API Foundation Model avec débit approvisionné
Cet article montre comment déployer des API de modèle de fondation avec débit provisionné. Databricks recommande le débit approvisionné pour les charges de travail de production et il offre une inférence optimisée pour les modèles de fondation avec des garanties de performances.
Consultez API Foundation Model à débit approvisionné pour obtenir la liste des architectures de modèle prises en charge.
Spécifications
Consultez les exigences.
Pour déployer des modèles de base affinés,
- Votre modèle doit être enregistré en utilisant MLflow 2.11 ou une version ultérieure, OU de Databricks Runtime 15.0 ML ou une version ultérieure.
- Databricks recommande d’utiliser des modèles dans Le catalogue Unity pour accélérer le chargement et le téléchargement de modèles volumineux.
[Recommandé] Déployer des modèles de base à partir du catalogue Unity
Important
Cette fonctionnalité est disponible en préversion publique.
Databricks recommande d’utiliser les modèles de base préinstallés dans le catalogue Unity. Vous trouverez ces modèles sous le catalogue system dans le ai de schéma (system.ai).
Pour déployer un modèle de base :
- Accédez à
system.aidans l’Explorateur de catalogues. - Cliquez sur le nom du modèle à déployer.
- Sur la page du modèle, cliquez sur le bouton Servir ce modèle.
- La page Créer un point de terminaison de service s’affiche. Consultez Créer votre point de terminaison avec débit provisionné en utilisant l’interface utilisateur.
Déployer des modèles de base à partir de la Place de marché Databricks
Vous pouvez également installer des modèles de base dans le catalogue Unity à partir de Databricks Marketplace.
Vous pouvez rechercher une famille de modèles. Ensuite, dans la page du modèle, vous pouvez sélectionner Obtenir l’accès et indiquer les informations d’identification de connexion pour installer le modèle dans Unity Catalog.
Une fois le modèle installé sur Unity Catalog, vous pouvez créer un point de terminaison de service de modèle en utilisant l’interface utilisateur de service.
Déployer des modèles DBRX
Databricks recommande la mise en service du modèle DBRX Instruct pour vos charges de travail. Pour servir le modèle DBRX Instruct à l’aide d’un débit provisionné, suivez les instructions de [Recommandé] Déployer des modèles de base à partir du catalogue Unity.
Lors de la mise en service de ces modèles DBRX, le débit approvisionné prend en charge une longueur maximale de contexte de 16 k.
Les modèles DBRX utilisent l’invite système par défaut suivante pour garantir la pertinence et la précision des réponses du modèle :
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Enregistrer des modèles de base optimisés
Si vous ne pouvez pas utiliser les modèles dans le schéma system.ai ou installer des modèles à partir de la Place de marché Databricks, vous pouvez déployer un modèle de base affiné en le connectant au catalogue Unity. L’exemple suivant montre comment configurer votre code pour enregistrer un modèle MLflow dans Unity Catalog :
mlflow.set_registry_uri('databricks-uc')
CATALOG = "ml"
SCHEMA = "llm-catalog"
MODEL_NAME = "mpt" # or "bge"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Vous pouvez enregistrer votre modèle à l’aide de la saveur MLflow transformers et spécifier l’argument de la tâche au moyen de l’interface de type de modèle appropriée à partir des options suivantes :
task="llm/v1/completions"task="llm/v1/chat"task="llm/v1/embeddings"
Ces arguments spécifient la signature d’API utilisée pour le point de terminaison de service de modèle, tandis que les modèles enregistrés de cette façon sont éligibles au débit provisionné.
Les modèles enregistrés à partir du package sentence_transformers prennent également en charge la définition du type de point de terminaison "llm/v1/embeddings".
Pour les modèles enregistrés à l’aide de MLflow 2.12 (ou une version ultérieure), l’argument log_model task définit automatiquement la valeur de la clé metadata task. Si les arguments task et metadata task sont définis sur des valeurs différentes, un argument Exception est déclenché.
