Avril 2018
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Remarque
Nous fournissons désormais des avis de dépréciation de Databricks Runtime dans les versions et la compatibilité des notes de publication de Databricks Runtime.
Secrets CLI
26 avril 2018
Databricks CLI version 0.7.0 vous donne la possibilité de gérer les secrets à partir de la ligne de commande. La documentation sur les secrets montre maintenant comment utiliser les commandes CLI de secrets pour créer et gérer des secrets.
Consultez Gestion des secrets.
Guides du Deep Learning
24 avril 2018
Nous avons ajouté de la documentation pour le Deep Learning sur Azure Databricks à l’aide de clusters UC.
Consultez Deep Learning.
Mise à jour de l’API Secrets pour la création d’une étendue de secrets
25 avril-1er mai 2018 : version 2.70
Le point de terminaison Créer une étendue de secret (2.0/preview/secret/scopes/create) déprécie désormais le champ initial_manage_acl et utilise initial_manage_principal à la place. Le nouveau champ fournit les mêmes fonctionnalités mais une meilleure sémantique.
Consultez l’API Secrets.
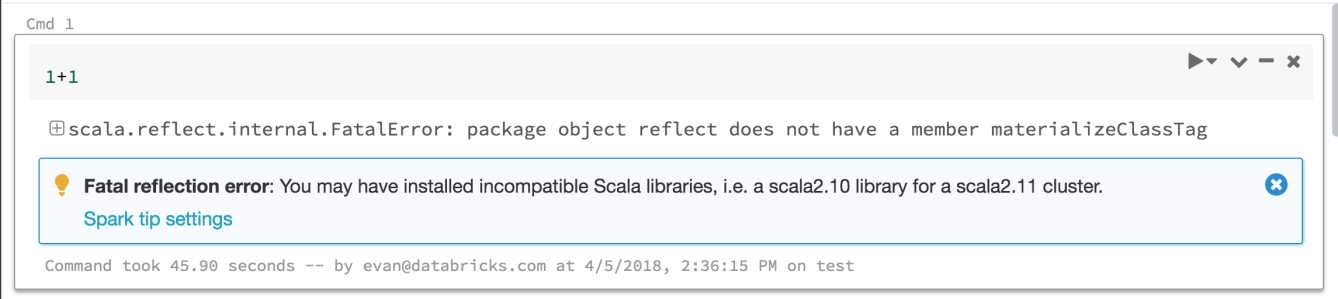
Conseils sur les erreurs Spark
24 avril-1er mai 2018 : version 2.70
Azure Databricks fournit maintenant des conseils pour vous aider à interpréter et à résoudre la plupart des erreurs que vous pouvez rencontrer lors de l’exécution de commandes Spark. Nous continuerons à en ajouter d’autres.
Databricks CLI 0.7.0
24 avril 2018
Databricks CLI 0.7.0 comprend des correctifs de bogues.
La version fournit également une interface de ligne de commande à l’API Secrets.
Consultez l’interface CLI Databricks (héritée).
Augmenter la limite de troncation de la sortie des scripts init
24 avril-1er mai 2018 : version 2.70
Nous avons augmenté la limite de troncation de sortie pour les scripts init à 500 000 caractères.
Voir Que sont les scripts d'initialisation ?.
API Clusters : ajout du type d’événement UPSIZE_COMPLETED
24 avril-1er mai 2018 : version 2.70
Le nouveau type d’événement de cluster UPSIZE_COMPLETED indique que les nœuds ont fini d’être ajoutés à un cluster.
Consultez l’API Clusters dans la référence de l’API Clusters.
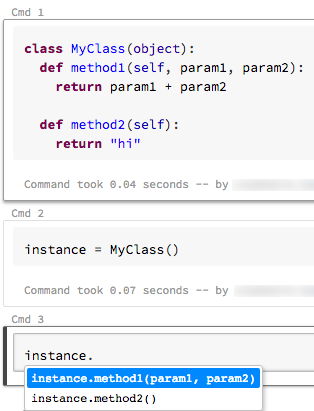
Autocomplétion des commandes
10 - 17 avril 2018 : Version 2.69
Azure Databricks prend désormais en charge deux types d’autocomplétion dans vos notebooks : local et serveur. L’autocomplétion locale complète les mots qui existent dans le notebook. L’autocomplétion du serveur est plus puissante, car elle accède au cluster pour les types, les classes et les objets définis, ainsi que la base de données SQL et les tables. Pour activer l’autocomplétion du serveur, vous devez joindre votre notebook à un cluster en cours d’exécution et exécuter toutes les cellules qui définissent des objets pouvant être mis à la valeur.
Pools serverless mis à niveau vers Databricks Runtime 4.0
10 avril 2018
La version du runtime des pools serverless a été mise à niveau à partir de Databricks Runtime 3.5 (qui inclut Apache Spark 2.2.1) vers Databricks Runtime 4.0 (qui inclut Apache Spark 2.3.0). Vous devez redémarrer vos clusters pour récupérer cette modification.
La mise à niveau représente une mise à jour de version mineure Apache Spark et une compatibilité descendante.
Consultez Informations de référence sur la configuration de calcul.