Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Découvrez comment utiliser le pilote JDBC à partir d’une application Java. Pour envoyer des requêtes Apache Hive à Apache Hadoop dans Azure HDInsight. Les informations contenues dans ce document montrent comment se connecter par programmation à partir du client SQuirreL SQL.
Pour plus d’informations sur l’interface JDBC pour Hive, consultez HiveJDBCInterface.
Prérequis
- Un cluster HDInsight Hadoop. Pour en créer un, consultez Prise en main d’Azure HDInsight. Vérifiez que le service HiveServer2 est en cours d’exécution.
- Le Kit de développeur Java (JDK) version 11 ou supérieure.
- SQuirreL SQL. SQuirreL est une application cliente JDBC.
Chaîne de connexion JDBC
Les connexions JDBC à un cluster HDInsight sur Azure sont établies sur le port 443. Le trafic est sécurisé à l’aide de TLS/SSL. La passerelle publique derrière laquelle se trouvent les clusters redirige le trafic vers le port d’écoute réel d’HiveServer2. La chaîne de connexion suivante montre le format à utiliser pour HDInsight :
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Remplacez CLUSTERNAME par le nom de votre cluster HDInsight :
Nom d’hôte dans la chaîne de connexion
Le nom d’hôte « CLUSTERNAME.azurehdinsight.net » dans la chaîne de connexion est identique à l’URL de votre cluster. Vous pouvez l’obtenir via le portail Azure.
Port dans la chaîne de connexion
Vous pouvez utiliser uniquement le port 443 pour vous connecter au cluster à partir de certains emplacements en dehors du réseau virtuel Azure. HDInsight est un service géré, ce qui signifie que toutes les connexions au cluster sont gérées via une passerelle sécurisée. Vous ne pouvez pas vous connecter à HiveServer 2 directement sur les ports 10001 ou 10000. Ces ports ne sont pas exposés à l’extérieur.
Authentification
Lors de l’établissement de la connexion, utilisez le nom et mot de passe d’administrateur du cluster HDInsight pour vous authentifier. À partir de clients JDBC, tels que SQuirreL SQL, entrez le nom et mot de passe d’administrateur dans les paramètres du client.
À partir d’une application Java, vous devez utiliser les nom et mot de passe lors de l’établissement d’une connexion. Par exemple, le code Java suivant ouvre une nouvelle connexion :
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Connexion avec un client SQuirreL SQL
SQuirreL SQL est un client JDBC permettant d’exécuter à distance des requêtes Hive avec votre cluster HDInsight. Les étapes suivantes supposent que vous avez déjà installé SQuirreL SQL.
Créez un répertoire contenant certains fichiers à copier à partir de votre cluster.
Dans le script suivant, remplacez
sshuserpar le nom de compte d’utilisateur SSH pour le cluster. RemplacezCLUSTERNAMEpar le nom du cluster HDInsight. À partir d’une ligne de commande, passez de votre répertoire de travail à celui créé à l’étape précédente, puis entrez la commande suivante pour copier des fichiers depuis un cluster HDInsight :scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Démarrez l’application SQuirreL SQL. Dans la partie gauche de la fenêtre, sélectionnez Pilotes.

Parmi les icônes en haut de la boîte de dialogue Pilotes, sélectionnez l’icône + pour créer un pilote.
Dans la boîte de dialogue Pilote ajouté, ajoutez les informations suivantes :
Propriété Valeur Nom Hive Exemple d’URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Chemin de la classe supplémentaire Utilisez le bouton Ajouter pour ajouter tous les fichiers jar téléchargés précédemment. Nom de la classe org.apache.hive.jdbc.HiveDriver 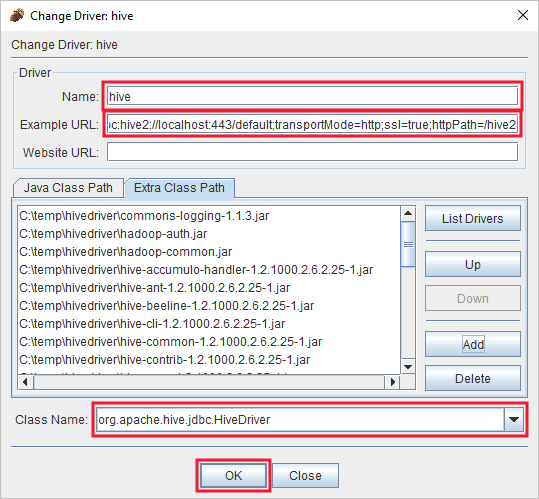
Sélectionnez OK pour enregistrer ces paramètres.
Dans la partie gauche de la fenêtre SQL SQuirreL, sélectionnez Alias. Sélectionnez ensuite l’icône + pour créer un alias de connexion.