Voici l’exemple d’un enregistrement de modèle de langage de saisie semi-automatique à l’aide de MLflow 2.12 ou une version ultérieure :
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct",torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
task="llm/v1/completions",
registered_model_name=registered_model_name
)
Pour les modèles enregistrés en utilisant MLflow 2.11 ou une version ultérieure, vous pouvez spécifier l’interface du point de terminaison en utilisant les valeurs de métadonnées suivantes :
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Voici l’exemple d’un enregistrement de modèle de langage de saisie semi-automatique en utilisant MLflow 2.11 ou une version ultérieure :
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct",torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
task="llm/v1/completions",
metadata={"task": "llm/v1/completions"},
registered_model_name=registered_model_name
)
Le débit provisionné prend également en charge le petit et le grand modèle d’incorporation BGE. Voici l’exemple d’un enregistrement de modèle BAAI/bge-small-en-v1.5 pour qu’il puisse être servi avec un débit approvisionné en utilisant MLflow 2.11 ou une version ultérieure :
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-small-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="bge-small-transformers",
task="llm/v1/embeddings",
metadata={"task": "llm/v1/embeddings"}, # not needed for MLflow >=2.12.1
registered_model_name=registered_model_name
)
Lors de l’enregistrement d’un modèle BGE affiné, vous devez également spécifier la clé de métadonnées model_type :
metadata={
"task": "llm/v1/embeddings",
"model_type": "bge-large" # Or "bge-small"
}
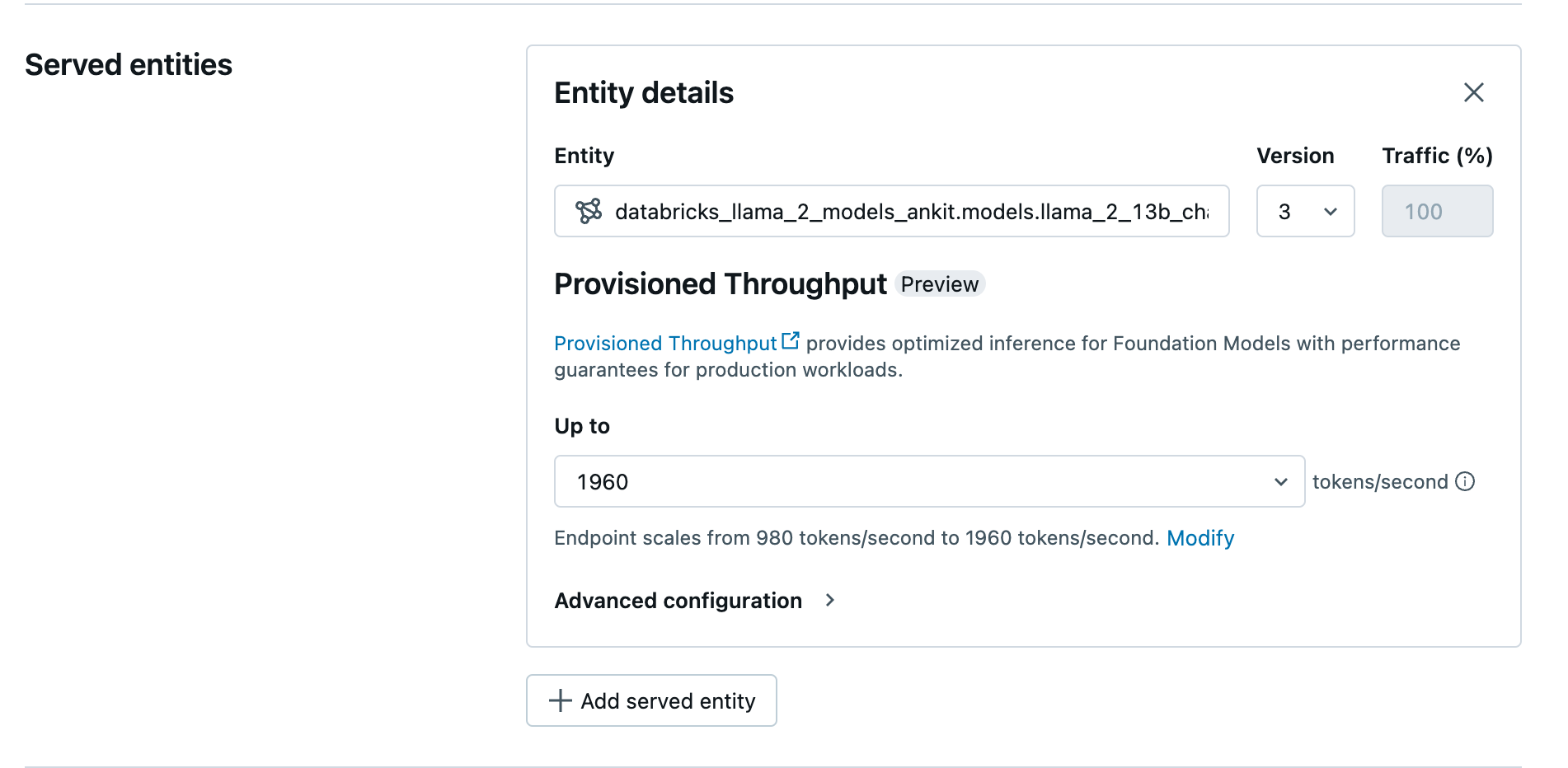
Créer votre point de terminaison avec débit provisionné en utilisant l’interface utilisateur
Une fois le modèle enregistré dans Unity Catalog, créez un point de terminaison de service avec débit provisionné en procédant comme suit :
- Accédez à l’interface utilisateur de service dans votre espace de travail.
- Sélectionnez Créer un point de terminaison de service.
- Dans le champ Entité, sélectionnez votre modèle dans Unity Catalog. Pour les modèles éligibles, l’interface utilisateur de l’entité servie affiche l’écran Débit provisionné.
