Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit deux modèles courants pour déplacer des artefacts ML à travers les étapes intermédiaires et vers la production. La nature asynchrone des modifications apportées aux modèles et au code signifie qu’il existe plusieurs modèles possibles qu’un processus de développement ML peut suivre.
Les modèles sont créés par le code, mais les artefacts de modèle résultants et le code qui les ont créés peuvent fonctionner de manière asynchrone. Autrement dit, les nouvelles versions de modèle et les modifications de code peuvent ne pas se produire en même temps. Par exemple, examinons les scénarios suivants :
- Pour détecter les transactions frauduleuses, vous développez un pipeline ML qui réentraîne un modèle chaque semaine. Le code peut ne pas changer très souvent, mais le modèle peut être réentraîné chaque semaine pour incorporer de nouvelles données.
- Vous pouvez créer un réseau neuronal volumineux et profond pour classifier des documents. Dans ce cas, l’entraînement du modèle est fastidieux et coûteux en calcul, et le réentraînement du modèle est susceptible de se produire rarement. Toutefois, le code qui déploie, sert et surveille ce modèle peut être mis à jour sans reformer le modèle.
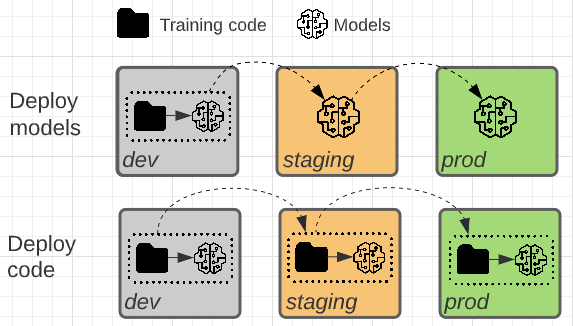
Les deux modèles diffèrent selon que l’artefact de modèle ou le code d’entraînement qui produit l’artefact de modèle est promu vers la production.
Déployer du code (recommandé)
Dans la plupart des cas, Databricks recommande l’approche de « déploiement de code ». Cette approche est incorporée dans le flux de travail MLOps recommandé.
Dans ce modèle, le code permettant d’entraîner des modèles est développé dans l’environnement de développement. Le même code passe à l'environnement de préproduction, puis à la production. Le modèle est formé dans chaque environnement : initialement dans l’environnement de développement dans le cadre du développement de modèle, en préproduction (sur un sous-ensemble limité de données) dans le cadre de tests d’intégration et dans l’environnement de production (sur les données de production complètes) pour produire le modèle final.
Avantages :
- Dans les organisations où l’accès aux données de production est limité, ce modèle permet de former le modèle sur les données de production dans l’environnement de production.
- Le réentraînement de modèle automatisé est plus sûr, car le code d’entraînement est passé en revue, testé et approuvé pour la production.
- Le code de support suit le même schéma que le code d’entraînement du modèle. Les deux passent par des tests d’intégration en préproduction.
Inconvénients :
- La courbe d’apprentissage pour les scientifiques des données de transmettre le code à leurs collaborateurs peut être abrupte. Les modèles de projet et les flux de travail prédéfinis sont utiles.
En outre, dans ce modèle, les scientifiques des données doivent être en mesure d’examiner les résultats de formation de l’environnement de production, car ils ont les connaissances nécessaires pour identifier et résoudre les problèmes spécifiques au ML.
Si votre situation exige que le modèle soit formé en préproduction sur le jeu de données de production complet, vous pouvez utiliser une approche hybride en déployant du code sur la préproduction, en entraînant le modèle, puis en déployant le modèle à la production. Cette approche permet d’économiser les coûts de formation en production, mais ajoute un coût d’opération supplémentaire en préproduction.
Déployer des modèles
Dans ce modèle, le modèle d'artefact est généré par le code d’entraînement dans l’environnement de développement. L’artefact est ensuite testé dans l’environnement intermédiaire avant d’être déployé en production.
Envisagez cette option dans un ou plusieurs des cas suivants :
- L’entraînement de modèle est très coûteux ou difficile à reproduire.
- Tout le travail est effectué dans un seul espace de travail Azure Databricks.
- Vous ne travaillez pas avec des dépôts externes ou un processus CI/CD.
Avantages :
- Un transfert plus simple pour les scientifiques des données
- Dans les cas où l’entraînement du modèle est coûteux, il suffit d’entraîner le modèle une seule fois.
Inconvénients :
- Si les données de production ne sont pas accessibles à partir de l’environnement de développement (ce qui peut être vrai pour des raisons de sécurité), cette architecture peut ne pas être viable.
- L'automatisation du réentraînement de modèles est délicate dans ce schéma. Vous pouvez automatiser la reformation dans l’environnement de développement, mais l’équipe responsable du déploiement du modèle en production peut ne pas accepter le modèle résultant comme prêt pour la production.
- Le code auxiliaire, par exemple les pipelines utilisés pour l'ingénierie des fonctionnalités, l'inférence et le monitoring, doit être déployé séparément dans l'environnement de production.
En général, un environnement (développement, intermédiaire ou production) correspond à un catalogue dans Unity Catalog. Pour plus d’informations sur l’implémentation de ce modèle, consultez le guide de mise à niveau.
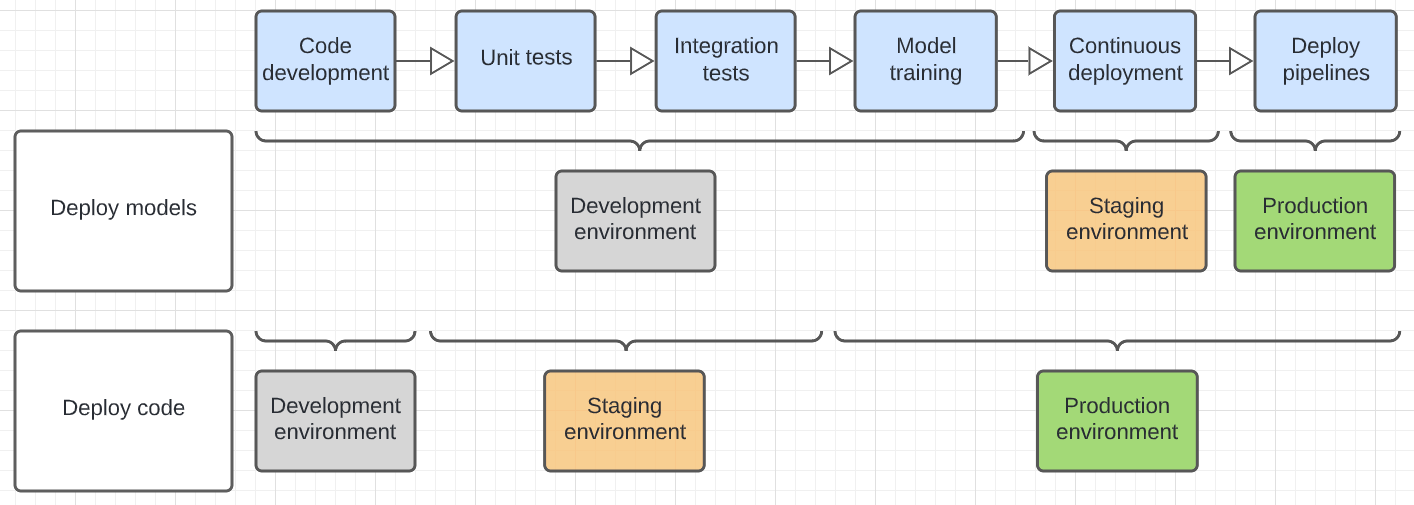
Le diagramme ci-dessous compare le cycle de vie du code pour les modèles de déploiement ci-dessus dans les différents environnements d’exécution.
L’environnement affiché dans le diagramme est l’environnement final dans lequel une étape est exécutée. Par exemple, dans le modèle de déploiement, l’unité finale et les tests d’intégration sont effectués dans l’environnement de développement. Dans le modèle de code de déploiement, les tests unitaires et les tests d’intégration sont exécutés dans les environnements de développement, et les tests d’unité et d’intégration finaux sont effectués dans l’environnement intermédiaire.