Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans un cluster HBase, vous pouvez décider de supprimer des données qui ont vieilli, soit pour libérer du stockage et réduire les coûts car vous n’avez plus besoin de ces données, soit pour vous conformer aux réglementations. Lorsque cela s’avère nécessaire, vous devez définir la durée de vie (TTL) dans une table située au niveau ColumnFamily pour qu’elle expire et supprime automatiquement les anciennes données. La TTL peut également être définie au niveau cellule, mais le niveau ColumnFamily est généralement plus pratique pour des raisons de facilité d’administration et parce qu’une TTL au niveau cellule (exprimée en ms) ne peut pas prolonger la durée de vie effective d’une cellule au-delà d’un paramètre de TTL de niveau ColumnFamily (exprimée en secondes) ; seules les durées de conservation plus courtes requises au niveau cellule peuvent tirer parti de la définition d’une TTL au niveau cellule.
Malgré la définition de la TTL, vous pouvez ne pas toujours obtenir l’effet escompté concernant l’expiration des données et/ou la diminution de la taille de stockage.
Prérequis
Suivez les étapes et les commandes données, ouvrez deux connexions ssh au cluster HBase :
Dans l’une des sessions ssh, conservez l’interpréteur de commandes bash par défaut.
Dans la deuxième session ssh, lancez l’interpréteur de commandes HBase en exécutant la commande suivante.
hbase shell
Vérifier si la TTL souhaitée est configurée et si les données qui ont expiré sont supprimées du résultat de la requête
Suivez les étapes données pour comprendre où se situe le problème. Commencez par déterminer si le comportement concerne une table spécifique ou toutes les tables. Si vous ne savez pas si le problème affecte toutes les tables ou une table spécifique, commencez par prendre comme exemple un nom de table particulier.
Vérifiez d’abord que la TTL a été configurée sur ColumnFamily pour les tables cibles. Exécutez la commande suivante dans la session SSH dans laquelle vous avez lancé l’interpréteur de commandes HBase, examinez la sortie. La TTL d’une famille de colonnes est définie sur 50 secondes tandis qu’aucune TTL n’est configurée pour l’autre famille. Celle-ci est donc définie sur « FOREVER » (ce qui signifie que les données de cette famille de colonnes ne sont pas configurées pour expirer).
describe 'table_name'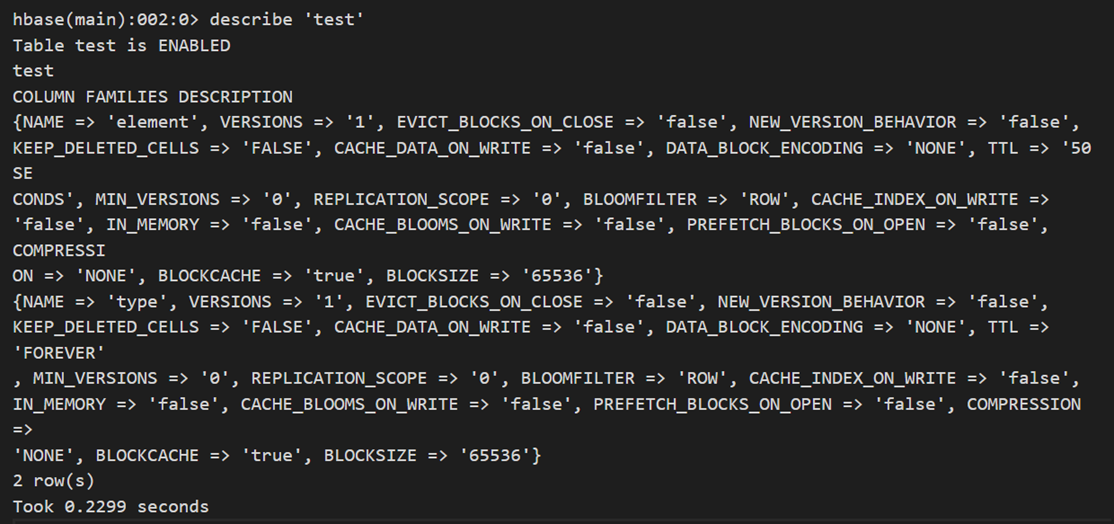
Si elle n’est pas configurée, la TTL par défaut est définie sur « FOREVER ». Deux raisons peuvent expliquer pourquoi les données n’ont pas expiré comme prévu et n’ont pas été supprimées du résultat de la requête.
- Si la TTL n’est pas définie sur « FOREVER », examinez la valeur en secondes de la famille de colonnes et notez-la (prêtez attention à l’unité de mesure mise en corrélation car la TTL au niveau cellule est exprimée en ms alors que la TTL au niveau ColumnFamily est exprimée en secondes) pour vérifier qu’il s’agit bien de la valeur attendue. Si la valeur observée n’est pas correcte, commencez par la corriger.
- Si la TTL est définie sur « FOREVER » pour toutes les familles de colonnes, configurez d’abord la TTL, puis surveillez les données pour voir si elles expirent comme prévu.
Si vous avez établi que la TTL est configurée et que la valeur définie pour ColumnFamily est correcte, l’étape suivante consiste à vérifier que les données qui ont expiré n’apparaissent plus lors de l’analyse des tables. Lorsque des données expirent, elles doivent être supprimées et ne plus apparaître dans les résultats d’analyse des tables. Exécutez la commande ci-dessous dans l’interpréteur de commandes HBase pour vérifier.
scan 'table_name'
Vérifier le nombre et la taille des StoreFiles par table et par région pour déterminer si des changements sont visibles après l’opération de compactage
Avant de passer à l’étape suivante, à partir de la session ssh utilisant l’interpréteur de commandes bash, exécutez la commande suivante pour vérifier le nombre actuel de StoreFiles et la taille de chaque StoreFile actuellement affiché pour la ColumnFamily pour laquelle la TTL a été configurée. Notez d’abord la table et la ColumnFamily pour lesquelles vous effectuez la vérification, puis exécutez la commande suivante dans la session ssh (bash).
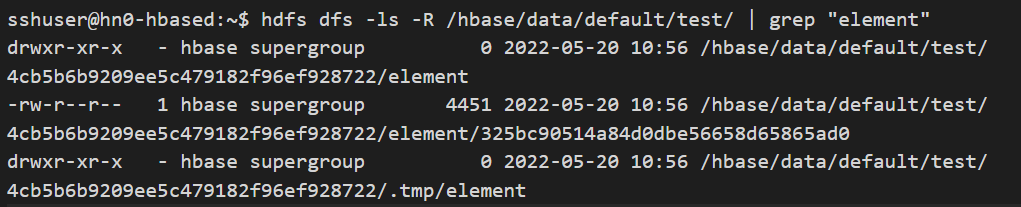
hdfs dfs -ls -R /hbase/data/default/table_name/ | grep "column_family_name"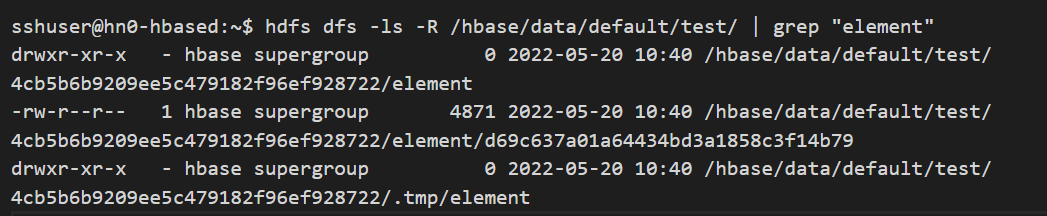
La sortie affiche probablement plus de résultats, un résultat pour chaque ID de région de la table, et entre 0 et plus de résultats pour les StoreFiles présents sous chaque nom de région, pour la ColumnFamily sélectionnée. Pour compter le nombre total de lignes dans la sortie de résultats ci-dessus, exécutez la commande suivante.
hdfs dfs -ls -R /hbase/data/default/table_name/ | grep "column_family_name" | wc -l
Vérifier le nombre et la taille des StoreFiles par table et par région après le vidage
En fonction de la TTL configurée pour chaque ColumnFamily et de la quantité de données écrites dans la table pour la ColumnFamily cible, une partie des données peut encore subsister dans le MemStore et ne pas être écrite en tant que StoreFile dans le stockage. Par conséquent, pour veiller à ce que les données soient écrites dans le stockage en tant que StoreFile, avant que la taille maximale configurée du MemStore soit atteinte, vous pouvez exécuter la commande suivante dans l’interpréteur de commandes HBase afin d’écrire immédiatement les données du MemStore dans le StoreFile.
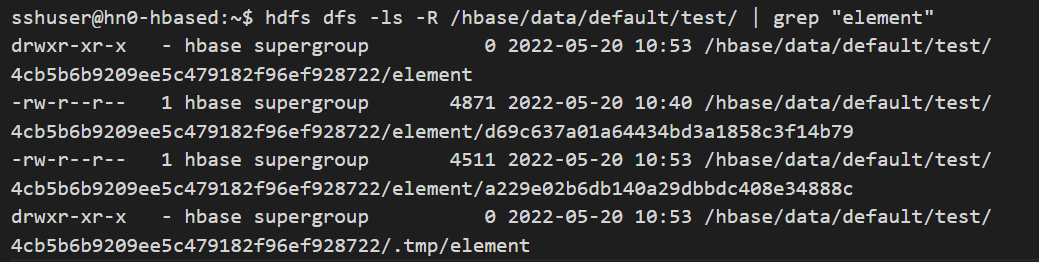
flush 'table_name'Observez le résultat en exécutant à nouveau la commande dans l’interpréteur de commandes bash.
hdfs dfs -ls -R /hbase/data/default/table_name/ | grep "column_family_name"Un fichier de stockage supplémentaire est créé par rapport à la sortie de résultat précédente pour chaque région où les données sont modifiées. Le StoreFile inclut le contenu actuel du MemStore de cette région.
Vérifier le nombre et la taille des StoreFiles par table et par région après un compactage majeur
À ce stade, les données du MemStore ont été écrites dans un StoreFile, dans le stockage, mais des données ayant expiré peuvent encore subsister dans un ou plusieurs des StoreFiles actuels. Bien que des compactages mineurs puissent permettre de supprimer certaines des entrées expirées, il n’est pas garanti qu’ils les suppriment toutes en tant que compactage mineur. Cela ne sélectionne pas tous les StoreFiles pour le compactage, alors que le compactage majeur sélectionne tous les StoreFiles pour le compactage dans cette région.
Il existe une autre situation dans laquelle un compactage mineur peut ne pas supprimer les cellules dont la TTL a expiré. La propriété MIN_VERSIONS est définie par défaut sur 0 (voir dans la sortie ci-dessus de describe 'table_name' la propriété MIN_VERSIONS=>'0'). Lorsque cette propriété est définie sur 0, le compactage mineur supprime les cellules dont la TTL a expiré. Lorsque cette valeur est supérieure à 0, le compactage mineur peut ne pas supprimer les cellules dont la TTL a expiré même si le fichier correspondant est touché dans le cadre du compactage. Cette propriété configure le nombre minimal de versions d’une cellule à conserver, même si la TTL de ces versions a expiré.
Pour veiller à ce que les données qui ont expiré soient également supprimées du stockage, nous devons exécuter une opération de compactage majeur. Une fois l’opération de compactage majeur terminée, il ne reste qu’un seul StoreFile par région. Dans l’interpréteur de commandes HBase, exécutez la commande suivante pour exécuter une opération de compactage majeur sur la table :
major_compact 'table_name'Selon la taille de la table, l’opération de compactage majeur peut prendre un certain temps. Utilisez la commande suivante dans l’interpréteur de commandes HBase pour en surveiller la progression. Si le compactage est toujours en cours d’exécution lorsque vous exécutez la commande suivante, vous obtenez la sortie « MAJOR », et si le compactage est terminé, cette sortie est remplacée par « NONE ».
compaction_state 'table_name'Lorsque l’état de compactage « NONE » s’affiche dans l’interpréteur de commandes HBase, si vous basculez rapidement vers bash et exécutez la commande.
hdfs dfs -ls -R /hbase/data/default/table_name/ | grep "column_family_name"Remarquez qu’un StoreFile supplémentaire a été créé, en plus des précédents par région et par ColumnFamily, et au bout de quelques instants, seul le dernier StoreFile créé par région et par famille de colonnes est conservé.
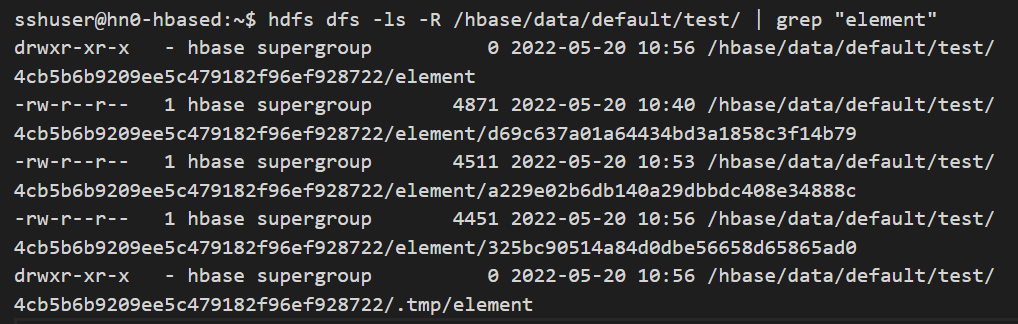
Pour l’exemple de région ci-dessus, une fois le temps supplémentaire écoulé, nous remarquons un seul StoreFile restant. La taille occupée par ce fichier sur le stockage est également réduite en raison du compactage majeur. À ce stade, toutes les données expirées et non supprimées (par un autre compactage majeur) vont bientôt être supprimées après l’exécution de l’actuelle opération principale de compactage.
Remarque
Dans le cadre de cet exercice de résolution des problèmes, vous avez déclenché manuellement un compactage majeur. Mais dans la pratique, procéder manuellement sur de nombreuses tables peut prendre beaucoup de temps. Par défaut, sur un cluster HDInsight, le compactage majeur est désactivé La principale raison de conserver le compactage majeur désactivé par défaut concerne l’impact sur les performances des opérations de table pendant un compactage majeur. Mais vous pouvez activer un compactage majeur en configurant la valeur de la propriété hbase.hregion.majorcompaction en ms, ou utiliser une tâche cron ou un autre système externe pour planifier le compactage au moment opportun, avec une charge de travail moindre.
Étapes suivantes
Si votre problème ne figure pas dans cet article ou si vous ne parvenez pas à le résoudre, utilisez un des canaux suivants pour obtenir de l’aide :
Obtenez des réponses de la part d’experts Azure en faisant appel au Support de la communauté Azure.
Connectez-vous à @AzureSupport, le compte Microsoft Azure officiel pour améliorer l’expérience client. Connexion de la communauté Azure aux ressources appropriées :
answers,supportetexperts.Si vous avez besoin d’une aide supplémentaire, vous pouvez envoyer une requête de support à partir du Portail Microsoft Azure. Sélectionnez Support dans la barre de menus, ou ouvrez le hub Aide + Support. Pour plus d’informations, consultez Création d’une demande de support Azure. L’accès au support relatif à la gestion et à la facturation des abonnements est inclus avec votre abonnement Microsoft Azure. En outre, le support technique est fourni avec l’un des plans de support Azure.