Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit comment vous pouvez utiliser MLOps sur la plateforme Databricks pour optimiser les performances et l'efficacité à long terme de vos systèmes de machine learning (ML). Il comprend des recommandations générales pour une architecture MLOps et décrit un flux de travail généralisé utilisant la plateforme Databricks que vous pouvez utiliser comme modèle pour votre processus de développement à la production en machine learning (ML). Pour connaître les modifications de ce flux de travail pour les applications LLMOps, consultez flux de travail LLMOps.
Pour plus d’informations, consultez The Big Book of MLOps.
Qu’est-ce que MLOps ?
MLOps est un ensemble de processus et d’étapes automatisées pour gérer le code, les données et les modèles afin d’améliorer le niveau de performance, la stabilité et l’efficacité à long terme des systèmes de ML. Il combine DevOps, DataOps et ModelOps.
Les ressources ML, telles que le code, les données et les modèles, sont développées en phases, qui vont des premières phases de développement qui n’ont pas de limites d’accès strictes et qui ne sont pas testées rigoureusement, en passant par une phase de test intermédiaire pour finir par une phase de production qui est étroitement contrôlée. La plateforme Databricks vous permet de gérer ces ressources sur une seule plateforme avec un contrôle d'accès unifié. Vous pouvez développer des applications de données et des applications ML sur la même plateforme, ce qui réduit les risques et les retards associés au déplacement des données.
Recommandations générales relatives à MLOps
Cette section contient quelques recommandations générales relatives à MLOps sur Databricks avec des liens redirigeant vers plus d’informations.
Créer un environnement distinct pour chaque phase
Un environnement d’exécution est l’endroit où les modèles et les données sont créés ou consommés par le code. Chaque environnement d’exécution se compose d’instances de calcul, de runtimes et de bibliothèques, et de travaux automatisés.
Databricks recommande de créer des environnements distincts pour les différentes phases de développement du code et du modèle ML avec des transitions clairement définies entre les phases. Le workflow décrit dans cet article suit ce processus avec les noms courants pour les phases :
D’autres configurations peuvent également être utilisées pour répondre aux besoins spécifiques de votre organisation.
Contrôle d’accès et versioning
Le contrôle d’accès et le versioning sont des composants clés de tout processus d’opérations logicielles. Databricks recommande les éléments suivants :
- Utiliser Git pour la gestion de versions. Les pipelines et le code doivent être stockés dans Git pour la gestion de versions. La progression de la logique ML d’une phase à l’autre peut être interprétée comme le déplacement du code de la branche de développement vers la branche de préproduction, puis vers la branche de mise en production. Utilisez les dossiers Databricks Git pour l’intégration de votre fournisseur Git et la synchronisation des notebooks et du code source avec les espaces de travail Databricks. Databricks fournit également des outils supplémentaires pour l’intégration git et le contrôle de version ; consultez outils de développement local.
- Stocker les données dans une architecture Lakehouse avec des tables Delta. Les données doivent être stockées dans une architecture Lakehouse dans votre compte cloud. Les données brutes et les tables de caractéristiques doivent être stockées sous forme de tables Delta avec des contrôles d’accès pour déterminer qui peut les lire et les modifier.
- Gérer le développement de modèles avec MLflow. Vous pouvez utiliser MLflow pour suivre le processus de développement de modèles et enregistrer des instantanés de code, des paramètres de modèle, des métriques et autres métadonnées.
- Utiliser des modèles dans Unity Catalog pour gérer le cycle de vie des modèles. Utiliser Modèles dans Unity Catalog pour gérer le contrôle de version, la gouvernance et l’état du déploiement des modèles.
Déployer du code, pas des modèles
Dans la plupart des cas, pendant le processus de développement du ML, Databricks vous recommande promouvoir le code, plutôt que les modèles, d’un environnement à l’autre. Ainsi, le déplacement des ressources de projet garantit que tout le code du processus de développement du ML passe par les mêmes processus de revue et de test d’intégration du code. Il garantit également que la version de production du modèle est formée sur le code de production. Pour une discussion plus détaillée sur les options et les compromis, consultez Schémas de déploiement de modèles.
Workflow MLOps recommandé
Les sections suivantes décrivent un workflow MLOps typique, couvrant chacune des trois phases : développement, préproduction et production.
Cette section utilise les termes « scientifique des données » et « ingénieur ML » comme personnages archétypaux. Les rôles et responsabilités spécifiques dans le workflow MLOps varient entre les équipes et les organisations.
Phase de développement
Le point central de la phase de développement est l’expérimentation. Les scientifiques des données développent des caractéristiques et des modèles et procèdent à des expériences pour optimiser les performances des modèles. Le résultat du processus de développement est le code de pipeline ML qui peut comprendre le calcul des caractéristiques, l’entraînement du modèle, l’inférence et la surveillance.
