Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Dans ce guide de démarrage rapide, vous utilisez le portail Azure pour créer un cluster Apache Spark dans Azure HDInsight. Vous créez ensuite un notebook Jupyter et utilisez-le pour exécuter des requêtes Spark SQL sur des tables Apache Hive. Azure HDInsight est un service d’analytique open source managé, complet et à spectre complet pour les entreprises. Le framework Apache Spark pour HDInsight permet une analytique données et des calculs sur cluster rapides à l’aide du traitement en mémoire. Jupyter Notebook vous permet d’interagir avec vos données, de combiner du code avec du texte markdown et d’effectuer des visualisations simples.
Pour obtenir des explications détaillées sur les configurations disponibles, consultez Configurer des clusters dans HDInsight. Pour plus d’informations sur l’utilisation du portail pour créer des clusters, consultez Créer des clusters dans le portail.
Si vous utilisez plusieurs clusters ensemble, vous souhaiterez peut-être créer un réseau virtuel ; Si vous utilisez un cluster Spark, vous pouvez également utiliser Hive Warehouse Connector. Pour plus d’informations, consultez Planifier un réseau virtuel pour Azure HDInsight et Intégrer Apache Spark et Apache Hive à Hive Warehouse Connector.
Important
La facturation pour les clusters HDInsight est calculée au prorata par minute, que vous les utilisiez ou non. Veillez à supprimer votre cluster une fois que vous avez terminé de l’utiliser. Pour plus d’informations, consultez la section Nettoyer les ressources de cet article.
Prerequisites
Un compte Azure avec un abonnement actif. Créez un compte gratuitement.
Créer un cluster Apache Spark dans HDInsight
Vous utilisez le portail Azure pour créer un cluster HDInsight qui utilise des Blobs de stockage Azure comme stockage pour le cluster. Pour plus d’informations sur l’utilisation de Data Lake Storage Gen2, consultez Démarrage rapide : Configurer des clusters dans HDInsight.
Connectez-vous au portail Azure.
Dans le menu du haut, sélectionnez + Créer une ressource.
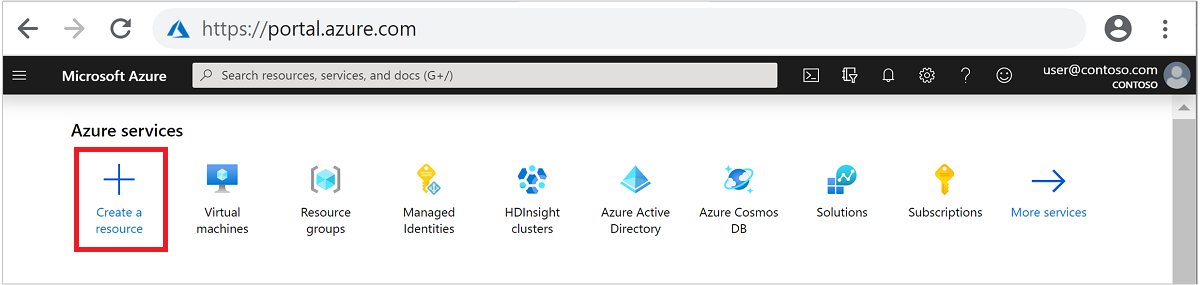
Sélectionnez Analytics>Azure HDInsight pour accéder à la page Créer un cluster HDInsight .
