Récupération d’urgence régionale pour les clusters Azure Databricks
Cet article décrit une architecture de récupération d’urgence utile pour les clusters Azure Databricks, ainsi que les étapes à suivre pour réaliser cette conception.
Architecture Azure Databricks
Lorsque vous créez un espace de travail Azure Databricks sur le portail Azure, une application managée est déployée sous forme de ressource Azure dans votre abonnement, dans la région Azure choisie (par exemple, USA Ouest). Ce déploiement s’effectue dans un Réseau virtuel Azure avec un Groupe de sécurité réseau et un compte de Stockage Azure, disponible dans votre abonnement. Le réseau virtuel assure la sécurité au niveau du périmètre de l’espace de travail Databricks ; il est protégé au moyen du groupe de sécurité réseau. Dans l’espace de travail, vous créez des clusters Databricks en indiquant le type de machine virtuelle de travail/pilote et la version du runtime Databricks. Les données persistantes sont disponibles dans votre compte de stockage. Une fois le cluster créé, vous pouvez exécuter des travaux par le biais de notebooks, d’API REST ou de points de terminaison ODBC/JDBC en les attachant à un cluster spécifique.
Le plan de contrôle Databricks gère et surveille l’environnement de l’espace de travail Databricks. Toutes les opérations de gestion, comme la création d’un cluster, seront lancées à partir du plan de contrôle. Toutes les métadonnées, telles que les travaux planifiés, sont stockées dans une base de données Azure, et les sauvegardes de base de données sont automatiquement géorépliquées dans les régions jumelées où elles sont implémentées.
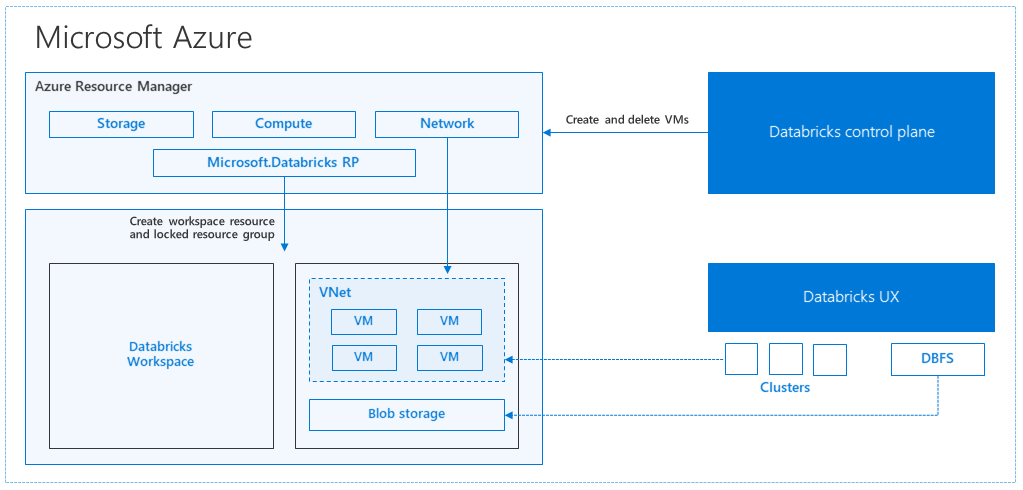
L’un des avantages de cette architecture est que les utilisateurs peuvent connecter Azure Databricks à n’importe quelle ressource de stockage de leur compte. Par ailleurs, le calcul (Azure Databricks) et le stockage peuvent évoluer indépendamment l’un de l’autre.
Créer une topologie de récupération d’urgence régionale
Dans la description de l’architecture précédente, différents composants sont utilisés pour un pipeline de Big Data avec Azure Databricks : le Stockage Azure, Azure Database et d’autres sources de données. Azure Databricks est le volet calcul du pipeline de Big Data. Il est éphémère par nature, ce qui signifie qu’il est possible de terminer le calcul (cluster Azure Databricks) afin d’éviter de le payer inutilement, tandis que les données restent disponibles dans le Stockage Azure. Le calcul (Azure Databricks) et les sources de stockage doivent être dans la même région pour éviter que les travaux ne subissent une latence élevée.
Pour créer votre propre topologie de récupération d’urgence régionale, respectez les exigences suivantes :
Approvisionnez plusieurs espaces de travail Azure Databricks dans des régions Azure distinctes. Par exemple, créez l’espace de travail Azure Databricks principal dans USA Est. Créez l’espace de travail Azure Databricks secondaire de récupération d’urgence dans une autre région, comme USA Ouest. Pour obtenir une liste des régions Azure appariées, voir Réplication interrégionale. Pour plus d’informations sur les régions Azure Databricks, voir Régions prises en charge.
Utilisez le stockage géoredondant. Par défaut, les données associées à Azure Databricks sont stockées dans le stockage Azure et les résultats des travaux Databricks sont stockés dans le stockage Blob Azure, afin que les données traitées soient durables et restent hautement disponibles une fois le cluster arrêté. Le stockage de cluster et le stockage de travail se trouvent dans la même zone de disponibilité. Pour vous protéger contre l’indisponibilité régionale, les espaces de travail Azure Databricks utilisent le stockage géoredondant par défaut. Avec le stockage géoredondant, les données sont répliquées dans une région Azure jumelée. Databricks vous recommande de conserver la le stockage géoredondant par défaut, mais si vous avez besoin d’utiliser plutôt un stockage localement redondant, vous pouvez définir
storageAccountSkuNamesurStandard_LRSdans le modèle ARM pour l’espace de travail.Une fois la région secondaire créée, il vous faut migrer les utilisateurs, les dossiers utilisateur, les notebooks, la configuration du cluster et des travaux, les bibliothèques, le stockage et les scripts init, et reconfigurer le contrôle d’accès. Des détails supplémentaires sont donnés dans la section suivante.
Sinistre régional
Pour vous préparer aux sinistres régionaux, vous devez gérer explicitement un autre ensemble d’espaces de travail Azure Databricks dans une région secondaire. Consultez Récupération d'urgence.
Nos outils recommandés pour la récupération d’urgence sont principalement Terraform (pour la réplication Infra) et Delta Deep Clone (pour la réplication des données).
Étapes de migration détaillées
Configurez l’interface de ligne de commande Databricks sur votre ordinateur.
Cet article présente différents exemples de code qui utilisent l’interface de ligne de commande pour la plupart des étapes automatisées, puisqu’il s’agit d’un wrapper simple d'utilisation reposant sur l’API REST Azure Databricks.
Avant toute étape de migration, installez databricks-cli sur votre ordinateur de bureau ou une machine virtuelle sur laquelle vous prévoyez d’effectuer le travail. Pour plus d’informations, voir Installer l’interface CLI Databricks.
pip install databricks-cliNotes
Normalement, tous les scripts Python fournis dans cet article devraient fonctionner avec Python 2.7+ < 3.x.
Configurez deux profils.
Configurez-en un pour l’espace de travail principal et un autre pour l’espace de travail secondaire :
databricks configure --profile primary --token databricks configure --profile secondary --tokenLes blocs de code de cet article basculent d’un profil à l’autre à chaque étape à l’aide de la commande d’espace de travail correspondante. Veillez à ce que les noms des profils que vous créez soient intervertis dans chaque bloc de code.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"Vous pouvez basculer manuellement en ligne de commande si nécessaire :
databricks workspace ls --profile primary databricks workspace ls --profile secondaryMigrer les utilisateurs Microsoft Entra ID (anciennement Azure Active Directory)
Ajoutez manuellement à l’espace de travail secondaire les mêmes utilisateurs Microsoft Entra ID (anciennement Azure Active Directory) que ceux qui existent dans l’espace de travail principal.
Migrez les notebooks et les dossiers utilisateurs.
Utilisez le code Python suivant pour migrer les environnements utilisateurs sandbox, notamment la structure de dossiers imbriqués et les notebooks de chaque utilisateur.
Notes
Les bibliothèques ne sont pas copiées à cette étape, car l’API sous-jacente ne les prend pas en charge.
Copiez et enregistrez le script Python suivant dans un fichier et exécutez-le en ligne de commande Databricks. Par exemple :
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Migrer les configurations de cluster
Une fois les notebooks migrés, vous pouvez éventuellement migrer les configurations de cluster vers le nouvel espace de travail. Cette étape est presque entièrement automatisée avec databricks-cli, sauf en cas de migration de certaines configurations de cluster et non de la totalité.
Notes
Il n’existe malheureusement aucun point de terminaison de création de configuration de cluster, et ce script tente immédiatement de créer chaque cluster. S’il n’y a pas assez de cœurs disponibles dans votre abonnement, la création de cluster risque d’échouer. Cet échec peut être ignoré tant que la configuration est bel et bien transférée.
Le script fourni ci-dessous imprime un mappage entre les anciens et les nouveaux ID de cluster, qui pourra être utilisé par la suite pour la migration de travaux (ceux qui sont configurés pour utiliser des clusters existants).
Copiez et enregistrez le script Python suivant dans un fichier et exécutez-le en ligne de commande Databricks. Par exemple :
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Migrez la configuration des travaux.
Si vous avez migré des configurations de cluster à l’étape précédente, vous pouvez choisir de migrer les configurations de travaux vers le nouvel espace de travail. Cette étape est entièrement automatisée avec databricks-cli, sauf en cas de migration de certaines configurations de travaux et non de la totalité.
Notes
La configuration d’un travail planifié comporte également les informations de « planification » ; par défaut, il s’exécutera donc selon le planning configuré une fois migré. C’est pourquoi le bloc de code suivant supprime les informations de planification pendant la migration (afin d’éviter des exécutions en double entre les anciens et les nouveaux espaces de travail). Configurez la planification de ces travaux une fois que le basculement est prêt.
La configuration des travaux exige des paramètres pour un cluster actuel ou un nouveau cluster. Si vous utilisez un cluster existant, le code du script ci-dessous tente de remplacer l’ancien ID de cluster par le nouveau.
Copiez et enregistrez le script Python suivant dans un fichier. Remplacez la valeur de
old_cluster_idet denew_cluster_idpar la sortie de la migration de cluster effectuée à l’étape précédente. Exécutez-le en ligne de commande databricks-cli (par exemple,python scriptname.py).import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Migrez les bibliothèques.
Il n’existe actuellement aucun moyen de migrer directement les bibliothèques d’un espace de travail à un autre. Réinstallez-les manuellement dans le nouvel espace de travail. Il est possible d’automatiser l’opération à l’aide d’une combinaison entre l’interface CLI DBFS pour charger des bibliothèques personnalisées dans l’espace de travail et l’interface CLI Bibliothèques.
Migrez les montages Azure Data Lake Storage et Stockage Blob Azure.
Remontez manuellement tous les points de montage Stockage Blob Azure et Azure Data Lake Storage (Gen 2) à l’aide d’une solution basée sur des notebooks. Les ressources de stockage auront été montées dans l’espace de travail principal, et cette opération doit être répétée dans l’espace de travail secondaire. Il n’existe aucune API externe pour les montages.
Migrez les scripts d’initialisation de clusters.
Tous les scripts d’initialisation de cluster peuvent être migrés de l’ancien vers le nouvel espace de travail avec l’interface CLI DBFS. Tout d’abord, copiez les scripts nécessaires de
dbfs:/dat abricks/init/..vers votre poste de travail local ou votre machine virtuelle. Ensuite, copiez-les dans le nouvel espace de travail, au même chemin d’accès.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryReconfigurez et réappliquez manuellement le contrôle d’accès.
Si votre espace de travail principal existant est configuré pour utiliser le niveau Premium ou Enterprise (SKU), il est probable que vous utilisiez également la fonctionnalité de contrôle d'accès.
Si c’est le cas, réappliquez manuellement le contrôle d’accès aux ressources (notebooks, clusters, travaux, tables).
Récupération d’urgence pour votre écosystème Azure
Si vous utilisez d’autres services Azure, veillez à implémenter les meilleures pratiques de récupération d’urgence également pour ces services. Par exemple, si vous décidez d’utiliser une instance de metastore Hive externe, vous devez envisager la récupération d’urgence pour Azure SQL Database, Azure HDInsight et/ou Azure Database pour MySQL. Pour des informations générales sur la récupération d’urgence, voir Récupération d’urgence des applications Microsoft Azure.
Étapes suivantes
Pour plus d’informations, voir la documentation Azure Databricks.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour