Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans Recherche Azure AI, le classeur sémantique est une fonctionnalité qui améliore sensiblement la pertinence de la recherche en utilisant les modèles de compréhension du langage de Microsoft pour reclasser les résultats de la recherche. Cet article est une introduction générale pour vous aider à comprendre les comportements et les avantages du classeur sémantique.
Le classeur sémantique est une fonctionnalité Premium facturée à l’utilisation. Nous vous recommandons cet article pour vous familiariser avec le sujet, mais si vous préférez commencer sans plus attendre, procédez comme suit.
Remarque
Le ranker sémantique n’utilise ni l’IA générative ni les vecteurs pour le classement de niveau secondaire 2 (L2). Si vous recherchez des vecteurs et une recherche de similarité, consultez Recherche vectorielle dans Recherche d’IA Azure.
Qu’est-ce que le classement sémantique ?
Le ranker sémantique est une collection de fonctionnalités côté requête qui améliorent la qualité d’un résultat de recherche initial classé bm25 ou classé RRF pour les requêtes textuelles, la partie texte des requêtes vectorielles et les requêtes hybrides. Le classement sémantique étend le pipeline d’exécution de requête de trois façons :
Tout d’abord, il ajoute toujours un classement secondaire à un ensemble de résultats initiaux qui ont été notés à l’aide de BM25 ou de Reciprocal Rank Fusion (RRF). Ce classement secondaire utilise des modèles de deep learning multilingues adaptés à Microsoft Bing pour promouvoir les résultats les plus sémantiquement pertinents.
Ensuite, elle retourne des légendes et extrait éventuellement des réponses dans la réponse, que vous pouvez afficher sur une page de recherche pour améliorer l’expérience de recherche de l’utilisateur.
Troisièmement, si vous activez la réécriture de requête, elle développe une chaîne de requête initiale en plusieurs chaînes de requête sémantiquement similaires.
Le classement secondaire et les « réponses » s’appliquent à la réponse de requête. La réécriture de requête fait partie de la requête.
Voici les fonctionnalités du reclasseur sémantique.
| Fonctionnalité | Descriptif |
|---|---|
| Classeur L2 | Utilise le contexte ou la signification sémantique d’une requête pour calculer un nouveau score de pertinence sur les résultats préclassés. |
| Légendes et mises en surbrillance sémantiques | Extrait des phrases détaillées et des expressions de champs qui résume le mieux le contenu, avec des mises en surbrillance sur les passages clés pour faciliter l’analyse. Les légendes qui résument un résultat sont utiles lorsque les champs de contenu individuels sont trop denses pour la page des résultats de recherche. Le texte mis en surbrillance élève les termes et expressions les plus pertinents afin que les utilisateurs puissent déterminer rapidement la raison pour laquelle une correspondance a été considérée comme pertinente. |
| Réponses sémantiques | Sous-structure facultative et supplémentaire retournée à partir d’une requête sémantique. Elle fournit une réponse directe à une requête qui ressemble à une question. Elle exige qu’un document comporte du texte avec les caractéristiques d’une réponse. |
| Réécriture de requête | À l’aide de requêtes de texte ou de la partie texte d’une requête vectorielle, le ranker sémantique crée jusqu’à 10 variantes de la requête, peut-être en corrigeant des fautes de frappe ou d’orthographe, ou en répliquant une requête à l’aide de synonymes générés. La requête réécrite s’exécute sur le moteur de recherche. Les résultats sont évalués à l’aide de la notation BM25 ou RRF, puis réévalués par un classeur sémantique. |
Fonctionnement du classeur sémantique
Le classeur sémantique alimente les modèles de compréhension de langage hébergés par Microsoft avec une requête et les résultats et recherche ensuite les meilleures correspondances.
L’illustration suivante explique le concept. Regardez le terme « capital ». Il a des significations différentes selon que le contexte est financier, droit, géographie ou grammaire. Grâce à la compréhension du langage, l’éditeur de classement sémantique peut détecter le contexte et promouvoir les résultats qui correspondent à l’intention de requête.
