HorovodRunner : Deep Learning distribué avec Horovod
Découvrez comment effectuer l’apprentissage distribué de modèles Machine Learning à l’aide de HorovodRunner pour lancer des travaux de formation Horovod en tant que travaux Spark sur Azure Databricks.
Qu’est-ce que HorovodRunner ?
HorovodRunner est une API générale permettant d’exécuter des charges de travail d’apprentissage profond distribuées sur Azure Databricks à l’aide de l’infrastructure Horovod . En intégrant Horovod au mode barrière de Spark, Azure Databricks est en mesure d'offrir une plus grande stabilité aux travaux de formation d'apprentissage profond de longue durée sur Spark. HorovodRunner prend une méthode Python qui contient le code d’apprentissage approfondi avec des crochets Horovod. HorovodRunner condiments la méthode sur le pilote et la distribue aux Workers Spark. Une tâche MPI Horovod est incorporée en tant que tâche Spark à l’aide du mode d’exécution de cloisonnement. Le premier exécuteur collecte les adresses IP de tous les exécuteurs de tâches à l’aide BarrierTaskContext de et déclenche une tâche Horovod à l’aide de mpirun. Chaque processus MPI python charge le programme utilisateur Pickle, le désérialise et l’exécute.
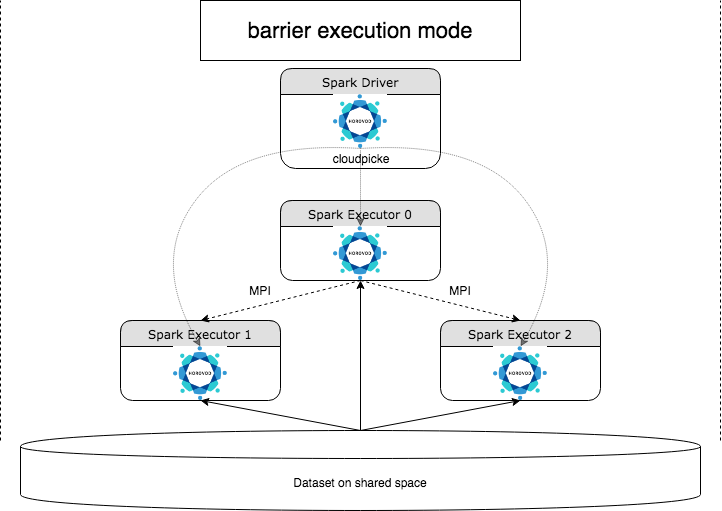
Entraînement distribué avec HorovodRunner
HorovodRunner vous permet de lancer des travaux de formation Horovod en tant que travaux Spark. L’API HorovodRunner prend en charge les méthodes indiquées dans le tableau. Pour plus d’informations, consultez la documentation de l'API HorovodRunner.
| Méthode et signature | Description |
|---|---|
init(self, np) |
Créez une instance de HorovodRunner. |
run(self, main, **kwargs) |
Exécutez un travail de formation Horovod appelant main(**kwargs) . La fonction principale et les arguments de mot clé sont sérialisés à l’aide de cloudpickle et distribués aux Workers de cluster. |
L’approche générale du développement d’un programme de formation distribué à l’aide de HorovodRunner est la suivante :
- Créez une instance
HorovodRunnerinitialisée avec le nombre de nœuds. - Définissez une méthode d’apprentissage Horovod en fonction des méthodes décrites dans utilisation de Horovod, en veillant à ajouter des instructions Import à l’intérieur de la méthode.
- Transmettez la méthode d’apprentissage à l'instance
HorovodRunner.
Par exemple :
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Pour exécuter HorovodRunner sur le pilote uniquement avec les sous-processus n, utilisez hr = HorovodRunner(np=-n) . Par exemple, s’il y a 4 GPU sur le nœud du pilote, vous pouvez choisir n jusqu’à 4 . Pour plus d’informations sur le paramètre np, consultez la documentation de HorovodRunner AP. Pour plus d’informations sur l’épinglage d’un GPU par sous-processus, consultez le Guide d’utilisation de Horovod.
Une erreur courante est que les objets TensorFlow sont introuvables ou Pickle. Cela se produit lorsque les instructions d’importation de bibliothèque ne sont pas distribuées à d’autres exécuteurs. Pour éviter ce problème, incluez toutes les déclarations d'importation (par exemple, import tensorflow as tf) ainsi que en haut de la méthode d'apprentissage Horovod et à l'intérieur de toute autre fonction définie par l'utilisateur appelée dans la méthode d'apprentissage Horovod.
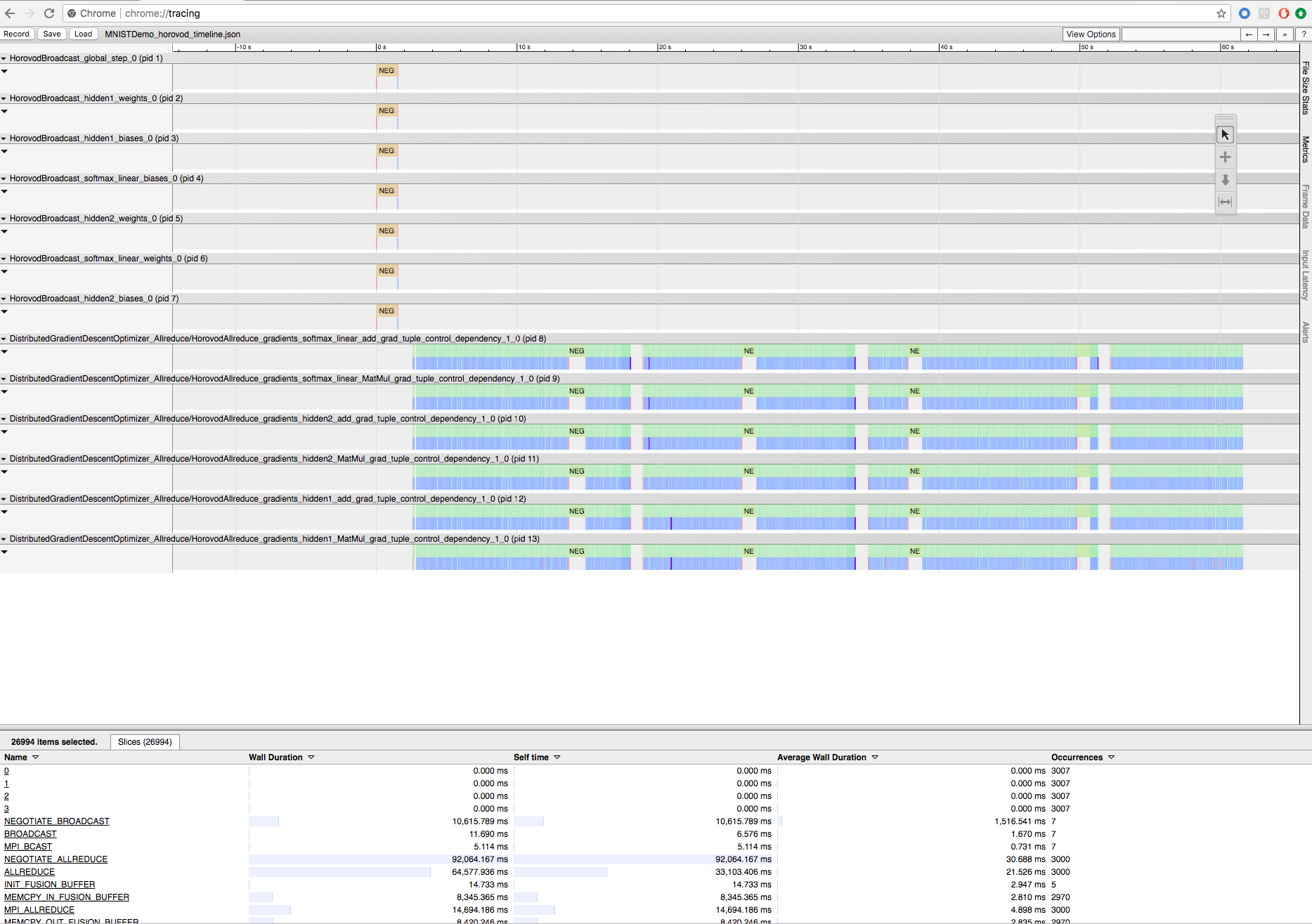
Enregistrer l’entraînement Horovod avec Horovod Timeline
Horovod a la possibilité d’enregistrer la chronologie de son activité, appelée chronologie Horovod.
Important
La chronologie Horovod a un impact significatif sur les performances. Le débit Inception3 peut diminuer d’environ 40% lorsque la chronologie Horovod est activée. Pour accélérer les tâches HorovodRunner, n’utilisez pas la chronologie Horovod.
Vous ne pouvez pas afficher la chronologie Horovod pendant que la formation est en cours.
Pour enregistrer une chronologie Horovod, définissez la variable d’environnement HOROVOD_TIMELINE à l’emplacement où vous souhaitez enregistrer le fichier de chronologie. Databricks recommande d’utiliser un emplacement sur un stockage partagé afin que le fichier de chronologie puisse être récupéré facilement. Par exemple, vous pouvez utiliser les API de fichier local DBFS comme indiqué ci-dessous :
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Ajoutez ensuite du code spécifique à la chronologie au début et à la fin de la fonction d’apprentissage. L’exemple de notebook suivant contient un exemple de code que vous pouvez utiliser comme solution de contournement pour voir la progression de l’entraînement.
Exemple de bloc-notes Horovod
Pour télécharger le fichier chronologique, utilisez l’interface CLI Databricks puis utilisez la fonctionnalité chrome://tracing du navigateur Chrome pour le visualiser. Par exemple :
Workflow de développement
Voici les étapes générales de la migration d’un code d’apprentissage profond à nœud unique vers une formation distribuée. Ces étapes sont illustrées dans Exemples : Migrer vers le Deep Learning distribué avec HorovodRunner dans cette même section.
- Préparer le code à un seul nœud : Préparez et testez le code à nœud unique avec TensorFlow, keras ou PyTorch.
- Migrer vers Horovod : Suivez les instructions de l'utilisation de Horovod pour migrer le code avec Horovod et testez-le sur le pilote :
- Ajoutez
hvd.init()pour initialiser Horovod. - Épinglez un GPU de serveur devant être utilisé par ce processus à l’aide de
config.gpu_options.visible_device_list. Avec la configuration par défaut d’un GPU par processus, vous pouvez définir le rang local. Dans ce cas, le premier processus sur le serveur sera alloué au premier GPU, le second processus recevra le deuxième GPU, et ainsi de suite. - Incluez un partition du jeu de données. Cet opérateur de jeu de données est très utile lors de l’exécution de la formation distribuée, car il permet à chaque thread de travail de lire un sous-ensemble unique.
- Mettez à l’échelle le taux d’apprentissage par nombre de Workers. La taille de lot effective dans une formation distribuée synchrone est mise à l’échelle par le nombre de Workers. L’augmentation du taux d’apprentissage compense l’augmentation de la taille du lot.
- Encapsulez l’optimiseur dans
hvd.DistributedOptimizer. L’optimiseur distribué délègue le calcul du gradient à l’optimiseur d’origine, calcule la moyenne des dégradés à l’aide de allreduce ou allgather, puis applique les dégradés de moyenne. - Ajoutez
hvd.BroadcastGlobalVariablesHook(0)pour diffuser les États des variables initiales du rang 0 à tous les autres processus. Ceci est nécessaire pour assurer une initialisation cohérente de tous les workers lorsque la formation est lancée avec des poids aléatoires ou restaurée à partir d'un point de contrôle. Si vous n’utilisez pasMonitoredTrainingSession, vous pouvez également exécuter l'opérationhvd.broadcast_global_variablesaprès l’initialisation des variables globales. - Modifiez votre code pour enregistrer les points de contrôle uniquement sur le Worker 0 pour empêcher d’autres utilisateurs de les corrompre.
- Ajoutez
- Migrer vers HorovodRunner : HorovodRunner exécute la tâche de formation Horovod en appelant une fonction Python. Vous devez regrouper la procédure principale de formation dans une seule fonction Python. Vous pouvez ensuite tester HorovodRunner en mode local et en mode distribué.
Mettre à jour les bibliothèques de Deep Learning
Notes
Cet article contient des références au terme esclave, un terme qu’Azure Databricks n’utilise pas. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Si vous mettez à niveau ou rétrogradez TensorFlow, keras ou PyTorch, vous devez réinstaller Horovod afin qu’il soit compilé avec la bibliothèque nouvellement installée. Par exemple, si vous souhaitez mettre à niveau TensorFlow, Databricks recommande l’utilisation du script init à partir des instructions d’installation de TensorFlow et l’ajout du code d’installation Horovod spécifique TensorFlow suivant à la fin de celui-ci. Consultez les instructions d’installation de Horovod pour travailler avec différentes combinaisons, telles que la mise à niveau ou la rétrogradation de PyTorch et d’autres bibliothèques.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Exemples : Migrer vers le Deep Learning distribué avec HorovodRunner
Les exemples suivants, basés sur le jeu de données MNIST , montrent comment migrer un programme d’apprentissage profond à nœud unique vers un apprentissage profond distribué avec HorovodRunner.
- Deep learning à l’aide de TensorFlow avec HorovodRunner pour MNIST
- Adaptez le nœud unique PyTorch pour le Deep Learning distribué
Limites
- Lorsque vous utilisez des fichiers d’espace de travail, HorovodRunner ne fonctionnera pas si
npest défini sur une valeur supérieure à 1 et si le notebook s’importe depuis d’autres fichiers relatifs. Envisagez d’utiliser horovod.spark au lieu deHorovodRunner. - Si vous rencontrez des erreurs telles que
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer, cela indique un problème de communication réseau entre les nœuds de votre cluster. Pour résoudre cette erreur, ajoutez l’extrait de code suivant dans votre code d’entraînement pour utiliser l’interface réseau principale.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour