Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Databricks Runtime pour le Machine Learning (Databricks Runtime ML) fournit une infrastructure de Machine Learning prédéfinie qui est intégrée à toutes les fonctionnalités de l’espace de travail Azure Databricks. Chaque version de Databricks Runtime ML est basée sur la version correspondante de Databricks Runtime. Par exemple, Databricks Runtime 12.2 LTS pour le Machine Learning repose sur Databricks Runtime 12.2 LTS.
Pour plus d’informations sur les fonctionnalités de chaque version de Databricks Runtime ML, y compris la liste complète des bibliothèques incluses, consultez les notes de publication.
Pourquoi utiliser Databricks Runtime pour le Machine Learning ?
Databricks Runtime ML automatise la création d’un cluster optimisé pour le Machine Learning. Voici quelques-uns des avantages de l’utilisation de clusters Databricks Runtime ML :
- Bibliothèques de Machine Learning populaires intégrées, telles que TensorFlow, PyTorch, Keras et XGBoost.
- Bibliothèques d’entraînement distribué intégrées, telles que Horovod.
- Versions compatibles des bibliothèques installées.
- Prise en charge des GPU préconfigurés, y compris les pilotes et les bibliothèques de prise en charge.
- Création de cluster plus rapide.
Avec Azure Databricks, vous pouvez utiliser n’importe quelle bibliothèque pour créer la logique permettant d’effectuer l’apprentissage de votre modèle. Databricks Runtime ML préconfiguré permet de mettre à l’échelle facilement les étapes courantes du Machine Learning et du Deep Learning.
Databricks Runtime ML inclut également toutes les fonctionnalités de l’espace de travail Azure Databricks, telles que :
- Exploration, gestion et gouvernance des données.
- Création et gestion de cluster.
- Gestion de la bibliothèque et de l’environnement.
- Gestion du code avec Databricks Repos.
- Prise en charge de l’automatisation, notamment Delta Live Tables, Databricks Jobs et API.
- MLflow intégré pour le suivi du développement de modèles, le déploiement et la mise en service de modèles et l’inférence en temps réel.
Pour obtenir des informations complètes sur l’utilisation d’Azure Databricks pour le Machine Learning et le Deep Learning, consultez Présentation de Databricks Machine Learning.
Bibliothèques incluses dans Databricks Runtime ML
Le ML Databricks Runtime comprend une variété de bibliothèques ML populaires. Les bibliothèques sont mises à jour avec chaque version pour inclure de nouvelles fonctionnalités et des correctifs.
Azure Databricks a désigné un sous-ensemble des bibliothèques prises en charge en tant que bibliothèques de niveau supérieur. Pour ces bibliothèques, Azure Databricks offre une cadence de mise à jour plus rapide, en mettant à jour les versions les plus récentes des packages avec chaque version du Runtime (conflits de dépendances). Azure Databricks fournit également une prise en charge avancée, des tests et des optimisations incorporées pour les bibliothèques de niveau supérieur.
Pour obtenir la liste complète des bibliothèques de niveau supérieur et des autres bibliothèques fournies, consultez les notes de publication de Databricks Runtime ML.
Créer un cluster en utilisant Databricks Runtime ML
Lorsque vous créez un cluster, sélectionnez une version de Databricks Runtime ML dans le menu déroulant Version Databricks Runtime. Les runtimes de ML UC et GPU sont disponibles.
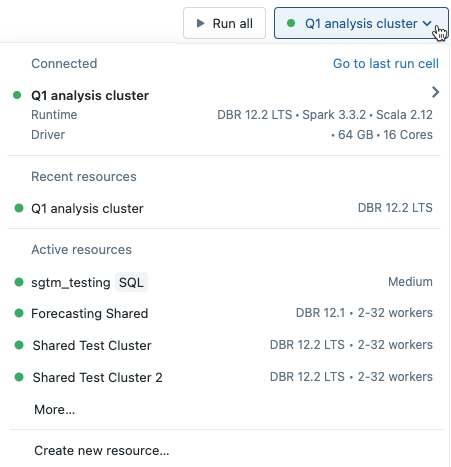
Si vous sélectionnez un cluster dans le menu déroulant du notebook, la version de Databricks Runtime s’affiche à droite du nom du cluster :
Si vous sélectionnez un runtime ML avec GPU, vous êtes invité à sélectionner un Type de pilote et un Type de Workercompatibles. Les types d’instance incompatibles sont grisés dans les menus déroulants. Les types d’instances avec GPU sont répertoriés sous l’étiquette Accéléré GPU.
Notes
Pour accéder aux données dans Unity Catalog pour les flux de travail Machine Learning, le mode d’accès du cluster doit être un utilisateur unique (affecté). Les clusters partagés ne sont pas compatibles avec Databricks Runtime pour le Machine Learning.
Gérer les packages Python
Databricks Runtime ML diffère de Databricks Runtime par la façon dont vous gérez les packages Python. Dans Databricks Runtime ML, le gestionnaire de package virtualenv est utilisé pour installer les packages Python. Tous les packages Python sont installés dans un environnement unique : /databricks/python3 .
Pour plus d’informations sur la gestion des bibliothèques Python, consultez bibliothèques.
Prise en charge du Machine Learning automatisé
Databricks Runtime ML comprend des outils pour automatiser le processus de développement de modèle et vous aider à trouver efficacement le modèle le plus performant.
- AutoML crée, ajuste et évalue automatiquement un ensemble de modèles et crée un bloc-notes Python avec le code source pour chaque exécution afin que vous puissiez examiner, reproduire et modifier le code.
- MLFlow managé gère le cycle de vie du modèle de bout en bout, notamment le suivi des exécutions expérimentales, le déploiement et le partage de modèles et la gestion d’un registre de modèle centralisé.
- Hyperopt, qui est complété avec la classe
SparkTrials, automatise et distribue ML le paramétrage du modèle de modèle.
Limites
Databricks Runtime ML n’est pas pris en charge sur :
- Les clusters TableACL.
- Les clusters UC partagés.
- Les clusters avec
spark.databricks.pyspark.enableProcessIsolation configdéfini surtrue.