Créer des points de terminaison de mise en service de modèles d’IA générative
Dans cet article, vous apprendrez à créer des points de terminaison de service de modèle qui servent des modèles d’IA générative.
Le Service de modèles Databricks prend en charge les modèles de base suivants :
- Modèles de base ouverts de pointe mis à disposition par les API de modèles de base. Ces modèles sont des architectures de modèle de base curées qui prennent en charge l’inférence optimisée. Les modèles de base, comme Llama-2-70B-chat, BGE-Large et Mistral-7B sont disponibles pour une utilisation immédiate avec une tarification de paiement par jeton. Les charges de travail de production, à l’aide de modèles de base ou affinés, peuvent être déployées avec des garanties de niveau de performance à l’aide de débit approvisionné.
- Modèles externes. Il s’agit de modèles hébergés en dehors de Databricks. Les points de terminaison servant des modèles externes peuvent être régis de manière centralisée et les clients peuvent établir des limites de débit et un contrôle d’accès les concernant. Les exemples incluent des modèles de base tels que GPT-4 d’OpenAI, Claude d’Anthropic et d’autres.
Le service de modèles fournit les options suivantes pour la création de points de terminaison de service de modèles :
- L’Interface utilisateur de mise en service
- API REST
- Kit de développement logiciel (SDK) de déploiements MLflow
Pour créer des points de terminaison qui servent des modèles ML ou Python traditionnels, consultez Créer des points de terminaison pour des modèles personnalisé.
Exigences
- Un espace de travail Databricks dans une région prise en charge.
- Si vous souhaitez créer des points de terminaison en tirant parti du Kit de développement logiciel (SDK) Déploiements MLflow, vous devez installer le client Déploiements MLflow. Pour l’installer, exécutez :
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Créer un modèle de base servant un point de terminaison
Vous pouvez créer un point de terminaison qui sert des variantes affinées des modèles de base mis à disposition à l’aide du débit approvisionné des API de modèles de base. Voir Créer votre point de terminaison avec débit approvisionné en utilisant l’API REST.
Pour les modèles de base mis à disposition à l’aide des API des modèles de base payer par jeton, Databricks fournit automatiquement des points de terminaison spécifiques pour accéder aux modèles pris en charge dans votre espace de travail Databricks. Pour y accéder, sélectionnez l’onglet Service dans la barre latérale gauche de l’espace de travail. Les API Foundation Model se trouvent en haut de la liste des points de terminaison.
Pour interroger ces points de terminaison, consultez modèles de base de requêtes.
Créer un point de terminaison de mise en service de modèles externes