Sous l’onglet Informations de base , fournissez les informations suivantes :
Propriété Descriptif Subscription Dans la liste déroulante, sélectionnez l’abonnement Azure utilisé pour le cluster. groupe de ressources Dans la liste déroulante, sélectionnez votre groupe de ressources existant ou Créer. Nom du cluster Entrez un nom globalement unique. Région Dans la liste déroulante, sélectionnez une région où le cluster est créé. Zone de disponibilité Facultatif : spécifiez une zone de disponibilité dans laquelle déployer votre cluster Type de cluster Sélectionnez le type de cluster pour ouvrir une liste. Dans la liste, sélectionnez Spark. Version du cluster Lorsque le type de cluster est sélectionné, ce champ est automatiquement renseigné avec la version par défaut. Nom d’utilisateur de connexion du cluster Entrez le nom d’utilisateur de connexion du cluster. Le nom par défaut est administrateur. Vous utilisez ce compte pour vous connecter au bloc-notes Jupyter ultérieurement dans le guide de démarrage rapide. Mot de passe de connexion du cluster Entrez le mot de passe de connexion du cluster. Nom d’utilisateur SSH (Secure Shell) Entrez le nom d’utilisateur SSH. Le nom d’utilisateur SSH utilisé pour ce démarrage rapide est sshuser. Par défaut, ce compte partage le même mot de passe que le compte de nom d’utilisateur de connexion au cluster. 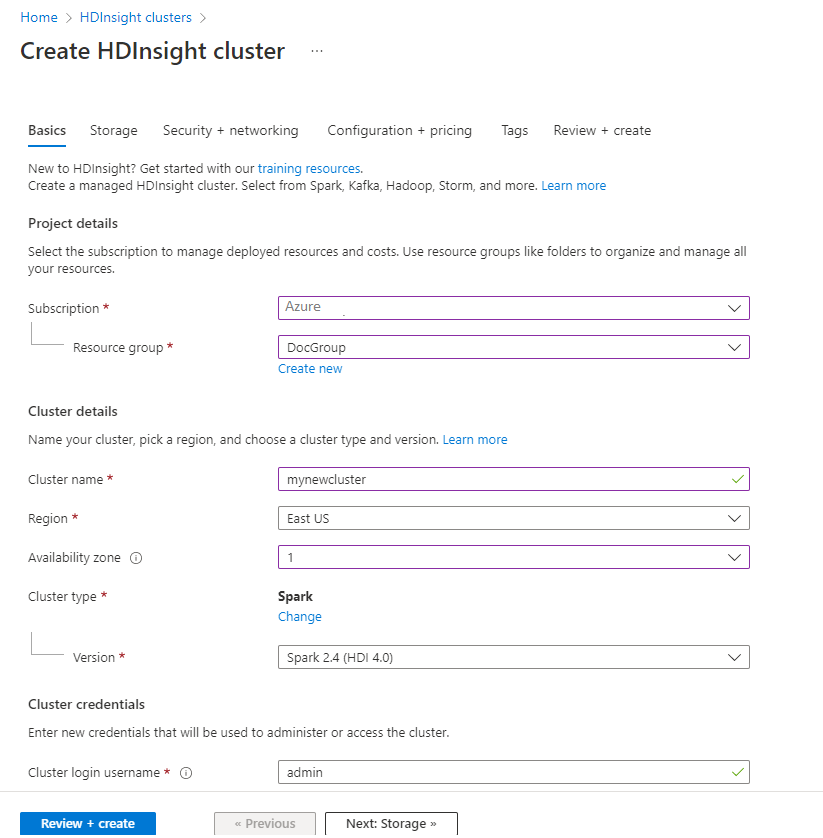
Sélectionnez Suivant : Stockage >> pour passer à la page Stockage .
Sous Stockage, fournissez les valeurs suivantes :
Propriété Descriptif Type de stockage principal Utilisez la valeur par défaut stockage Azure. Méthode de sélection Utilisez la valeur par défaut Sélectionner dans la liste. Compte de stockage principal Utilisez la valeur renseignée automatiquement. Conteneur Utilisez la valeur renseignée automatiquement. 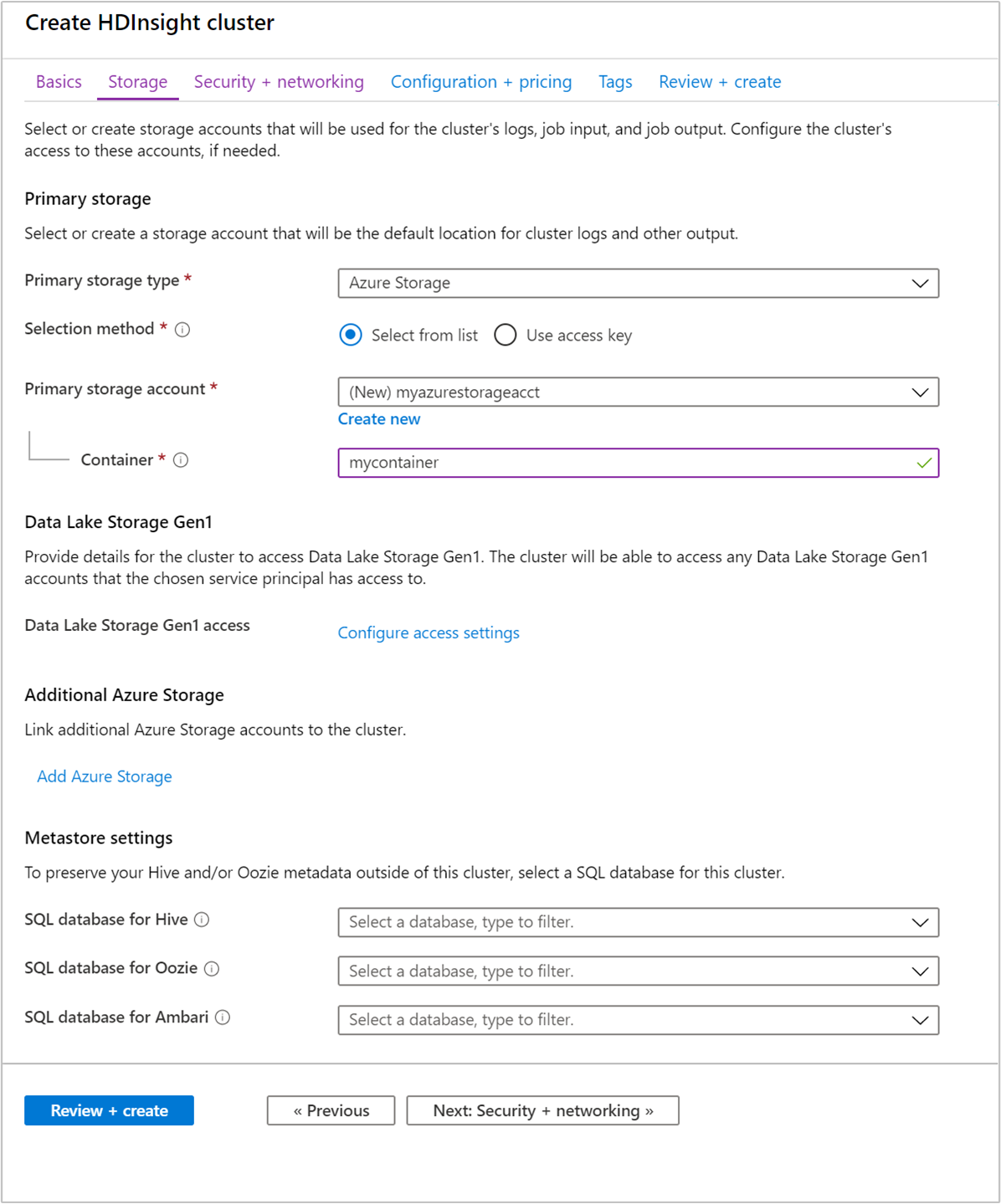
