Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Apache Spark Streaming propose le traitement des flux de données sur les clusters HDInsight Spark. Il garantit que tout événement d’entrée est traité une seule fois, même en cas de défaillance d’un nœud. Un flux Spark est un travail durable qui reçoit des données d’entrée provenant d’un large éventail de sources, notamment Azure Event Hubs. Également : Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, sockets TCP bruts ou à partir d’un monitoring de systèmes de fichiers YARN Apache Hadoop. Contrairement à un processus uniquement déclenché par des événements, un flux Spark regroupe les données d’entrée dans des fenêtres temporelles (par exemple, une tranche de 2 secondes), puis transforme chaque lot de données à l’aide d’opérations de mappage, de réduction, de jointure et d’extraction. Spark Stream écrit ensuite les données transformées dans les systèmes de fichiers, les bases de données, les tableaux de bord et la console.
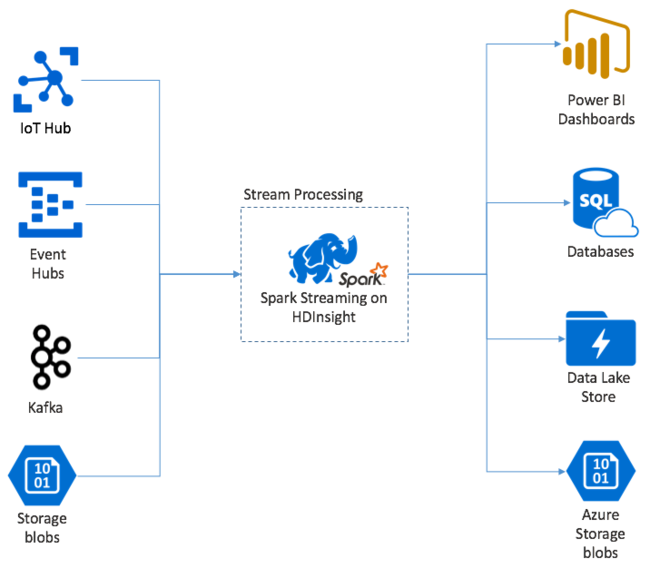
Les applications Spark Streaming doivent attendre quelques fractions de seconde avant de pouvoir collecter chaque micro-batch d’événements et envoyer ce lot pour traitement. En revanche, une application basée sur les événements traite chaque événement immédiatement. La latence de Spark Streaming est généralement inférieure à quelques secondes. Les avantages de l’approche par micro-lots sont un traitement plus efficace des données et des calculs d’agrégation plus simples.
Présentation de DStream
Spark Streaming représente un flux continu de données entrantes utilisant un flux de données discrétisé appelé DStream. Un DStream peut être créé à partir de sources d’entrée telles que Event Hubs ou Kafka, ou en appliquant des transformations sur un autre DStream.
Un DStream fournit une couche d’abstraction sur les données d’événement brutes.
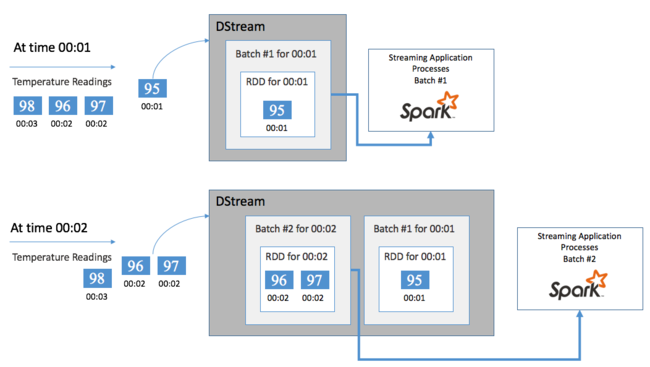
Commençons par un événement unique, par exemple une lecture de température depuis un thermostat connecté. Quand cet événement arrive à votre application Spark Streaming, il y est stocké de manière fiable et y est répliqué sur plusieurs nœuds. Cette tolérance de panne garantit que la défaillance d’un nœud unique n’entraîne pas la perte de votre événement. Le noyau Spark utilise une structure de données qui distribue les données sur plusieurs nœuds du cluster, où chaque nœud conserve généralement ses propres données en mémoire pour des performances optimales. Cette structure de données est appelée un jeu de données distribué résilient (RDD).
Chaque RDD représente les événements collectés sur un laps de temps défini par l’utilisateur appelé l’intervalle de lots. Au fur et à mesure que chacun de ces intervalles s’écoule, un nouveau RDD contenant toutes les données de cet intervalle est produit. L’ensemble continu de RDD est collecté dans un DStream. Par exemple, si l’intervalle de traitement par lots est d’une seconde, votre DStream émet chaque seconde un lot incluant un RDD qui contient toutes les données ingérées durant cette seconde. Lors du traitement du DStream, l’événement de température apparaît dans l’un de ces lots. Une application Spark Streaming traite les lots qui contiennent les événements et agit en fin de compte sur les données stockées dans chaque RDD.
Structure d’une application Spark Streaming
Une application Spark Streaming est une application durable qui reçoit des données de sources d’ingestion. Elle applique les transformations pour traiter les données, puis envoie (push) les données vers une ou plusieurs destinations. La structure d’une application Spark Streaming a une partie statique et une partie dynamique. La partie statique définit la provenance des données, le traitement à appliquer aux données et l’emplacement où stocker les résultats. La partie dynamique exécute l’application indéfiniment, jusqu’au signal d’arrêt.
Voici par exemple une application simple qui reçoit une ligne de texte sur un socket TCP et qui compte le nombre d’apparition de chaque mot.
Définition de l’application
La définition logique de l’application consiste en quatre étapes :
- Créer un StreamingContext
- Créer un DStream à partir du StreamingContext
- Appliquer des transformations au DStream
- Afficher les résultats
Cette définition est statique et aucune donnée n’est traitée tant que vous n’exécutez pas l’application.
Créer un StreamingContext
Créez à partir du SparkContext un StreamingContext qui pointe vers votre cluster. Lorsque vous créez un StreamingContext, vous devez spécifier la taille du lot en secondes, par exemple :
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Créer un DStream
À l’aide de l’instance StreamingContext, créez un DStream d’entrée pour votre source d’entrée. Dans ce cas, l’application surveille l’apparition de nouveaux fichiers dans le stockage par défaut attaché.
val lines = ssc.textFileStream("/uploads/Test/")
Appliquer des transformations
Vous implémentez le traitement en appliquant des transformations au DStream. Cette application reçoit une ligne de texte à la fois à partir du fichier, divise chaque ligne en mots, puis utilise un modèle map-reduce pour compter le nombre de fois où chaque mot apparaît.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Afficher les résultats
Envoyez les résultats de transformation vers les systèmes de destination en appliquant des opérations de sortie. Dans ce cas, le résultat de chaque exécution à travers le calcul est imprimé dans la sortie de la console.
wordCounts.print()
Exécution de l'application
Démarrez l’application de diffusion en continu et exécutez-la jusqu'à la réception d’un signal d’arrêt.
ssc.start()
ssc.awaitTermination()
Pour plus d’informations sur l’API Spark Stream, consultez Guide de programmation d’Apache Spark Streaming.
L’exemple d’application suivant étant autonome, vous pouvez l’exécuter dans un Bloc-notes Jupyter. Cet exemple permet de créer une source de données fictive dans la classe DummySource qui génère la valeur d’un compteur et l’heure actuelle en millisecondes toutes les cinq secondes. Un nouvel objet StreamingContext a un intervalle de lots de 30 secondes. Chaque fois qu’un lot est créé, l’application de diffusion en continu examine le RDD produit. Elle convertit ensuite le RDD en DataFrame Spark et crée une table temporaire sur la DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Attendez environ 30 secondes après le démarrage de l’application ci-dessus. Vous pouvez ensuite interroger la trame de données régulièrement, afin de vérifier l’ensemble actuel de valeurs présentes dans le lot, par exemple à l’aide de cette requête SQL :
%%sql
SELECT * FROM demo_numbers
La sortie obtenue ressemble à la sortie suivante :
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Il existe six valeurs, étant donné que la classe DummySource crée une valeur toutes les 5 secondes et que l’application émet un lot toutes les 30 secondes.
Fenêtres glissantes
Afin d’effectuer des calculs d’agrégation sur votre DStream sur une certaine période de temps, par exemple pour obtenir une température moyenne sur les deux dernières secondes, utilisez les opérations sliding window incluses avec Spark Streaming. Une fenêtre glissante a une durée (la longueur de la fenêtre) et l’intervalle pendant lequel le contenu de la fenêtre est évalué (l’intervalle de glissement).
Ces fenêtres glissantes peuvent se chevaucher. Vous pouvez par exemple définir une fenêtre avec une longueur de deux secondes, qui glisse toutes les secondes. Cette action signifie que, chaque fois que vous effectuez un calcul d’agrégation, la fenêtre inclut les données de la dernière seconde de la fenêtre précédente ainsi que toutes les nouvelles données de la seconde suivante.
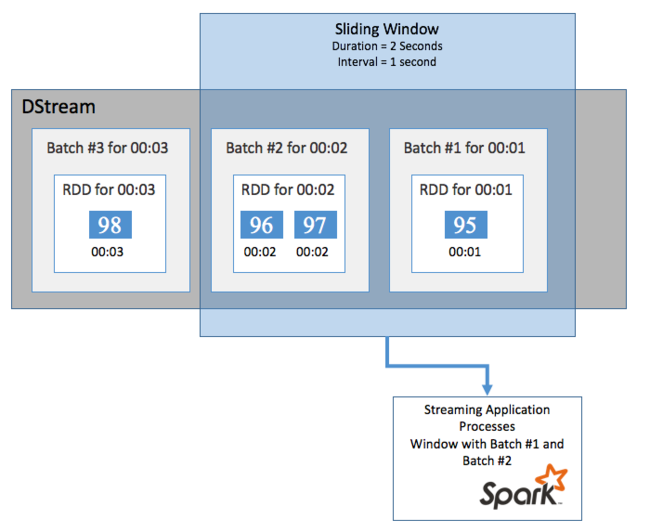
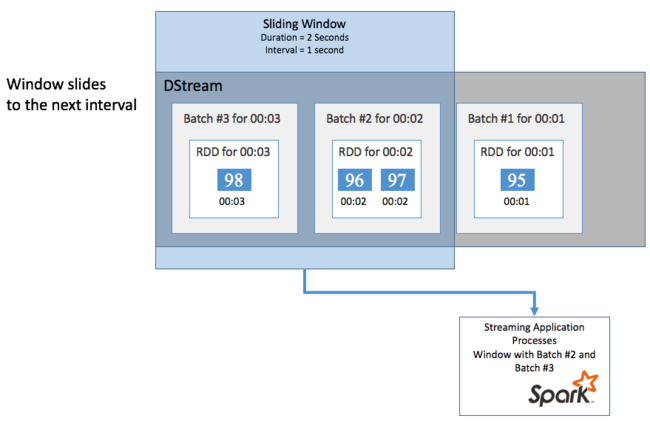
L’exemple suivant permet de mettre à jour le code qui utilise la classe DummySource pour collecter les lots dans une fenêtre avec une durée d’une minute et un glissement d’une minute.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Après la première minute, 12 entrées sont obtenues, à savoir 6 entrées de chacun des deux lots collectés dans la fenêtre.
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Les fonctions de fenêtre glissante disponibles dans l’API Spark Streaming incluent window, countByWindow, reduceByWindow et countByValueAndWindow. Pour plus d’informations sur ces fonctions, consultez Transformations sur DStreams.
Points de contrôle
Pour la résilience et la tolérance de panne, Spark Streaming s’appuie sur les points de contrôle pour s’assurer que le traitement de flux de données s’effectue sans interruption, même en cas de défaillances de nœud. Spark crée des points de contrôle pour un stockage durable (Stockage Azure ou Data Lake Storage). Ces points de contrôle stockent les métadonnées de l’application de diffusion en continu, telles que la configuration, les opérations définies par l’application et tous les lots qui ont été mis en file d’attente, mais qui n’ont pas encore été traités. Parfois, les points de contrôle incluent également l’enregistrement des données dans les RDD pour régénérer plus rapidement l’état des données à partir de ce qui existe dans les RDD gérés par Spark.
Déploiement d’applications Spark Streaming
En général, vous créez une application Spark Streaming localement dans un fichier JAR. Vous le déployez ensuite vers Spark sur HDInsight en copiant le fichier JAR sur le stockage attaché par défaut. Vous pouvez démarrer votre application à l’aide des API REST LIVY disponibles dans votre cluster à l’aide de l’opération POST. Le corps de l’opération POST inclut un document JSON qui fournit le chemin d’accès à votre fichier JAR, le nom de la classe dont la méthode principale définit et exécute l’application de diffusion en continu et éventuellement les besoins en ressources du travail (tels que le nombre d’exécuteurs et de cœurs et la quantité de mémoire). Il inclut également tous les paramètres de configuration requis par votre code d’application.
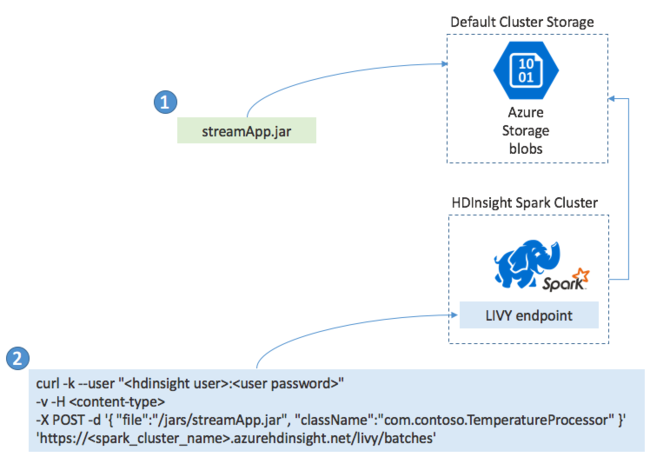
L’état de toutes les applications peut également être vérifié à l’aide d’une requête GET sur un point de terminaison LIVY. Enfin, vous pouvez terminer une application en cours d’exécution en émettant une requête DELETE sur le point de terminaison LIVY. Pour plus d’informations sur l’API LIVY, consultez Travaux à distance avec Apache LIVY