- Dans la liste déroulante Jusqu’à, vous pouvez configurer le débit maximal en jetons par seconde pour votre point de terminaison.
- Les points de terminaison avec débit provisionné sont automatiquement mis à l’échelle : vous pouvez donc sélectionner Modifier pour voir le nombre minimal de jetons par seconde auquel votre point de terminaison peut descendre.
Créer votre point de terminaison avec débit provisionné en utilisant l’API REST
Pour déployer votre modèle en mode de débit provisionné en utilisant l’API REST, vous devez spécifier des champs min_provisioned_throughput et max_provisioned_throughput dans votre requête.
Pour identifier la plage appropriée de débit provisionné pour votre modèle, consultez Obtenir le débit provisionné par incréments.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Obtenir le débit provisionné par incréments
Le débit provisionné est disponible par incréments de jetons par seconde, les incréments spécifiques variant selon le modèle. Pour identifier la plage appropriée à vos besoins, Databricks recommande d’utiliser l’API d’informations d’optimisation du modèle au sein de la plateforme.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Voici un exemple de réponse de l’API :
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Exemples de Notebook
Les carnets de notes suivants montrent des exemples de création d’une API de modèle de fondation à débit approvisionné :
Débit approvisionné pour la mise en service du notebook de modèle Llama2
Débit approvisionné pour la mise en service du notebook de modèle Mistral
Mise en service de débit provisionné pour un notebook de modèle BGE
Limites
- Le modèle de déploiement peut échouer en raison de problèmes de capacité du GPU, ce qui entraîne un dépassement du délai d’expiration lors de la création ou de la mise à jour du point de terminaison. Contactez l’équipe de votre compte Databricks afin d’obtenir de l’aide pour la résolution du problème.
- La mise à l’échelle automatique des API de modèles de fondation est plus lente que la mise à disposition de modèles par l’unité centrale. Databricks recommande le surapprovisionnement pour éviter les expirations des délais d’attente de requête.
Ressources supplémentaires
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour