Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article vous montre comment évaluer les réponses d’une application de chat par rapport à un ensemble de réponses correctes ou idéales (connues sous le nom de vérité terrain). Chaque fois que vous modifiez votre application de chat d’une manière qui affecte les réponses, exécutez une évaluation pour comparer les modifications. Cette application de démonstration offre des outils que vous pouvez utiliser aujourd’hui pour faciliter l’exécution des évaluations.
En suivant les instructions de cet article, vous devez :
- Utilisez les flux d’invite fournis, adaptés au domaine du sujet. Ces flux d’invite sont déjà dans le référentiel.
- Générez des questions d’utilisateur exemple et des réponses de vérité terrain à partir de vos propres documents.
- Exécutez des évaluations en utilisant une invite d'exemple avec les questions utilisateur générées.
- Passez en revue l’analyse des réponses.
Note
Cet article utilise un ou plusieurs modèles d’application IA comme base pour les exemples et les conseils qu’il contient. Les modèles d’application IA vous fournissent des implémentations de référence bien gérées qui sont faciles à déployer. Ils aident à garantir un point de départ de haute qualité pour vos applications IA.
Vue d’ensemble architecturale
Les principaux composants de l’architecture sont les suivants :
- Application de conversation hébergée sur Azure : L’application de conversation s’exécute dans Azure App Service.
- Protocole Microsoft AI Chat : le protocole fournit des contrats d’API standardisés entre les solutions et les langages IA. L’application de chat est conforme au Microsoft AI Chat Protocol, ce qui permet à l’application d’évaluation de fonctionner avec toute application de chat conforme au protocole.
- Recherche Azure AI : L’application de conversation utilise Recherche Azure AI pour stocker les données de vos propres documents.
- Générateur de questions d’exemple : L'outil peut générer de nombreuses questions pour chaque document avec la réponse basée sur la réalité terrain. Plus il y a de questions, plus les évaluations sont longues.
- Évaluateur : L'outil exécute des exemples de questions et envoie des invites à l'application de conversation, puis renvoie les résultats.
- Outil de révision : l’outil examine les résultats des évaluations.
- Outil Diff : l’outil compare les réponses entre les évaluations.
Lorsque vous déployez cette évaluation sur Azure, le point de terminaison du service Azure OpenAI est créé pour le GPT-4 modèle avec sa propre capacité. Lorsque vous évaluez des applications de conversation, il est important que l’évaluateur dispose de sa propre ressource Azure OpenAI utilisant GPT-4 avec sa propre capacité.
Prerequisites
Abonnement Azure. En créer un gratuitement
Déployez une application de conversation.
Ces applications de chat chargent les données dans la ressource Recherche Azure AI. Cette ressource est requise pour que l’application d’évaluation fonctionne. Ne complétez pas la section Nettoyer les ressources de la procédure précédente.
Vous avez besoin des informations suivantes concernant les ressources Azure de ce déploiement, désignées sous le nom de application de chat dans cet article :
- URI de l’API de chat : Le point de terminaison de backend de service affiché à la fin du processus
azd up. - Recherche Azure AI. Les valeurs suivantes sont requises :
- Nom de la ressource : Le nom de la ressource Recherche Azure AI, rapporté comme
Search servicependant le processusazd up. - Nom de l’index : Le nom de l’index Recherche Azure AI où vos documents sont stockés. Vous trouverez le nom de l’index dans le portail Azure pour le service De recherche.
- Nom de la ressource : Le nom de la ressource Recherche Azure AI, rapporté comme
L’URL de l’API de chat permet aux évaluations d’effectuer des requêtes via votre application backend. Les informations d’Recherche Azure AI permettent aux scripts d’évaluation d’utiliser le même modèle de déploiement que votre backend, chargé avec les documents.
Après avoir collecté ces informations, vous n’avez pas besoin d’utiliser à nouveau l’environnement de développement d’applications de conversation . Cet article fait référence à l’application de conversation plusieurs fois pour montrer comment l’application Évaluations l’utilise. Ne supprimez pas les ressources de l’application de conversation tant que vous n’avez pas terminé toutes les étapes décrites dans cet article.