Dans la boîte de dialogue Ajouter un Alias, utilisez les valeurs suivantes :
Propriété Valeur Nom Hive sur HDInsight Pilote Sélectionnez le pilote Hive dans la liste déroulante. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Remplacez CLUSTERNAME par le nom de votre cluster HDInsight.User Name Nom de compte de connexion de votre cluster HDInsight. Le nom par défaut est admin. Mot de passe Mot de passe du compte de connexion du cluster. 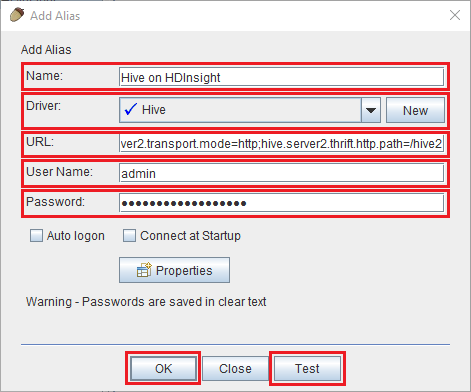
Important
Utilisez le bouton Test pour vérifier que la connexion fonctionne. Quand la boîte de dialogue Se connecter à : Hive sur HDInsight s’affiche, sélectionnez Connexion pour effectuer le test. Si le test réussit, la boîte de dialogue Connexion réussie s’affiche. Si une erreur se produit, consultez Résolution de problèmes.
Pour enregistrer l’alias de connexion, utilisez le bouton OK au bas de la boîte de dialogue Ajouter un alias.
Dans la liste déroulante Se connecter à en haut de SQuirreL SQL, sélectionnez Hive sur HDInsight. Lorsque vous y êtes invité, sélectionnez Connexion.
Une fois connecté, entrez la requête suivante dans la boîte de dialogue Requête SQL, puis sélectionnez l’icône Exécuter (représentant une personne qui court). La zone de résultats doit afficher les résultats de la requête.
select * from hivesampletable limit 10;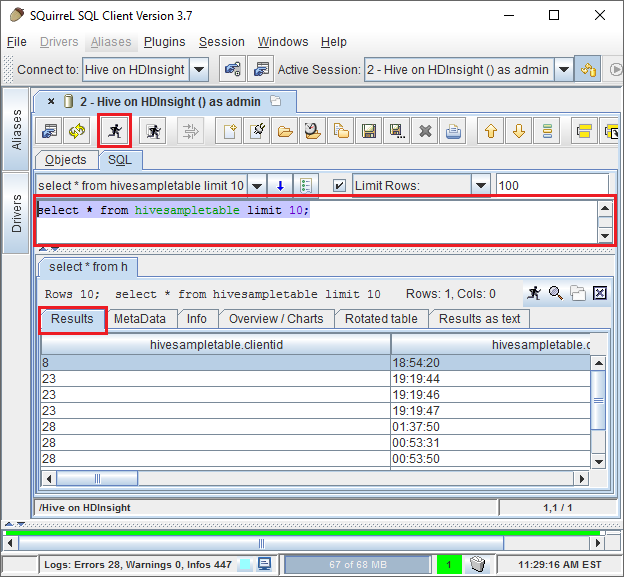
Connexion à partir d’un exemple d’application Java
Un exemple d’utilisation d’un client Java pour interroger Hive sur HDInsight est disponible sur https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Suivez les instructions indiquées dans le référentiel pour générer et exécuter l’exemple.
Dépannage
Une erreur inattendue s'est produite lors de l'ouverture d'une connexion SQL
Symptômes : Quand vous vous connectez à un cluster HDInsight version 3.3 ou supérieure, vous pouvez recevoir un message indiquant qu’une erreur inattendue s’est produite. L’arborescence des appels de procédure pour cette erreur commence par les lignes suivantes :
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Cause : Cette erreur est due à une version plus ancienne du fichier commons-codec.jar incluse avec SQuirreL.
Résolution : Pour corriger cette erreur, utilisez les étapes suivantes :
Quittez SQuirreL et accédez au répertoire où SQuirreL est installé sur votre système, peut-être
C:\Program Files\squirrel-sql-4.0.0\lib. Dans le répertoire SquirreL, sous le dossierlib, remplacez le fichier commons-codec.jar existant par le fichier téléchargé à partir du cluster HDInsight.Redémarrez SQuirreL. L'erreur ne devrait plus apparaître lors de la connexion à Hive sur HDInsight.
Connexion déconnectée par HDInsight
Symptômes : HDInsight interrompt inopinément la connexion quand il essaie de télécharger une très grande quantité de données (disons plusieurs Go) via JDBC/ODBC.
Cause : La limitation sur les nœuds de passerelle provoque cette erreur. Quand vous obtenez des données à partir de JDBC/ODBC, toutes les données doivent traverser le nœud de passerelle. Toutefois, une passerelle n’étant pas conçue pour télécharger une énorme quantité de données, la passerelle peut fermer la connexion si elle ne peut pas gérer le trafic.
Résolution : Évitez d’utiliser un pilote JDBC/ODBC pour télécharger d’énormes quantités de données. Copiez plutôt les données directement à partir du stockage d’objets blob.
Étapes suivantes
À présent que vous avez vu comment utiliser JDBC avec Hive, utilisez les liens suivants pour découvrir d’autres façons d’utiliser Azure HDInsight.
- Visualiser des données Apache Hive à l’aide de Microsoft Power BI dans Azure HDInsight.
- Visualiser des données Interactive Query Hive à l’aide de Power BI dans Azure HDInsight.
- Connecter Excel à HDInsight avec le pilote ODBC Microsoft Hive.
- Connecter Excel à Apache Hadoop à l’aide de Power Query.
- Utilisation d’Apache Hive avec HDInsight
- Utilisation d’Apache Pig avec HDInsight
- Utilisation des tâches MapReduce avec HDInsight