Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Découvrez les principaux problèmes rencontrés lors de l’utilisation de charges utiles Apache Hadoop YARN dans Apache Ambari, et leur résolution.
Comment créer une file d’attente YARN dans un cluster ?
Étapes de résolution
Effectuez les étapes suivantes via Ambari pour créer une file d’attente YARN, puis équilibrer l’allocation de capacité entre toutes les files d’attente.
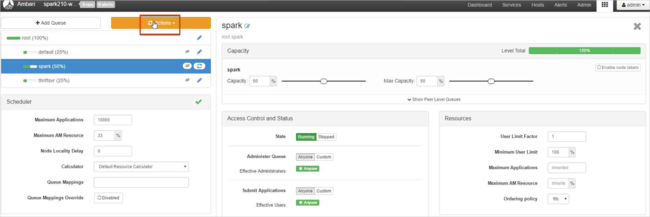
Dans cet exemple, la capacité de deux files d’attente existantes (default et thriftsvr) est modifiée de 50 % à 25 %, ce qui permet à la nouvelle file d’attente (spark) de bénéficier d’une capacité de 50 %.
| File d'attente | Capacité | Capacité maximale |
|---|---|---|
| default | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Cliquez sur l’icône Vues Ambari, puis sur l’icône de grille. Sélectionnez ensuite YARN Queue Manager (Gestionnaire de files d’attente YARN).
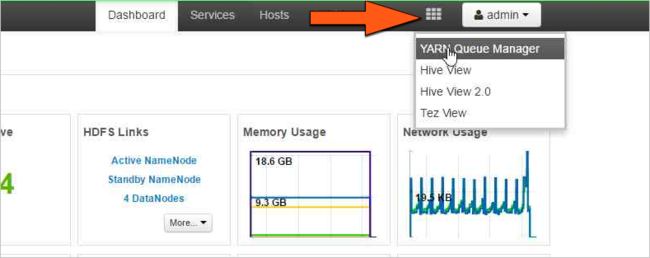
Sélectionnez la file d’attente default (par défaut).
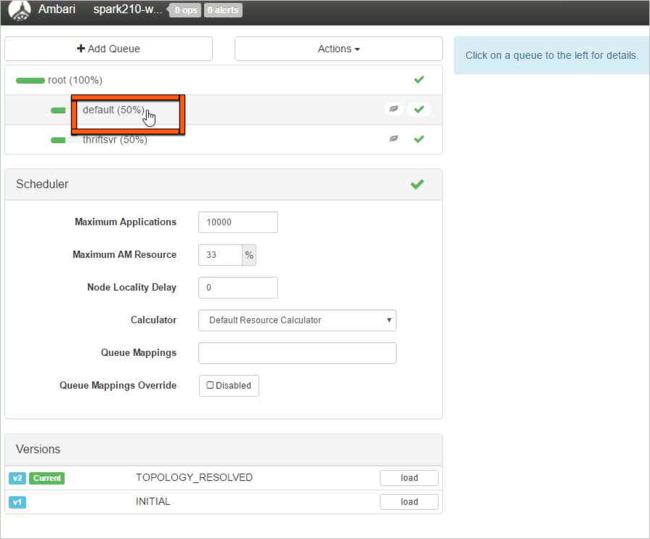
Modifiez la valeur Capacity (Capacité) de 50 % à 25 % pour la file d’attente default (par défaut) et faites de même pour la file d’attente thriftsvr .
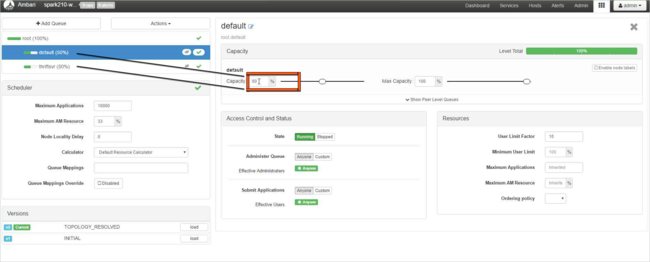
Cliquez sur Add Queue (Ajouter une file d’attente) pour créer une file d’attente.
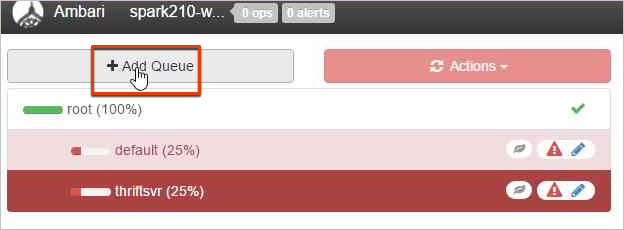
Nommez la nouvelle file d’attente.
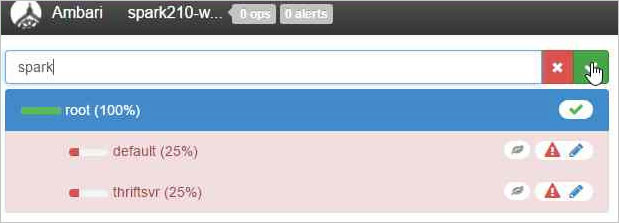
Conservez la valeur de capacité de 50 %, puis cliquez sur le bouton Actions.
Sélectionnez Save and Refresh Queues (Enregistrer et actualiser les files d’attente).
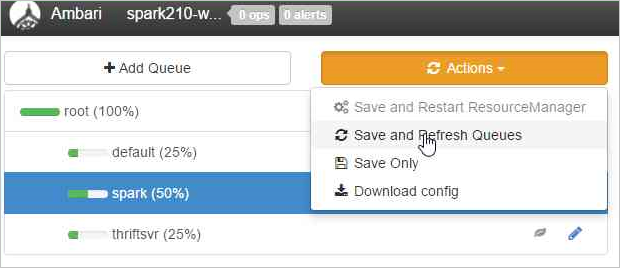
Ces modifications se répercutent immédiatement sur l’interface utilisateur du planificateur YARN.
Pour aller plus loin
Comment télécharger les journaux d’activité YARN à partir d’un cluster ?
Étapes de résolution
Connectez-vous au cluster HDInsight à l’aide d’un client Secure Shell (SSH). Pour plus d’informations, consultez Lecture supplémentaire.
Pour répertorier les ID de toutes les applications YARN en cours d’exécution, exécutez la commande suivante :
yarn topLes ID sont répertoriés dans la colonne APPLICATIONID. Vous pouvez télécharger les journaux d’activité depuis la colonne APPLICATIONID.
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerPour télécharger les journaux d’activité de conteneurs YARN pour tous les processus maîtres d’application, utilisez la commande suivante :
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtCette commande crée un fichier journal nommé amlogs.txt.
Pour télécharger les journaux d’activité de conteneurs YARN uniquement pour les processus maîtres d’application les plus récents, utilisez la commande suivante :
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtCette commande crée un fichier journal nommé latestamlogs.txt.
Pour télécharger les journaux d’activité de conteneurs YARN pour les deux premiers processus maîtres d’application, utilisez la commande suivante :
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtCette commande crée un fichier journal nommé first2amlogs.txt.
Pour télécharger tous les journaux d’activité de conteneurs YARN, utilisez la commande suivante :
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtCette commande crée un fichier journal nommé logs.txt.
Pour télécharger le journal de conteneur YARN pour un conteneur spécifique, utilisez la commande suivante :
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtCette commande crée un fichier journal nommé containerlogs.txt.
Documentation supplémentaire
- Se connecter à HDInsight (Apache Hadoop) avec SSH
- Apache Hadoop YARN concepts and applications (Concepts et applications Apache Hadoop Yarn, en anglais)
Comment puis-je vérifier les informations de diagnostic de l'application Yarn ?
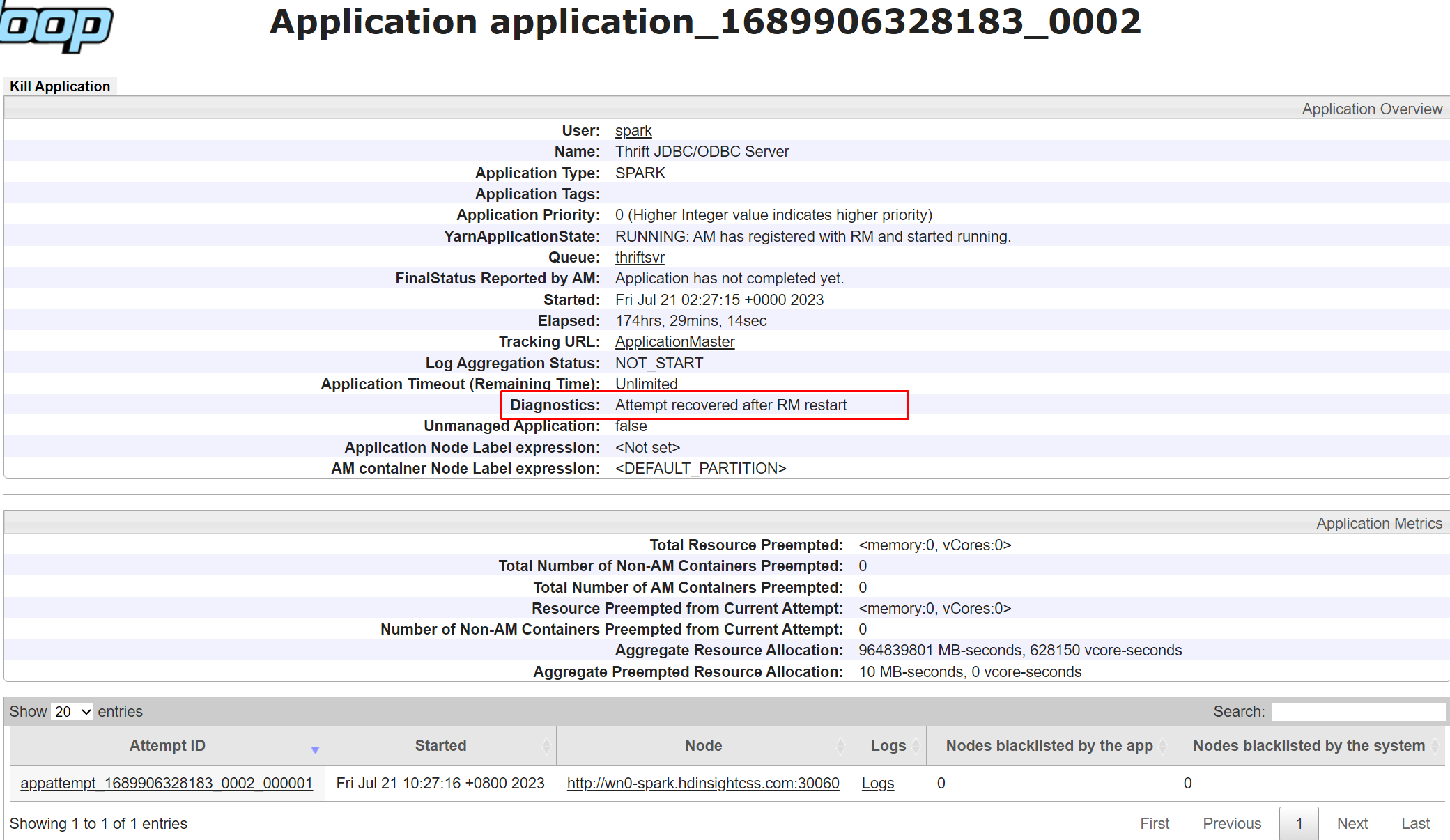
Diagnostics in Yarn UI est une fonctionnalité qui vous permet d'afficher l'état et les journaux de vos applications exécutées sur Yarn. Les diagnostics peuvent vous aider à dépanner et à déboguer vos applications, ainsi qu'à surveiller leurs performances et l'utilisation des ressources.
Pour afficher les diagnostics d'une application spécifique, vous pouvez cliquer sur l'ID de l'application dans la liste des applications. Sur la page des détails de l'application, vous pouvez également voir une liste de toutes les tentatives qui ont été faites pour exécuter l'application. Vous pouvez cliquer sur n'importe quelle tentative pour afficher plus de détails, tels que l'ID de la tentative, l'ID du conteneur, l'ID du nœud, l'heure de début, l'heure de fin et les diagnostics
Comment résoudre les problèmes courants de YARN ?
L’interface utilisateur Yarn ne se charge pas
Si votre interface utilisateur YARN ne se charge pas ou est inaccessible, et retourne « Erreur HTTP 502.3 - Passerelle incorrecte », cela indique fortement que votre service Resource Manager n’est pas sain. Pour résoudre le problème, effectuez les étapes suivantes :
- Accédez à l’interface utilisateur Ambari>YARN>RÉCAPITULATIF, puis vérifiez si seule l’instance Resource Manager active est dans l’état Démarré. Si ce n’est pas le cas, essayez d’atténuer le problème en redémarrant l’instance Resource Manager non saine ou arrêtée.
- Si l’étape 1 ne résout pas le problème, établissez une liaison SSH sur le nœud principal de l’instance Resource Manager active et vérifiez l’état du nettoyage de la mémoire en utilisant
jstat -gcutil <Resource Manager pid> 1000 100. Si vous voyez que la valeur FGCT augmente de manière significative en quelques secondes, cela indique que l’instance Resource Manager est occupée par un GC complet et qu’elle ne peut pas traiter d’autres demandes. - Accédez à l’interface utilisateur Ambari>YARN>CONFIGS>Advanced et augmentez
Resource Manager java heap size. - Redémarrez les services requis dans l’interface utilisateur Ambari.
Passage en veille des deux gestionnaires de ressources
- Consultez le journal Resource Manager pour vérifier s’il y a une erreur similaire.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Le cas échéant, vérifiez si certains fichiers sont en cours de réplication ou s’il y a des blocs manquants dans le système HDFS. Vous pouvez exécuter
hdfs fsck hdfs://mycluster/.Exécutez
hdfs fsck hdfs://mycluster/ -deletepour forcer le nettoyage du système HDFS et pour éliminer le problème en cours de l’instance Resource Manager. Vous pouvez également exécuter PatchYarnNodeLabel sur l’un des nœuds principaux pour corriger le cluster.
Étapes suivantes
Si votre problème ne figure pas dans cet article ou si vous ne parvenez pas à le résoudre, utilisez un des canaux suivants pour obtenir de l’aide :
Obtenez des réponses de la part d’experts Azure en faisant appel au Support de la communauté Azure.
Connectez-vous à @AzureSupport, le compte Microsoft Azure officiel pour améliorer l’expérience client. Connexion de la communauté Azure aux ressources appropriées : réponses, support technique et experts.
Si vous avez besoin d’une aide supplémentaire, vous pouvez envoyer une requête de support à partir du Portail Microsoft Azure. Sélectionnez Support dans la barre de menus, ou ouvrez le hub Aide + Support. Pour plus d’informations, consultez Création d’une demande de support Azure. L’accès au support relatif à la gestion et à la facturation des abonnements est inclus avec votre abonnement Microsoft Azure. En outre, le support technique est fourni avec l’un des plans de support Azure.