- URI de l’API de chat : Le point de terminaison de backend de service affiché à la fin du processus
Un environnement de conteneur de développement est disponible avec toutes les dépendances requises pour terminer cet article. Vous pouvez exécuter le conteneur de développement dans GitHub Codespaces (dans un navigateur) ou localement à l’aide de Visual Studio Code.
- Compte GitHub
Ouvrir un environnement de développement
Suivez ces instructions pour configurer un environnement de développement préconfiguré avec toutes les dépendances requises pour terminer cet article. Organisez votre espace de travail monitor pour que vous puissiez voir cette documentation et l’environnement de développement en même temps.
Cet article a été testé avec la région switzerlandnorth pour le déploiement d’évaluation.
GitHub Codespaces exécute un conteneur de développement géré par GitHub avec Visual Studio Code pour le Web comme interface utilisateur. Utilisez GitHub Codespaces pour l’environnement de développement le plus simple. Il est fourni avec les outils de développement et les dépendances appropriés préinstallés pour terminer cet article.
Importante
Tous les comptes GitHub peuvent utiliser GitHub Codespaces pour jusqu’à 60 heures gratuites chaque mois avec deux instances principales. Pour plus d’informations, consultez Le stockage mensuel inclus et les heures de cœur GitHub Codespaces.
Démarrez le processus pour créer un espace de code GitHub sur la
mainbranche du dépôt GitHub Azure-Samples/ai-rag-chat-évaluateur.Pour afficher l’environnement de développement et la documentation disponible en même temps, cliquez avec le bouton droit sur le bouton suivant, puis sélectionnez Ouvrir le lien dans la nouvelle fenêtre.

Dans la page Créer un codespace , passez en revue les paramètres de configuration du codespace, puis sélectionnez Créer un codespace
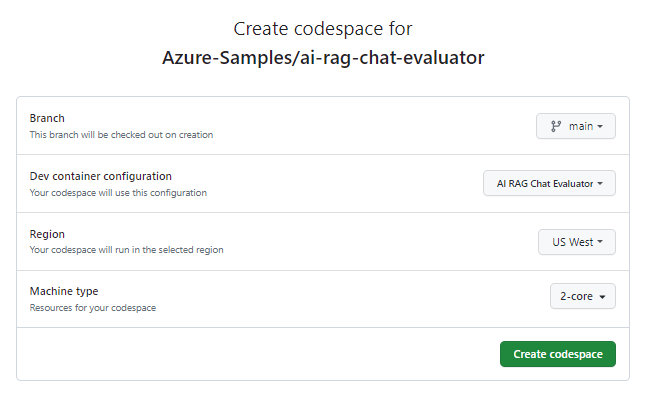
Attendez que le codespace démarre. Ce processus de démarrage peut prendre quelques minutes.
Dans le terminal en bas de l’écran, connectez-vous à Azure avec Azure Developer CLI :
azd auth login --use-device-codeCopiez le code à partir du terminal, puis collez-le dans un navigateur. Suivez les instructions pour vous authentifier avec votre compte Azure.
Provisionnez la ressource Azure requise, Azure OpenAI Service, pour l’application d’évaluation :
azd upCette
AZDcommande ne déploie pas l’application d’évaluation, mais crée la ressource Azure OpenAI avec un déploiement requisGPT-4pour exécuter les évaluations dans l’environnement de développement local.
Les tâches restantes de cet article s’effectuent dans ce conteneur de développement.
Le nom du dépôt GitHub apparaît dans la barre de recherche. Cet indicateur visuel vous aide à distinguer l’application d’évaluation de l’application de conversation. Ce ai-rag-chat-evaluator dépôt est appelé application d’évaluation dans cet article.

Préparez les valeurs d’environnement et les informations de configuration
Mettez à jour les valeurs de l’environnement et les informations de configuration avec les informations que vous avez collectées pendant les conditions préalables pour l’application d’évaluation.