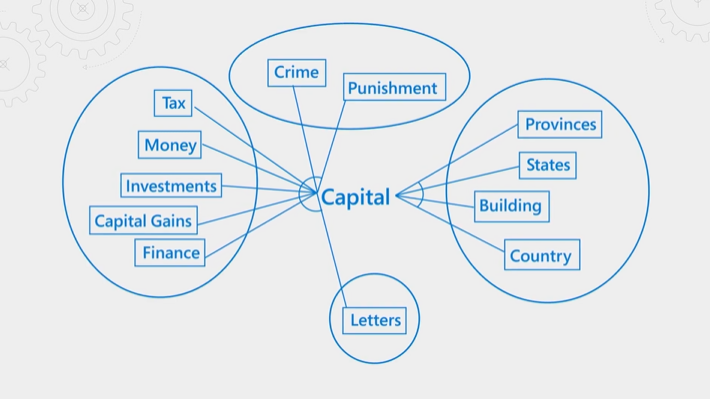
Le classement sémantique est gourmand en ressources et en temps. Pour terminer le traitement dans la latence attendue d’une opération de requête, les entrées du ranker sémantique sont consolidées et réduites afin que l’étape de reclassement puisse être effectuée le plus rapidement possible.
Il existe trois étapes pour le classeur sémantique :
- Collecter et synthétiser les entrées
- Noter les résultats à l’aide du classeur sémantique
- Sortie des résultats notés, des légendes et des réponses
Comment les entrées sont collectées et résumées
Dans le classement sémantique, le sous-système de requête transmet les résultats de recherche en tant qu’entrée aux modèles de synthèse et de classement. Étant donné que les modèles de classement ont des contraintes de taille d’entrée et qu’ils traitent de manière intensive, les résultats de recherche doivent être dimensionnés et structurés (résumés) pour une gestion efficace.
Le classeur sémantique commence par un résultat classé BM25 à partir d’une requête de texte ou d’un résultat classé RRF à partir d’un vecteur ou d’une requête hybride. Seul le texte est utilisé dans l’exercice de reclassement, et seuls les 50 premiers résultats progressent vers le classement sémantique, même si les résultats incluent plus de 50. En règle générale, les champs utilisés dans le classement sémantique sont informatifs et descriptifs.
Pour chaque document du résultat de recherche, le modèle de synthèse accepte jusqu’à 2 000 jetons, où un jeton est d’environ 10 caractères. Les entrées sont assemblées à partir des champs « title » (titre), « keyword » (mot clé) et « content » (contenu) répertoriés dans la configuration sémantique.
Les chaînes excessivement longues sont coupées pour garantir que la longueur globale répond aux exigences d’entrée de l’étape de synthèse. Cet exercice de découpage est pourquoi il est important d’ajouter des champs à votre configuration sémantique dans l’ordre de priorité. Si vous avez des documents très volumineux avec des champs contenant beaucoup de texte, tout ce qui se trouve après la limite maximale est ignoré.
Champ sémantique Limite de jetons « title » 128 Jetons « Mots clés 128 Jetons « content » (contenu) jetons restants La sortie de synthèse est une chaîne récapitulative pour chaque document, composée des informations les plus pertinentes de chaque champ. Les chaînes récapitulatives sont envoyées au ranker pour le scoring et à la lecture automatique des modèles de compréhension pour les légendes et les réponses.
À compter du mois de novembre 2024, la longueur maximale de chaque chaîne récapitulative générée passée au transmise au classeur sémantique est de 2048 jetons. Elle était précédemment de 256 jetons.
Comment le classement est marqué
Le scoring est effectué sur la légende et tout autre contenu de la chaîne récapitulative qui remplit la longueur des 2048 jetons.
Les légendes sont évaluées sur le plan de leur pertinence conceptuelle et sémantique, par rapport à la requête fournie.
Un @search.rerankerScore est affecté à chaque document en fonction de la pertinence sémantique du document pour la requête donnée. Les scores varient de 4 à 0 (élevé à faible), où un score plus élevé indique une pertinence plus élevée.
Résultat Signification 4,0 Le document est très pertinent et répond complètement à la question, bien que le passage puisse contenir du texte supplémentaire non lié à la question. 3.0 Le document est pertinent, mais ne contient pas de détails qui le rendent complet. 2.0 Le document est quelque peu pertinent; il répond à la question partiellement ou seulement à certains aspects de la question. 1,0 Le document est lié à la question, et il répond à une petite partie de celle-ci. 0,0 Le document n’est pas pertinent. Les correspondances sont répertoriées dans l’ordre décroissant par score et incluses dans la charge utile de réponse de requête. La charge utile comprend des réponses, du texte brut et des légendes en surbrillance, ainsi que tous les champs que vous avez marqués comme pouvant être extraits ou spécifiés dans une clause select.
Remarque
Pour toute requête donnée, les distributions de @search.rerankerScore peuvent présenter de légères variations en raison de conditions au niveau de l’infrastructure. Il est également avéré que les mises à jour du modèle de classement pouvaient affecter la distribution. Pour ces raisons, si vous écrivez du code personnalisé pour des seuils minimaux, ou si vous définissez la propriété de seuil pour les requêtes vectorielles et hybrides, ne définissez pas des limites trop précises.
Sorties du classeur sémantique
À partir de chaque chaîne récapitulative, les modèles de compréhension de lecture automatique trouvent des passages qui sont les plus représentatifs.
Les sorties sont les suivantes :
Un légende sémantique pour le document. Chaque légende est disponible dans une version en texte brut et une version en surbrillance et compte souvent moins de 200 mots par document.
Une réponse sémantique facultative, en supposant que vous avez spécifié le paramètre
answers, que la requête a été posée comme une question et qu’un passage se trouve dans la longue chaîne qui fournit une réponse probable à la question.
Les légendes et les réponses sont toujours textuelles à partir de votre index. Il n’existe aucun modèle d’IA générative dans ce flux de travail qui crée ou compose du nouveau contenu.
Fonctionnalités et limitations sémantiques
Que peut faire l’éditeur de classement sémantique :
Promouvoir les correspondances qui sont sémantiquement plus proches de l’intention de la requête d’origine.
Recherchez des chaînes à utiliser comme légendes et réponses. Les légendes et les réponses sont retournées dans la réponse et peuvent être affichées dans une page de résultats de recherche.
Ce que le classeur sémantique ne peut pas effectuer est réexécuter la requête sur l’ensemble du corpus pour trouver des résultats sémantiquement pertinents. Le classement sémantique reclasse le jeu de résultats existant, composé des 50 premiers résultats, comme indiqué par l’algorithme de classement par défaut. En outre, le classeur sémantique ne peut pas créer d’informations ni de chaînes. Les légendes et les réponses sont extraites détaillées de votre contenu. Par conséquent, si les résultats n’incluent pas de texte de type réponse, les modèles de langue ne en produisent pas.
Bien que le classement sémantique ne soit pas avantageux dans chaque scénario, certains contenus peuvent tirer parti de ses fonctionnalités de manière significative. Les modèles de langage dans le classeur sémantique fonctionnent mieux sur le contenu pouvant faire l’objet d’une recherche riche et structurée en prose. Une base de connaissances, une documentation en ligne ou des documents contenant du contenu descriptif voient les gains les plus importants des fonctionnalités de classeur sémantique.
La technologie sous-jacente provient de Bing et de Microsoft Research, et est intégrée à l’infrastructure Recherche Azure AI en tant que fonctionnalité de module complémentaire. Pour plus d’informations sur les investissements de recherche et d’IA qui appuient le classeur sémantique, consultez Comment l’IA de Bing alimente la Recherche Azure AI (Issues du blog Microsoft Research).
La vidéo suivante fournit une vue des fonctionnalités.
Comment le classement sémantique utilise les cartes de synonymes
Si vous avez déjà activé la prise en charge des mappages de synonymes associés à un champ dans votre index de recherche et que ce champ est inclus dans la configuration du ranker sémantique, le ranker sémantique applique automatiquement les synonymes configurés pendant le processus de reclassement.
Disponibilité et tarification
Le classeur sémantique est disponible dans les services de recherche aux niveaux De base et supérieurs, sous réserve d’une disponibilité régionale.
Lorsque vous configurez le ranker sémantique, choisissez un plan tarifaire pour la fonctionnalité :
- Au niveau des volumes de requêtes inférieurs (moins de 1000 par mois), le classement sémantique est gratuit.
- À des volumes de requêtes plus élevés, choisissez le plan tarifaire standard.
La page de tarification Recherche Azure AI affiche le taux de facturation pour différentes devises et intervalles.
Les frais de classeur sémantique sont facturés lorsque les demandes de requête incluent queryType=semantic et que la chaîne de recherche n’est pas vide (par exemple, search=pet friendly hotels in New York). Si votre chaîne de recherche est vide (search=*), vous n’êtes pas facturé, même si le queryType est défini sur sémantique.
Comment démarrer avec classeur sémantique
Se connecter au portail Azure pour vérifier si votre service de recherche est un service de base ou supérieur.
Configurez le ranker sémantique pour le service de recherche, en choisissant un plan tarifaire.
Configurer l’éditeur de classeur sémantique dans un index de recherche.
Configurer des requêtes pour retourner des légendes et des mises en surbrillance sémantiques.