API Databricks Foundation Model
Cet article offre une vue d’ensemble des API Foundation Model d’Azure Databricks. Il traite des exigences d’utilisation, des modèles pris en charge et des limitations.
En quoi consistent les API Databricks Foundation Model ?
Le service de modèle Databricks prend désormais en charge les API Foundation Model qui vous permettent d’accéder à des modèles ouverts de pointe et de les interroger à partir d’un point de terminaison de service. Grâce aux API Foundation Model, vous pouvez générer avec rapidité et simplicité des applications qui tirent profit d’un modèle d’IA générative de haute qualité sans conserver votre propre modèle de déploiement.
Les API Foundation Model sont fournies selon deux modes de tarification :
- Paiement par jeton : façon la plus simple d’accéder aux modèles de base Foundation Model sur Databricks et mode recommandé pour commencer votre aventure avec des API Foundation Model. Ce mode n’est pas conçu pour les applications à haut débit ou les charges de travail de production performantes.
- Débit approvisionné : ce mode est recommandé pour toutes les charges de travail de production, en particulier celles qui nécessitent un débit élevé, des garanties de performances, des modèles affinés ou des exigences de sécurité supplémentaires. Les points de terminaison de débit approvisionné sont disponibles avec des certifications de conformité telles que HIPAA.
Pour plus d’informations sur l’utilisation de ces deux modes et ses modèles pris en charge, consultez Utiliser les API Foundation Model.
Grâce aux API Foundation Model, vous pouvez :
- Interroger un LLM généralisé pour vérifier la validité d’un projet avant de faire appel à davantage de ressources.
- Interroger un LLM généralisé afin de créer une preuve de concept rapide pour une application basée sur un LLM avant d’investir dans l’apprentissage et le déploiement d’un modèle personnalisé.
- Utiliser un modèle de fondation, ainsi qu’une base de données vectorielle, pour créer un chatbot utilisant la génération augmentée de récupération (RAG).
- Remplacer les modèles propriétaires par des alternatives libres de droits afin d’optimiser les coûts et les performances.
- Comparez efficacement les LLM pour déceler le meilleur candidat pour votre cas d’usage, ou échangez un modèle de production contre un modèle plus performant.
- Générez une application LLM de développement ou de production en plus d’une solution de service LLM évolutive dotée d’un contrat de niveau de service pouvant gérer vos pics de trafic de production.
Exigences
- Jeton d’API Databricks pour authentifier les demandes du point de terminaison.
- Calcul serverless (pour les modèles avec débit provisionné).
- Un espace de travail dans une région prise en charge :
Remarque
Pour connaître les charges de travail de débit approvisionné qui utilisent le modèle de base DBRX, consultez Limites des API Foundation Model pour la disponibilité de la région.
Utiliser les API Foundation Model
Vous pouvez interroger les API Foundation Model à l’aide de plusieurs méthodes.
Les API sont compatibles avec OpenAI. Vous pouvez donc également utiliser le client OpenAI pour l’interrogation. Vous pouvez également utiliser l’interface utilisateur, le kit de développement logiciel (SDK) Python des API Foundation Model, le kit de développement logiciel (SDK) des déploiements MLflow ou l’API REST pour interroger des modèles pris en charge. Databricks recommande d’utiliser le kit de développement logiciel (SDK) des déploiements MLflow ou l’API REST pour les interactions étendues et l’interface utilisateur pour essayer la fonctionnalité.
Consultez Interroger les modèles de base pour obtenir des exemples de scoring.
API Foundation Model avec paiement par jeton
Important
Cette fonctionnalité est disponible en préversion publique.
Les modèles de paiement par jeton sont accessibles dans votre espace de travail Azure Databricks et sont recommandés pour commencer. Pour y accéder dans votre espace de travail, accédez à l’onglet Service dans la barre latérale gauche. Les API Foundation Model se trouvent en haut de la liste des points de terminaison.
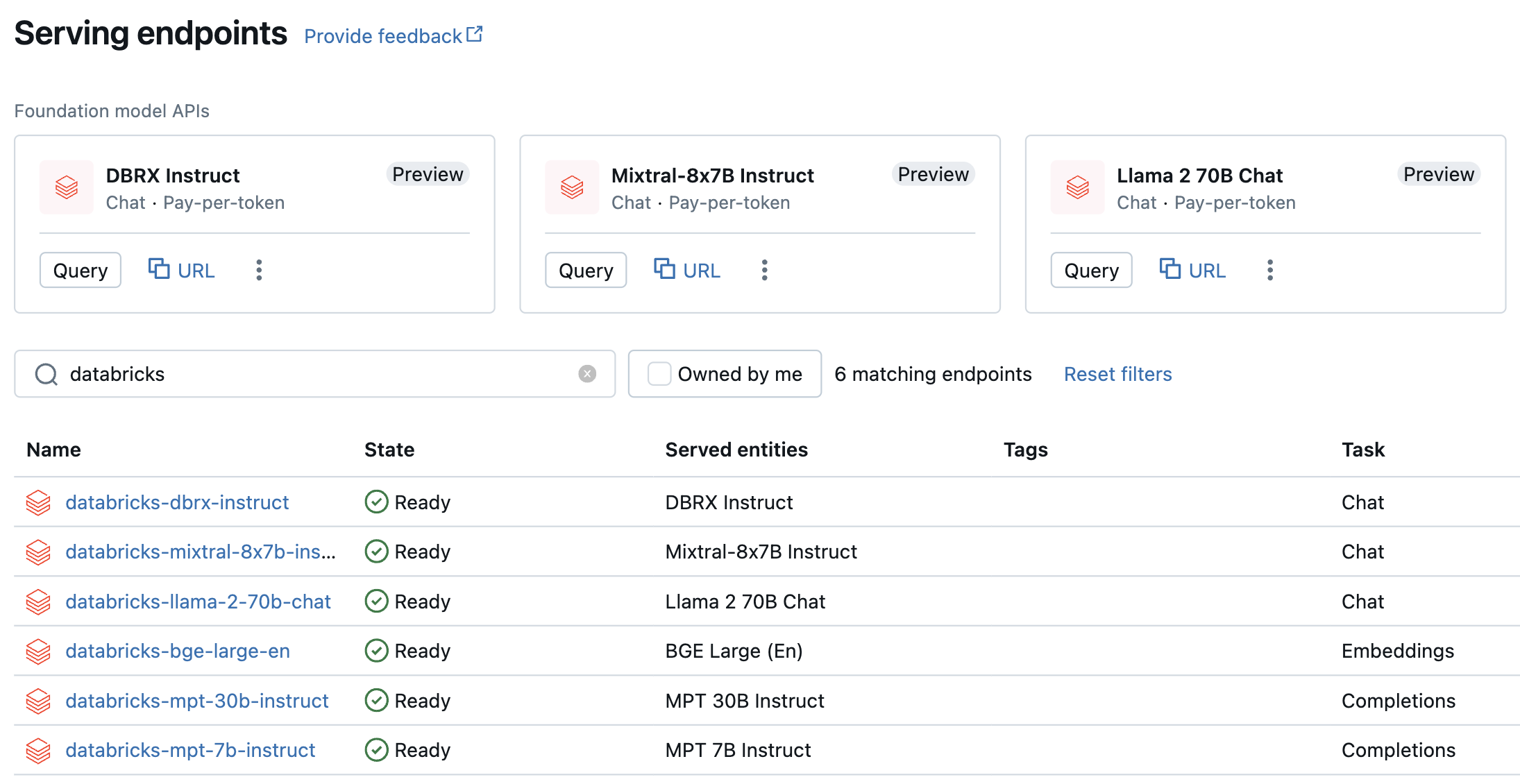
Le tableau suivant résume les modèles pris en charge pour le paiement par jeton. Consultez les modèles pris en charge pour le paiement par jeton pour obtenir des informations supplémentaires sur le modèle.
Si vous souhaitez tester et avoir une conversation avec ces modèles, vous pouvez le faire en utilisant le terrain de jeu de l’IA (AI Playground). Consultez Conversation avec des LLM pris en charge en utilisant AI Playground.
| Modèle | Type de tâche | Point de terminaison |
|---|---|---|
| DBRX Instruct | Converser | databricks-dbrx-instruct |
| Meta-Llama-3-70B-Instruct | Converser | databricks-meta-llama-3-70b-instruct |
| Meta-Llama-2-70B-Chat | Converser | databricks-llama-2-70b-chat |
| Instruire Mixtral-8x7B | Conversation instantanée | databricks-mixtral-8x7b-instruct |
| Instruction MPT 7B | Completion | databricks-mpt-7b-instruct |
| Instruction MPT 30B | Completion | databricks-mpt-30b-instruct |
| BGE Large (anglais) | Intégration | databricks-bge-large-en |
- Consultez Interroger les modèles de base pour obtenir de l’aide sur la façon d’interroger les API Foundation Model.
- Consultez les Informations de référence sur les API REST Foundation Model pour connaître les paramètres et la syntaxe nécessaires.
API Foundation Model avec débit approvisionné
Le débit approvisionné est généralement disponible et Databricks recommande le débit approvisionné pour les charges de travail de production. Le débit approvisionné fournit des points de terminaison avec une inférence optimisée pour les charges de travail de modèles de base qui nécessitent des garanties de performances. Consultez API Foundation Model à débit approvisionné pour obtenir un guide étape par étape sur la manière de déployer les API Foundation Model en mode débit approvisionné.
La prise en charge du débit approvisionné comprend les éléments suivants :
- Modèles de base de toutes tailles, tels que DBRX Base. Les modèles de base sont accessibles via la Place de marché Databricks, mais vous pouvez également les télécharger à partir de Hugging Face ou d’une autre source externe et les enregistrer dans le catalogue Unity. Cette dernière approche fonctionne avec toutes les variantes finement ajustées des modèles pris en charge, quelle que soit la méthode d’affinage utilisée.
- Variantes affinées de modèles de base, comme LlamaGuard-7B. Cela comprend des modèles affinés sur des données propriétaires.
- Poids et générateurs de jetons entièrement personnalisés, comme ceux entraînés à partir de zéro ou préentraînés, ou autres variantes utilisant l’architecture du modèle de base (par exemple, CodeLlama, Yi-34B-Chat ou SOLAR-10.7B).
Le tableau suivant récapitule les architectures de modèle prises en charge pour le débit approvisionné.
| Architecture du modèle | Types de tâche | Notes |
|---|---|---|
| DBRX | Conversation ou saisie semi-automatique | Consultez Limites des API Foundation Model pour la disponibilité de la région. |
| Meta Llama 3 | Conversation ou saisie semi-automatique | |
| Meta Llama 2 | Conversation ou saisie semi-automatique | |
| Mistral | Conversation ou saisie semi-automatique | |
| Mixtral | Conversation ou saisie semi-automatique | |
| MPT | Conversation ou saisie semi-automatique | |
| BGE v1.5 (anglais) | Intégration |
Limites
Consultez Limites et régions de la mise en service de modèles.