Sélectionnez Vérifier + créer pour continuer.
Sous Vérifier + créer, sélectionnez Créer. La création du cluster prend environ 20 minutes. Il faut que le cluster soit créé pour pouvoir passer à la prochaine session.
Si vous rencontrez un problème avec la création de clusters HDInsight, il se peut que vous n’ayez pas les autorisations appropriées pour le faire. Pour plus d’informations, consultez la configuration requise pour le contrôle d’accès.
Créer un notebook Jupyter
Jupyter Notebook est un environnement de notebook interactif qui prend en charge différents langages de programmation. Le notebook vous permet d’interagir avec vos données, de combiner du code avec du texte markdown et d’effectuer des visualisations simples.
À partir d’un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/jupyter, oùCLUSTERNAMEest le nom de votre cluster. Si vous y êtes invité, entrez les informations d’identification de connexion du cluster.Sélectionnez New>PySpark pour créer un notebook.
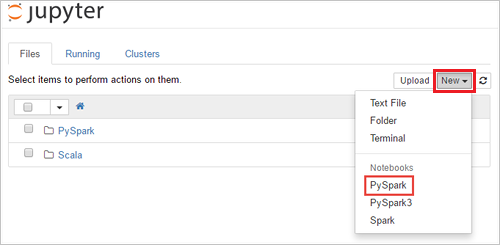
Un nouveau notebook est créé et ouvert avec le nom Untitled(Untitled.pynb).
Exécuter des instructions APACHE Spark SQL
SQL (Langage de requête structurée) est le langage le plus courant et le plus couramment utilisé pour interroger et définir des données. Spark SQL fonctionne comme extension d’Apache Spark pour le traitement des données structurées à l’aide de la syntaxe SQL familière.
Vérifiez que le noyau est prêt. Le noyau est prêt lorsque vous voyez un cercle creux en regard du nom du noyau dans le bloc-notes. Le cercle solide indique que le noyau est occupé.

Lorsque vous démarrez le notebook pour la première fois, le noyau effectue certaines tâches en arrière-plan. Attendez que le noyau soit prêt.
Collez le code suivant dans une cellule vide, puis appuyez sur Maj + Entrée pour exécuter le code. La commande répertorie les tables Hive sur le cluster :
%%sql SHOW TABLESLorsque vous utilisez un notebook Jupyter avec votre cluster HDInsight, vous obtenez une présélection
sqlContextque vous pouvez utiliser pour exécuter des requêtes Hive à l’aide de Spark SQL.%%sqlindique à Jupyter Notebook d’utiliser la présélectionsqlContextpour exécuter la requête Hive. La requête récupère les 10 premières lignes d’une table Hive (hivesampletable) fournie par défaut avec tous les clusters HDInsight. Il faut environ 30 secondes pour obtenir les résultats. Le résultat se présente ainsi :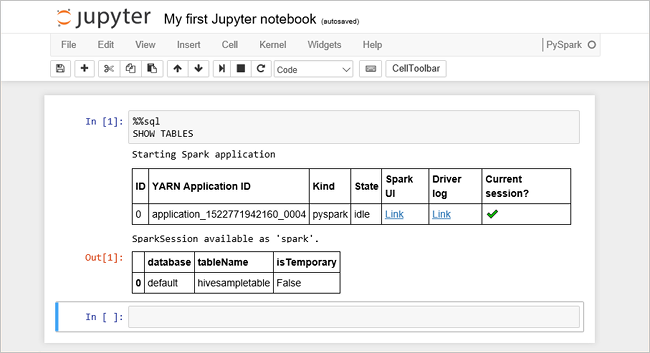 s’agit du démarrage rapide." border="true":::
s’agit du démarrage rapide." border="true":::Chaque fois que vous exécutez une requête dans Jupyter, le titre de la fenêtre du navigateur web affiche un état (Occupé) ainsi que le titre du bloc-notes. Vous voyez également un cercle plein en regard du texte PySpark dans le coin supérieur droit.
Exécutez une autre requête pour afficher les données dans
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10L’écran doit s’actualiser pour afficher la sortie de la requête.
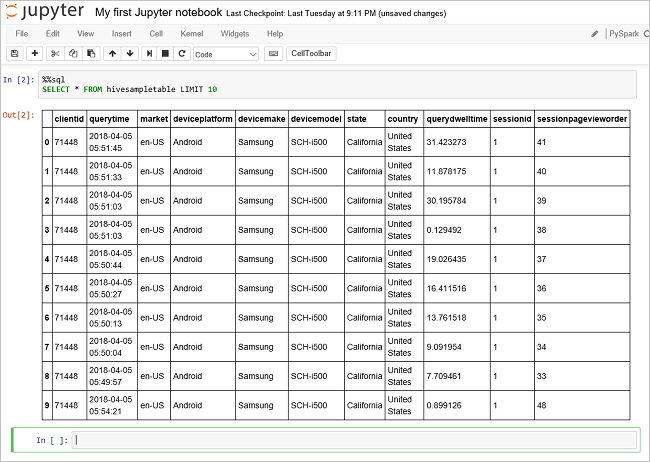 Insight" border="true":::
Insight" border="true":::Dans le menu Fichier du bloc-notes, sélectionnez Fermer et Arrêter. L’arrêt du notebook libère les ressources du cluster.
Nettoyer les ressources
HDInsight enregistre vos données dans Stockage Azure ou Azure Data Lake Storage. Vous pouvez donc supprimer en toute sécurité un cluster lorsqu’il n’est pas utilisé. Vous devez également payer pour un cluster HDInsight, même quand vous ne l’utilisez pas. Étant donné que les frais pour le cluster sont bien plus élevés que les frais de stockage, mieux vaut supprimer les clusters quand ils ne sont pas utilisés. Si vous envisagez de travailler sur le didacticiel répertorié dans les étapes suivantes immédiatement, vous souhaiterez peut-être conserver le cluster.
Revenez au portail Azure, puis sélectionnez Supprimer.
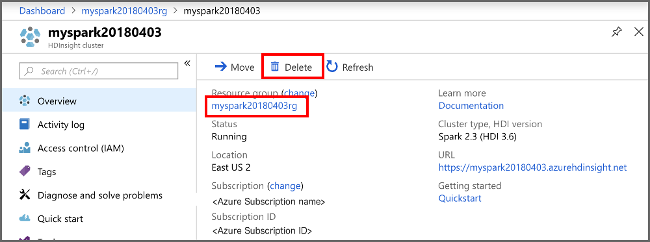 sight cluster" border="true":::
sight cluster" border="true":::
Vous pouvez également sélectionner le nom du groupe de ressources pour ouvrir la page du groupe de ressources, puis sélectionner Supprimer le groupe de ressources. En supprimant le groupe de ressources, vous supprimez à la fois le cluster HDInsight et le compte de stockage par défaut.
Étapes suivantes
Dans ce guide de démarrage rapide, vous avez appris à créer un cluster Apache Spark dans HDInsight et à exécuter une requête Spark SQL de base. Passez au tutoriel suivant pour apprendre à utiliser un cluster HDInsight pour exécuter des requêtes interactives sur des exemples de données.