Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
Cette fonctionnalité est disponible en préversion publique.
Important
Cet article décrit l’expérience de table d’inférence héritée, qui est uniquement pertinente pour certains points de terminaison de service de débit approvisionné et de modèle personnalisé.
- À compter du 20 février 2026, les tables d’inférence héritées ne peuvent pas être activées sur des points de terminaison de service de modèle nouveaux ou existants.
- À compter du 30 avril 2026, l’expérience de table d’inférence héritée ne sera plus prise en charge.
Databricks recommande les tables d’inférence compatibles avec la passerelle AI pour leur disponibilité sur des points de terminaison de modèle personnalisé, de modèle fondamental et d’agents. Pour obtenir des instructions sur la migration vers des tables d’inférence compatibles avec AI Gateway, consultez Migration vers des tables d’inférence de passerelle AI.
Remarque
Si vous servez une application IA de génération dans Databricks, vous pouvez utiliser la supervision d’IA de génération Databricks pour configurer automatiquement des tables d’inférence et suivre les métriques opérationnelles et de qualité pour votre application.
L’article présente les tables d’inférence pour le monitoring de modèles servis. Le diagramme suivant montre un workflow typique avec des tables d’inférence. La table d’inférence capture automatiquement les requêtes entrantes et les réponses sortantes pour un point de terminaison de mise en service de modèle et les enregistre sous forme de table Delta Unity Catalog. Vous pouvez utiliser les données de cette table pour monitorer, déboguer et améliorer des modèles ML.
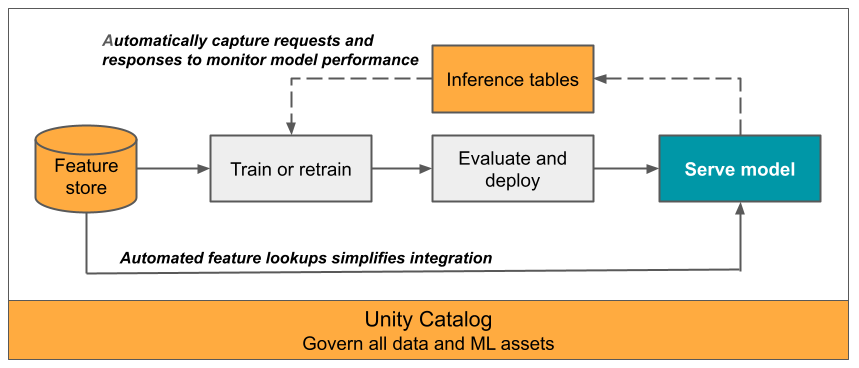
Que sont les tables d’inférence ?
Le monitoring des performances des modèles dans des workflows de production est un aspect important du cycle de vie de modèles ML et IA. Les tables d’inférence simplifient la supervision et le diagnostic des modèles en journalisant continuellement les entrées des requêtes de mise en service et les réponses (prédictions) à partir des points de terminaison de service de modèle Mosaic AI, puis en les enregistrant dans une table Delta dans Unity Catalog. Vous pouvez ensuite utiliser toutes les fonctionnalités de la plateforme Databricks, telles que les requêtes SQL Databricks, les notebooks et le profilage des données pour surveiller, déboguer et optimiser vos modèles.
Vous pouvez activer des tables d’inférence sur tout point de terminaison de mise en service de modèles existant ou nouvellement créé pour que toutes les requêtes à ce point de terminaison soient automatiquement journalisées vers une table dans Unity Catalog.
Certaines applications courantes pour les tables d’inférence sont les suivantes :
- Surveiller les données et la qualité du modèle. Vous pouvez surveiller en permanence les performances et la dérive des données de votre modèle à l’aide du profilage des données. Le profilage des données génère automatiquement des tableaux de bord de qualité des données et des modèles que vous pouvez partager avec les parties prenantes. En outre, vous pouvez activer des alertes pour savoir quand vous devez réentraîner votre modèle en fonction de changements dans les données entrantes ou de baisses en matière de performances des modèles.
- Déboguer des problèmes de production. Les tables d’inférence journalisent des données telles que des codes d’état HTTP, des délais d’exécution de modèles et du code JSON de requête et de réponse. Vous pouvez utiliser ces données de performances à des fins de débogage. Vous pouvez également utiliser les données historiques dans les tables d’inférence pour comparer les performances d’un modèle sur l’historique des requêtes.
- Créez un corpus d’apprentissage. En rejoignant les tables d’inférence avec des étiquettes de vérité de terrain, vous pouvez créer un corpus d’apprentissage que vous pouvez utiliser pour réentraîner ou ajuster et améliorer votre modèle. À l’aide des Tâches Lakeflow, vous pouvez configurer une boucle de rétroaction continue et automatiser la réformation.
Exigences
- Votre espace de travail doit être activé pour Unity Catalog.
- Le créateur de l'endpoint et le modificateur doivent tous deux avoir les permissions de gestion sur l'endpoint. Consultez Listes de contrôle d’accès.
- Le créateur ou la créatrice du point de terminaison et le modificateur doivent avoir les autorisations suivantes dans Unity Catalog :
- Autorisations
USE CATALOGsur le catalogue spécifié. - Autorisations
USE SCHEMAsur le schéma spécifié. - Autorisations
CREATE TABLEdans le schéma.
- Autorisations
Activer désactiver les tables d’inférence
La section vous présente comment activer ou désactiver les tables d’inférence en tirant parti de l’interface utilisateur Databricks. Vous pouvez également utilisez l’API ; voir Activer des tables d’inférence sur des points de terminaison de mise en service de modèles en utilisant l’API pour découvrir des instructions.
Le propriétaire des tables d’inférence est l’utilisateur ayant créé le point de terminaison. Toutes les listes de contrôle d’accès (ACL) de la table suivent les autorisations standard du catalogue Unity et peuvent être modifiées par le propriétaire de la table.
Avertissement
La table d’inférence peut être altérée si vous effectuez l’une des actions suivantes :
- Modifiez le schéma de la table.
- Modifiez le nom de la table.
- Supprimez le tableau.
- Les autorisations sur le catalogue ou le schéma Unity Catalog ont été perdues.
Dans ce cas, le auto_capture_config de l’état du point de terminaison affiche un état FAILED pour la table de charge utile. Si cela se produit, vous devez créer un point de terminaison pour continuer à utiliser des tables d’inférence.
Pour activer les tables d’inférence lors de la création du point de terminaison, procédez comme suit :
Cliquez sur Service dans l’interface utilisateur de Databricks Mosaic AI.
Cliquez sur Créer un point de service.
Sélectionnez Activer des tables d’inférence.
Dans les menus déroulants, sélectionnez le catalogue et le schéma souhaités pour l’emplacement souhaité de la table.
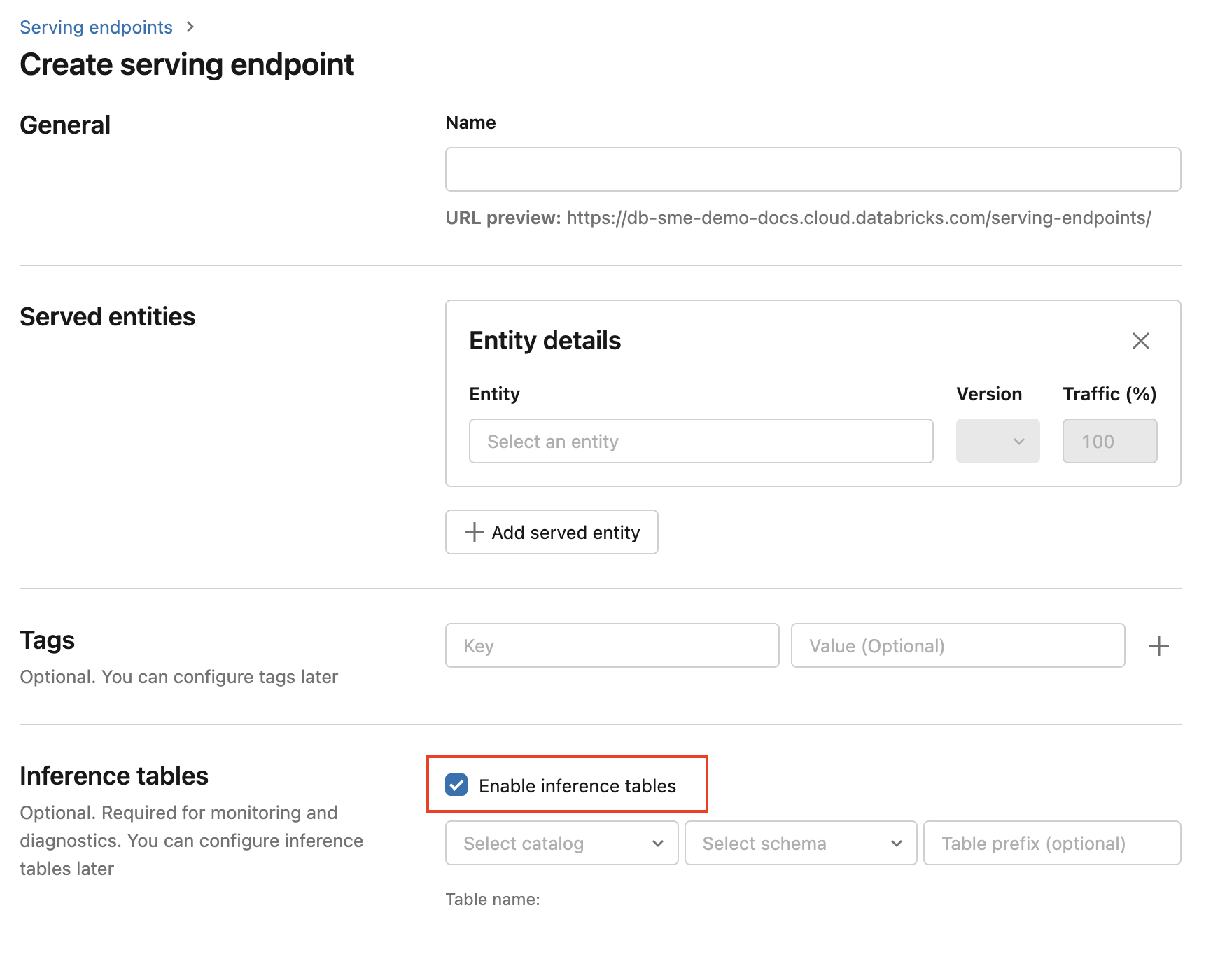
Le nom de table par défaut est
<catalog>.<schema>.<endpoint-name>_payload. Si vous le souhaitez, vous pouvez entrer un préfixe de table personnalisé.Cliquez sur Créer un point de service.
Vous pouvez également activer les tables d’inférence sur un point de terminaison existant. Pour modifier une configuration de point de terminaison existante, procédez comme suit :
- Rendez-vous sur la page de votre point d'accès.
- Cliquez sur Modifier la configuration.
- Suivez les instructions précédentes, à partir de l’étape 3.
- Une fois terminé, cliquez sur Mettre à jour le point de terminaison de service.
Suivez ces instructions pour désactiver des tables d’inférence :
- Accédez à la page de votre point de terminaison.
- Cliquez sur Modifier la configuration.
- Cliquez sur Activer la table d’inférence pour supprimer la coche.
- Lorsque les spécifications des points de terminaison vous conviennent, cliquez sur Mettre à jour.
Migration vers des tables d'inférence de la passerelle IA
Important
Une fois qu’un point de terminaison migre pour utiliser une table d’inférence de passerelle IA, il ne peut pas revenir à la table héritée.
Remarque
Les tables d’inférence ai Gateway ont des schémas différents par rapport aux tables d’inférence héritées.
Pour plus d’informations sur la tarification, consultez la page de tarification de la passerelle Mosaïque IA.
Cette section explique comment migrer des tables d’inférence héritées vers des tables d’inférence AI Gateway.
Il existe deux étapes principales pour mettre à jour la configuration :
- Mettez à jour le point de terminaison de service pour désactiver la table d’inférence héritée.
- Mettez à jour l’endpoint de service pour activer la table d’inférence de l’IA Gateway.
