Augmentation d’un modèle de langage volumineux avec la génération augmentée de récupération et le réglage précis
Les articles de cette série décrivent les modèles de récupération des connaissances que les modules LLM utilisent pour générer leurs réponses. Par défaut, un modèle de langage volumineux (LLM) n’a accès qu’à ses données d’apprentissage. Toutefois, vous pouvez augmenter le modèle pour inclure des données en temps réel ou des données privées. Cet article traite de l’un des deux mécanismes d’augmentation d’un modèle.
Le premier mécanisme est la génération d’extraction augmentée (RAG), qui est une forme de prétraitement qui combine la recherche sémantique avec l’priming contextuel (abordé dans un autre article).
Le deuxième mécanisme est un réglage précis, qui fait référence au processus de formation supplémentaire du modèle sur un jeu de données spécifique après sa formation initiale, étendue, avec l’objectif de l’adapter pour mieux effectuer des tâches ou comprendre les concepts liés à ce jeu de données. Ce processus aide le modèle à se spécialiser ou à améliorer sa précision et son efficacité dans la gestion de types particuliers d’entrée ou de domaines.
Les sections suivantes décrivent ces deux mécanismes plus en détail.
Présentation de RAG
RAG est souvent utilisé pour activer le scénario « discuter sur mes données », où les entreprises qui ont un grand corpus de contenu textuel (documents internes, documentation, etc.) et souhaitent utiliser ce corpus comme base pour les réponses aux invites des utilisateurs.
À un niveau élevé, vous créez une entrée de base de données pour chaque document (ou une partie d’un document appelé « bloc »). Le bloc est indexé sur son incorporation, un vecteur (tableau) de nombres qui représentent des facettes du document. Lorsqu’un utilisateur envoie une requête, vous recherchez dans la base de données des documents similaires, puis envoyez la requête et les documents au LLM pour composer une réponse.
Remarque
Terme de génération augmentée de récupération (RAG) accommodant. Le processus d’implémentation d’un système de conversation basé sur RAG décrit dans cet article peut être appliqué s’il existe une volonté d’utiliser des données externes à utiliser dans une capacité de support (RAG) ou pour être utilisé comme pièce centrale de la réponse (RCG). Cette distinction nuanceuse n’est pas abordée dans la plupart des lectures liées à RAG.
Création d’un index de documents vectorisés
La première étape de création d’un système de conversation basé sur RAG consiste à créer un magasin de données vectorielles contenant l’incorporation vectorielle du document (ou une partie du document). Considérez le diagramme suivant qui décrit les étapes de base de la création d’un index vectorisé de documents.

Ce diagramme représente un pipeline de données, qui est responsable de l’ingestion, du traitement et de la gestion des données utilisées par le système. Cela inclut le prétraitement des données à stocker dans la base de données vectorielle et s’assurer que les données transmises dans le LLM sont au format correct.
L’ensemble du processus est piloté par la notion d’incorporation, qui est une représentation numérique des données (généralement des mots, des expressions, des phrases, des phrases ou même des documents entiers) qui capture les propriétés sémantiques de l’entrée d’une manière qui peut être traitée par des modèles Machine Learning.
Pour créer une incorporation, vous envoyez le bloc de contenu (phrases, paragraphes ou documents entiers) à l’API d’incorporation Azure OpenAI. Ce qui est retourné à partir de l’API d’incorporation est un vecteur. Chaque valeur du vecteur représente une caractéristique (dimension) du contenu. Les dimensions peuvent inclure la matière des rubriques, la signification sémantique, la syntaxe et la grammaire, l’utilisation des mots et des expressions, les relations contextuelles, le style et le ton, etc. Ensemble, toutes les valeurs du vecteur représentent l’espace dimensionnel du contenu. En d’autres termes, si vous pouvez penser à une représentation 3D d’un vecteur avec trois valeurs, un vecteur donné vit dans une certaine zone du plan x, y, z. Que se passe-t-il si vous avez 1000 valeurs (ou plus) ? Même s’il n’est pas possible pour les humains de dessiner un graphique de 1 000 dimensions sur une feuille de papier pour le rendre plus compréhensible, les ordinateurs n’ont aucun problème à comprendre ce degré d’espace dimensionnel.
L’étape suivante du diagramme illustre le stockage du vecteur avec le contenu lui-même (ou un pointeur vers l’emplacement du contenu) et d’autres métadonnées dans une base de données vectorielle. Une base de données vectorielle est semblable à n’importe quel type de base de données, avec deux différences :
- Les bases de données vectorielles utilisent un vecteur comme index pour rechercher des données.
- Les bases de données vectorielles implémentent un algorithme appelé recherche similaire cosinus, également appelé voisin le plus proche, qui utilise des vecteurs qui correspondent le plus étroitement aux critères de recherche.
Avec le corpus de documents stockés dans une base de données vectorielle, les développeurs peuvent créer un composant de récupérateur qui récupère les documents correspondant à la requête de l’utilisateur à partir de la base de données afin de fournir au LLM ce dont il a besoin pour répondre à la requête de l’utilisateur.
Réponses aux requêtes avec vos documents
Un système RAG utilise d’abord la recherche sémantique pour rechercher des articles qui pourraient être utiles pour le LLM lors de la composition d’une réponse. L’étape suivante consiste à envoyer les articles correspondants ainsi qu’à l’invite d’origine de l’utilisateur à LLM pour composer une réponse.
Considérez le diagramme suivant comme une implémentation RAG simple (parfois appelée « RAG naïve »).
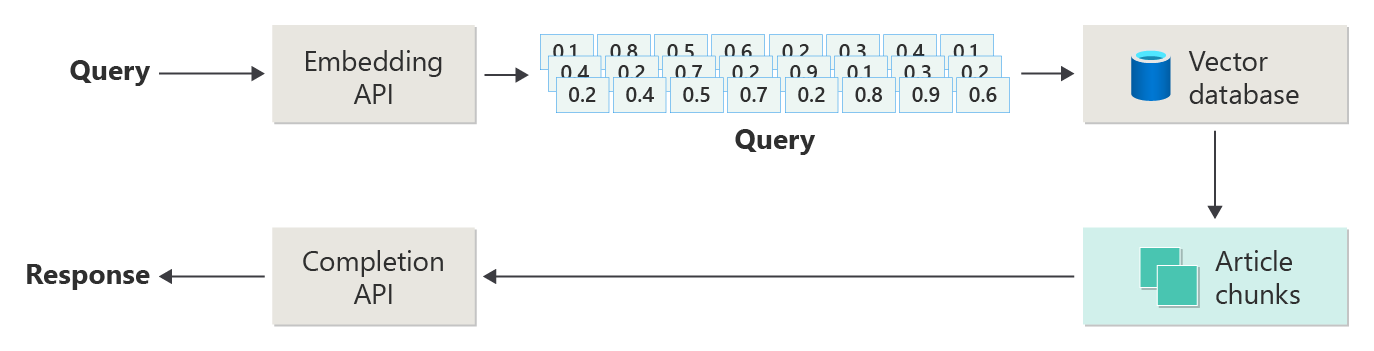
Dans le diagramme, un utilisateur envoie une requête. La première étape consiste à créer une incorporation pour l’invite de l’utilisateur afin de récupérer un vecteur. L’étape suivante consiste à rechercher la base de données vectorielle pour ces documents (ou parties de documents) qui sont une correspondance « voisin le plus proche ».
La similarité cosinus est une mesure utilisée pour déterminer la façon dont deux vecteurs similaires sont, essentiellement l’évaluation du cosinus de l’angle entre eux. Une similarité cosinus proche de 1 indique un degré élevé de similarité (petit angle), tandis qu’une similarité proche de -1 indique une dissimilarité (angle approchant de 180 degrés). Cette métrique est cruciale pour les tâches telles que la similarité des documents, où l’objectif est de trouver des documents avec du contenu ou une signification similaires.
Les algorithmes « Voisin le plus proche » fonctionnent en recherchant les vecteurs les plus proches (voisins) à un point donné dans l’espace vectoriel. Dans l’algorithme k-nearest neighbors (KNN), 'k' fait référence au nombre de voisins les plus proches à prendre en compte. Cette approche est largement utilisée dans la classification et la régression, où l’algorithme prédit l’étiquette d’un nouveau point de données en fonction de l’étiquette majoritaire de ses voisins les plus proches dans le jeu d’entraînement. La similarité KNN et cosinus est souvent utilisée ensemble dans des systèmes comme les moteurs de recommandation, où l’objectif est de trouver des éléments les plus similaires aux préférences d’un utilisateur, représentés en tant que vecteurs dans l’espace d’incorporation.