Les instructions suivantes expliquent comment créer un point de terminaison qui sert un modèle d’IA générative mis à disposition à l’aide de modèles externes Databricks.
Interface utilisateur de service
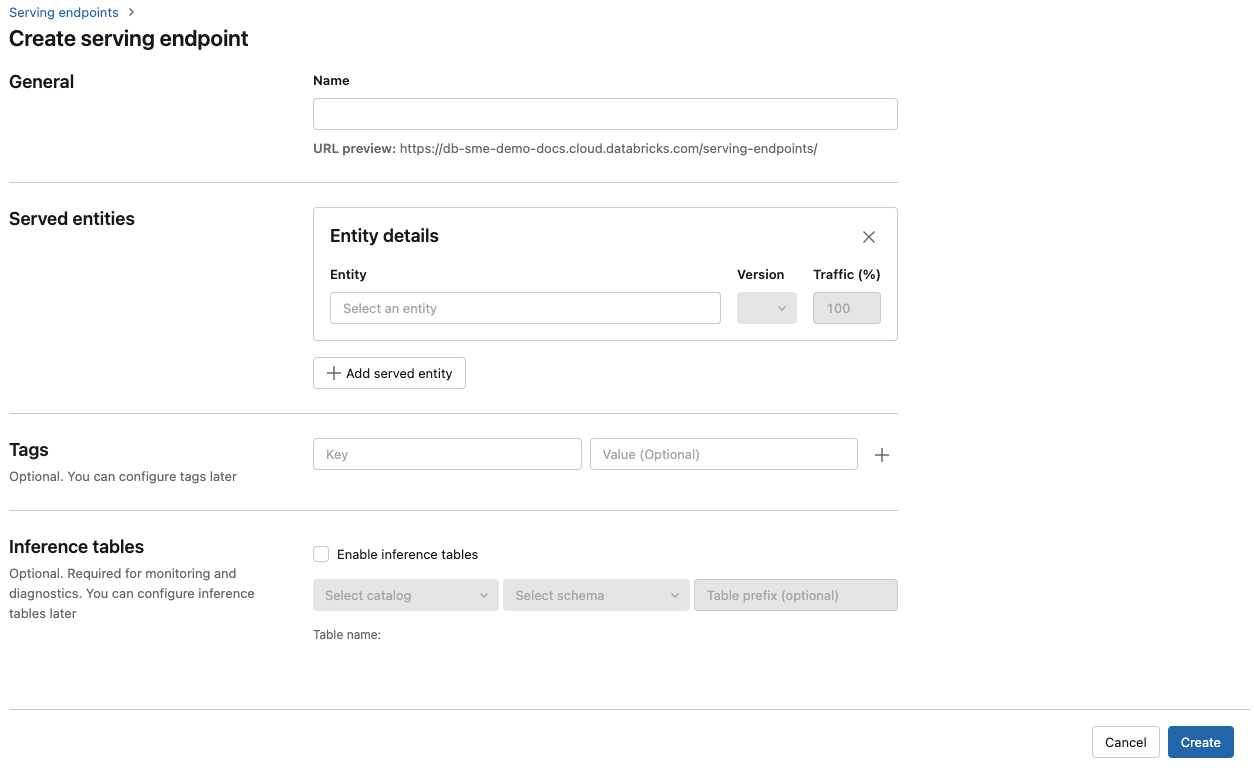
- Dans le champ Nom , indiquez un nom pour votre point de terminaison.
- Dans la section Entités servies
- Cliquez sur le champ Entités pour ouvrir le formulaire Sélectionner une entité servie.
- Sélectionnez Modèle externe.
- Sélectionnez le fournisseur de modèles que vous souhaitez utiliser.
- Cliquez sur Confirmer.
- Indiquez le nom du modèle externe que vous souhaitez utiliser. Le formulaire est mis à jour dynamiquement en fonction de votre sélection. Consultez les modèles externes disponibles.
- Sélectionnez le type de tâche. Les tâches disponibles sont les conversations, les achèvements et les incorporations.
- Fournissez les détails de configuration pour accéder au fournisseur de modèles sélectionné. Il s’agit généralement du secret qui fait référence au jeton d’accès personnel à utiliser pour accéder à ce modèle.
- Cliquez sur Créer. La page Points de terminaison de mise en service s’affiche avec l’état du point de terminaison de mise en service indiqué comme Non prêt.
API REST
Important
Les paramètres de l’API REST permettant de créer des points de terminaison de service qui servent des modèles externes sont en préversion publique.
L’exemple suivant crée un point de terminaison qui sert la première version du modèle text-embedding-ada-002 fourni par OpenAI.
Pour connaître les paramètres de configuration des points de terminaison, consultez POST /api/2.0/serving-endpoints.
{
"name": "openai_endpoint",
"config":{
"served_entities": [
{
"name": "openai_embeddings",
"external_model":{
"name": "text-embedding-ada-002",
"provider": "openai",
"task": "llm/v1/embeddings",
"openai_config":{
"openai_api_key": "{{secrets/my_scope/my_openai_api_key}}"
}
}
}
]
},
"rate_limits": [
{
"calls": 100,
"key": "user",
"renewal_period": "minute"
}
],
"tags": [
{
"key": "team",
"value": "gen-ai"
}
]
}
Voici un exemple de réponse.
{
"name": "openai_endpoint",
"creator": "user@email.com",
"creation_timestamp": 1699617587000,
"last_updated_timestamp": 1699617587000,
"state": {
"ready": "READY"
},
"config": {
"served_entities": [
{
"name": "openai_embeddings",
"external_model": {
"provider": "openai",
"name": "text-embedding-ada-002",
"task": "llm/v1/embeddings",
"openai_config": {
"openai_api_key": "{{secrets/my_scope/my_openai_api_key}}"
}
},
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1699617587000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "openai_embeddings",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "gen-ai"
}
],
"id": "69962db6b9db47c4a8a222d2ac79d7f8",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
Kit de développement logiciel (SDK) de déploiements MLflow
L’exemple suivant crée un point de terminaison pour des incorporations avec le modèle text-embedding-ada-002 d’OpenAI.