Utiliser l’interface utilisateur pour migrer la configuration de la table d’inférence
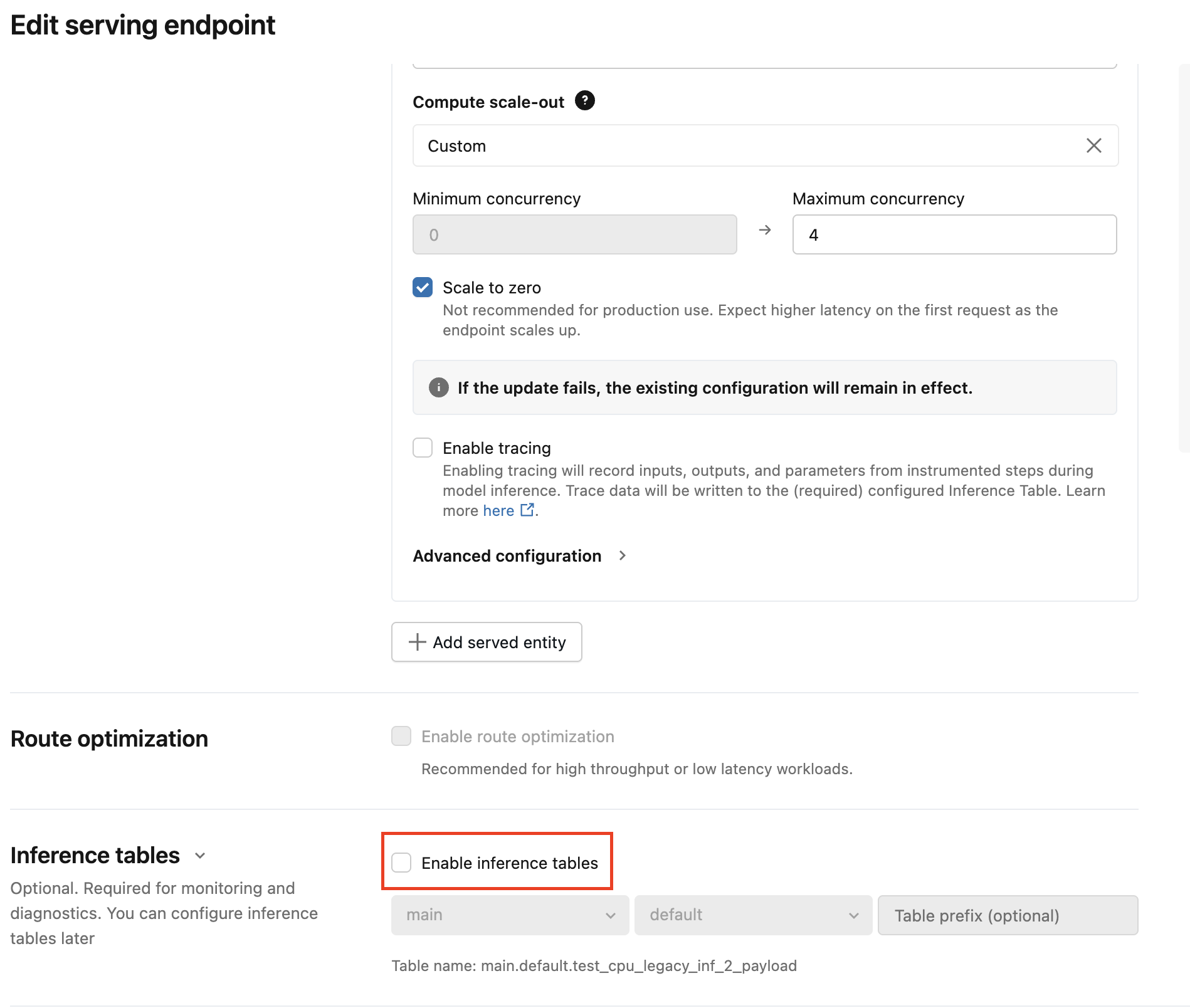
Pour un petit nombre de points de terminaison de service, modifiez la configuration du point de terminaison dans l’interface utilisateur :
Cliquez sur Service dans l’interface utilisateur de l’IA Databricks Mosaïque et accédez à votre page de point de terminaison.
