Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Apache Hive Warehouse Connector (HWC) est une bibliothèque qui vous permet de travailler plus facilement avec Apache Spark et Apache Hive, Elle prend en charge certaines tâches comme le déplacement de données entre les DataFrames Spark et les tables Hive. De même, elle achemine les données de streaming Spark vers les tables Hive. Le connecteur d’entrepôt Hive fonctionne comme un pont entre Spark et Hive. Cette bibliothèque prend aussi en charge l’utilisation des langages de programmation Scala, Java et Python à des fins de développement.
Le connecteur d’entrepôt Hive vous permet de profiter des fonctionnalités uniques de Hive et de Spark afin de créer de puissantes applications Big Data.
Apache Hive prend en charge les transactions de base de données ACID (Atomiques, Cohérentes, Isolées et Durables). Pour plus d'informations sur ACID et les transactions dans Hive, voir Transactions Hive. Hive offre également des contrôles de sécurité détaillés via Apache Ranger et Low Latency Analytical Processing (LLAP), des options non disponibles dans Apache Spark.
Apache Spark dispose d’une API de flux structuré qui offre des capacités de diffusion en continu non disponibles dans Apache Hive. À partir de HDInsight 4.0, Apache Spark 2.3.1 et versions ultérieures, et Apache Hive 3.1.0 proposent des catalogues de metastores distincts qui nuisent à l’interopérabilité.
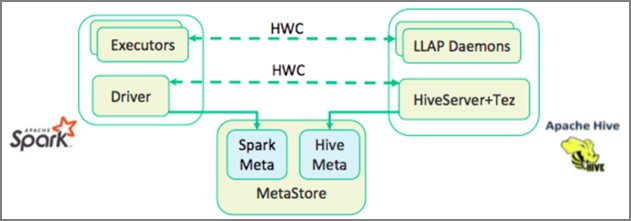
Le connecteur Hive Warehouse Connector (HWC) facilite l’utilisation simultanée de Spark et de Hive. La bibliothèque HWC charge les données de démons LLAP dans des exécuteurs Spark en parallèle. Ce processus la rend plus efficace et plus adaptable qu’une connexion JDBC standard de Spark à Hive. Cela fait paraître deux modes d’exécution différents pour HWC :
- Mode Hive JDBC via HiveServer2
- Mode Hive LLAP utilisant des démons LLAP [Recommandé]
Par défaut, HWC est configuré pour utiliser des démons Hive LLAP. Pour exécuter des requêtes Hive (à la fois en lecture et en écriture) en utilisant les modes ci-dessus avec leurs API respectives, consultez API HWC.
Voici quelques-unes des opérations prises en charge par le connecteur d'entrepôt Hive :
- Description d’une table
- Création d'une table pour les données au format ORC
- Sélection de données Hive et récupération d'un DataFrame
- Écriture par lots d'un DataFrame vers Hive
- Exécution d'une instruction de mise à jour Hive
- Lecture des données d’une table à partir de Hive, transformation de ces données dans Spark, puis leur écriture dans une nouvelle table Hive
- Écriture d'un flux DataFrame ou Spark vers Hive à l'aide de HiveStreaming
Configuration du connecteur d’entrepôt Hive
Important
- L’instance HiveServer2 Interactive installée sur les clusters Pack Sécurité Entreprise Spark 2.4 n’est pas prise en charge pour une utilisation avec Hive Warehouse Connector. Vous devez configurer un cluster HiveServer2 Interactive distinct pour héberger vos charges de travail HiveServer2 Interactive. Une configuration Hive Warehouse Connector utilisant un cluster Spark 2.4 unique n’est pas prise en charge.
- La bibliothèque Hive Warehouse Connector (HWC) n’est pas prise en charge pour une utilisation avec des clusters Interactive Query où la fonctionnalité de gestion de la charge de travail (WLM) est activée.
Dans un scénario où vous avez uniquement des charges de travail Spark et souhaitez utiliser la bibliothèque HWC, vérifiez que la fonctionnalité de gestion de la charge de travail du cluster Interactive Query n’est pas activée (la configuration dehive.server2.tez.interactive.queuen’est pas définie dans les configurations Hive).
Dans un scénario où des charges de travail Spark (HWC) et des charges de travail natives LLAP existent, vous devez créer deux clusters Interactive Query distincts avec une base de données metastore partagée. Un cluster pour les charges de travail LLAP natives où la fonctionnalité WLM peut être activée en fonction des besoins et un autre cluster pour la charge de travail HWC uniquement où la fonctionnalité WLM ne doit pas être configurée. Il est important de noter que vous pouvez afficher les plans de ressources WLM à partir des deux clusters, même s’ils sont activés dans un seul cluster. N’apportez aucune modification aux plans de ressources dans le cluster où la fonctionnalité WLM est désactivée, car cela peut avoir un impact sur la fonctionnalité WLM dans l’autre cluster. - Bien que Spark prenne en charge le langage de calcul R pour simplifier son analyse des données, la bibliothèque Hive Warehouse Connector (HWC) n’est pas prise en charge pour une utilisation avec R. Pour exécuter des charges de travail HWC, vous pouvez exécuter des requêtes à partir de Spark sur Hive à l’aide de l’API HiveWarehouseSession de type JDBC qui prend uniquement en charge Scala, Java et Python.
- L’exécution de requêtes (à la fois en lecture et en écriture) par le biais de HiveServer2 via le mode JDBC n’est pas prise en charge pour les types de données complexes tels que les types Arrays/Struct/Map.
- HWC prend uniquement en charge l’écriture dans les formats de fichiers ORC. Les écritures non ORC (par exemple, les formats de fichiers Parquet et texte) ne sont pas prises en charge via HWC.
Hive Warehouse Connector a besoin de clusters distincts pour les charges de travail Spark et Interactive Query. Suivez les étapes ci-dessous pour configurer ces clusters dans Azure HDInsight.
Versions et types de cluster pris en charge
| Version HWC | Version de Spark | Version InteractiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Requêtes interactives 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Requêtes interactives 3.1 | HDI 5.0 |
Créer des clusters
Créez un cluster HDInsight Spark 4.0 avec un compte de stockage et un réseau virtuel Azure personnalisé. Pour plus d'informations sur la création d'un cluster dans un réseau virtuel Azure, voir Ajouter HDInsight à un réseau virtuel existant.
Créez un cluster HDInsight Interactive Query (LLAP) 4.0 avec le même compte de stockage et le même réseau virtuel Azure que pour le cluster Spark.
Configurer les paramètres HWC
Recueillir des informations préliminaires
À partir d’un navigateur web, accédez à
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE, où LLAPCLUSTERNAME est le nom de votre cluster Interactive Query.Accédez à Summary>HiveServer2 Interactive JDBC URL et notez la valeur. La valeur peut être similaire à :
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Accédez à Configs>Advanced>Advanced hive-site>hive.zookeeper.quorum et notez la valeur. La valeur peut être similaire à :
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Accédez à Configs>Advanced>General>hive.metastore.uris et notez la valeur. La valeur peut être similaire à :
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Accédez à Configs>Advanced>Advanced hive-interactive-site>hive.llap.daemon.service.hosts et notez la valeur. La valeur peut être similaire à :
@llap0.
Configurer les paramètres du cluster Spark
À partir d’un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs, où CLUSTERNAME est le nom de votre cluster Apache Spark.Développez Custom spark2-defaults.
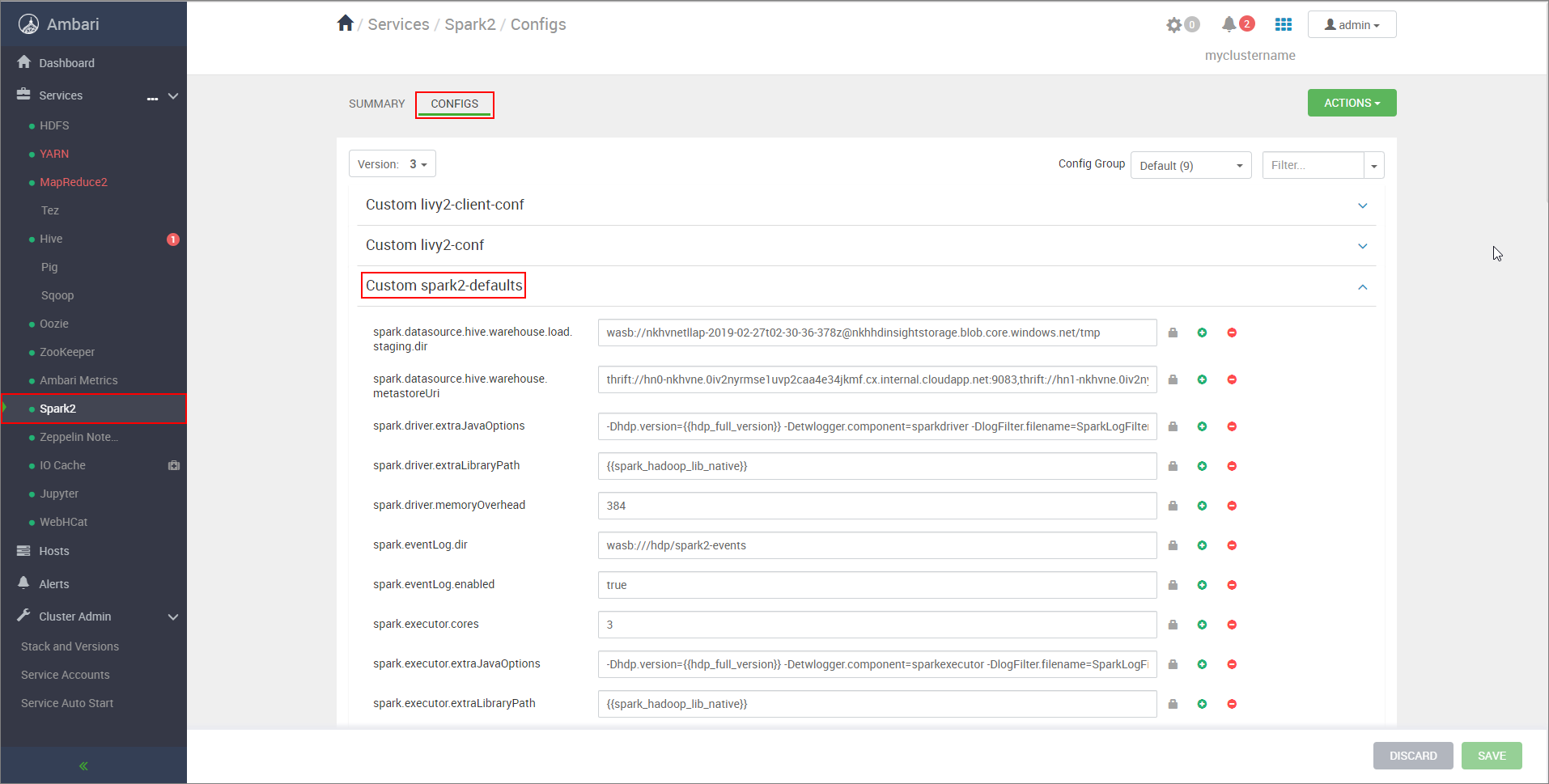
Sélectionnez Add Property... (Ajouter une propriété...) pour ajouter les configurations suivantes :
Configuration Valeur spark.datasource.hive.warehouse.load.staging.dirSi vous utilisez un compte de stockage ADLS Gen2, utilisez abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Si vous utilisez un compte Stockage Blob Azure, utilisezwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Définir sur un répertoire de préproduction compatible HDFS approprié. Si vous utilisez deux clusters différents, ce répertoire doit être un dossier dans le répertoire de préproduction du compte de stockage du cluster LLAP afin que HiveServer2 puisse y accéder. RemplacezSTORAGE_ACCOUNT_NAMEpar le nom du compte de stockage utilisé par le cluster etSTORAGE_CONTAINER_NAMEpar le nom du conteneur de stockage.spark.sql.hive.hiveserver2.jdbc.urlValeur que vous avez obtenue précédemment à partir de HiveServer2 Interactive JDBC URL spark.datasource.hive.warehouse.metastoreUriLa valeur que vous avez obtenue précédemment à partir de hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtruepour le mode de cluster YARN etfalsepour le mode client YARN.spark.hadoop.hive.zookeeper.quorumLa valeur que vous avez obtenue précédemment à partir de hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsLa valeur que vous avez obtenue précédemment à partir de hive.llap.daemon.service.hosts. Enregistrez les modifications, puis redémarrez tous les composants concernés.
Configurer HWC pour des clusters Pack Sécurité Entreprise (ESP)
Le Pack Sécurité Entreprise (ESP) vous fournit des fonctionnalités de qualité professionnelle, notamment l’authentification basée sur Active Directory, la prise en charge multi-utilisateur et le contrôle d’accès en fonction du rôle pour les clusters Apache Hadoop dans Azure HDInsight. Pour plus d’informations sur le pack ESP, consultez Utiliser le Pack Sécurité Entreprise dans HDInsight.
En dehors des configurations mentionnées dans la section précédente, ajoutez la configuration suivante pour utiliser HWC sur les clusters ESP.
À partir de l’interface utilisateur web Ambari du cluster Spark, accédez à Spark2>CONFIGS>Custom spark2-defaults.
Mettez à jour la propriété suivante.
Configuration Valeur spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>À partir d’un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, où CLUSTERNAME est le nom de votre cluster Interactive Query. Cliquez sur HiveServer2 Interactive. Vous verrez le nom de domaine complet (FQDN) du nœud principal sur lequel LLAP s’exécute, comme indiqué dans la capture d’écran. Remplacez<llap-headnode>par cette valeur.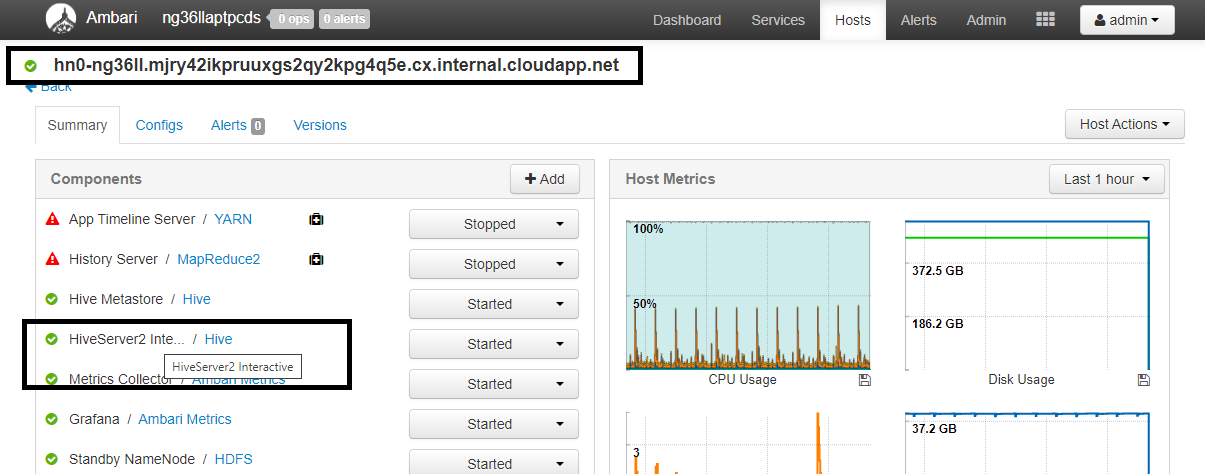
Utilisez la commande ssh pour vous connecter à votre cluster Interactive Query. Recherchez le paramètre
default_realmdans le fichier/etc/krb5.conf. Remplacez<AAD-DOMAIN>par cette valeur sous forme de chaîne en majuscules, sinon les informations d’identification ne seront pas trouvées.
Par exemple,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Enregistrez les modifications et redémarrez les composants si nécessaire.
Utilisation de Hive Warehouse Connector
Vous pouvez choisir entre différentes méthodes pour vous connecter à votre cluster Interactive Query et exécuter des requêtes à l'aide du connecteur d’entrepôt Hive. Les méthodes prises en charge incluent les outils suivants :
Vous trouverez ci-dessous des exemples de connexion à HWC à partir de Spark.
Spark-shell
Il s’agit d’un moyen d’exécuter Spark de manière interactive par le biais d’une version modifiée de l’interpréteur de commandes Scala.
Utilisez une commande ssh pour vous connecter à votre cluster Apache Spark. Modifiez la commande ci-dessous en remplaçant CLUSTERNAME par le nom de votre cluster, puis entrez la commande :
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netÀ partir de votre session ssh, exécutez la commande suivante pour noter la version de
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorModifiez le code ci-dessous avec la version de
hive-warehouse-connector-assemblyidentifiée ci-dessus. Exécutez ensuite la commande pour démarrer l’interpréteur de commandes Spark :spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseAprès que vous avez démarré l’interpréteur de commandes Spark, une instance de Hive Warehouse Connector peut être démarrée à l’aide des commandes suivantes :
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit est un utilitaire qui permet de soumettre un programme (ou un travail) Spark à des clusters Spark.
Le travail spark-submit va installer et configurer Spark et Hive Warehouse Connector conformément à nos instructions, exécuter le programme que nous lui passons, puis libérer correctement les ressources qui étaient utilisées.
Une fois que vous avez créé le code scala/java avec les dépendances dans un fichier jar d’assembly, utilisez la commande ci-dessous pour lancer une application Spark. Remplacez <VERSION> et <APP_JAR_PATH> par les valeurs réelles.
Mode client YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarMode de cluster YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Cet utilitaire est également utilisé lors de l’écriture de l’ensemble de l’application dans pySpark et de son empaquetage dans des fichiers.py (Python), afin que nous puissions soumettre l’intégralité du code au cluster Spark en vue de son exécution.
Pour les applications Python, passez un fichier .py à la place de /<APP_JAR_PATH>/myHwcAppProject.jar, puis ajoutez le fichier de configuration (.zip Python) ci-dessous au chemin de recherche avec --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Exécuter des requêtes sur des clusters Pack Sécurité Entreprise (ESP)
Utilisez kinit avant de lancer spark-shell ou spark-submit. Remplacez USERNAME par le nom d’un compte de domaine doté d’autorisations d’accès au cluster, puis exécutez la commande suivante :
kinit USERNAME
Sécurisation des données sur les clusters ESP Spark
Créez une table
demoavec quelques exemples de données en entrant les commandes suivantes :create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Visualisez le contenu de la table avec la commande suivante. Avant que vous appliquiez la stratégie, la table
demoaffiche la colonne complète.hive.executeQuery("SELECT * FROM demo").show()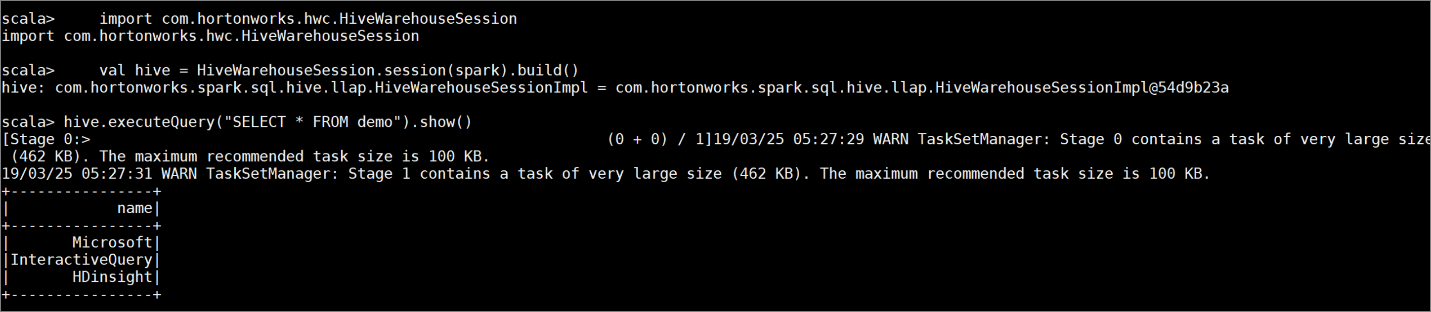
Appliquez une stratégie de masquage des colonnes qui n'affiche que les quatre derniers caractères de la colonne.
Accédez à l’interface utilisateur de l’administrateur Ranger à l’adresse
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Cliquez sur le service Hive pour votre cluster sous Hive.
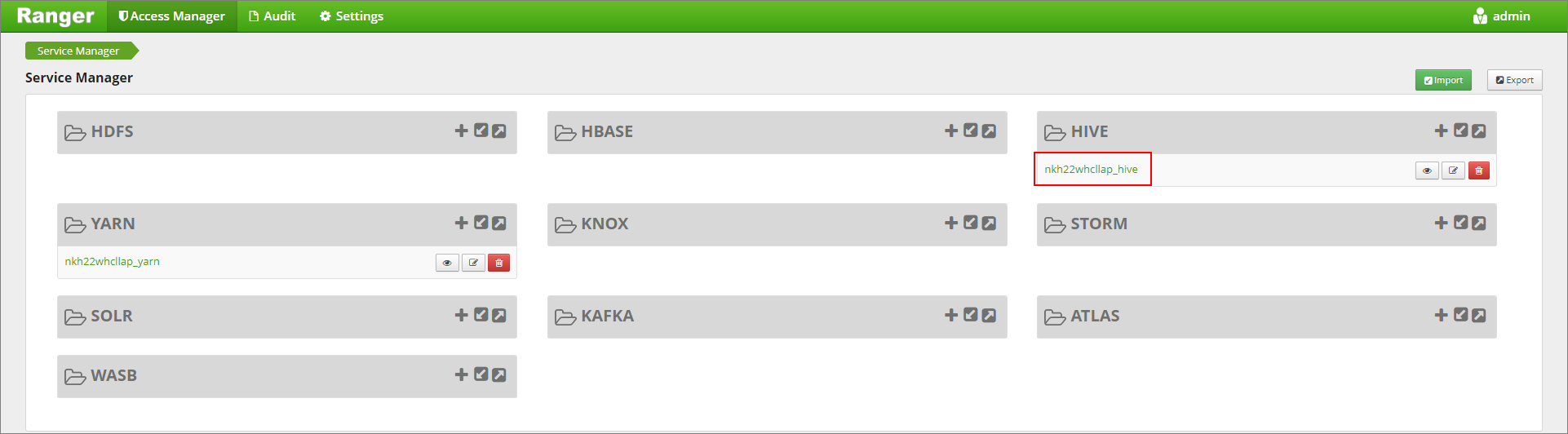
Cliquez sur l’onglet Masquage, puis sur Ajouter une nouvelle stratégie
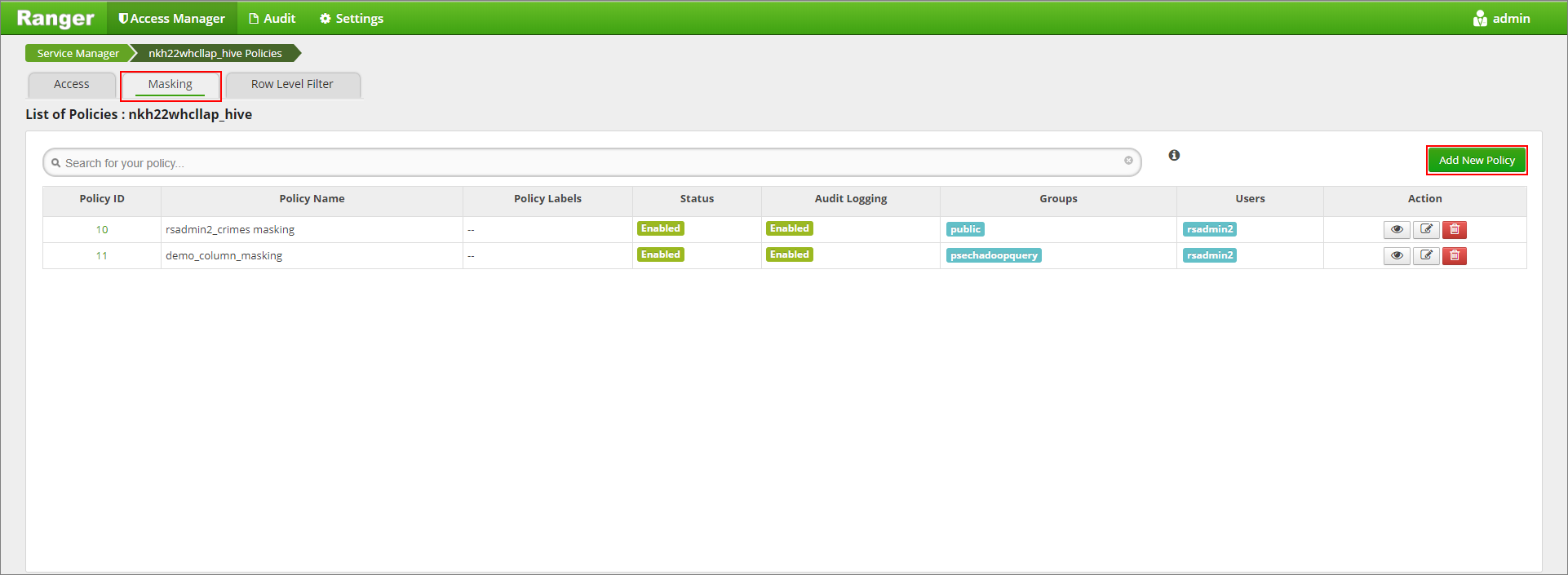
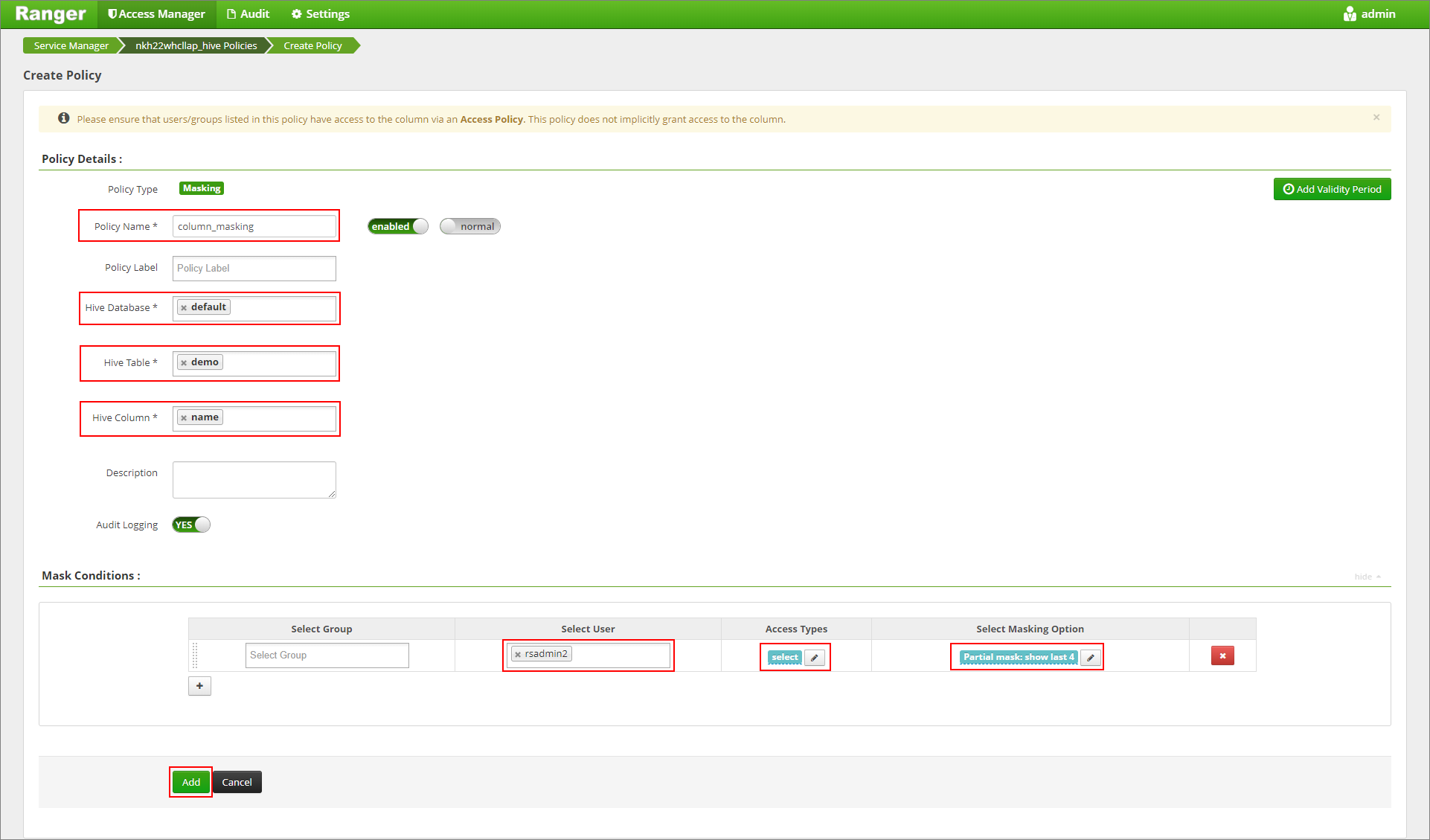
Nommez la stratégie. Sélectionnez la base de données : Default, Table Hive : demo, Colonne Hive : name, Utilisateur : rsadmin2, Types d’accès : select, et Partial mask: show last 4 dans le menu Select Masking Option (Sélectionner l’option de masquage). Cliquez sur Ajouter.
Affichez à nouveau le contenu de la table. Après avoir appliqué la stratégie Ranger, nous ne voyons que les quatre derniers caractères de la colonne.
