Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Apprenez à utiliser Apache Spark MLlib pour créer une application de Machine Learning. L'application effectue une analyse prédictive sur un jeu de données ouvert. À partir des bibliothèques de Machine Learning intégrées de Spark, cet exemple utilise une classification de régression logistique.
MLLib est une bibliothèque Spark de base qui fournit de nombreux utilitaires très pratiques pour les tâches de Machine Learning suivantes :
- classification ;
- régression ;
- Clustering
- Modélisation
- Décomposition de valeur singulière (SVD) et analyse des composants principaux (PCA)
- Hypothèse de test et de calcul des exemples de statistiques
Comprendre la classification et la régression logistique
Une classification, tâche de Machine Learning très courante, est le processus de tri de données d’entrée par catégories. La fonction d'un algorithme de classification consiste à déterminer comment attribuer des « étiquettes » aux données d'entrée que vous fournissez. Par exemple, vous pourriez penser à un algorithme de Machine Learning qui accepte les informations relatives à un stock comme données d'entrée. Puis qui divise le stock en deux catégories : le stock que vous devez vendre et le stock que vous devez conserver.
La régression logistique correspond à l’algorithme que vous utilisez pour la classification. L’API de régression logistique de Spark est utile pour la classification binaireou pour classer les données d’entrée dans un des deux groupes. Pour plus d’informations sur la régression logistique, consultez Wikipedia.
En résumé, le processus de régression logistique produit une fonction logistique. Utilisez cette fonction pour prédire la probabilité qu'un vecteur d'entrée appartienne à l'un ou l'autre des groupes.
Exemple d’analyse prédictive sur des données d’inspection alimentaire
Dans cet exemple, vous utilisez Spark pour effectuer une analyse prédictive sur des données d'inspection alimentaire (Food_Inspections1.csv). Données acquises via le portail de données de la ville de Chicago. Ce jeu de données contient des informations sur les inspections des établissements alimentaires menées à Chicago. Notamment des informations sur chaque établissement, les infractions constatées (le cas échéant) et les résultats de l'inspection. Le fichier de données CSV est déjà disponible dans le compte de stockage associé au cluster dans /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
Dans les étapes suivantes, vous développez un modèle pour voir ce qui est nécessaire à la réussite ou à l’échec d’une inspection alimentaire.
Créer une application de Machine Learning Apache Spark MLlib
Créez un fichier Jupyter Notebook en utilisant le noyau PySpark. Pour obtenir des instructions, consultez Créer un fichier Jupyter Notebook.
Importez les types requis pour cette application. Copiez et collez le code suivant dans une cellule vide, puis appuyez sur MAJ + ENTRÉE.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Grâce au noyau PySpark, il est inutile de créer des contextes explicitement. Les contextes Spark et Hive sont automatiquement créés lorsque vous exécutez la première cellule de code.
Construire une trame de données d’entrée
Utilisez le contexte Spark pour extraire les données CSV brutes en mémoire sous forme de texte non structuré. Utilisez ensuite la bibliothèque CSV de Python pour analyser chaque ligne de données.
Exécutez les lignes suivantes pour créer un jeu de données distribué résilient (RDD) par l’importation et l’analyse des données d’entrée.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Exécutez le code suivant pour récupérer une ligne du RDD, afin de pouvoir observer le schéma de données :
inspections.take(1)La sortie est la suivante :
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]La sortie donne une idée du schéma du fichier d’entrée. Elle comprend le nom et le type de chaque établissement. Ainsi que l'adresse, les données des inspections et l'emplacement, entre autres.
Exécutez le code suivant pour créer une trame de données (df) et une table temporaire (CountResults) avec quelques colonnes utiles pour l’analyse prédictive.
sqlContextpermet d'effectuer des transformations sur des données structurées.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Les quatre colonnes qui vous intéressent dans la trame de données sont : ID, nom, résultats et infractions.
Exécutez le code suivant pour obtenir un petit échantillon de données :
df.show(5)La sortie est la suivante :
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Comprendre les données
Commençons par nous faire une idée de ce que contient le jeu de données.
Exécutez le code suivant pour afficher les valeurs distinctes dans la colonne résultats :
df.select('results').distinct().show()La sortie est la suivante :
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Exécutez le code suivant pour visualiser la distribution de ces résultats :
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsLa méthode
%%sqlsuivie par-o countResultsdfgarantit que le résultat de la requête est conservé localement sur le serveur Jupyter (généralement le nœud principal du cluster). Le résultat est conservé sous la forme d’une trame de données Pandas avec le nom spécifié countResultsdf. Pour plus d’informations sur la méthode magique%%sqlet d’autres méthodes magiques disponibles avec le noyau PySpark, consultez Noyaux disponibles sur Jupyter Notebooks avec clusters Apache Spark HDInsight.La sortie est la suivante :
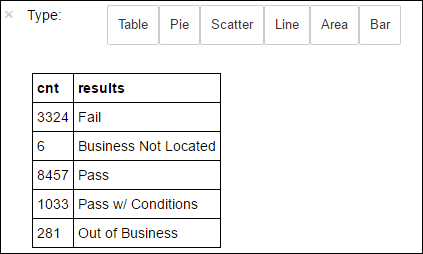
Vous pouvez également utiliser Matplotlib, une bibliothèque permettant de construire une visualisation des données, pour créer un tracé. Étant donné que le tracé doit être créé à partir du tableau de données countResultsdf conservé localement, l’extrait de code doit commencer par la commande magique
%%local. Cette action garantit l'exécution locale du code sur le serveur Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Pour prédire un résultat d’inspection de produits alimentaires, vous devez développer un modèle basé sur les violations. Étant donné que la régression logistique est une méthode de classification binaire, il est judicieux de regrouper les données de résultat en deux catégories : Échec et Réussite :
Réussite
- Réussite
- Réussite avec conditions
Échec
- Échec
Abandonner
- Entreprise introuvable
- Cessation d’activités
Les données comportant les autres résultats (« Entreprise introuvable » ou « Faillite ») sont inutiles et représentent de toute façon un faible pourcentage.
Exécutez le code suivant pour convertir la trame de données existante (
df) en une nouvelle trame de données dans laquelle chaque inspection est représentée par une paire étiquette-violations. Dans ce cas, une étiquette0.0représente un échec, une étiquette1.0représente un succès et une étiquette-1.0représente d'autres résultats.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Exécutez le code suivant pour afficher une ligne de données étiquetées :
labeledData.take(1)La sortie est la suivante :
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Créer un modèle de régression logistique à partir de la trame de données d’entrée
La dernière tâche consiste à convertir les données étiquetées. Convertissez les données dans un format analysé par une régression logistique. L'entrée d'un algorithme de régression logistique nécessite un ensemble de paires de vecteurs étiquette-fonctionnalité. Sachant que le « vecteur fonctionnalité » est un vecteur de nombres qui représentent le point d'entrée. Vous devez donc convertir la colonne « infractions », qui est semi-structurée et contient un grand nombre de commentaires sous forme de texte libre. Convertissez la colonne en un tableau de nombres réels faciles à comprendre pour un ordinateur.
Une approche standard de Machine Learning dans le cadre du traitement du langage naturel consiste à attribuer un index à chaque mot. Transmettez ensuite un vecteur à l'algorithme de Machine Learning. Afin que la valeur de chaque index contienne la fréquence relative de ce mot dans la chaîne de texte.
MLLib permet d'effectuer cette opération en toute simplicité. Tout d’abord, il convertit en jetons chaque chaîne de violations afin d’obtenir les mots de celle-ci. Ensuite, il utilise un HashingTF pour convertir chaque ensemble de jetons en un vecteur fonctionnalité qui peut ensuite être transmis à l’algorithme de régression logistique pour construire un modèle. Vous exécutez toutes ces étapes successivement en utilisant un pipeline.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Évaluer le modèle à l’aide d’un autre jeu de données
Vous pouvez utiliser le modèle créé précédemment pour prédire les résultats des nouvelles inspections. Les prédictions reposent sur les infractions qui ont été observées. Vous avez formé ce modèle sur le jeu de données Food_Inspections1.csv. Vous pouvez utiliser un deuxième jeu de données, Food_Inspections2.csv, pour évaluer la puissance de ce modèle sur les nouvelles données. Ce deuxième jeu de données (Food_Inspections2.csv) se trouve dans le conteneur de stockage par défaut associé au cluster.
Exécutez le code suivant pour créer une nouvelle trame de données, predictionsDf, qui contient la prédiction générée par le modèle. Il crée également une table temporaire, Predictions, basée sur la tramedonnées.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsUn résultat similaire à ce qui suit s’affiche normalement :
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Observez une des prédictions. Exécutez cet extrait de code :
predictionsDf.take(1)Le jeu de données de test contient une prédiction pour la première entrée.
La méthode
model.transform()applique la même transformation à toutes les nouvelles données possédant le même schéma afin d’obtenir une prédiction permettant de classer les données. Vous pouvez générer des statistiques pour avoir une idée des prédictions :numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")La sortie ressemble au texte suivant :
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateL'utilisation de la régression logistique avec Spark vous fournit un modèle de la relation entre les descriptions des infractions, en anglais. Et indique si une entreprise donnée réussirait ou non l'inspection alimentaire.
Créer une représentation visuelle de la prédiction
Vous pouvez désormais construire une visualisation finale pour faciliter l’examen des résultats de ce test.
Vous commencez par extraire les différents prédictions et résultats de la table temporaire Predictions créée précédemment. Les requêtes suivantes séparent la sortie en tant que true_positive, false_positive, true_negative et false_negative. Dans les requêtes ci-après, vous désactivez la visualisation en utilisant
-qet vous enregistrez la sortie (avec-o) sous la forme de trames de données qui sont ensuite utilisables avec la magie%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Enfin, utilisez l’extrait suivant pour générer le tracé à l’aide de Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Vous devez normalement voir la sortie suivante.
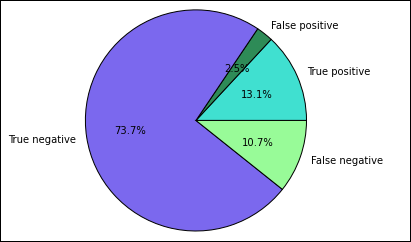
Dans ce graphique, un résultat « positif » fait référence à l’inspection de produits alimentaires ayant échoué, tandis qu’un résultat négatif fait référence à une inspection réussie.
Arrêtez le bloc-notes
Une fois l’exécution de l’application terminée, fermez le notebook pour la mise en production des ressources. Pour ce faire, dans le menu Fichier du bloc-notes, sélectionnez Fermer et arrêter. Cela a pour effet d’arrêter et de fermer le bloc-notes.