Cliquez sur Modifier la configuration.
Cliquez sur Activer les tables d’inférence pour supprimer la coche.
cliquez sur Mettre à jour et attendez que l’état du point de terminaison devienne Prêt.
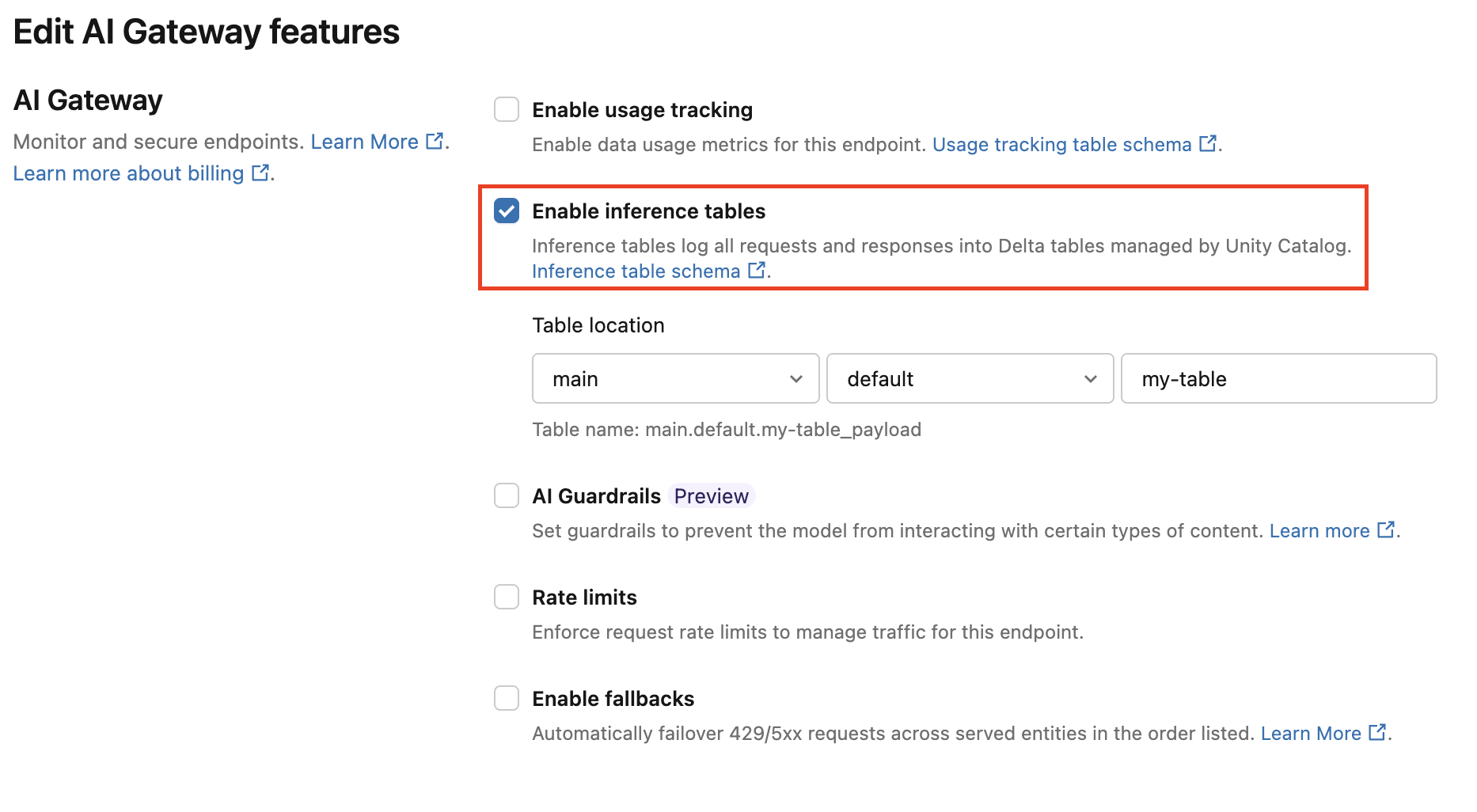
Suivez ces instructions pour activer la table d’inférence de la passerelle IA :
Cliquez sur Service dans l’interface utilisateur de l’IA Databricks Mosaïque et accédez à votre page de point de terminaison.
Cliquez sur Modifier la passerelle IA.
Cliquez sur Activer les tables d’inférence.
Dans le menu déroulant, sélectionnez le catalogue et le schéma souhaités dans lesquels vous souhaitez que le tableau se trouve.
Le nom de table par défaut est
<catalog>.<schema>.<endpoint-name>_payload. Si vous le souhaitez, entrez un préfixe de table personnalisé.Cliquez sur Update.
Utiliser le notebook pour migrer la configuration de la table d’inférence
Pour de nombreux points de terminaison, vous pouvez utiliser l’API pour automatiser le processus de migration. Databricks fournit un exemple de notebook qui migre par lot les points de terminaison de service d'inférence et des exemples montrant comment migrer les données existantes depuis des tables d’inférence héritées vers des tables d’inférence AI Gateway.
Migrer vers le notebook des tables d’inférence de passerelle AI
Workflow : monitorer les performances d’un modèle en utilisant des tables d’inférence
Pour monitorer les performances d’un modèle en utilisant des tables d’inférence, suivez ces étapes :
- Activez les tables d’inférence sur votre point de terminaison au moment de sa création ou lors d’une mise à jour ultérieure.
- Planifiez un workflow pour traiter les charges utiles JSON dans la table d’inférence en les décompressant en fonction du schéma du point de terminaison.
- (Facultatif) Joignez les demandes et réponses décompressées avec des étiquettes ground-truth pour permettre le calcul des métriques de qualité du modèle.
- Créez un moniteur sur la table Delta résultante et actualisez les métriques.
Le notebook de démarrage implémente ce workflow.
Bloc-notes de démarrage pour le suivi d’une table d’inférence
Le notebook suivant implémente les étapes décrites ci-dessus pour décompresser les demandes d’une table d’inférence de profilage des données. Le notebook peut être exécuté à la demande ou selon une planification périodique à l’aide de Jobs Lakeflow.
Bloc-notes de démarrage du profilage des données de table d’inférence
Notebook de démarrage pour surveiller la qualité d’un texte à partir de points de terminaison utilisant des grands modèles de langage (LLM)
Le notebook suivant décompresse des requêtes à partir d’une table d’inférence, calcule un ensemble de mesures d’évaluation du texte (telles que la lisibilité et la toxicité) et permet le monitoring de ces mesures. Le notebook peut être exécuté à la demande ou selon une planification périodique à l’aide de Jobs Lakeflow.
Notebook de démarrage du profilage des données de table d’inférence LLM
Interroger et analyser des résultats dans la table d’inférence
Une fois vos modèles servis prêts, toutes les requêtes adressées à vos modèles sont enregistrées automatiquement dans la table d’inférence, ainsi que les réponses. Vous pouvez afficher la table dans l’interface utilisateur, interroger la table à partir de DBSQL ou d’un notebook, ou interroger la table en utilisant l’API REST.
Pour afficher la table dans l’interface utilisateur : sur la page du point de terminaison, cliquez sur le nom de la table d’inférence pour ouvrir la table dans l’Explorateur de catalogues.

Pour interroger la table à partir de DBSQL ou d’un notebook Databricks : vous pouvez exécuter du code semblable à ce qui suit pour interroger la table d’inférence.
SELECT * FROM <catalog>.<schema>.<payload_table>
Si vous avez activé des tables d’inférence en utilisant l’interface utilisateur, payload_table est le nom de table que vous avez affecté lors de votre création du point de terminaison. Si vous avez activé des tables d’inférence en utilisant l’API, payload_table est signalé dans la section state de la réponse auto_capture_config. Pour obtenir un exemple, voir Activer des tables d’inférence sur des points de terminaison de mise en service de modèles en utilisant l’API.
Remarque sur les performances
Après avoir appelé le point de terminaison, vous pouvez voir l’appel enregistré dans votre table d’inférence dans l’heure après l’envoi d’une demande de scoring. De plus, Azure Databricks garantit que les journaux soient envoyés au moins une fois. Il est donc possible, bien que peu probable, que les journaux soient envoyés en double.
Schéma de table d’inférence du catalogue Unity
Chaque requête et réponse journalisée dans une table d’inférence est écrite dans une table Delta avec le schéma suivant :
Remarque
Si vous appelez le point de terminaison avec un lot d’entrées, le lot entier est enregistré sous forme d’une ligne.
| Nom de colonne | Descriptif | Catégorie |
|---|---|---|
databricks_request_id |
Identificateur de requête généré par Azure Databricks attaché à toutes les requêtes de mise en service de modèle. | CORDE |
client_request_id |
Identificateur de requête généré par un client facultatif qui peut être spécifié dans le corps de la requête de mise en service de modèle. Pour plus d’informations, consultez Specify client_request_id. |
CORDE |
date |
Date UTC de réception de la requête de mise en service de modèle. | date |
timestamp_ms |
Horodatage en millisecondes d’époque de l’heure de réception de la requête de service du modèle. | LONG |
status_code |
Code d’état HTTP retourné par le modèle. | INT |
sampling_fraction |
Fraction d’échantillonnage utilisée dans le cas où la requête a été sous-échantillonnée. Cette valeur est comprise entre 0 et 1, où 1 indique que 100 % des requêtes entrantes ont été incluses. | DOUBLE |
execution_time_ms |
Durée d’exécution en millisecondes pour laquelle le modèle a réalisé l’inférence. Cela n’inclut pas les latences réseau de surcharge et représente uniquement le temps nécessaire pour que le modèle génère des prédictions. | LONG |
request |
Le corps de requête JSON brut qui a été envoyé au point d'accès de service de modèle. | CORDE |
response |
Corps JSON de réponse brute retourné par le point de terminaison du modèle. | CORDE |
request_metadata |
Une carte des métadonnées liées au point de terminaison du service de modèle associé à la requête. Ce mappage contient le nom du point de terminaison, le nom du modèle et la version du modèle utilisées pour votre point de terminaison. | MAPPE<CHAÎNE, CHAÎNE> |
Spécifiez client_request_id
Le champ client_request_id est une valeur facultative que l’utilisateur peut fournir dans le corps de la demande de service du modèle. Cela permet à l'utilisateur de fournir son propre identifiant pour une requête qui s'affiche dans la table d'inférence finale sous client_request_id et peut être utilisé pour associer votre requête à d'autres tables qui utilisent client_request_id, comme l'association des étiquettes de vérité terrain. Pour spécifier client_request_id, incluez-le en tant que clé de niveau supérieur de la charge utile de la requête. Si client_request_id n’est pas spécifié, la valeur apparaît comme nulle dans la ligne correspondant à la demande.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
client_request_id peut être utilisé ultérieurement pour les jonctions d'étiquettes de véracité terrain si d'autres tables ont des étiquettes associées à client_request_id.
Limites
- Les clés gérées par le client ne sont pas prises en charge.
- Pour les points de terminaison qui hébergent des modèles de fondation, les tables d’inférence sont prises en charge seulement sur des charges de travail avec débit provisionné.
- Azure Firewall peut entraîner l’échec de la création de la table Unity Catalog Delta, qui n’est donc pas prise en charge par défaut. Contactez l’équipe de votre compte Databricks pour l’activer.
- Lorsque des tables d’inférence sont activées, la limite de concurrence maximale totale est de 128 pour tous les modèles servis dans un point de terminaison unique. Contactez l’équipe en charge de votre compte Azure Databricks pour demander une augmentation de cette limite.
- Si une table d’inférence contient plus de 500 000 fichiers, aucune donnée supplémentaire n’est enregistrée. Pour éviter de dépasser cette limite, exécutez ou configurez OPTIMIZE la rétention sur votre table en supprimant des données plus anciennes. Pour vérifier le nombre de fichiers de votre table, exécutez
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - La livraison des fichiers journaux des tables d'inférence est actuellement un effort maximum. Toutefois, vous pouvez vous attendre à la disponibilité des journaux dans l'heure suivant la demande. Contactez votre équipe de compte Databricks pour plus d’informations.
Pour connaître les limitations générales des points de terminaison de service de modèle, consultez limites et régions du service de modèle.