Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
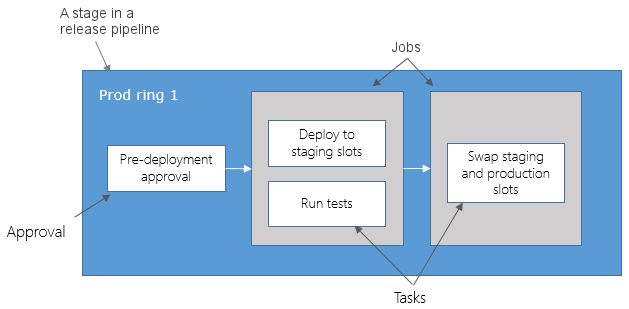
Une étape est une limite logique dans un pipeline Azure DevOps. Phases des actions de groupe dans votre processus de développement logiciel, telles que la création de l’application, l’exécution de tests et le déploiement sur la préproduction. Chaque étape contient un ou plusieurs travaux.
Lorsque vous définissez plusieurs étapes dans un pipeline, par défaut, elles s’exécutent l’une après l’autre. Les étapes peuvent également être interdépendantes. Vous pouvez utiliser le mot-clé dependsOn pour définir des dépendances. Les étapes peuvent également être exécutées de manière conditionnelle en fonction du résultat d'une étape précédente.
Pour comprendre comment les étapes fonctionnent avec des travaux parallèles et des licences, consultez Configurer et payer des travaux parallèles.
Pour comprendre le lien entre les étapes et d'autres parties d'un pipeline, telles que les tâches, consultez Concepts clés des pipelines.
Vous pouvez également en savoir plus sur la relation entre les étapes et les parties d’un pipeline dans l’article sur les étapes du schéma YAML.
Vous pouvez organiser les travaux de pipeline en phases. Les phases sont les principales divisions d’un pipeline : « générer cette application », « exécuter ces tests » et « déployer en préproduction » sont de bons exemples de phases. Il s’agit de limites logiques dans votre pipeline qui vous permettent de suspendre le pipeline et d’effectuer diverses vérifications.
Chaque pipeline a au moins une étape, même si vous ne le définissez pas explicitement. Vous pouvez également organiser des étapes dans un graphique de dépendance afin qu'une étape se déroule avant une autre. Une étape peut avoir jusqu’à 256 tâches.
Spécifier les étapes
Dans le cas le plus simple, vous n’avez pas besoin de limites logiques dans votre pipeline. Pour ces scénarios, vous pouvez spécifier directement les travaux dans votre fichier YAML sans le stages mot clé. Par exemple, si vous disposez d’un pipeline simple qui génère et teste une petite application sans nécessiter d’environnements ou de étapes de déploiement distincts, vous pouvez définir tous les travaux directement sans utiliser de phases.
pool:
vmImage: 'ubuntu-latest'
jobs:
- job: BuildAndTest
steps:
- script: echo "Building the application"
- script: echo "Running tests"
Ce pipeline a une étape implicite et deux tâches. Le stages mot clé n’est pas utilisé, car il n’y a qu’une seule étape.
jobs:
- job: Build
steps:
- bash: echo "Building"
- job: Test
steps:
- bash: echo "Testing"
Pour organiser votre pipeline en plusieurs étapes, utilisez le stages mot clé. Ce yaML définit un pipeline avec deux étapes où chaque étape contient plusieurs travaux, et chaque travail a des étapes spécifiques à exécuter.
stages:
- stage: A
displayName: "Stage A - Build and Test"
jobs:
- job: A1
displayName: "Job A1 - build"
steps:
- script: echo "Building the application in Job A1"
displayName: "Build step"
- job: A2
displayName: "Job A2 - Test"
steps:
- script: echo "Running tests in Job A2"
displayName: "Test step"
- stage: B
displayName: "Stage B - Deploy"
jobs:
- job: B1
displayName: "Job B1 - Deploy to Staging"
steps:
- script: echo "Deploying to staging in Job B1"
displayName: "Staging deployment step"
- job: B2
displayName: "Job B2 - Deploy to Production"
steps:
- script: echo "Deploying to production in Job B2"
displayName: "Production deployment step"
Si vous spécifiez un pool au niveau de l’étape, tous les travaux de l’étape utilisent ce pool, sauf si un pool est spécifié au niveau du travail.
stages:
- stage: A
pool: StageAPool
jobs:
- job: A1 # will run on "StageAPool" pool based on the pool defined on the stage
- job: A2 # will run on "JobPool" pool
pool: JobPool
Spécifier des dépendances
Lorsque vous définissez plusieurs étapes dans un pipeline, elles s’exécutent séquentiellement par défaut dans l’ordre dans lequel vous les définissez dans le fichier YAML. sauf lorsque vous ajoutez des dépendances. En cas de dépendances, les index s’exécutent dans l’ordre des exigences dependsOn.
Les pipelines doivent contenir au moins une étape sans dépendances.
Pour plus d’informations sur la définition des phases, consultez les étapes du schéma YAML.
Les étapes d’exemple suivantes s’exécutent de manière séquentielle. Si vous n’utilisez pas de dependsOn mot clé, les étapes s’exécutent dans l’ordre dans lequel elles sont définies.
stages:
- stage: Build
displayName: "Build Stage"
jobs:
- job: BuildJob
steps:
- script: echo "Building the application"
displayName: "Build Step"
- stage: Test
displayName: "Test Stage"
jobs:
- job: TestJob
steps:
- script: echo "Running tests"
displayName: "Test Step"
Exemples d'étapes qui s'exécutent en parallèle :
stages:
- stage: FunctionalTest
displayName: "Functional Test Stage"
jobs:
- job: FunctionalTestJob
steps:
- script: echo "Running functional tests"
displayName: "Run Functional Tests"
- stage: AcceptanceTest
displayName: "Acceptance Test Stage"
dependsOn: [] # Runs in parallel with FunctionalTest
jobs:
- job: AcceptanceTestJob
steps:
- script: echo "Running acceptance tests"
displayName: "Run Acceptance Tests"
Exemple de comportement de distribution et de regroupement :
stages:
- stage: Test
- stage: DeployUS1
dependsOn: Test # stage runs after Test
- stage: DeployUS2
dependsOn: Test # stage runs in parallel with DeployUS1, after Test
- stage: DeployEurope
dependsOn: # stage runs after DeployUS1 and DeployUS2
- DeployUS1
- DeployUS2
Définir les conditions
Vous pouvez spécifier les conditions sous lesquelles chaque étape s’exécute avec des expressions. Par défaut, une étape s’exécute si elle ne dépend d’aucune autre étape, ou si toutes les étapes dont elle dépend sont terminées et réussies. Vous pouvez personnaliser ce comportement en forçant l’exécution d’une étape même si une étape précédente échoue ou en spécifiant une condition personnalisée.
Si vous personnalisez la condition par défaut des étapes précédentes pour un index, vous supprimez les conditions d’achèvement et de réussite. Par conséquent, si vous utilisez une condition personnalisée, il est courant d’utiliser and(succeeded(),custom_condition) pour vérifier si l’étape précédente s’est achevée avec succès. Sinon, l'étape s'exécute indépendamment du résultat de l'étape précédente.
Remarque
Les conditions d’échec (« JOBNAME/STAGENAME ») et de réussite (« JOBNAME/STAGENAME ») telles qu’indiquées dans l’exemple suivant fonctionnent uniquement pour les pipelines YAML.
Exemple d’exécution d’un index en fonction de l’état d’exécution d’un index précédent :
stages:
- stage: A
# stage B runs if A fails
- stage: B
condition: failed()
# stage C runs if B succeeds
- stage: C
dependsOn:
- A
- B
condition: succeeded('B')
Exemple d’utilisation d’une condition personnalisée :
stages:
- stage: A
- stage: B
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
Spécifier des stratégies de mise en file d’attente
Les pipelines YAML ne prennent pas en charge les stratégies de mise en file d’attente. Chaque exécution d’un pipeline est indépendante et ignore les autres exécutions. En d’autres termes, vos deux commits successifs peuvent déclencher deux pipelines, et chacun exécutera la même séquence d’étapes sans attendre l’autre. Bien que nous travaillons à intégrer des stratégies de mise en file d’attente aux pipelines YAML, nous vous recommandons d’utiliser des approbations manuelles pour séquencer et contrôler manuellement l’ordre d’exécution, si cela est important.
Spécifier des approbations
Vous pouvez contrôler manuellement le moment où une étape doit s’exécuter à l’aide de vérifications d’approbation. Cette vérification est couramment utilisée pour contrôler les déploiements dans des environnements de production. Les vérifications sont un mécanisme à la disposition du propriétaire de ressources qui lui permet de contrôler si un index dans un pipeline peut consommer une ressource et à quel moment. En tant que propriétaire d’une ressource, telle qu’un environnement, vous pouvez définir des vérifications qui doivent être satisfaites pour qu’un index consommant cette ressource puisse démarrer.
Actuellement, les vérifications d’approbation manuelle sont prises en charge sur les environnements. Pour plus d’informations, consultez Approbations.
Ajouter un déclencheur manuel
Les étapes de pipeline YAML déclenchées manuellement vous permettent d’avoir un pipeline unifié sans l’exécuter toujours jusqu’à la fin.
Par exemple, votre pipeline peut inclure des étapes pour la construction, les tests, le déploiement dans un environnement de préproduction et le déploiement en production. Vous pourriez vouloir que toutes les étapes s’exécutent automatiquement, sauf pour le déploiement en production, que vous préférez déclencher manuellement lorsqu’il est prêt.
Pour utiliser cette fonctionnalité, ajoutez la propriété trigger: manual à une étape.
Dans l’exemple suivant, l’étape de développement s’exécute automatiquement, tandis que l’étape de production nécessite un déclenchement manuel. Les deux étapes exécutent un script d’affichage d’un message « hello world ».
stages:
- stage: Development
displayName: Deploy to development
jobs:
- job: DeployJob
steps:
- script: echo 'hello, world'
displayName: 'Run script'
- stage: Production
displayName: Deploy to production
trigger: manual
jobs:
- job: DeployJob
steps:
- script: echo 'hello, world'
displayName: 'Run script'
Marquer une étape comme obligatoire
Marquez une étape comme isSkippable: false pour empêcher les utilisateurs du pipeline de passer des étapes. Par exemple, vous pouvez avoir un modèle YAML qui injecte une étape qui effectue la détection des programmes malveillants dans tous les pipelines. Si vous définissez isSkippable: false pour cette étape, votre pipeline ne pourra pas ignorer la détection des programmes malveillants.
Dans l’exemple suivant, l’étape de détection des programmes malveillants est marquée comme nonskippable, ce qui signifie qu’elle doit être exécutée dans le cadre de l’exécution du pipeline.
- stage: malware_detection
displayName: Malware detection
isSkippable: false
jobs:
- job: check_job
...
Lorsqu’une étape ne peut pas être ignorée, elle s’affiche avec une case à cocher désactivée dans le panneau de configuration des Étapes à exécuter.
