Databricks Autologging
Cette page explique comment personnaliser Databricks Autologging, qui capture automatiquement les paramètres des modèles, les métriques, les fichiers et les informations de lignage lorsque vous entraînez des modèles à partir d'une variété de bibliothèques d'apprentissage automatique populaires. Les sessions de formation sont enregistrées en tant qu’exécutions de suivi MLflow. Les fichiers de modèle sont également suivis afin que vous puissiez facilement les enregistrer dans le registre de modèles MLflow.
Remarque
Pour activer la journalisation des traces pour les charges de travail IA génératives, MLflow prend en charge la mise en place automatique d’OpenAI.
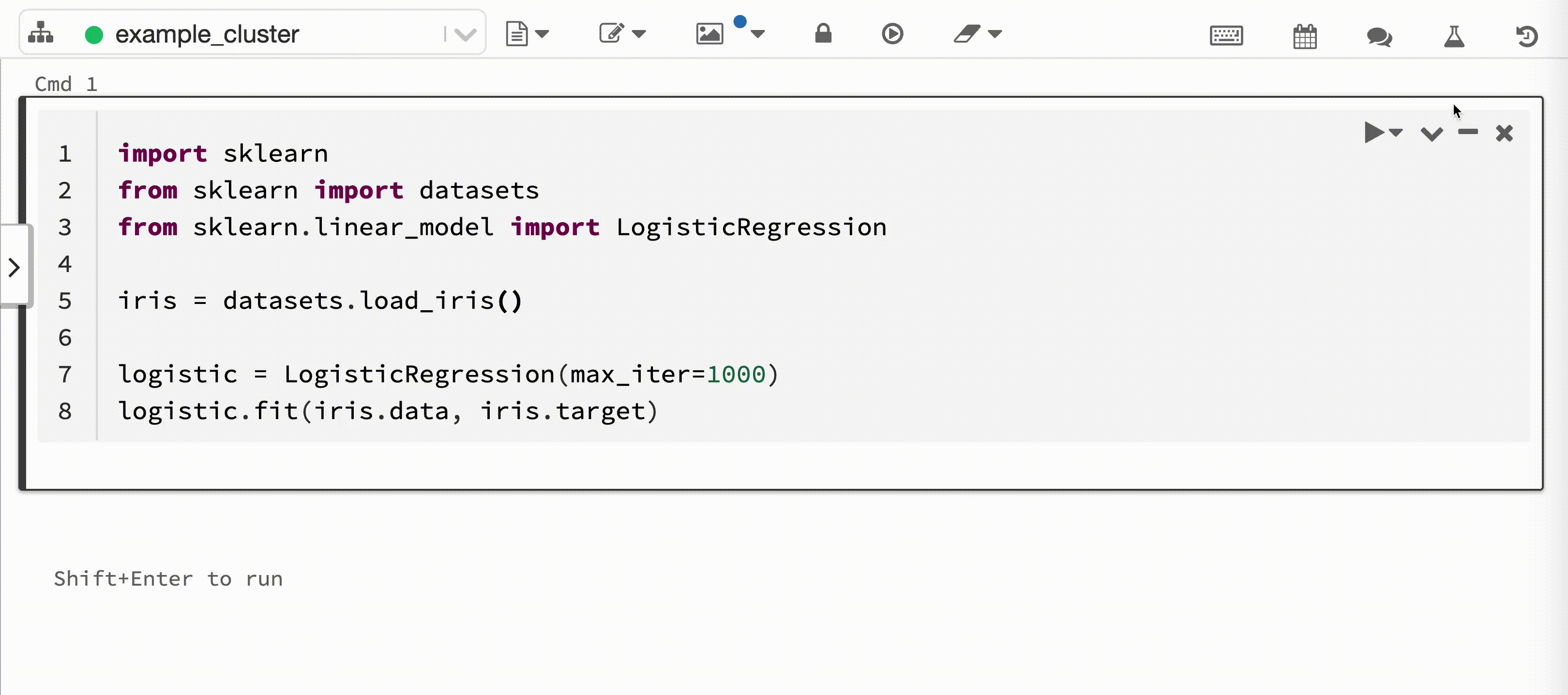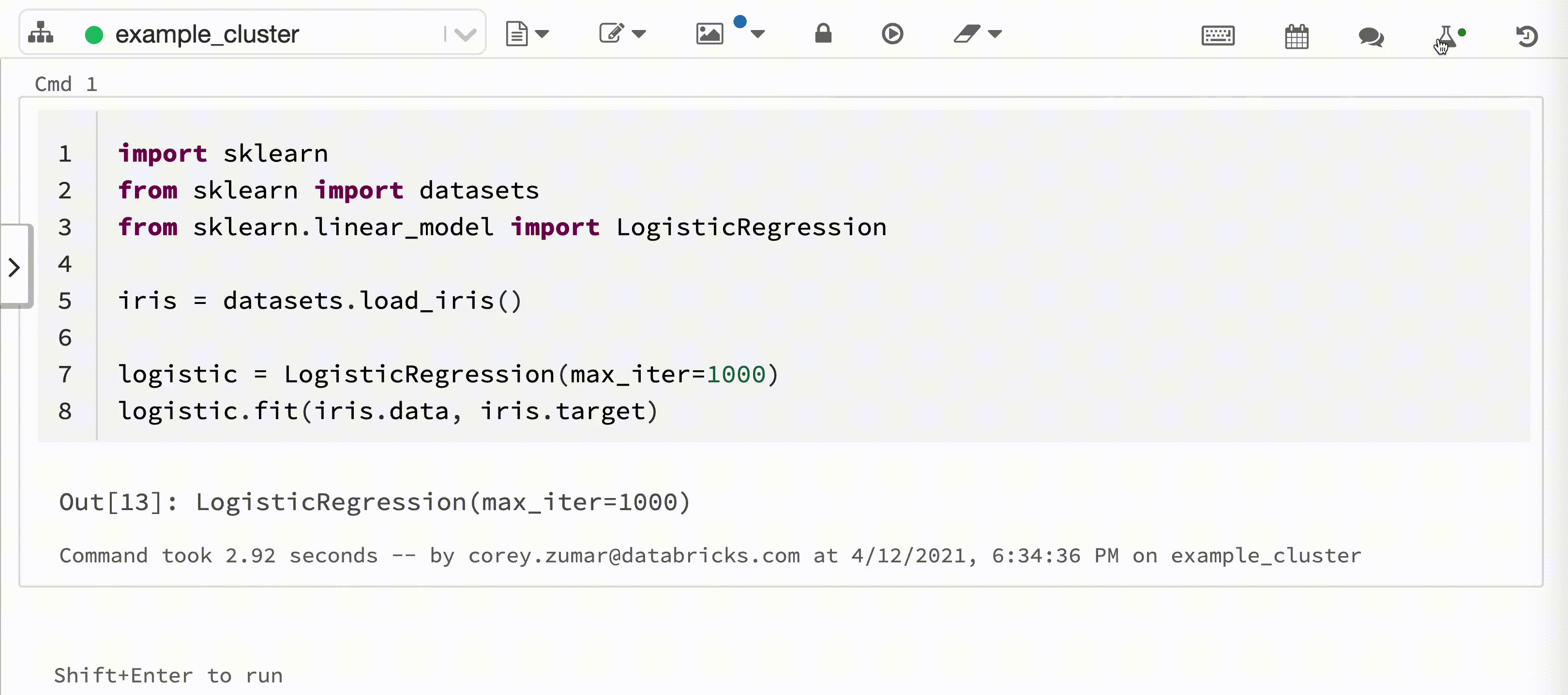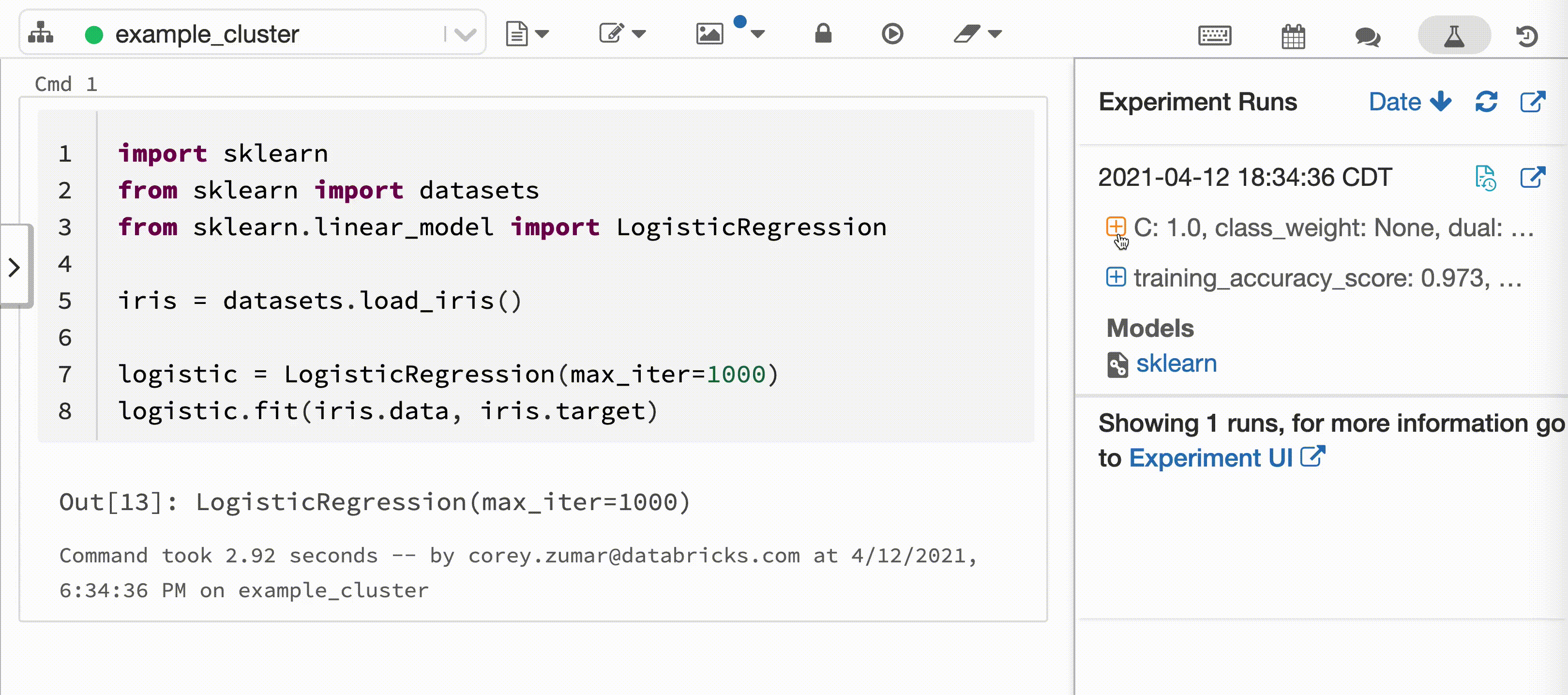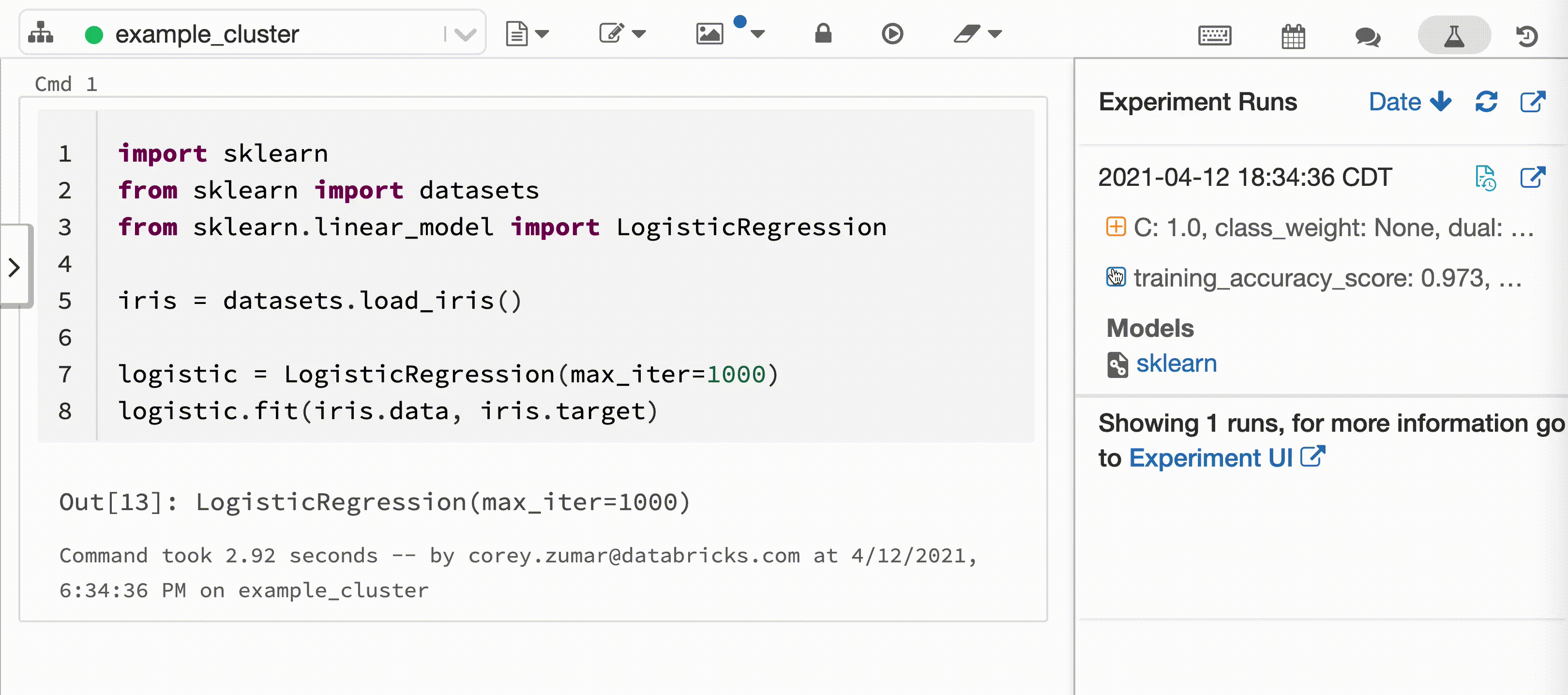