Vous prenez les meilleurs résultats de cette recherche et envoyez le contenu correspondant avec l’invite de l’utilisateur pour générer une réponse qui (espérons-le) est informée par le contenu correspondant.
Défis et considérations
L’implémentation d’un système RAG est fournie avec son ensemble de défis. La confidentialité des données est primordiale, car le système doit gérer les données utilisateur de manière responsable, en particulier lors de la récupération et du traitement des informations à partir de sources externes. Les exigences de calcul peuvent également être significatives, car les processus de récupération et de génération sont gourmands en ressources. Garantir la précision et la pertinence des réponses tout en gérant les biais présents dans les données ou le modèle est une autre considération essentielle. Les développeurs doivent parcourir attentivement ces défis pour créer des systèmes RAG efficaces, éthiques et précieux.
L’article suivant de cette série, Building advanced Retrieval-Augmented Generation systems fournit plus de détails sur la création de pipelines de données et d’inférence pour permettre un système RAG prêt pour la production.
Si vous souhaitez commencer à expérimenter immédiatement la création d’une solution d’INTELLIGENCE artificielle générative, nous vous recommandons de vous familiariser avec la conversation à l’aide de votre propre exemple de données pour Python. Il existe également des versions du didacticiel disponibles dans .NET, Java et JavaScript.
Réglage précis d’un modèle
Le réglage précis, dans le contexte d’un LLM, fait référence au processus d’ajustement des paramètres du modèle sur un jeu de données spécifique à un domaine après avoir été formé initialement sur un jeu de données volumineux et diversifié.
Les modules LLM sont formés (préentraînés) sur un jeu de données large, la structure du langage, le contexte et un large éventail de connaissances. Cette étape implique l’apprentissage des modèles de langage généraux. Le réglage précis ajoute davantage d’entraînement au modèle préentraîné en fonction d’un jeu de données plus petit et spécifique. Cette phase de formation secondaire vise à adapter le modèle afin d’effectuer de meilleures tâches ou de comprendre des domaines spécifiques, améliorant sa précision et sa pertinence pour ces applications spécialisées. Pendant le réglage précis, les pondérations du modèle sont ajustées pour mieux prédire ou comprendre les nuances de ce jeu de données plus petit.
Tenez compte des points suivants :
- Spécialisation : Le réglage précis adapte le modèle à des tâches spécifiques, telles que l’analyse de documents juridiques, l’interprétation de texte médical ou les interactions avec les services à la clientèle. Cela rend le modèle plus efficace dans ces domaines.
- Efficacité : il est plus efficace d’affiner un modèle préentraîné pour une tâche spécifique que d’entraîner un modèle à partir de zéro, car le réglage précis nécessite moins de données et de ressources de calcul.
- Adaptabilité : l’optimisation permet l’adaptation aux nouvelles tâches ou domaines qui ne faisaient pas partie des données d’apprentissage d’origine, ce qui rend les outils polyvalents llMs pour diverses applications.
- Amélioration des performances : Pour les tâches qui sont considérablement différentes des données sur laquelle le modèle a été formé à l’origine, le réglage précis peut entraîner de meilleures performances, car il ajuste le modèle pour comprendre le langage, le style ou la terminologie spécifiques utilisés dans le nouveau domaine.
- Personnalisation : Dans certaines applications, le réglage précis peut aider à personnaliser les réponses ou prédictions du modèle pour répondre aux besoins ou préférences spécifiques d’un utilisateur ou d’une organisation. Toutefois, le réglage précis présente également certains inconvénients et limitations. La compréhension de ces éléments peut vous aider à décider quand choisir le réglage précis et les alternatives comme la génération d’extraction augmentée (RAG).
- Exigences en matière de données : le réglage précis nécessite un jeu de données suffisamment volumineux et de haute qualité spécifique à la tâche ou au domaine cible. La collecte et la création de ce jeu de données peuvent être difficiles et gourmandes en ressources.
- Risque de surajustement : il existe un risque de surajustement, en particulier avec un petit jeu de données. Le surajustement rend le modèle performant sur les données d’apprentissage, mais mal sur de nouvelles données invisibles, ce qui réduit sa généralisabilité.
- Coût et ressources : bien que moins gourmand en ressources que l’entraînement à partir de zéro, le réglage précis nécessite toujours des ressources de calcul, en particulier pour les grands modèles et jeux de données, ce qui peut être prohibitif pour certains utilisateurs ou projets.
- Maintenance et mise à jour : les modèles affinés peuvent nécessiter des mises à jour régulières pour rester efficaces à mesure que les informations spécifiques au domaine changent au fil du temps. Cette maintenance continue nécessite des ressources et des données supplémentaires.
- Dérive du modèle : étant donné que le modèle est affiné pour des tâches spécifiques, il peut perdre une partie de sa compréhension générale du langage et de sa polyvalence, ce qui entraîne un phénomène connu sous le nom de dérive de modèle.
La personnalisation d’un modèle avec réglage précis explique comment ajuster un modèle. À un niveau élevé, vous fournissez un jeu de données JSON de questions potentielles et des réponses préférées. La documentation suggère qu’il existe des améliorations notables en fournissant 50 à 100 paires question/réponse, mais le bon nombre varie considérablement sur le cas d’usage.
Réglage précis par rapport à la génération augmentée par récupération
Sur la surface, il peut sembler qu’il y a un peu de chevauchement entre le réglage précis et la génération augmentée de récupération. Le choix entre l’optimisation et la génération augmentée par récupération dépend des exigences spécifiques de votre tâche, notamment les attentes en matière de performances, la disponibilité des ressources et la nécessité d’une spécificité de domaine par rapport à la généralisabilité.
Quand préférer le réglage précis sur la génération d’extraction augmentée :
- Performances spécifiques aux tâches : l’optimisation des tâches est préférable lorsque des performances élevées sur une tâche spécifique sont critiques et qu’il existe suffisamment de données spécifiques au domaine pour entraîner efficacement le modèle sans risque important de surajustement.
- Contrôle des données : si vous avez des données propriétaires ou hautement spécialisées qui diffèrent considérablement des données sur lesquelles le modèle de base a été formé, le réglage précis vous permet d’incorporer ces connaissances uniques dans le modèle.
- Besoin limité de mises à jour en temps réel : si la tâche ne nécessite pas que le modèle soit constamment mis à jour avec les dernières informations, le réglage précis peut être plus efficace, car les modèles RAG ont généralement besoin d’accéder à des bases de données externes à jour ou à Internet pour extraire des données récentes.
Quand préférer la génération augmentée de récupération par rapport au réglage précis :
- Contenu dynamique ou évolutif - RAG est plus adapté aux tâches où les informations les plus actuelles sont essentielles. Étant donné que les modèles RAG peuvent extraire des données à partir de sources externes en temps réel, ils sont mieux adaptés aux applications telles que la génération d’actualités ou répondre aux questions sur les événements récents.
- Généralisation sur spécialisation - Si l’objectif est de maintenir de fortes performances sur un large éventail de sujets plutôt que d’exceller dans un domaine étroit, RAG peut être préférable. Il utilise des base de connaissances externes, ce qui lui permet de générer des réponses entre différents domaines sans risque de surajustement à un jeu de données spécifique.
- Contraintes de ressources : pour les organisations disposant de ressources limitées pour la collecte de données et l’apprentissage des modèles, l’utilisation d’une approche RAG peut offrir une alternative rentable au réglage précis, en particulier si le modèle de base effectue déjà raisonnablement bien les tâches souhaitées.
Considérations finales susceptibles d’influencer vos décisions de conception d’application
Voici une courte liste des éléments à prendre en compte et d’autres points à prendre en compte dans cet article qui affectent vos décisions de conception d’application :
- Choisissez entre l’optimisation et la génération augmentée de récupération en fonction des besoins spécifiques de votre application. Le réglage précis peut offrir de meilleures performances pour les tâches spécialisées, tandis que RAG peut fournir une flexibilité et un contenu à jour pour les applications dynamiques.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour