Créer des points de terminaison de mise en service de modèles personnalisés
Cet article explique comment créer et gérer des points de terminaison de mise en service de modèles qui utilisent la Mise en service de modèles Databricks pour mettre en service des modèles personnalisés.
La mise en service de modèles propose les options suivantes pour la création de points de terminaison de mise en service :
- Interface utilisateur de mise en service
- API REST
- Kit de développement logiciel (SDK) de déploiements MLflow
Si vous souhaitez créer des points de terminaison de service de modèles d’IA générative, consultez Créer des points de terminaison de service de modèles d’IA générative.
Exigences
- Votre espace de travail doit se trouver dans une région prise en charge.
- Si vous utilisez des bibliothèques personnalisées ou des bibliothèques d’un serveur miroir privé avec votre modèle, consultez Utiliser des bibliothèques Python personnalisées avec la mise en service de modèles avant de créer le point de terminaison du modèle.
- Si vous souhaitez créer des points de terminaison en tirant parti du Kit de développement logiciel (SDK) Déploiements MLflow, vous devez installer le client Déploiements MLflow. Pour l’installer, exécutez :
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Contrôle d’accès
Pour comprendre les options de contrôle d’accès aux points de service de modèle pour la gestion des points de service, voir Gérer les autorisations sur votre point de service de modèle.
Vous pouvez également ajouter des variables d’environnement pour stocker les informations d’identification pour le service de modèle. Consultez Configurer l’accès aux ressources à partir de points de terminaison de mise en service de modèles
Créer un point de terminaison
Interface utilisateur de service
Vous pouvez créer un point de terminaison pour la mise en service de modèles avec l’interface utilisateur Mise en service.
Cliquez sur Mise en service dans la barre latérale pour afficher l’interface utilisateur de mise en service.
Cliquez sur Créer un point de terminaison de mise en service.
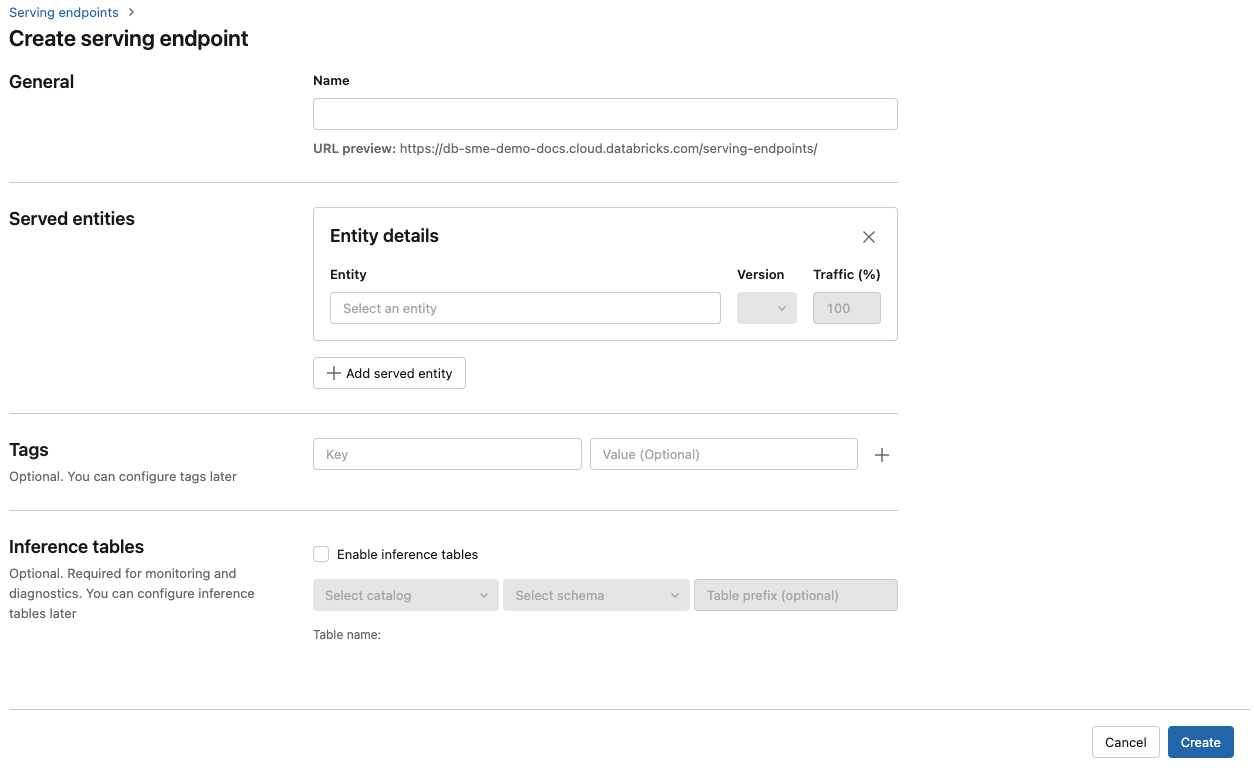
Pour les modèles inscrits dans le registre de modèles d’espace de travail ou dans des modèles Unity Catalog :
Dans le champ Nom , indiquez un nom pour votre point de terminaison.
Dans la section Entités servies
- Cliquez sur le champ Entités pour ouvrir le formulaire Sélectionner une entité servie.
- Sélectionnez le modèle que vous souhaitez servir. Le formulaire est mis à jour dynamiquement en fonction de votre sélection.
- Sélectionnez le modèle et la version du modèle que vous souhaitez servir.
- Sélectionnez le pourcentage de trafic à router vers votre modèle servi.
- Sélectionnez la taille de calcul à utiliser. Vous pouvez utiliser des calculs processeur ou GPU pour vos charges de travail. Pour plus d’informations sur les calculs GPU disponibles, consultez Types de charges de travail GPU.
- Sélectionnez la taille de calcul à utiliser. Vous pouvez utiliser des calculs processeur ou GPU pour vos charges de travail. Pour plus d’informations sur les calculs GPU disponibles, consultez Types de charges de travail GPU.
- Sous Scale-out de calcul, sélectionnez la taille du scale-out de calcul qui correspond au nombre de requêtes que ce modèle servi peut traiter en même temps. Ce nombre doit être à peu près égal au produit Nom de requêtes par second x Temps d’exécution du modèle.
- Les tailles disponibles sont Petit pour 0-4 demandes, Moyen pour 8-16 demandes et Large pour 16-64 demandes.
- Spécifiez si le point de terminaison doit être mis à l’échelle à zéro lorsqu’il n’est pas utilisé.
Cliquez sur Créer. La page Points de terminaison de mise en service s’affiche avec l’état du point de terminaison de mise en service indiqué comme Non prêt.
API REST
Vous pouvez créer des points de terminaison à l’aide de l’API REST. Pour connaître les paramètres de configuration des points de terminaison, consultez POST /api/2.0/serving-endpoints.
L’exemple suivant crée un point de terminaison qui sert la première version du modèle ads1 inscrite dans le registre de modèles. Pour spécifier un modèle à partir d’Unity Catalog, fournissez le nom complet du modèle, y compris le catalogue et le schéma parents, tels que catalog.schema.example-model.
POST /api/2.0/serving-endpoints
{
"name": "workspace-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
Voici un exemple de réponse. L’état config_update du point de terminaison est NOT_UPDATING et le modèle servi est dans un état READY.
{
"name": "workspace-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
Kit de développement logiciel (SDK) de déploiements MLflow
MLflow Deployments fournit une API pour créer, mettre à jour et supprimer des tâches. Les API de ces tâches acceptent les mêmes paramètres que l’API REST pour servir des points de terminaison. Pour connaître les paramètres de configuration des points de terminaison, consultez POST /api/2.0/serving-endpoints.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="workspace-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
Vous pouvez également :
Configurez votre point de terminaison pour servir plusieurs modèles.
Configurer votre point de terminaison pour l’optimisation des routes.
Activez les tables d'inférence pour capturer automatiquement les demandes entrantes et les réponses sortantes vers les points de terminaison de diffusion de votre modèle.
Types de charge de travail GPU
Le déploiement GPU est compatible avec les versions de package suivantes :
- Python 1.13.0 – 2.0.1
- TensorFlow 2.5.0 – 2.13.0
- MLflow 2.4.0 et supérieur
Pour déployer vos modèles à l'aide de GPU, incluez le champ workload_type dans la configuration de votre point de terminaison lors de la création du point de terminaison ou en tant que mise à jour de la configuration du point de terminaison à l'aide de l'API. Pour configurer votre point de terminaison pour les charges de travail GPU avec l'interface utilisateur de service, sélectionnez le type de GPU souhaité dans la liste déroulante Type de calcul.
{
"served_entities": [{
"name": "ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
Le tableau suivant récapitule les types de charges de travail GPU disponibles pris en charge.
| Type de charge de travail GPU | Instance GPU | Mémoire GPU |
|---|---|---|
GPU_SMALL |
1xT4 | 16 Go |
GPU_LARGE |
1xA100 | 80Go |
GPU_LARGE_2 |
2xA100 | 160Go |
Modifier un point de terminaison de modèle personnalisé
Après l’activation d’un point de terminaison de modèle personnalisé, vous pouvez mettre à jour la configuration de calcul comme vous le souhaitez. Cette configuration se révèle particulièrement utile si vous avez besoin de ressources supplémentaires pour votre modèle. La taille de la charge de travail et la configuration du calcul jouent un rôle clé dans les ressources allouées pour servir votre modèle.
Tant que la nouvelle configuration n’est pas prête, l’ancienne configuration continue de servir le trafic de prédiction. Tandis qu’une mise à jour est en cours, une autre mise à jour ne peut pas être effectuée. Cependant, vous pouvez annuler une mise à jour en cours depuis l’interface utilisateur de mise en service.
Interface utilisateur de service
Après avoir activé un point de terminaison de modèle, sélectionnez Modifier le point de terminaison pour modifier la configuration de calcul de votre point de terminaison.
Vous pouvez effectuer les opérations suivantes :
- Choisissez parmi quelques tailles de charge de travail, et la mise à l’échelle automatique est automatiquement configurée dans la taille de la charge de travail.
- Spécifiez si votre point de terminaison doit être mis à l’échelle à zéro lorsqu’il n’est pas utilisé.
- Modifiez le pourcentage de trafic à acheminer vers votre modèle servi.
Vous pouvez annuler une mise à jour de configuration en cours en sélectionnant Annuler la mise à jour en haut à droite de la page des détails du point de terminaison. Cette fonctionnalité est disponible seulement dans l’interface utilisateur de mise en service.
API REST
Voici un exemple de mise à jour de la configuration d’un point de terminaison en utilisant l’API REST. Consultez PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
Kit de développement logiciel (SDK) de déploiements MLflow
Le Kit de développement logiciel (SDK) Déploiements MLflow utilise les mêmes paramètres que l’API REST. Si vous souhaitez découvrir les détails du schéma de requête et de réponse, consultez PUT /api/2.0/serving-endpoints/{name}/config.
L’exemple de code suivant utilise un modèle à partir du registre de modèles Unity Code :
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Notation d’un point de terminaison de modèle
Pour évaluer votre modèle, envoyez des demandes au point de terminaison de mise en service de modèle.
- Consultez Points de terminaison de service de requête pour les modèles personnalisés.
- Consultez les modèles IA génératifs de requête.
Ressources supplémentaires
- Gérer des points de terminaison de service de modèles.
- Modèles externes dans le Service de modèles Mosaic AI.
- Si vous préférez utiliser Python, vous pouvez utiliser le SDK Python de service en temps réel Databricks.
Exemples de Notebook
Les notebooks suivants incluent différents modèles inscrits auprès de Databricks que vous pouvez utiliser pour bien démarrer avec les points de terminaison de service de modèles.
Les exemples de modèles peuvent être importés dans l’espace de travail sur la base des instructions figurant dans Importer un notebook. Après avoir choisi et créé un modèle à partir de l’un des exemples, inscrivez-le dans le catalogue Unity, puis suivez les étapes de flux de travail de l’interface utilisateur pour le service de modèle.