Pour les points de terminaison de modèle externe, vous devez fournir des clés API pour le fournisseur de modèles que vous souhaitez utiliser. Consultez POST /api/2.0/serving-endpoints pour plus d’informations sur le schéma de requête et de réponse, consultez dans l’API REST. Pour un guide étape par étape, voir Tutoriel : créer des points de terminaison de modèle externe pour interroger des modèles OpenAI.
Vous pouvez également créer des points de terminaison pour les tâches de complétion et de conversation, celles-ci étant spécifiées par le champ task dans la section external_model de la configuration. Pour connaître les modèles et fournisseurs pris en charge pour chaque tâche, consultez Modèles externes dans le Service de modèles Databricks.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="chat",
config={
"served_entities": [
{
"name": "completions",
"external_model": {
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": "{{secrets/scope/key}}",
},
},
}
],
},
)
assert endpoint == {
"name": "chat",
"creator": "alice@company.com",
"creation_timestamp": 0,
"last_updated_timestamp": 0,
"state": {...},
"config": {...},
"tags": [...],
"id": "88fd3f75a0d24b0380ddc40484d7a31b",
}
Mettre à jour un point de terminaison de modèle de base
Après avoir activé un point de terminaison de modèle, vous pouvez définir la configuration de calcul à votre guise. Cette configuration se révèle particulièrement utile si vous avez besoin de ressources supplémentaires pour votre modèle. La taille de la charge de travail et la configuration du calcul jouent un rôle clé dans les ressources allouées pour servir votre modèle.
Tant que la nouvelle configuration n’est pas prête, l’ancienne configuration continue de servir le trafic de prédiction. Tandis qu’une mise à jour est en cours, une autre mise à jour ne peut pas être effectuée. Dans l’interface utilisateur de Model Serving, vous pouvez annuler une mise à jour de configuration en cours en sélectionnant Cancel update en haut à droite de la page des détails du point de terminaison. Cette fonctionnalité est disponible seulement dans l’interface utilisateur de Model Serving.
Lorsqu’un external_model est présent dans une configuration de point de terminaison, la liste des entités servies ne peut avoir qu’un objet served_entity. Vous ne pouvez pas mettre à jour un point de terminaison existant avec un external_model pour obtenir un point de terminaison sans external_model. Si le point de terminaison est créé sans external_model, vous ne pouvez pas le mettre à jour pour ajouter un external_model.
API REST
Pour mettre à jour votre point de terminaison de modèle de base, consultez la documentation de configuration de la mise à jour de l’API REST pour obtenir des détails sur les schémas de demande et de réponse.
{
"name": "openai_endpoint",
"served_entities":[
{
"name": "openai_chat",
"external_model":{
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config":{
"openai_api_key": "{{secrets/my_scope/my_openai_api_key}}"
}
}
}
]
}
Kit de développement logiciel (SDK) de déploiements MLflow
Pour mettre à jour votre point de terminaison de modèle de base, consultez la documentation de configuration de la mise à jour de l’API REST pour obtenir des détails sur les schémas de demande et de réponse.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.update_endpoint(
endpoint="chat",
config={
"served_entities": [
{
"name": "chats",
"external_model": {
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": "{{secrets/scope/key}}",
},
},
}
],
},
)
assert endpoint == {
"name": "chats",
"creator": "alice@company.com",
"creation_timestamp": 0,
"last_updated_timestamp": 0,
"state": {...},
"config": {...},
"tags": [...],
"id": "88fd3f75a0d24b0380ddc40484d7a31b",
}
rate_limits = client.update_endpoint(
endpoint="chat",
config={
"rate_limits": [
{
"key": "user",
"renewal_period": "minute",
"calls": 10,
}
],
},
)
assert rate_limits == {
"rate_limits": [
{
"key": "user",
"renewal_period": "minute",
"calls": 10,
}
],
}
Ressources supplémentaires
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour