de cluster en tant que meilleure pratique de gouvernance des données. Voir Modes d’accès aux fichiers.
Informations d’identification et infrastructure sécurisables Unity Catalog
Unity Catalog gère l’accès au stockage d’objets cloud, au partage de données et à la fédération des requêtes à l’aide d’objets sécurisables inscrits au niveau du metastore. Voici de brèves descriptions de ces objets sécurisables autres que des données.
Connexion de Unity Catalog au stockage d’objets cloud
Vous devez définir des informations d’identification de stockage et des emplacements externes pour créer un emplacement de stockage managé ou inscrire des tables externes ou des volumes externes. Ces objets sécurisables sont inscrits dans Unity Catalog :
- Informations d’identification de stockage : informations d’identification cloud à long terme qui permettent d’accéder au stockage cloud.
- Emplacement externe : référence à un chemin de stockage d’objets cloud accessible à l’aide des informations d’identification de stockage jumelées.
Consultez Se connecter au stockage d’objets cloud à l’aide de Unity Catalog.
Delta Sharing
Azure Databricks inscrit les objets sécurisables Delta Sharing suivants dans Unity Catalog :
- Partage : collection en lecture seule de tables, de volumes et d’autres ressources de données.
- Fournisseur : organisation ou entité qui partage des données. Dans le modèle de partage Databricks à Databricks, le fournisseur est inscrit dans le metastore Unity Catalog du destinataire en tant qu’entité unique identifiée par son ID de metastore.
- Destinataire : entité qui reçoit des partages d’un fournisseur. Dans le modèle de partage Databricks à Databricks, le destinataire est identifié auprès du fournisseur par son ID de metastore unique.
Consultez Présentation de Delta Sharing.
Lakehouse Federation
Lakehouse Federation vous permet de créer des catalogues étrangers pour fournir un accès en lecture seule aux données résidant dans d’autres systèmes tels que PostgreSQL, MySQL et Snowflake. Vous devez définir une connexion au système externe pour créer des catalogues étrangers.
Connexion : objet Unity Catalog sécurisable qui spécifie un chemin et des informations d’identification pour accéder à un système de base de données externe dans un scénario Lakehouse Federation.
Consultez Qu’est-ce que Lakehouse Federation ?.
Emplacements de stockage managé pour les volumes et tables managés
Lorsque vous créez des tables et des volumes Azure Databricks, vous avez le choix de les gérer ou de les rendre externes. Unity Catalog gère l’accès aux tables et volumes externes à partir d’Azure Databricks, mais ne contrôle pas les fichiers sous-jacents ni gère entièrement l’emplacement de stockage de ces fichiers. Les tables et volumes managés, d’autre part, sont entièrement gérés par Unity Catalog et sont stockés dans un emplacement de stockage managé associé au schéma conteneur. Consultez Spécifier un emplacement de stockage managé dans Unity Catalog.
Databricks recommande des volumes managés et des tables managées pour la plupart des charges de travail, car elles simplifient la configuration, l’optimisation et la gouvernance.
Comparaison entre Unity Catalog et metastore Hive hérité
Databricks recommande d’utiliser Unity Catalog pour inscrire et régir tous les objets de base de données, mais fournit également une prise en charge héritée du metastore Hive pour la gestion des schémas, des tables, des vues et des fonctions.
Si vous interagissez avec des objets de base de données inscrits à l’aide du metastore Hive, consultez Objets de base de données dans le metastore Hive hérité.