Créez un
.envfichier basé sur.env.sample.cp .env.sample .envExécutez cette commande pour obtenir les valeurs requises pour
AZURE_OPENAI_EVAL_DEPLOYMENTetAZURE_OPENAI_SERVICEà partir de votre groupe de ressources déployé. Collez ces valeurs dans le.envfichier.azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEAjoutez les valeurs suivantes de l’application de conversation pour son instance Recherche Azure AI au
.envfichier que vous avez collecté dans la section Conditions préalables .AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Utilisez le Microsoft AI Chat Protocol pour obtenir des informations de configuration.
L’application de conversation et l’application d’évaluation implémentent toutes deux la spécification microsoft AI Chat Protocol, un contrat d’API de point de terminaison IA open source, cloud et indépendant du langage utilisé pour la consommation et l’évaluation. Lorsque vos points de terminaison client et intermédiaire respectent cette spécification d’API, vous pouvez utiliser et exécuter des évaluations cohérentes sur vos back-ends IA.
Créez un nouveau fichier nommé
my_config.jsonet copiez-y le contenu suivant :{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }script d’évaluation crée le dossier
my_results.L’objet
overridescontient tous les paramètres de configuration nécessaires pour l’application. Chaque application définit son propre ensemble de propriétés de paramètres.Utilisez le tableau suivant pour comprendre la signification des propriétés des paramètres envoyées à l’application de conversation.
Propriété de paramètre Descriptif semantic_rankerUtilisez classeur sémantique, un modèle qui reclasse les résultats de recherche en fonction de la similarité sémantique avec la requête de l’utilisateur. Nous le désactivons pour ce didacticiel afin de réduire les coûts. retrieval_modeMode de récupération à utiliser. Par défaut, il s’agit de hybrid.temperatureParamètre de température du modèle. Par défaut, il s’agit de 0.3.topLe nombre de résultats de recherche à renvoyer. Par défaut, il s’agit de 3.prompt_templateUn remplacement de l’invite utilisée pour générer la réponse en fonction de la question et des résultats de la recherche. seedValeur de départ pour tous les appels aux modèles GPT. La définition d’une valeur de départ entraîne des résultats plus cohérents entre les évaluations. Remplacez la valeur par la
target_urlvaleur URI de votre application de conversation, que vous avez collectée dans la section Conditions préalables . L’application de conversation doit être conforme au protocole de conversation. L’URI a le format suivant :https://CHAT-APP-URL/chat. Assurez-vous que le protocole et la routechatfont partie de l’URI.
Générer des exemples de données
Pour évaluer de nouvelles réponses, elles doivent être comparées à une réponse de vérité de base , qui est la réponse idéale pour une question particulière. Générez des questions et des réponses à partir de documents stockés dans Recherche IA Azure pour l’application de conversation.
Copiez le
example_inputdossier dans un nouveau dossier nommémy_input.Dans un terminal, exécutez la commande suivante pour générer les données d’exemple :
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Les paires question-et-réponse sont générées et stockées au my_input/qa.jsonlformat JSONL comme entrée à l’évaluateur utilisé à l’étape suivante. Pour une évaluation de production, vous générerez des paires questions-réponses supplémentaires. Plus de 200 éléments sont générés pour ce jeu de données.
Note
Seules quelques questions et réponses sont générées par source afin que vous puissiez effectuer rapidement cette procédure. Il n’est pas destiné à être une évaluation de production, qui doit avoir plus de questions et réponses par source.
Exécutez la première évaluation avec une invite affinée
Modifiez les propriétés du
my_config.jsonfichier de configuration.Propriété Nouvelle valeur results_dirmy_results/experiment_refinedprompt_template<READFILE>my_input/prompt_refined.txtLe flux d’invite raffiné est spécifique au domaine du sujet.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers, ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information, return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by a colon and the actual information. Always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].Dans un terminal, exécutez la commande suivante pour exécuter l’évaluation :
python -m evaltools evaluate --config=my_config.json --numquestions=14Ce script a créé un nouveau dossier d’expérimentation dans
my_results/avec l’évaluation. Le dossier contient les résultats de l’évaluation.Nom de fichier Descriptif config.jsonUne copie du fichier de configuration utilisé pour l’évaluation. evaluate_parameters.jsonLes paramètres utilisés pour l’évaluation. Similaire à config.jsonmais inclut d’autres métadonnées telles que l’horodatage.eval_results.jsonlChaque question et réponse, ainsi que les métriques GPT pour chaque paire question-réponse. summary.jsonLes résultats globaux, comme la moyenne des métriques GPT.
Exécutez la deuxième évaluation avec une invite faible.
Modifiez les propriétés du
my_config.jsonfichier de configuration.Propriété Nouvelle valeur results_dirmy_results/experiment_weakprompt_template<READFILE>my_input/prompt_weak.txtCette invite faible n’a aucun contexte sur le domaine du sujet.
You are a helpful assistant.Dans un terminal, exécutez la commande suivante pour exécuter l’évaluation :
python -m evaltools evaluate --config=my_config.json --numquestions=14
Exécuter la troisième évaluation avec une température spécifique
Utilisez un flux d’invite qui permet plus de créativité.
Modifiez les propriétés du
my_config.jsonfichier de configuration.Existant Propriété Nouvelle valeur Existant results_dirmy_results/experiment_ignoresources_temp09Existant prompt_template<READFILE>my_input/prompt_ignoresources.txtNouveau temperature0.9La valeur par défaut de
temperatureest 0,7. Plus la température est élevée, plus les réponses sont créatives.L'invite
ignoreest courte.Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!L’objet de configuration doit ressembler à l’exemple suivant, sauf que vous avez remplacé
results_dirpar votre chemin d’accès :{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }Dans un terminal, exécutez la commande suivante pour exécuter l’évaluation :
python -m evaltools evaluate --config=my_config.json --numquestions=14
Examiner les résultats de l’évaluation
Vous avez effectué trois évaluations basées sur différents flux d’invite et paramètres de l’application. Les résultats sont stockés dans le dossier my_results. Examinez comment les résultats diffèrent en fonction des paramètres.
Utilisez l’outil de révision pour afficher les résultats des évaluations.
python -m evaltools summary my_resultsLes résultats ressemblent à quelque chose comme :

Chaque valeur est renvoyée sous forme de nombre et de pourcentage.
Utilisez le tableau suivant pour comprendre la signification des valeurs.
Valeur Descriptif Fondement Vérifie la façon dont les réponses du modèle sont basées sur des informations factuelles vérifiables. Une réponse est considérée comme fondée si elle est factuellement exacte et reflète la réalité. Pertinence Évalue dans quelle mesure les réponses du modèle sont en adéquation avec le contexte ou l’invite. Une réponse pertinente répond directement à la requête ou à l’énoncé de l’utilisateur. Cohérence Vérifie la cohérence logique des réponses du modèle. Une réponse cohérente maintient un flux logique et ne se contredit pas. Citation Indique si la réponse a été retournée dans le format demandé dans l’invite. Length Mesure la longueur de la réponse. Les résultats devraient indiquer que les trois évaluations avaient une pertinence élevée alors que la
experiment_ignoresources_temp09pertinence était la plus faible.Sélectionnez le dossier pour voir la configuration de l’évaluation.
Entrez Ctrl + C pour quitter l’application et revenir au terminal.
Comparez les réponses
Comparez les réponses renvoyées des évaluations.
Sélectionnez deux des évaluations à comparer, puis utilisez le même outil de révision pour comparer les réponses.
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Passez en revue les résultats. Vos résultats peuvent varier.

Entrez Ctrl + C pour quitter l’application et revenir au terminal.
Suggestions pour d’autres évaluations
- Modifiez les flux d’invite dans
my_inputpour adapter les réponses telles que le domaine du sujet, la longueur et d’autres facteurs. - Modifiez le fichier
my_config.jsonpour modifier les paramètres tels quetemperature, etsemantic_rankeret relancez les expériences. - Comparez différentes réponses pour comprendre comment le flux d’invite et la question affectent la qualité de la réponse.
- Générez un ensemble distinct de questions et de réponses de vérité terrain pour chaque document de l’index Recherche Azure AI. Puis relancez les évaluations pour voir comment les réponses diffèrent.
- Modifiez les flux d’invite pour indiquer des réponses plus courtes ou plus longues en ajoutant l’exigence à la fin du flux d’invite. Par exemple
Please answer in about 3 sentences..
Nettoyez les ressources et les dépendances
Les étapes suivantes vous guident tout au long du processus de nettoyage des ressources que vous avez utilisées.
Nettoyage des ressources Azure
Les ressources Azure créées dans cet article sont facturées dans votre abonnement Azure. Si vous pensez ne plus avoir besoin de ces ressources, supprimez-les pour éviter des frais supplémentaires.
Pour supprimer les ressources Azure et supprimer le code source, exécutez la commande CLI Azure Developer suivante :
azd down --purge
Nettoyer GitHub Codespaces et Visual Studio Code
La suppression de l'environnement GitHub Codespaces garantit que vous pouvez maximiser le nombre d'heures gratuites par cœur auxquelles vous avez droit pour votre compte.
Importante
Pour plus d’informations sur les droits associés à votre compte GitHub, consultez Stockage et heures par cœur inclus chaque mois avec GitHub Codespaces.
Localisez vos espaces de code en cours d’exécution qui proviennent du dépôt GitHub Azure-Samples/ai-rag-chat-evaluator.
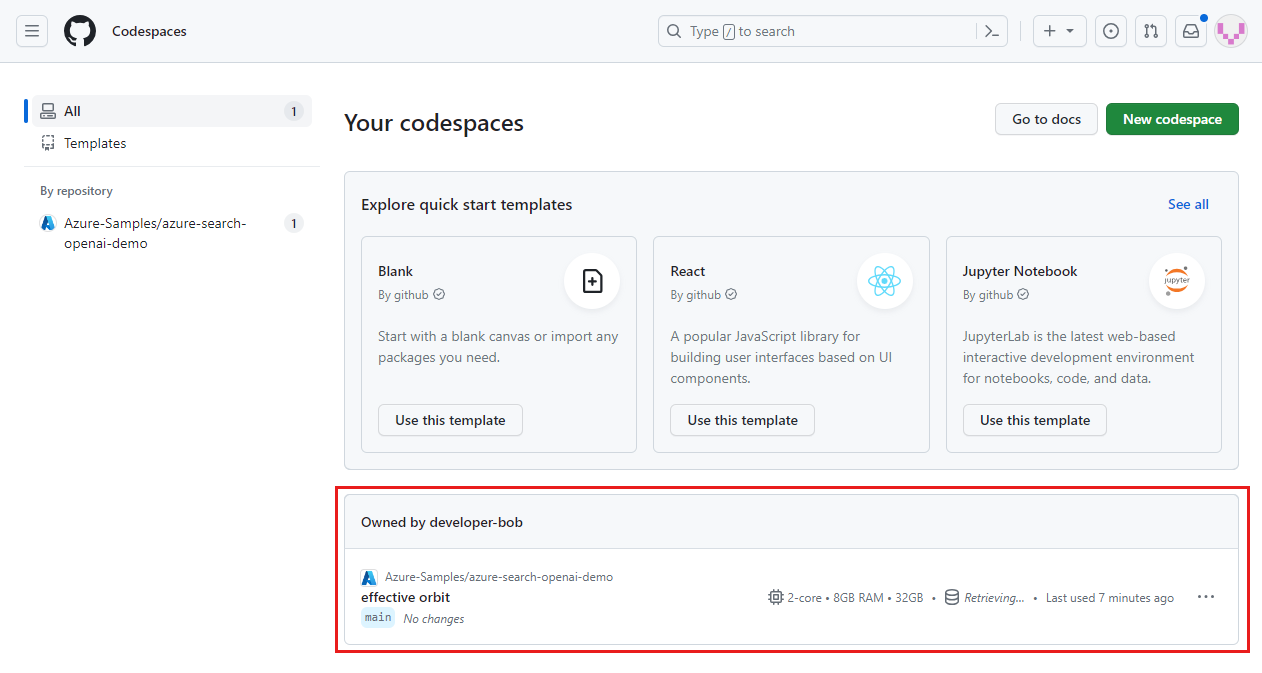
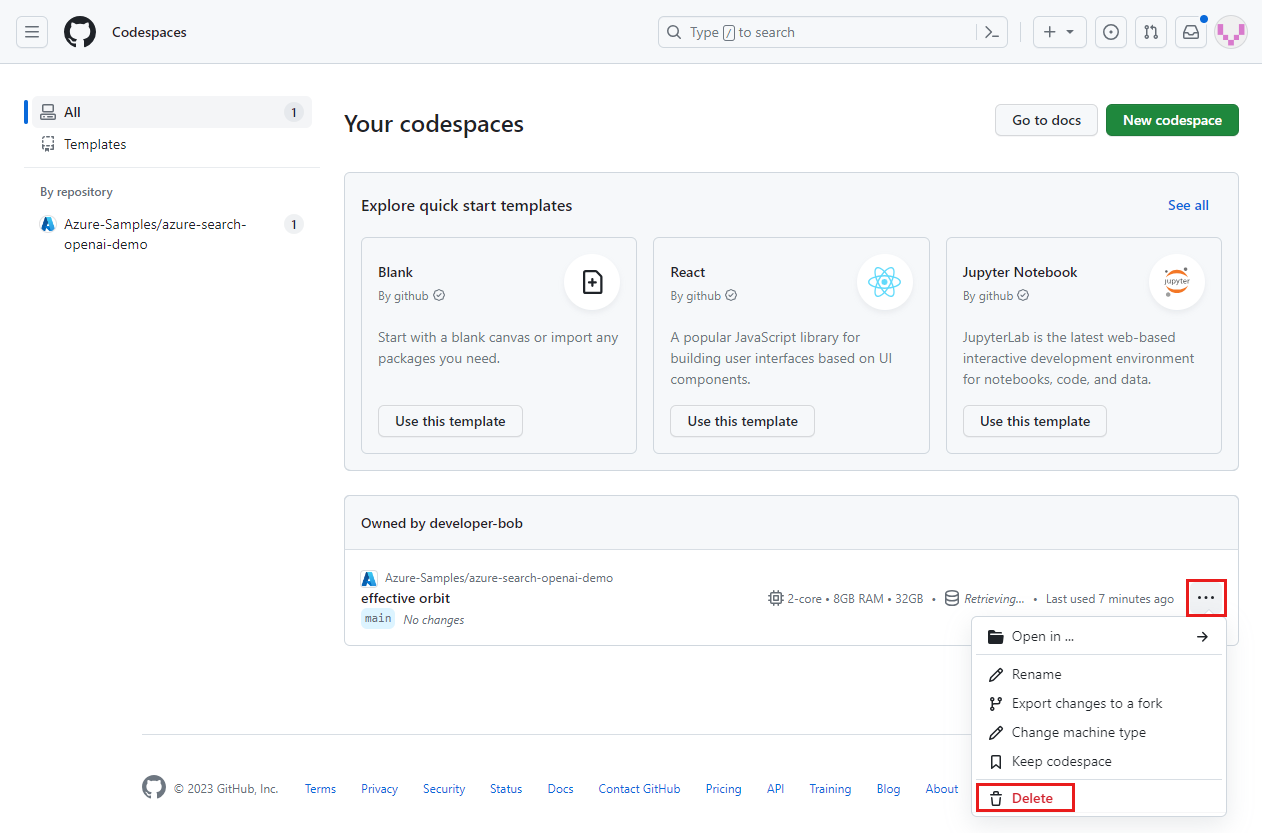
Ouvrez le menu contextuel de l’espace de code, puis sélectionnez Supprimer.
Revenez à l’article de l’application de conversation pour nettoyer ces ressources.
Contenu connexe
- Consultez le référentiel d’évaluations.
- Consultez le dépôt GitHub de l'application de chat d'entreprise .
- Créez une application de conversation en utilisant l'architecture de solution basée sur les meilleures pratiques d'Azure OpenAI.
- Découvrez le contrôle d'accès dans les applications d'IA générative avec Recherche Azure AI.
- Créez une solution Azure OpenAI prête pour l’entreprise avec Gestion des API Azure.
- Veuillez consulter la section Recherche Azure AI : Surpasser la recherche vectorielle avec des capacités de récupération et de classement hybrides.