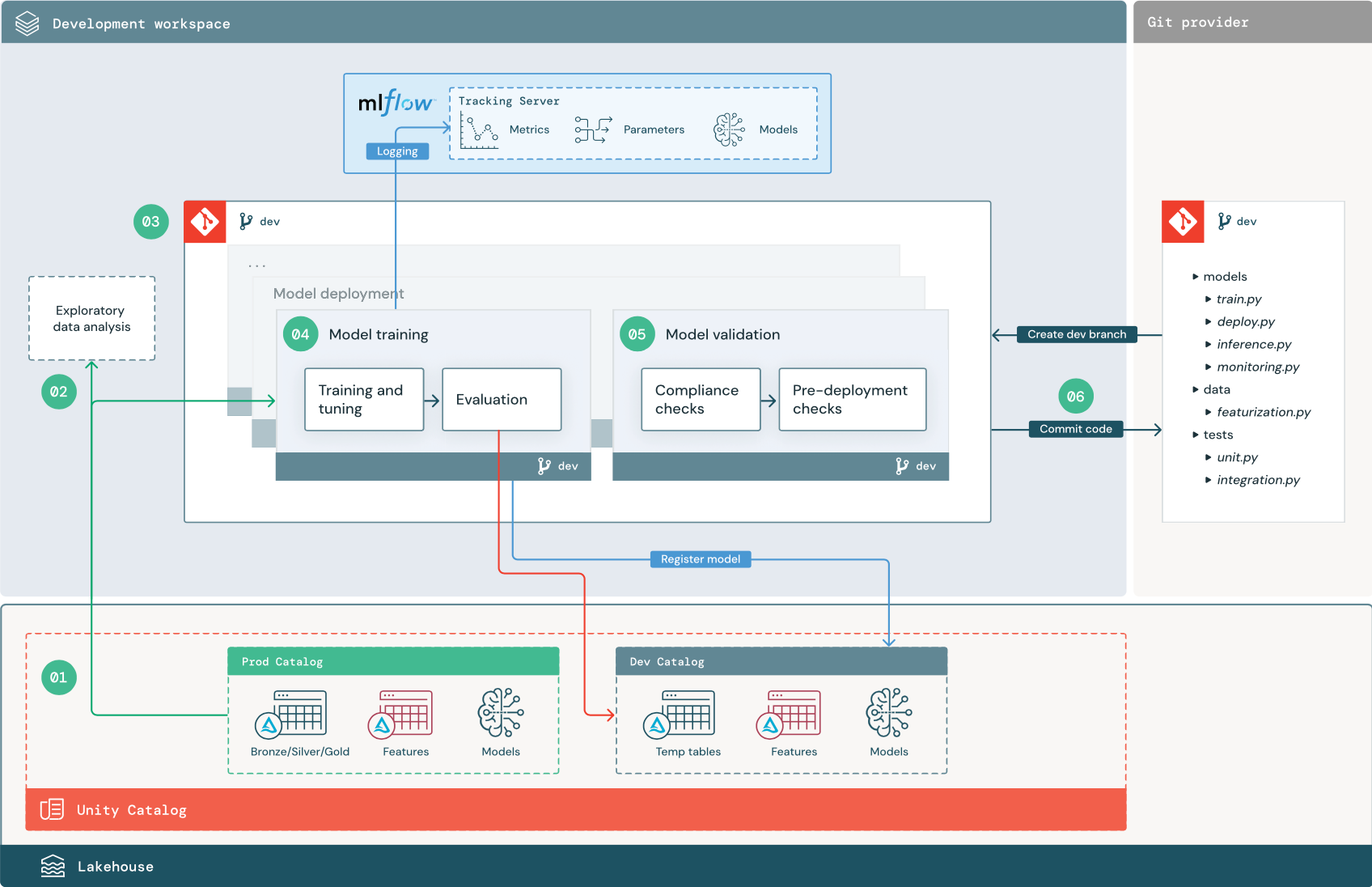
Les étapes numérotées correspondent aux numéros affichés dans le diagramme.
1. Sources de données
L’environnement de développement est représenté par le catalogue de développement dans Unity Catalog. Les scientifiques des données ont un accès en lecture-écriture au catalogue de développement, car ils créent des données temporaires et des tables de caractéristiques dans l’espace de travail de développement. Les modèles créés à l’étape de développement sont inscrits dans le catalogue de développement.
Dans l’idéal, les scientifiques des données travaillant dans l’espace de travail de développement disposent également d’un accès en lecture seule aux données de production dans le catalogue de production. Autoriser les scientifiques des données à accéder en lecture aux données, aux tables d’inférence et aux tables de métriques de production dans le catalogue de production leur permet d’analyser les prédictions et les performances actuelles des modèles de production. Les scientifiques des données doivent également être en mesure de charger des modèles de production à des fins d’expérimentation et d’analyse.
S’il n’est pas possible d’accorder un accès en lecture seule au catalogue de production, un instantané des données de production peut être écrit dans le catalogue de développement pour permettre aux scientifiques des données de développer et d’évaluer le code du projet.
2. Analyse exploratoire des données
Les scientifiques des données explorent et analysent les données dans un processus itératif interactif en utilisant des notebooks. L’objectif est d’évaluer si les données disponibles ont le potentiel nécessaire pour résoudre le problème métier. Dans cette étape, le scientifique des données commence par identifier les étapes de préparation et de caractérisation des données pour l’apprentissage du modèle. Ce processus ad hoc ne fait généralement pas partie d’un pipeline qui sera déployé dans d’autres environnements d’exécution.
AutoML accélère ce processus en générant des modèles de référence pour un jeu de données. AutoML effectue et enregistre un ensemble d’essais, et fournit un notebook Python avec le code source pour chaque exécution d’essai, ce qui vous permet de passer en revue, de reproduire et de modifier le code. AutoML calcule également des statistiques récapitulatives sur votre jeu de données et enregistre ces informations dans un notebook que vous pouvez consulter ultérieurement.
3. Code
Le dépôt de code contient tous les pipelines, modules et autres fichiers projet pour un projet ML. Les scientifiques des données créent des pipelines nouveaux ou mis à jour dans une branche de développement (« dev ») du dépôt du projet. Dès l’analyse exploratoire des données (EDA) et les phases initiales d’un projet, les scientifiques des données doivent travailler dans un dépôt pour partager le code et suivre les modifications.
4. Former le modèle (développement)
Les scientifiques des données développent le pipeline d’apprentissage du modèle dans l’environnement de développement en utilisant des tables provenant des catalogues de développement ou de production.
Ce pipeline comprend 2 tâches :
Entraînement et réglage. Le processus d’apprentissage journalise les paramètres, les métriques et les artefacts du modèle sur le serveur de suivi MLflow. Après l’apprentissage et l’optimisation des hyperparamètres, l’artefact du modèle final est enregistré sur le serveur de suivi pour enregistrer un lien entre le modèle, les données d’entrée sur lesquelles il a effectué l’apprentissage et le code utilisé pour le générer.
Évaluation. Évaluez la qualité du modèle en testant les données conservées. Les résultats de ces tests sont journalisés sur le serveur de suivi MLflow. L’objectif de l’évaluation est de déterminer si le modèle nouvellement développé est plus performant que le modèle de production actuel. Avec des autorisations suffisantes, tout modèle de production inscrit dans le catalogue de production peut être chargé dans l’espace de travail de développement et comparé à un modèle dont l’apprentissage a été nouvellement effectué.
Si les exigences de gouvernance de votre organisation incluent des informations supplémentaires sur le modèle, vous pouvez l’enregistrer à l’aide du suivi MLflow. Les artefacts sont typiquement des descriptions en texte brut et des interprétations de modèle comme les tracés produits par SHAP. Des exigences de gouvernance spécifiques peuvent provenir d’un responsable de la gouvernance des données ou des parties prenantes de l’entreprise.
Le résultat du pipeline d’apprentissage du modèle est un artéfact de modèle ML stocké dans le serveur de suivi MLflow pour l’environnement de développement. Si le pipeline est exécuté dans l’espace de travail intermédiaire ou de production, l’artefact du modèle est stocké dans le serveur de suivi MLflow pour cet espace de travail.
Une fois l’apprentissage du modèle terminé, inscrivez le modèle dans Unity Catalog. Configurez le code de votre pipeline pour inscrire le modèle dans le catalogue correspondant à l’environnement où le pipeline du modèle a été exécuté ; dans cet exemple, c’est le catalogue de développement.
Avec l’architecture recommandée, vous déployez un workflow Databricks multitâche où la première tâche est le pipeline d’apprentissage du modèle, suivie des tâches de validation du modèle et de déploiement du modèle. La tâche d’apprentissage du modèle génère un URI de modèle que la tâche de validation du modèle peut utiliser. Vous pouvez utiliser des valeurs de tâche pour passer cet URI au modèle.
5. Valider et déployer le modèle (développement)
En plus du pipeline d’apprentissage du modèle, d’autres pipelines comme la validation du modèle et les pipelines de déploiement du modèles sont développés dans l’environnement de développement.
Validation du modèle. Le pipeline de validation du modèle prend l’URI du modèle auprès du pipeline d’apprentissage du modèle, charge le modèle depuis Unity Catalog et effectue des contrôles de validation.
Les contrôles de validation dépendent du contexte. Ils peuvent inclure des contrôles de base, comme la vérification du format et des métadonnées requises, et des contrôles plus complexes qui peuvent être obligatoires pour les secteurs avec des réglementations fortement contraignantes, comme des contrôles de conformité prédéfinis et la vérification des performances du modèle sur des tranches de données sélectionnées.
La fonction principale du pipeline de validation du modèle est de déterminer si un modèle doit passer à l’étape de déploiement. Si le modèle passe les contrôles de prédéploiement, l’alias « Challenger » peut lui être affecté dans Unity Catalog. Si les contrôles échouent, le processus se termine. Vous pouvez configurer votre workflow pour avertir les utilisateurs d’un échec de validation. Consultez la section Ajouter des notifications sur un travail.
Déploiement du modèle. Le pipeline de déploiement du modèle promeut souvent directement le modèle « Challenger » nouvellement entraîné au statut de « Champion » par mise à jour d'alias, ou facilite une comparaison entre le modèle « Champion » existant et le nouveau modèle « Challenger ». Ce pipeline peut également configurer n’importe quelle infrastructure d’inférence requise, comme des points de terminaison de service de modèle. Pour une présentation détaillée des étapes impliquées dans le pipeline de déploiement de modèle, consultez Production.
6. Valider le code
Après avoir développé le code pour l’apprentissage, la validation, le déploiement et d’autres pipelines, le scientifique des données ou l’ingénieur ML valide les modifications apportées à la branche de développement dans le contrôle de code source.
Phase de mise en scène
Le point central de cette phase consiste à tester le code du pipeline ML pour s’assurer qu’il est prêt pour la production. L’ensemble du code du pipeline ML est testé au cours de cette phase, notamment le code pour l’entraînement du modèle ainsi que les pipelines d’ingénierie de caractéristiques, le code d’inférence, etc.
Les ingénieurs ML créent un pipeline CI pour implémenter les tests unitaires et d’intégration exécutés dans cette phase. Le résultat du processus de préproduction est une branche de mise en production qui déclenche le système CI/CD pour démarrer la phase de production.
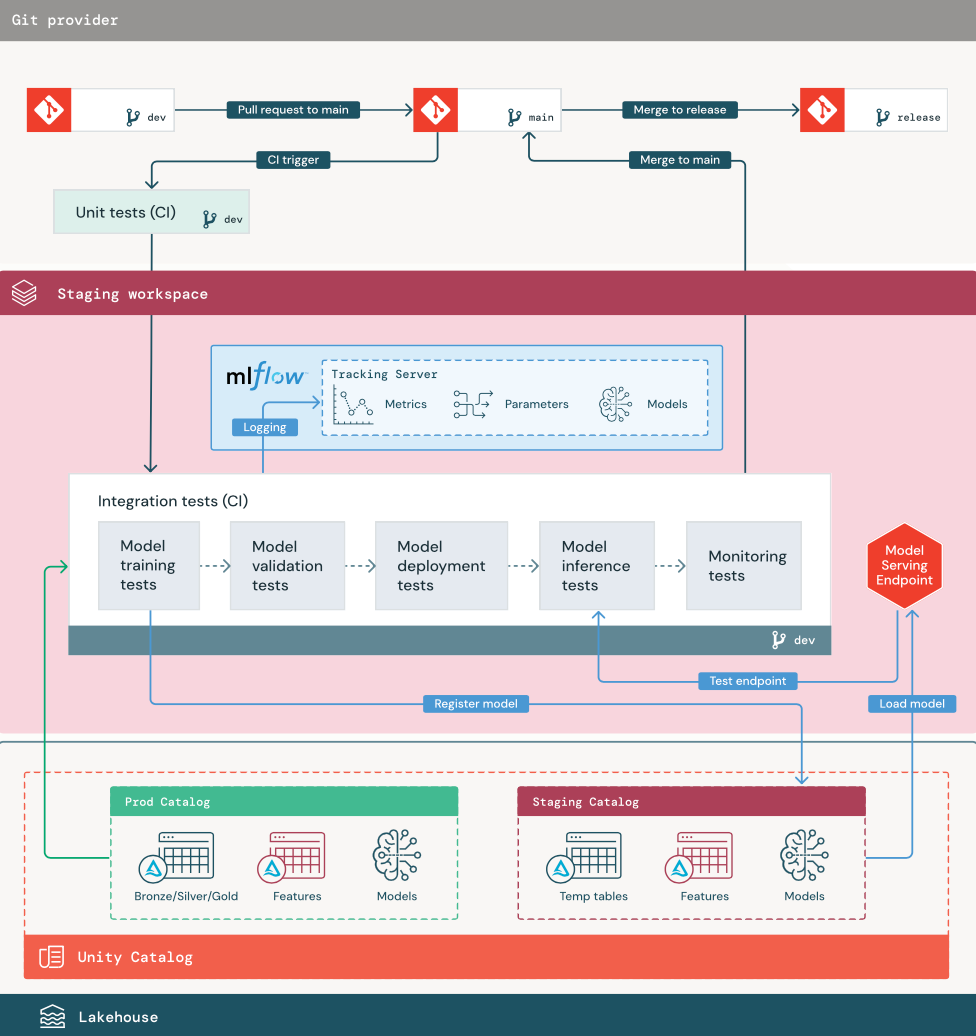
1. Données
L’environnement intermédiaire doit avoir son propre catalogue dans Unity Catalog pour tester les pipelines ML et inscrire des modèles dans Unity Catalog. Ce catalogue s’affiche en tant que « catalogue intermédiaire » dans le diagramme. Les ressources écrites dans ce catalogue sont généralement temporaires et sont conservées seulement jusqu’à ce que les tests soient terminés. L’environnement de développement peut également nécessiter l’accès au catalogue de mise en scène à des fins de débogage.
2. Fusionner du code
Les scientifiques des données développent le pipeline d’apprentissage du modèle dans l’environnement de développement en utilisant des tables provenant des catalogues de développement ou de production.
Demande de tirage. Le processus de déploiement commence quand une pull request est créée sur la branche principale du projet dans la gestion de code source.
Tests unitaires (CI). La pull request construit automatiquement le code source et déclenche des tests unitaires. Si les tests unitaires échouent, la demande de tirage est rejetée.
Les tests unitaires font partie du processus de développement logiciel, et ils sont exécutés en continu et ajoutés au codebase pendant le développement du code. L’exécution de tests unitaires dans le cadre d’un pipeline CI garantit que les modifications apportées dans une branche de développement ne compromettent pas les fonctionnalités existantes.
3. Tests d’intégration (CI)
Le processus CI exécute ensuite les tests d’intégration. Les tests d’intégration exécutent tous les pipelines (notamment l’ingénierie de caractéristiques, l’entraînement du modèle, l’inférence et le monitoring) pour vérifier qu’ils fonctionnent correctement ensemble. L’environnement de préproduction doit correspondre à l’environnement de production autant que possible dans une mesure raisonnable.
Si vous déployez une application ML avec une inférence en temps réel, vous devez créer et tester l’infrastructure de service dans l’environnement intermédiaire. Cette opération implique le déclenchement du pipeline de déploiement du modèle, qui crée un point de terminaison de service dans l’environnement intermédiaire et charge un modèle.
Pour réduire le temps nécessaire pour exécuter les tests d’intégration, certaines étapes peuvent faire un compromis entre la fidélité des tests et la vitesse ou le coût. Par exemple, si les modèles sont coûteux ou longs à entraîner, vous pouvez utiliser de petits sous-ensembles de données ou exécuter moins d’itérations d’apprentissage. Pour le service de modèle, en fonction des exigences de production, vous pouvez effectuer des tests de charge à grande échelle dans les tests d’intégration, ou vous pouvez simplement tester de petits travaux ou de petites demandes par lots sur un point de terminaison temporaire.
4. Fusionner avec la branche de préproduction
Si tous les tests réussissent, le nouveau code est fusionné dans la branche principale du projet. Si les tests échouent, le système CI/CD doit notifier les utilisateurs et publier les résultats sur le pull request.
Vous pouvez planifier des tests d’intégration périodiques sur la branche principale. C’est judicieux si la branche est fréquemment mise à jour avec des pull requests concurrentes de plusieurs utilisateurs.
5. Créer une branche de mise en production
Une fois que les tests CI ont réussi et que la branche de développement est fusionnée dans la branche principale, l’ingénieur ML crée une branche de mise en production, ce qui déclenche la mise à jour des travaux de production par le système CI/CD.
Phase de production
Les ingénieurs ML sont propriétaires de l’environnement de production où les pipelines ML sont déployés et exécutés. Ces pipelines déclenchent l’apprentissage du modèle, valident et déploient de nouvelles versions du modèle, publient des prédictions sur des tables ou des applications en aval, et supervisent l’ensemble du processus pour éviter la dégradation et l’instabilité des performances.
Les scientifiques des données n’ont généralement pas d’accès en écriture ou en calcul dans l’environnement de production. Cependant, il est important qu’ils aient la visibilité des résultats de test, des logs, des artefacts du modèle, de l’état du pipeline de production, et des tables de supervision. Cette visibilité leur permet d’identifier et de diagnostiquer les problèmes en production et de comparer les performances des nouveaux modèles aux modèles actuellement en production. Vous pouvez pour cela accorder aux scientifiques des données un accès en lecture seule aux ressources du catalogue de production.
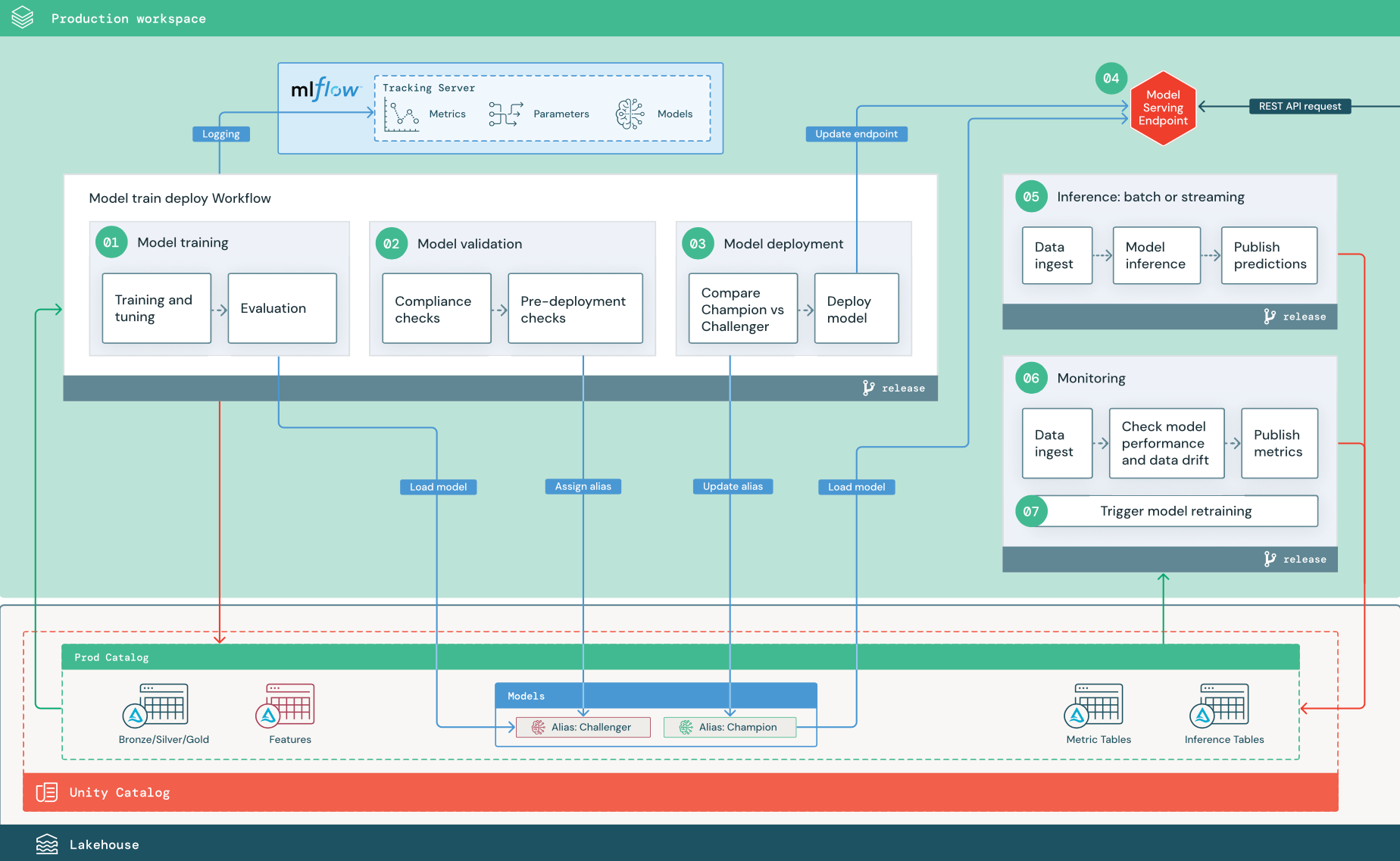
Les étapes numérotées correspondent aux numéros affichés dans le diagramme.
1. Entraîner le modèle
Ce pipeline peut être déclenché par des modifications de code ou par des tâches de réentraînement automatisées. Dans cette étape, les tables du catalogue de production sont utilisées pour les étapes suivantes.
Entraînement et réglage. Pendant le processus d’apprentissage, les journaux sont enregistrés sur le serveur de suivi MLflow de l’environnement de production. Ces journaux incluent les mesures, les paramètres, et les étiquettes du modèle, ainsi que le modèle en entier. Si vous utilisez des tables de caractéristiques, le modèle est enregistré dans MLflow en utilisant le client du magasin de caractéristiques Databricks, qui empaquette le modèle avec des informations de recherche de caractéristiques utilisées lors de l’inférence.
Pendant le développement, les scientifiques des données peuvent tester de nombreux algorithmes et hyperparamètres. Dans le code d’entraînement de production, il est courant d’envisager uniquement les options les plus performantes. Limiter le réglage de cette façon permet de gagner du temps et de réduire les écarts de réglage lors du réentraînement automatisé.
Si les scientifiques des données ont un accès en lecture seule au catalogue de production, ils peuvent être en mesure de déterminer l’ensemble optimal d’hyperparamètres pour un modèle. Dans ce cas, le pipeline d’apprentissage du modèle déployé en production peut être exécuté en utilisant l’ensemble sélectionné d’hyperparamètres, qui est généralement inclus dans le pipeline en tant que fichier de configuration.
Évaluation. La qualité du modèle est évaluée en effectuant des tests sur les données de production conservées. Les résultats de ces tests sont journalisés sur le serveur de suivi MLflow. Cette étape utilise les métriques d’évaluation spécifiées par les scientifiques des données dans la phase de développement. Ces métriques peuvent inclure du code personnalisé.
Enregistrement du modèle. Une fois la formation du modèle terminée, l'artefact de modèle est enregistré en tant que version de modèle enregistrée dans le chemin de modèle spécifié, dans le catalogue de production de Unity Catalog. La tâche d’apprentissage du modèle génère un URI de modèle que la tâche de validation du modèle peut utiliser. Vous pouvez utiliser des valeurs de tâche pour passer cet URI au modèle.
2. Valider le modèle
Ce pipeline utilise l’URI du modèle de l’étape 1 et charge le modèle depuis Unity Catalog. Il exécute ensuite une série de contrôles de validation. Ces contrôles dépendent de votre organisation et du cas d’usage, et ils peuvent inclure des vérifications comme des validations de base du format et des métadonnées, des évaluations des performances sur des tranches de données sélectionnées et la conformité avec des exigences organisationnelles, comme des vérifications de la conformité pour les étiquettes ou la documentation.
Si le modèle passe tous les contrôles de validation, vous pouvez affecter l’alias « Challenger » à la version du modèle dans Unity Catalog. Si le modèle ne passe pas tous les contrôles de validation, le processus s’arrête et les utilisateurs peuvent être avertis automatiquement. Vous pouvez utiliser des étiquettes pour ajouter des attributs clé-valeur en fonction du résultat de ces contrôles de validation. Par exemple, vous pouvez créer une étiquette « état_validation_modèle » et définir la valeur sur « EN ATTENTE » pendant l’exécution des tests, puis la mettre à jour sur « RÉUSSITE » ou sur « ÉCHEC » quand le pipeline est terminé.
Comme le modèle est inscrit dans Unity Catalog, les scientifiques des données travaillant dans l’environnement de développement peuvent charger cette version du modèle depuis le catalogue de production pour investiguer si la validation du modèle échoue. Quelle que soit l’issue, les résultats sont enregistrés dans le modèle inscrit dans le catalogue de production en utilisant des annotations sur la version du modèle.
3. Déployer un modèle
Comme le pipeline de validation, le pipeline de déploiement de modèle dépend de votre organisation et du cas d’usage. Cette section suppose que vous avez affecté l’alias « Challenger » au modèle nouvellement validé et que l’alias « Champion» a été affecté au modèle de production existant. La première étape avant de déployer le nouveau modèle est de vérifier qu’il est au moins aussi performant que le modèle de production actuel.
Comparez le modèle « CHALLENGER » au modèle « CHAMPION ». Vous pouvez effectuer cette comparaison hors connexion ou en ligne. Une comparaison hors connexion évalue les deux modèles par rapport à un jeu de données conservé à part et effectue le suivi des résultats en utilisant le serveur de suivi MLflow. Pour le service de modèle en temps réel, vous pouvez effectuer des comparaisons en ligne plus longues, comme des tests A/B ou un déploiement progressif du nouveau modèle. Si la version du modèle « Challenger » révèle de meilleures performances lors la comparaison, elle remplace l’alias « Champion » actuel.
Le profilage du service de modèle et des données vous permet de collecter et de surveiller automatiquement les tables d’inférence qui contiennent des données de demande et de réponse pour un point de terminaison.
S’il n’existe pas de modèle « Champion », vous pouvez comparer le modèle « Challenger » à une heuristique métier ou à un autre seuil comme ligne de base.
Le processus décrit ici est entièrement automatisé. Si des étapes d’approbation manuelles sont nécessaires, vous pouvez les configurer en utilisant des notifications de workflow ou des rappels CI/CD depuis le pipeline de déploiement de modèle.
Déployez un modèle. Les pipelines d’inférence par lots ou de diffusion en continu peuvent être configurés pour utiliser le modèle avec l’alias « Champion ». Pour les cas d’utilisation en temps réel, vous devez configurer l’infrastructure pour déployer le modèle en tant que point de terminaison d’API REST. Vous pouvez créer et gérer ce point de terminaison à l’aide du service model. Si un point de terminaison est déjà utilisé pour le modèle actuel, vous pouvez mettre à jour le point de terminaison avec le nouveau modèle. Model Service exécute une mise à jour sans temps d’arrêt en conservant la configuration existante en cours d’exécution jusqu’à ce que la nouvelle soit prête.
4. Service de modèles
Lors de la configuration d’un point de terminaison de service de modèle, vous spécifiez le nom du modèle dans Unity Catalog et la version à utiliser. Si l’apprentissage de la version du modèle a été effectué en utilisant des caractéristiques provenant de tables de Unity Catalog, le modèle stocke les dépendances pour les caractéristiques et les fonctions. Le service de modèle utilise automatiquement ce graphe des dépendances pour rechercher des caractéristiques dans les magasins en ligne appropriés au moment de l’inférence. Cette approche peut également être utilisée pour appliquer des fonctions lors du prétraitement des données ou pour calculer des caractéristiques à la demande lors du scoring du modèle.
Vous pouvez créer un point de terminaison unique avec plusieurs modèles et spécifier le partage du trafic du point de terminaison entre ces modèles, ce qui vous permet d’effectuer des comparaisons en ligne entre un modèle « Champion » et un modèle « Challenger ».
5. Inférence : en lots ou en streaming
Le pipeline d’inférence lit les données les plus récentes du catalogue de production, exécute des fonctions pour calculer des caractéristiques à la demande, charge le modèle « Champion », établit le score des données et retourne des prédictions. L’inférence en lots ou en streaming est généralement l’option la plus économique pour les cas d’usage avec un débit et une latence plus élevés. Pour les scénarios où des prédictions à latence faible sont nécessaires mais pour lesquels les prédictions peuvent être calculées hors connexion, ces prédictions par lots peuvent être publiées dans un magasin de clés-valeurs en ligne, comme DynamoDB ou Cosmos DB.
Le modèle inscrit dans Unity Catalog est référencé par son alias. Le pipeline d’inférence est configuré pour charger et appliquer la version du modèle « Champion ». Si la version « Champion » est mise à jour vers une nouvelle version du modèle, le pipeline d’inférence utilise automatiquement la nouvelle version lors de son exécution suivante. De cette façon, l’étape de déploiement du modèle est découplée des pipelines d’inférence.
Les travaux en batch publient généralement les prédictions dans le catalogue de production, dans des fichiers plats ou via une connexion JDBC. Les travaux de diffusion en continu publient généralement les prédictions dans des tables Unity Catalog ou dans des files d’attente de messages, comme Apache Kafka.
6. Profilage des données
Le profilage des données surveille les propriétés statistiques, telles que la dérive de données et les performances du modèle, des données d’entrée et des prédictions de modèle. Vous pouvez créer des alertes en fonction de ces métriques ou les publier dans des tableaux de bord.
- Ingestion des données. Ce pipeline lit dans les journaux à partir d’une inférence en lots, en streaming ou en ligne.
- Vérification de la justesse et de la dérive des données. Le pipeline calcule les métriques relatives aux données d’entrée, aux prédictions du modèle et aux performances de l’infrastructure. Les scientifiques des données spécifient les métriques des données et du modèle pendant le développement, tandis que les ingénieurs ML spécifient les métriques de l’infrastructure. Vous pouvez également définir des métriques personnalisées.
- Publiez des métriques et configurez des alertes. Le pipeline écrit dans des tables du catalogue de production pour l’analyse et l’élaboration de rapports. Vous devez configurer ces tables pour qu’elles soient lisibles depuis l’environnement de développement, afin que les scientifiques des données aient un accès qui leur permet d’effectuer des analyses. Vous pouvez utiliser Databricks SQL pour créer des tableaux de bord de surveillance visant à suivre les performances du modèle et configurer le travail de surveillance ou l’outil de tableau de bord pour émettre une notification lorsqu’une métrique dépasse un seuil spécifié.
- Déclenchez le réapprentissage du modèle. Si les métriques de supervision du modèle indiquent des problèmes de performances, le scientifique des données peut avoir besoin de développer une nouvelle version du modèle. Vous pouvez configurer des alertes SQL pour avertir les scientifiques des données quand cela se produit.
7. Réapprentissage
Cette architecture prend en charge le réapprentissage automatique en utilisant le même pipeline d’apprentissage de modèle que ci-dessus. Databricks recommande de commencer par un réapprentissage planifié et périodique, et de passer au réapprentissage déclenché quand c’est nécessaire.
- Planifié. Si de nouvelles données sont disponibles régulièrement, vous pouvez créer un travail planifié pour exécuter le code d’entraînement du modèle sur les dernières données disponibles. Voir Automatiser les travaux avec des planifications et des déclencheurs
- Déclenchée. Si le pipeline de supervision peut identifier des problèmes de performances du modèle et envoyer des alertes, il peut aussi déclencher le réapprentissage. Par exemple, si la distribution des données entrantes change de manière significative ou si les performances du modèle se dégradent, le réapprentissage et le redéploiement automatiques peuvent améliorer les performances du modèle avec une intervention humaine minimale. Vous pouvez effectuer ceci via une alerte SQL pour vérifier si une métrique est anormale (par exemple, vérifier la dérive ou la qualité du modèle par rapport à un seuil). L’alerte peut être configurée pour utiliser une destination de webhook, qui peut ensuite déclencher le workflow d’apprentissage.
Si le pipeline de réapprentissage ou d’autres pipelines présentent des problèmes de performances, le scientifique des données peut avoir besoin de revenir à l’environnement de développement pour procéder à une expérimentation supplémentaire afin de résoudre les problèmes.