La vidéo suivante montre Databricks Autologging avec une session de formation de modèles à l’aide d’un modèle scikit-learn dans un notebook Python interactif. Les informations de suivi sont automatiquement capturées et affichées dans la barre latérale Experiment Runs (Exécutions d’expériences) et dans l’interface utilisateur MLflow.
Spécifications
- Databricks Autologging est généralement disponible dans toutes les régions avec Databricks Runtime 10.4 LTS ML ou versions ultérieures.
- Databricks Autologging est disponible dans certaines régions en préversion avec Databricks Runtime 9.1 LTS ML ou versions ultérieures.
Fonctionnement
Lorsque vous attachez un notebook interactif Python à un cluster Azure Databricks, Databricks Autologging appelle mlflow.autolog() pour configurer le suivi de vos sessions d’apprentissage du modèle. Lorsque vous formez des modèles dans le notebook, les informations de formation de modèles sont automatiquement suivies avec MLflow Tracking. Pour plus de détails sur la manière dont ces informations de formation de modèles sont sécurisées et gérées, voir Sécurité et gestion des données.
La configuration par défaut de l'appel mlflow.autolog() est la suivante :
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Vous pouvez personnaliser la configuration de la journalisation automatique.
Usage
Pour utiliser Databricks Autologging, formez un modèle de Machine Learning dans une infrastructure prise en charge à l'aide d'un notebook Python Azure Databricks interactif. Databricks Autologging consigne automatiquement les informations de traçabilité du modèle, les paramètres et les métriques dans MLflow Tracking. Vous pouvez également personnaliser le comportement de Databricks Autologging.
Notes
Autologation Databricks ne s’applique pas aux exécutions créées à l'aide de l'API Fluent MLflow avec mlflow.start_run(). Dans ces cas, vous devez appeler mlflow.autolog() pour sauvegarder le contenu automatiquement journalisé dans l'exécution du MLflow. Voir Suivre du contenu supplémentaire.
Personnaliser le comportement de la journalisation
Pour personnaliser la journalisation, utilisez mlflow.autolog().
Cette fonction fournit des paramètres de configuration pour activer la journalisation des modèles (log_models), enregistrer les jeux de données (log_datasets), collecter des exemples d’entrée (log_input_examples), enregistrer les signatures des modèles (log_model_signatures), configurer les avertissements (silent), et plus encore.
Suivre du contenu supplémentaire
Pour suivre d’autres métriques, paramètres, fichiers et métadonnées avec les exécutions MLflow créées par Databricks Autologging, suivez ces étapes dans un notebook interactif Python Azure Databricks :
- Appelez mlflow.autolog() avec
exclusive=False. - Démarrez une exécution MLflow en utilisant mlflow.start_run().
Vous pouvez envelopper cet appel dans
with mlflow.start_run(); dans ce cas, l'exécution se termine automatiquement après son achèvement. - Utilisez les méthodes de suivi MLflow, par exemple mlflow.log_param(), pour suivre le contenu de pré-formation.
- Formez un ou plusieurs modèles de Machine Learning dans une infrastructure prise en charge par Databricks Autologging.
- Utilisez les méthodes de suivi MLflow, par exemple mlflow.log_metric(), pour suivre le contenu de post-formation.
- Si vous n'avez pas utilisé
with mlflow.start_run()à l'étape 2, terminez l'exécution de MLflow à l’aide de mlflow.end_run().
Par exemple :
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Désactiver Databricks Autologging
Pour désactiver Databricks Autologging dans un notebook interactif Python Azure Databricks, appelez mlflow.autolog() avec disable=True :
import mlflow
mlflow.autolog(disable=True)
Les administrateurs peuvent également désactiver Databricks Autologging pour tous les clusters d’un espace de travail à partir de l’onglet Avancé de la page Paramètres d’administration. Les clusters doivent être redémarrés pour que ce changement prenne effet.
Environnements et infrastructures pris en charge
Databricks Autologging est pris en charge dans les notebooks Python interactifs et est disponible pour les infrastructures ML suivantes :
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluon
- Fast.ai
- statsmodels
- PaddlePaddle
- OpenAI
- LangChain
Pour plus d'informations sur chacune des infrastructures prises en charge, voir Journalisation automatique MLflow.
Activation du suivi MLflow
Le suivi MLflow utilise la fonctionnalité autolog dans les intégrations respectives de cadre de modèle pour contrôler l’activation ou la désactivation de la prise en charge du suivi pour les intégrations qui prennent en charge le suivi.
Par exemple, pour activer le suivi lors de l’utilisation d’un modèle LlamaIndex, utilisez mlflow.llama_index.autolog() avec log_traces=True :
import mlflow
mlflow.llama_index.autolog(log_traces=True)
Les intégrations prises en charge qui ont l’activation du suivi dans leurs implémentations de journal automatique sont les suivantes :
Sécurité et gestion des données
Toutes les informations de formation de modèles suivies avec Databricks Autologging sont stockées dans MLflow Tracking et sécurisées à l’aide des autorisations d’expérience MLflow. Vous pouvez partager, modifier ou supprimer les informations de formation des modèles en utilisant l’API MLflow Tracking ou l'interface utilisateur.
Administration
Les administrateurs peuvent activer ou désactiver Databricks Autologging pour toutes les sessions interactives de notebooks de leur espace de travail dans l’onglet Avancé de la page de Paramètres d’administration. Les changements ne prennent pas effet tant que le cluster n'est pas redémarré.
Limites
- Databricks Autologging n'est pas pris en charge dans les travaux Azure Databricks. Pour utiliser la journalisation automatique à partir de travaux, vous pouvez appeler explicitement mlflow.autolog().
- Databricks Autologging est activé uniquement sur le nœud pilote de votre cluster Azure Databricks. Pour utiliser la journalisation automatique à partir de nœuds worker, vous devez appeler explicitement mlflow.autolog() à partir du code s'exécutant sur chaque worker.
- L'intégration XGBoost scikit-learn n'est pas prise en charge.
Apache Spark MLlib, Hyperopt et suivi MLflow automatisé
Databricks Autologging ne modifie pas le comportement des intégrations existantes de suivi MLflow automatisé pour Apache Spark MLlib et Hyperopt.
Notes
Dans Databricks Runtime 10.1 ML, la désactivation de l'intégration du suivi MLflow automatisé pour les modèles MLlib Apache Spark CrossValidator et TrainValidationSplit désactive également la fonction Databricks Autologging pour tous les modèles MLlib Apache Spark.