Bien démarrer l’utilisation des données DICOM dans les charges de travail d’analytique
Cet article explique comment bien démarrer l’utilisation des données DICOM® dans les charges de travail d’analytique avec Azure Data Factory et Microsoft Fabric.
Prérequis
Avant de commencer, suivez ces étapes :
- Créez un compte de stockage avec les fonctionnalités d’Azure Data Lake Storage Gen2 en activant un espace de noms hiérarchique :
- Créez un conteneur pour stocker les métadonnées DICOM, par exemple un conteneur nommé
dicom.
- Créez un conteneur pour stocker les métadonnées DICOM, par exemple un conteneur nommé
- Déployez une instance du service DICOM.
- (Facultatif) Déployez le service DICOM avec Data Lake Storage pour permettre un accès direct aux fichiers DICOM.
- Créez une instance de Data Factory :
- Activez une identité managée affectée par le système.
- Créez un lakehouse dans Fabric.
- Ajoutez des attributions de rôles à l’identité managée affectée par le système Data Factory pour le service DICOM et le compte de stockage Data Lake Storage Gen2 :
- Ajoutez le rôle Lecteur de données DICOM pour octroyer l’autorisation nécessaire au service DICOM.
- Ajoutez le rôle Contributeur aux données Blob du stockage pour octroyer l’autorisation nécessaire au compte Data Lake Storage Gen2.
Configurer un pipeline Data Factory pour le service DICOM
Dans cet exemple, un pipeline Data Factory est utilisé pour écrire les attributs DICOM des instances, des séries et des études au sein d’un compte de stockage dans un format de table Delta.
Dans le portail Azure, ouvrez l’instance de Data Factory, puis sélectionnez Lancer Studio pour commencer.

Créez des services liés
Les pipelines Data Factory lisent des sources de données et écrivent dans des récepteurs de données, qui sont généralement d’autres services Azure. Ces connexions à d’autres services sont gérées en tant que services liés.
Le pipeline de cet exemple lit les données d’un service DICOM et écrit sa sortie dans un compte de stockage. Un service lié doit donc être créé pour les deux.
Créer un service lié pour le service DICOM
Dans Azure Data Factory Studio, sélectionnez Gérer dans le menu de gauche. Sous Connexions, sélectionnez Services liés, puis Nouveau.
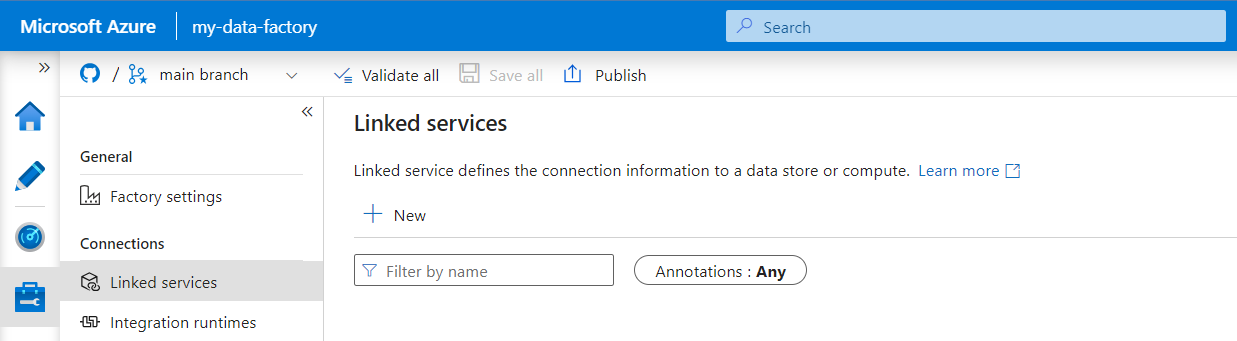
Dans le volet Nouveau service lié, recherchez REST. Sélectionnez la vignette REST, puis sélectionnez Continuer.
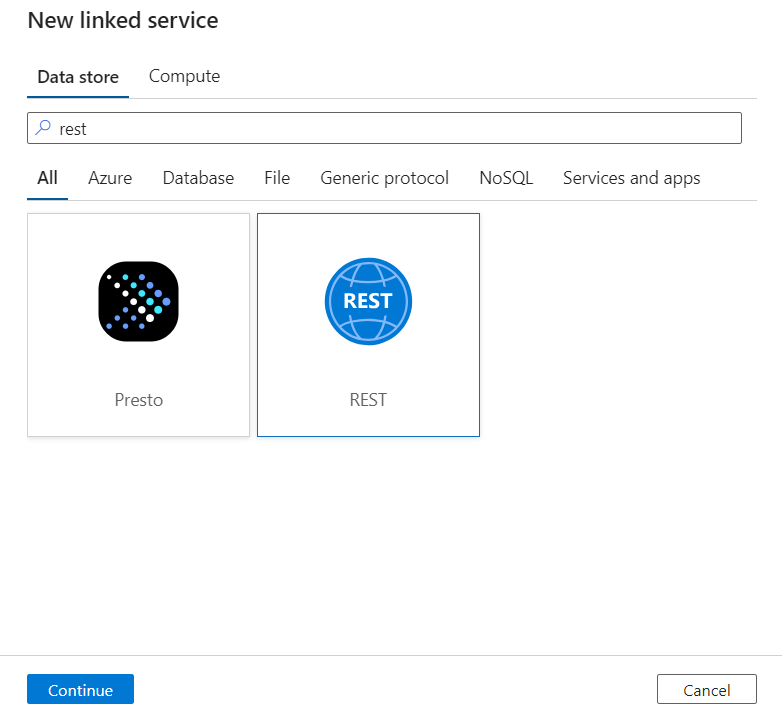
Entrez un Nom et une Description pour le service lié.
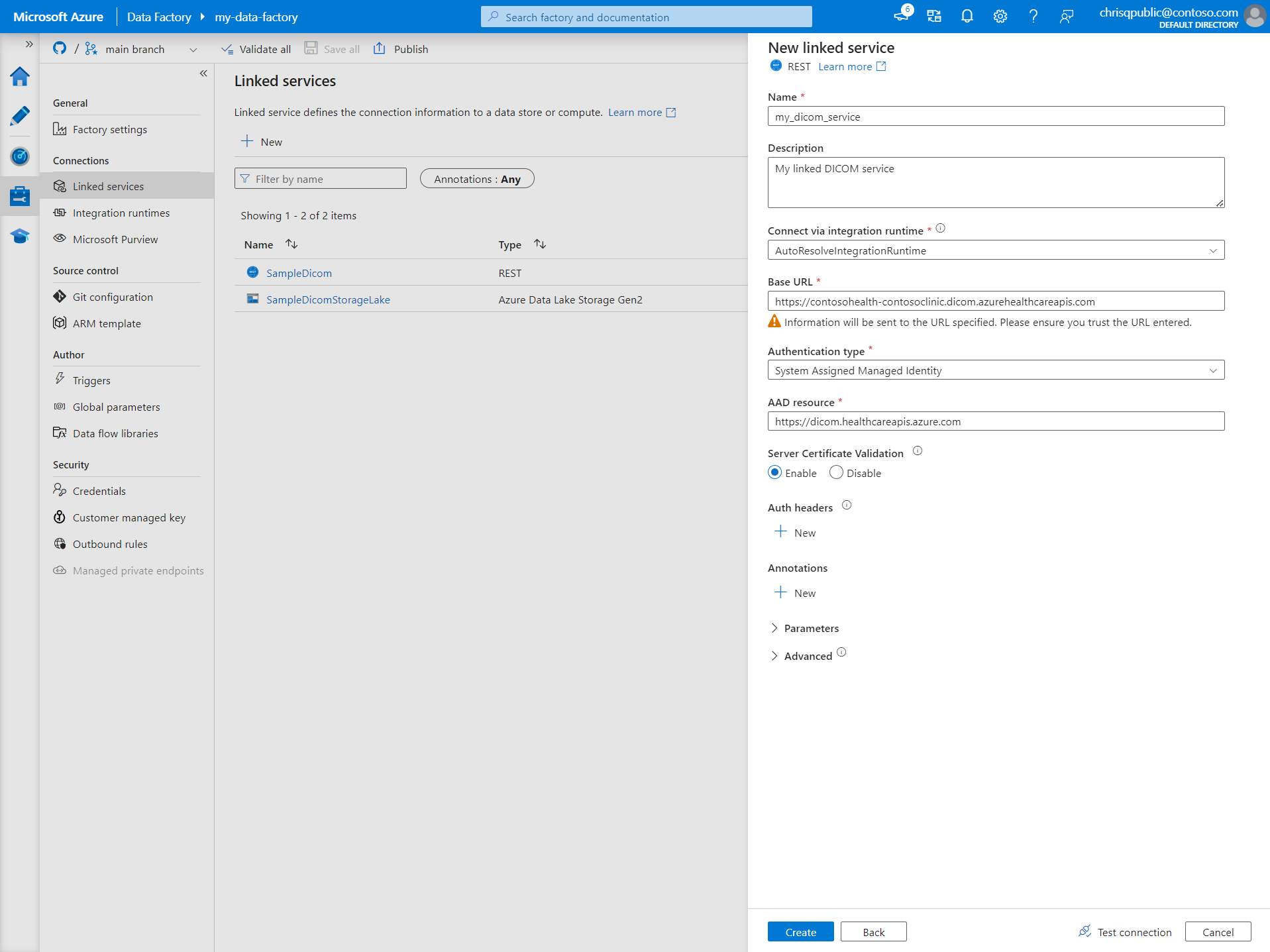
Dans le champ URL de base, entrez l’URL de service de votre service DICOM. Par exemple, un service DICOM nommé
contosoclinicdans l’espace de travailcontosohealtha l’URL de servicehttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.com.Pour Type d’authentification, sélectionnez Identité managée affectée par le système.
Pour Ressource AAD, entrez
https://dicom.healthcareapis.azure.com. Cette URL est la même pour toutes les instances de service DICOM.Une fois que vous avez renseigné les champs obligatoires, sélectionnez Tester la connexion pour vérifier que les rôles de l’identité sont correctement configurés.
Une fois le test de connexion réussi, sélectionnez Créer.



Créer un service lié pour Azure Data Lake Storage Gen2
Dans Data Factory Studio, sélectionnez Gérer dans le menu de gauche. Sous Connexions, sélectionnez Services liés, puis Nouveau.
Dans le volet Nouveau service lié, recherchez Azure Data Lake Storage Gen2. Sélectionnez la vignette Azure Data Lake Storage Gen2, puis sélectionnez Continuer.
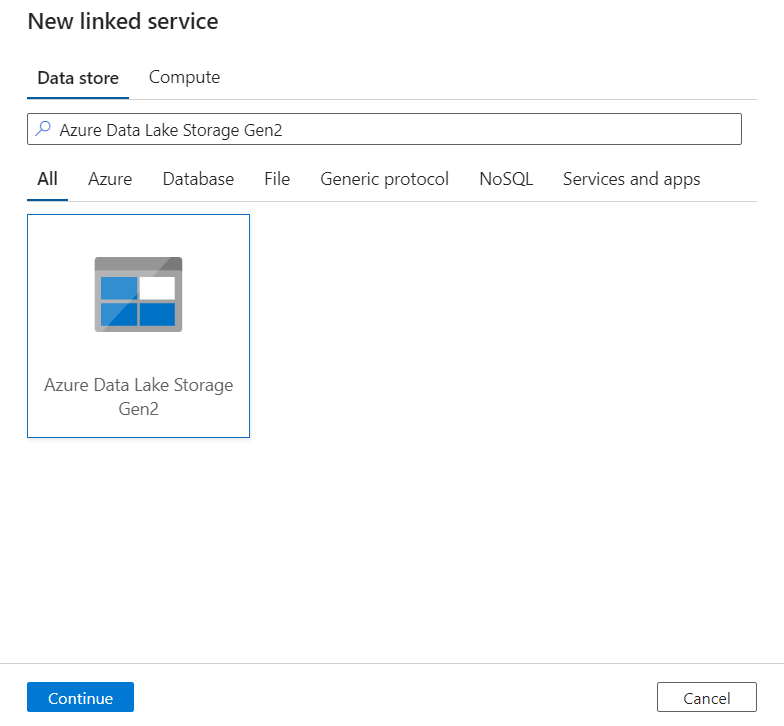
Entrez un Nom et une Description pour le service lié.
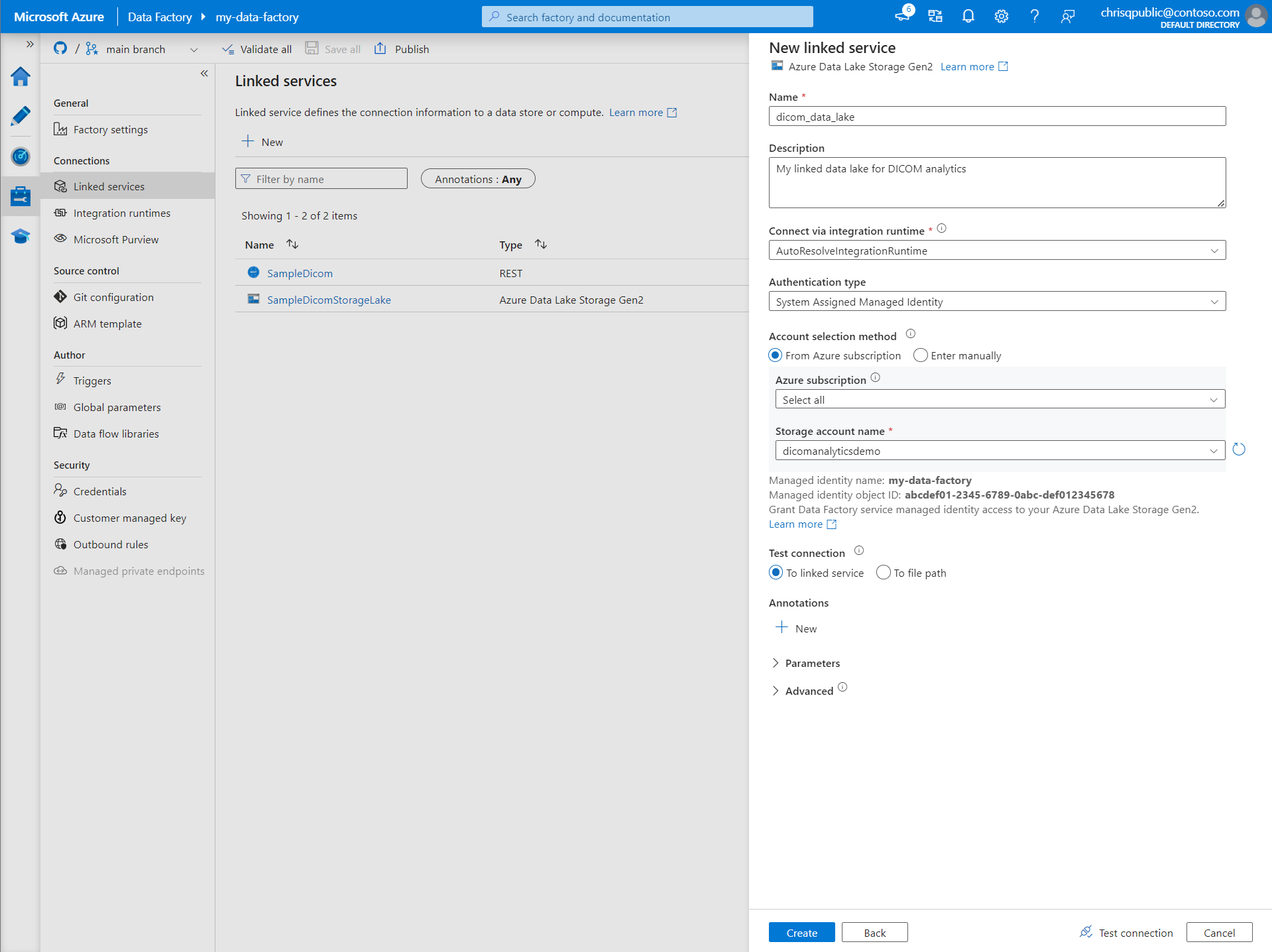
Pour Type d’authentification, sélectionnez Identité managée affectée par le système.
Entrez les détails du compte de stockage en entrant manuellement l’URL du compte de stockage. Vous pouvez également sélectionner l’abonnement Azure et le compte de stockage dans les listes déroulantes.
Une fois que vous avez renseigné les champs obligatoires, sélectionnez Tester la connexion pour vérifier que les rôles de l’identité sont correctement configurés.
Une fois le test de connexion réussi, sélectionnez Créer.


Créer un pipeline pour les données DICOM
Les pipelines Data Factory sont une collection d’activités qui effectuent une tâche, par exemple copier des métadonnées DICOM dans des tables Delta. Cette section détaille la création d’un pipeline qui synchronise régulièrement les données DICOM avec les tables Delta à mesure que les données sont ajoutées, mises à jour et supprimées d’un service DICOM.
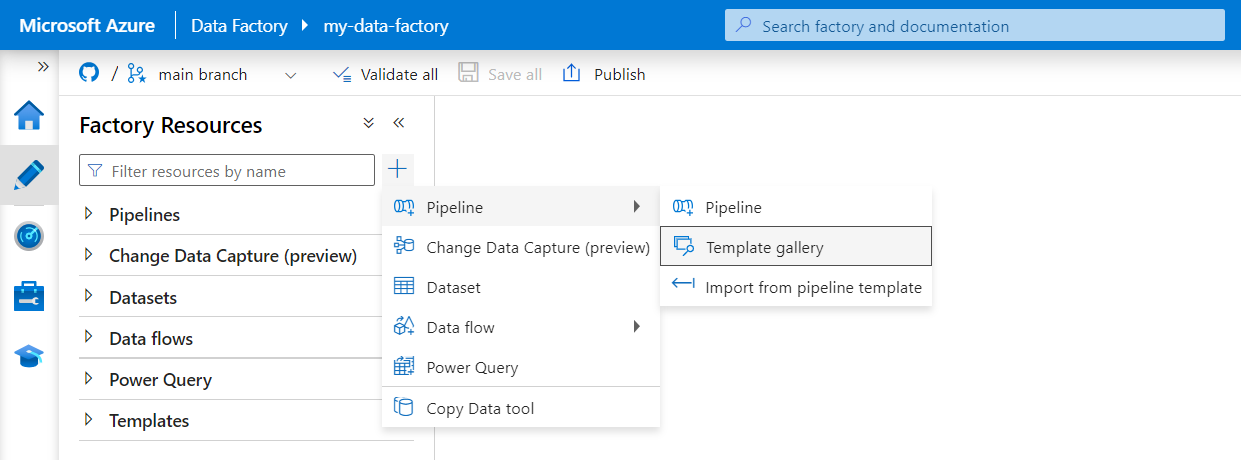
Sélectionnez Créer dans le menu de gauche. Dans le volet Ressources Factory, sélectionnez le signe plus (+) pour ajouter une nouvelle ressource. Sélectionnez Pipeline, puis sélectionnez Galerie de modèles dans le menu.
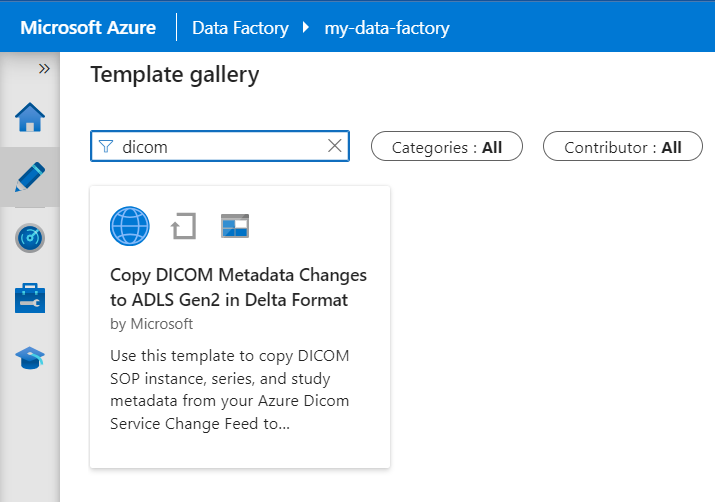
Dans la Galerie de modèles, recherchez DICOM. Sélectionnez la vignette Copier les changements apportés aux métadonnées DICOM dans ADLS Gen2 au format Delta, puis sélectionnez Continuer.
Dans la section Entrées, sélectionnez les services liés créés pour le service DICOM et le compte Data Lake Storage Gen2.
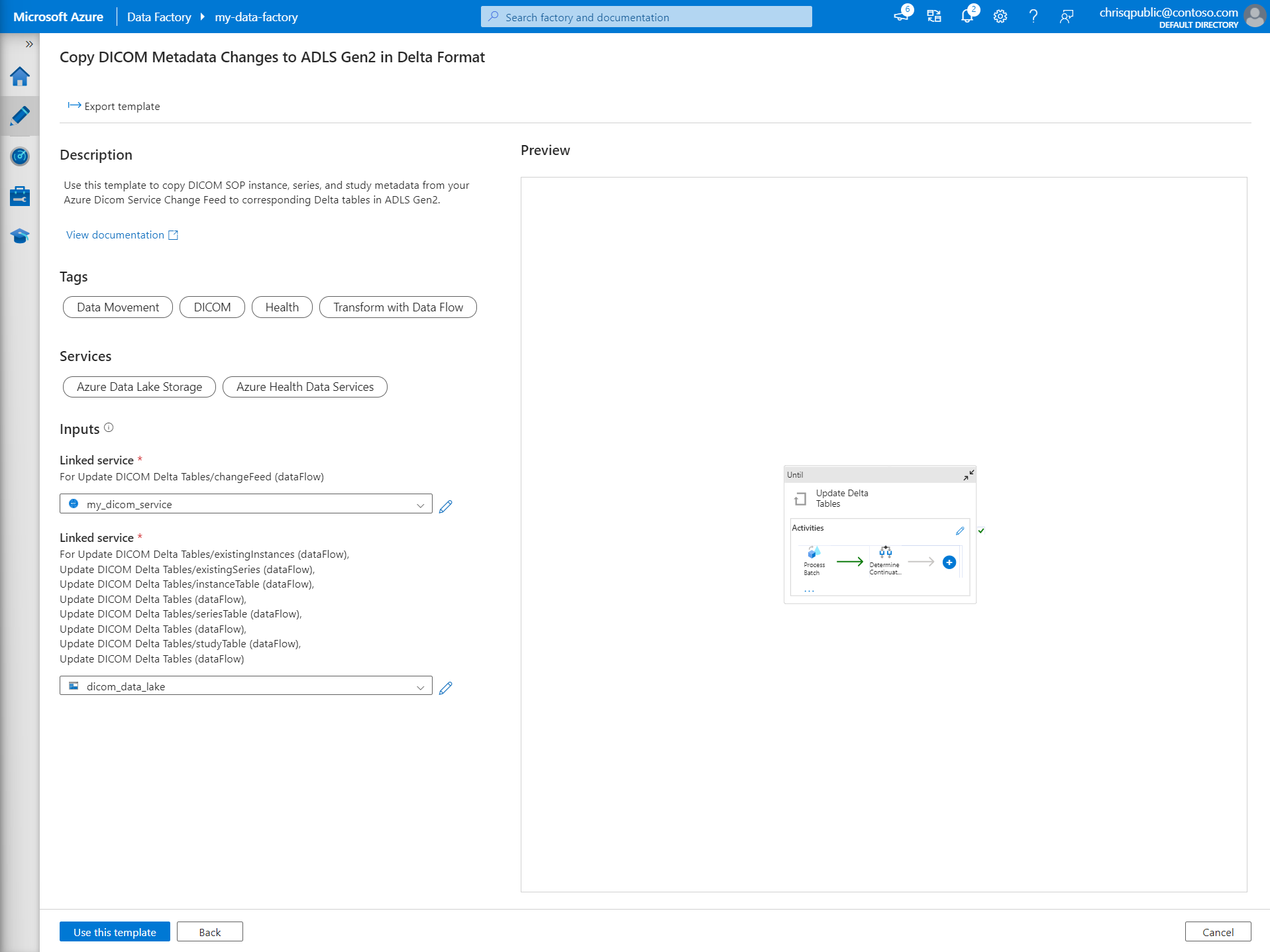
Sélectionnez Utiliser ce modèle pour créer le pipeline.



Créer un pipeline pour les données DICOM
Si vous avez créé le service DICOM avec Azure Data Lake Storage, vous devez utiliser un modèle personnalisé pour inclure un nouveau paramètre fileName dans le pipeline de métadonnées. Au lieu d'utiliser le modèle de la galerie de modèles, suivez les étapes suivantes pour configurer le pipeline.
Téléchargez le modèle à partir de GitHub. Le fichier de modèle est un dossier compressé (zippé). Vous n'avez pas besoin d'extraire les fichiers car ils sont déjà téléchargés sous forme compressée.
Dans Azure Data Factory, sélectionnez Auteur dans le menu de gauche. Sur le volet Ressources Factory, sélectionnez le signe plus (+) pour ajouter une nouvelle ressource. Sélectionnez Pipeline puis sélectionnez Importer à partir du modèle de pipeline.
Dans la fenêtre Ouvrir, sélectionnez le modèle que vous avez téléchargé. Sélectionnez Ouvrir.
Dans la section Entrées, sélectionnez les services liés créés pour le service DICOM et le compte Azure Data Lake Storage Gen2.
Sélectionnez Utiliser ce modèle pour créer le pipeline.
Planifier un pipeline
Les pipelines sont planifiés par des déclencheurs. Il existe différents types de déclencheurs. Les déclencheurs de planification permettent aux pipelines d’être déclenchés selon une planification d’horloge murale, ce qui signifie qu’ils s’exécutent à des moments spécifiques de la journée, tels que toutes les heures ou tous les jours à minuit. Les déclencheurs manuels déclenchent des pipelines à la demande, ce qui signifie qu’ils s’exécutent chaque fois que vous le souhaitez.
Dans cet exemple, un déclencheur de fenêtre bascule est utilisé pour exécuter le pipeline périodiquement en fonction d’un point de départ et d’un intervalle de temps régulier. Pour plus d’informations sur les déclencheurs, consultez Exécution de pipeline et déclencheurs dans Azure Data Factory ou Azure Synapse Analytics.
Créer un déclencheur de fenêtre bascule
Sélectionnez Créer dans le menu de gauche. Sélectionnez le pipeline du service DICOM, sélectionnez Ajouter un déclencheur, puis Nouveau/Modifier dans la barre de menus.
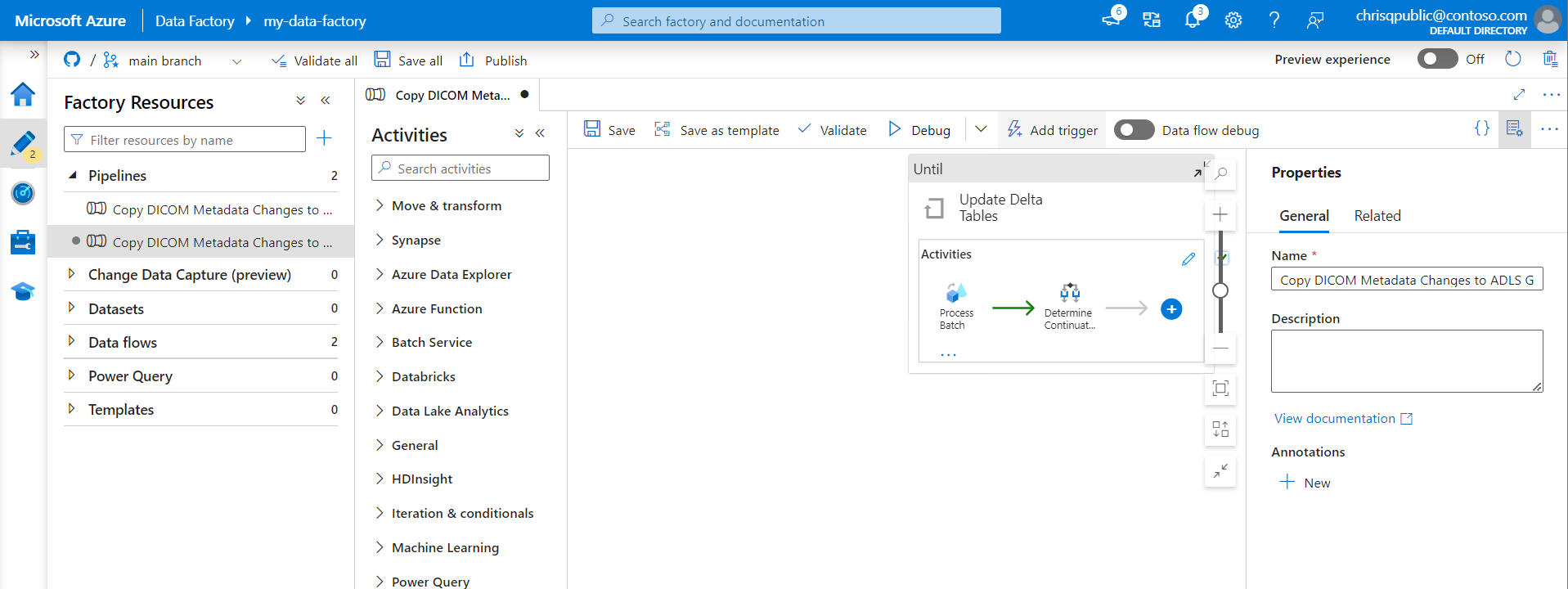
Dans le volet Ajouter des déclencheurs, sélectionnez la liste déroulante Choisir un déclencheur, puis sélectionnez Nouveau.
Entrez un Nom et une Description pour le déclencheur.
Sélectionnez Fenêtre bascule en tant que Type.
Pour configurer un pipeline qui s’exécute toutes les heures, affectez à la Périodicité la valeur 1 heure.
Développez la section Avancé, puis entrez un Délai de 15 minutes. Ce paramètre permet aux opérations en attente à la fin d’une heure de s’effectuer avant le traitement.
Affectez à Concurrence max. la valeur 1 pour garantir la cohérence entre les tables.
Sélectionnez OK pour continuer à configurer les paramètres d’exécution du déclencheur.


Configurer les paramètres d’exécution du déclencheur
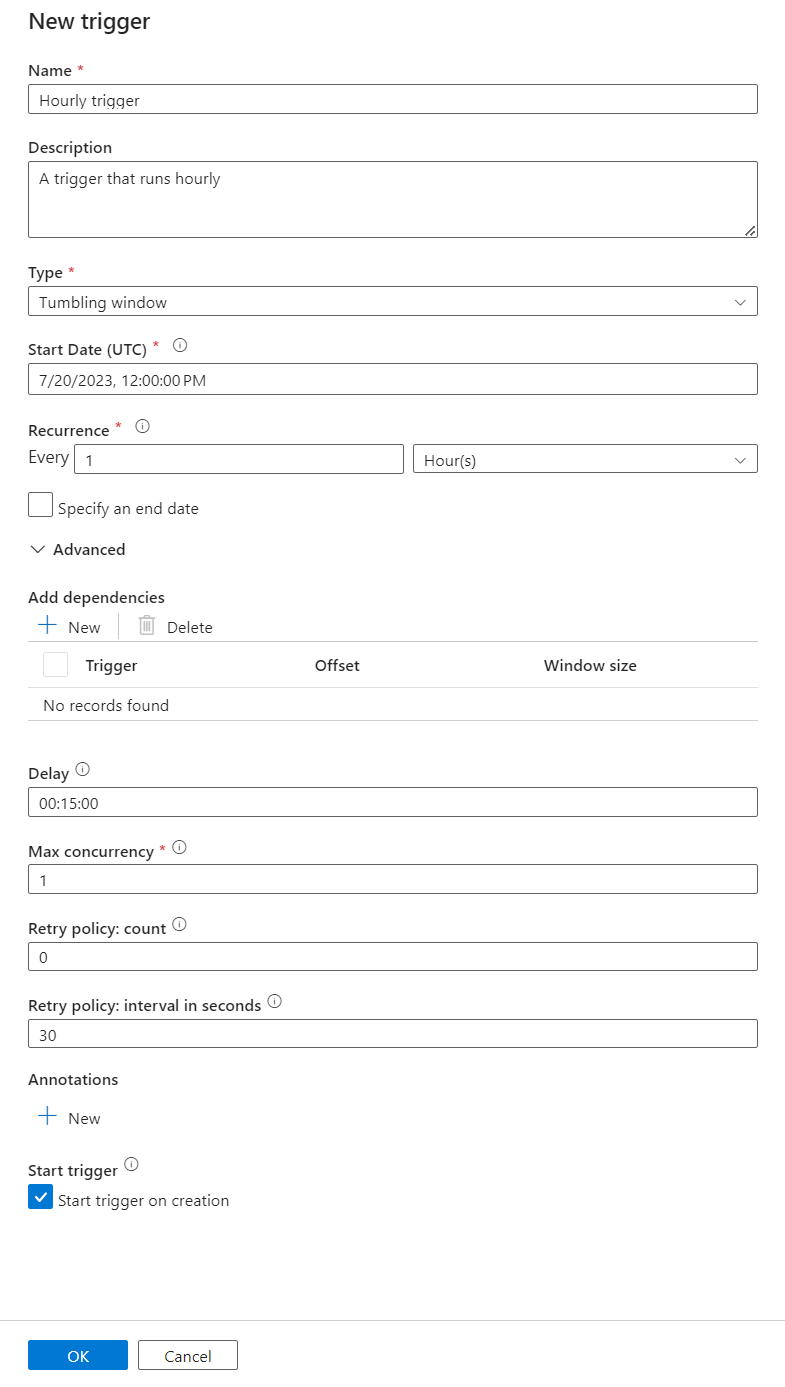
Les déclencheurs définissent le moment où un pipeline doit être exécuté. Ils incluent également des paramètres passés à l’exécution du pipeline. Le modèle Copier les changements apportés aux métadonnées DICOM au format Delta définit quelques paramètres décrits dans le tableau suivant. Si aucune valeur n’est fournie durant la configuration, la valeur par défaut listée est utilisée pour chaque paramètre.
| Nom du paramètre | Description | Valeur par défaut |
|---|---|---|
| BatchSize | Nombre maximal de changements à récupérer à la fois à partir du flux de modification (200 maximum) | 200 |
| ApiVersion | Version d’API pour le service Azure DICOM (minimum 2) | 2 |
| StartTime | Heure de début incluse pour les changements DICOM | 0001-01-01T00:00:00Z |
| EndTime | Heure de fin exclue pour les changements DICOM | 9999-12-31T23:59:59Z |
| ContainerName | Nom du conteneur pour les tables Delta résultantes | dicom |
| InstanceTablePath | Chemin qui contient la table Delta pour les instances SOP DICOM au sein du conteneur | instance |
| SeriesTablePath | Chemin qui contient la table Delta pour la série DICOM au sein du conteneur | series |
| StudyTablePath | Chemin qui contient la table Delta pour les études DICOM au sein du conteneur | study |
| RetentionHours | Conservation maximale en heures des données dans les tables Delta | 720 |
Dans le volet Paramètres d’exécution du déclencheur, entrez la valeur ContainerName qui correspond au nom du conteneur de stockage créé dans les prérequis.
Pour StartTime, utilisez la variable système
@formatDateTime(trigger().outputs.windowStartTime).Pour EndTime, utilisez la variable système
@formatDateTime(trigger().outputs.windowEndTime).Remarque
Seuls les déclencheurs de fenêtre bascule prennent en charge les variables système :
@trigger().outputs.windowStartTimeet@trigger().outputs.windowEndTime
Les déclencheurs de planification utilisent des variables système différentes :
@trigger().scheduledTimeet@trigger().startTime
Découvrez plus en détail les types de déclencheurs.
Sélectionnez Enregistrer pour créer le déclencheur. Sélectionnez Publier pour permettre au déclencheur de commencer à s’exécuter selon la planification définie.


Une fois le déclencheur publié, vous pouvez le déclencher manuellement à l’aide de l’option Déclencher maintenant. Si l’heure de début a été définie pour une valeur dans le passé, le pipeline démarre immédiatement.
Superviser les exécutions de pipelines
Vous pouvez effectuer le monitoring des exécutions de déclencheur et des exécutions de pipeline associées sous l’onglet Monitoring. Ici, vous pouvez voir le moment où chaque pipeline s’est exécuté ainsi que sa durée d’exécution. Le cas échéant, vous pouvez également déboguer les problèmes qui se produisent.

Microsoft Fabric
Fabric est une solution d’analytique tout-en-un qui repose sur Microsoft OneLake. Avec l’utilisation d’un lakehouse Fabric, vous pouvez gérer, structurer et analyser les données dans OneLake à un seul emplacement. Toutes les données en dehors de OneLake, écrites dans Data Lake Storage Gen2, peuvent être connectées à OneLake sous forme de raccourcis pour tirer parti de la suite d’outils de Fabric.
Créer des raccourcis vers les tables de métadonnées
Accédez au lakehouse créé dans les prérequis. Dans la vue Explorateur, sélectionnez le menu correspondant à des points de suspension (...) en regard du dossier Tables.
Sélectionnez Nouveau raccourci pour créer un raccourci vers le compte de stockage qui contient les données d’analytique DICOM.
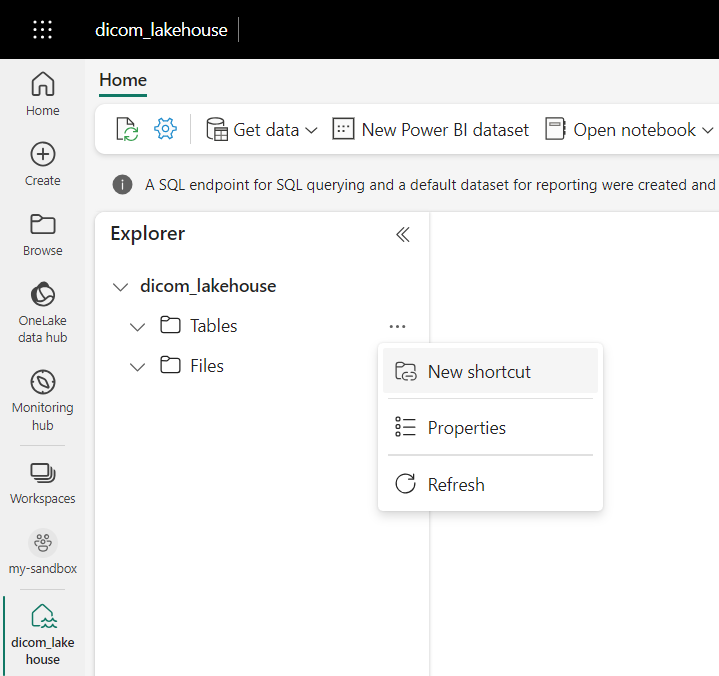
Sélectionnez Azure Data Lake Storage Gen2 en tant que source du raccourci.
Sous Paramètres de connexion, entrez l’URL que vous avez utilisée dans la section Services liés.
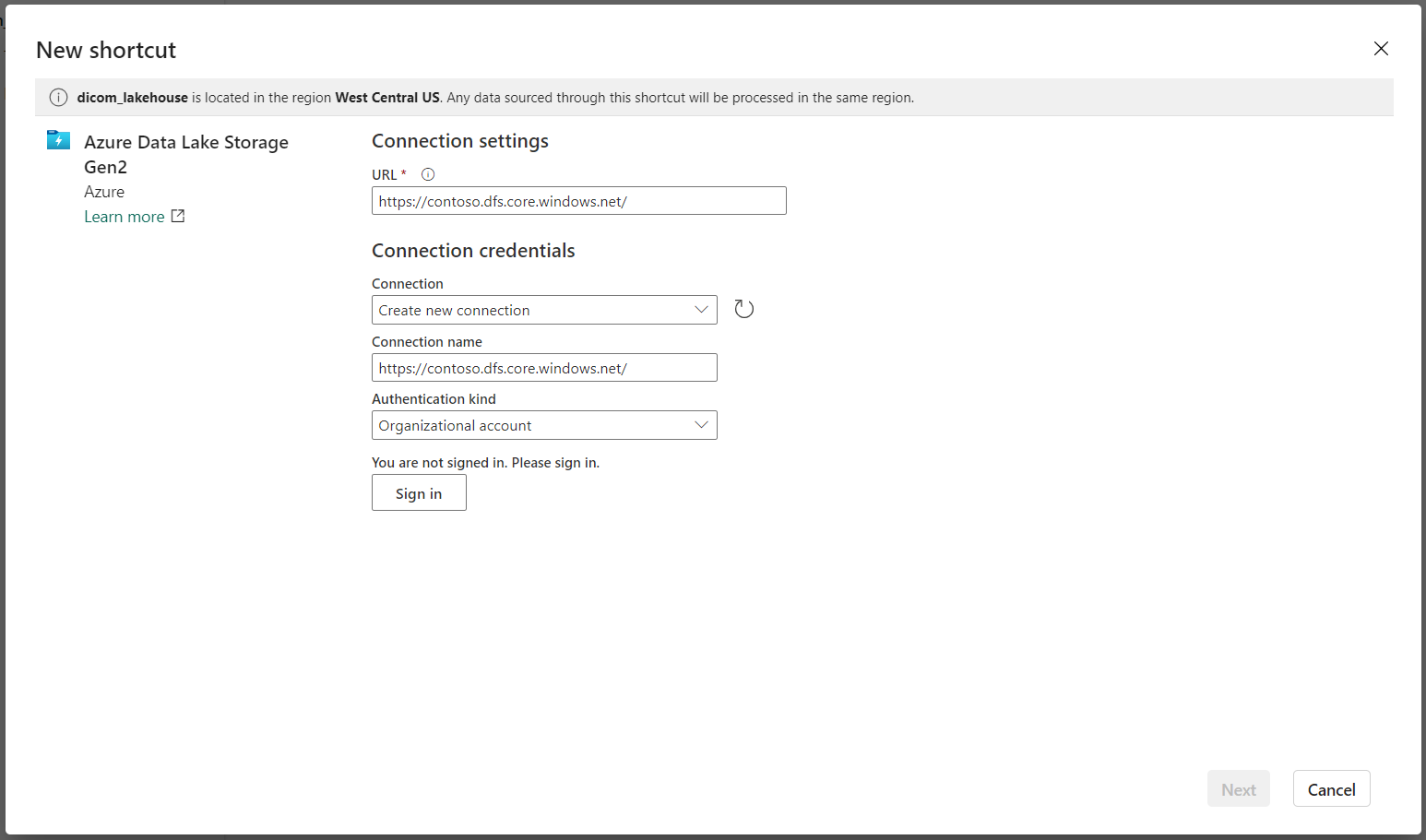
Sélectionnez une connexion existante, ou créez une connexion en sélectionnant le Type d’authentification à utiliser.
Remarque
Il existe quelques options pour l’authentification entre Data Lake Storage Gen2 et Fabric. Vous pouvez utiliser un compte d’organisation ou un principal de service. Nous vous déconseillons d’utiliser des clés de compte ou des jetons de signature d’accès partagé.
Cliquez sur Suivant.
Entrez un Nom de raccourci qui représente les données créées par le pipeline Data Factory. Par exemple, pour la table Delta
instance, le nom du raccourci est probablement instance.Entrez le Sous-chemin qui correspond au paramètre
ContainerNamede la configuration des paramètres d’exécution ainsi que le nom de la table pour le raccourci. Par exemple, utilisez/dicom/instancepour la table Delta avec le chemininstancedans le conteneurdicom.Sélectionnez Créer pour créer le raccourci.
Répétez les étapes 2 à 9 pour ajouter les raccourcis restants vers les autres tables Delta du compte de stockage (par exemple
seriesetstudy).



Une fois que vous avez créé les raccourcis, développez une table pour afficher les noms et les types des colonnes.

Créer des raccourcis vers des fichiers
Si vous utilisez un service DICOM avec Data Lake Storage, vous pouvez également créer un raccourci vers les données de fichier DICOM stockées dans le lac de données.
Accédez au lakehouse créé dans les prérequis. Dans la vue Explorateur, sélectionnez le menu correspondant à des points de suspension (...) en regard du dossier Fichiers.
Sélectionnez Nouveau raccourci pour créer un raccourci vers le compte de stockage qui contient les données DICOM.
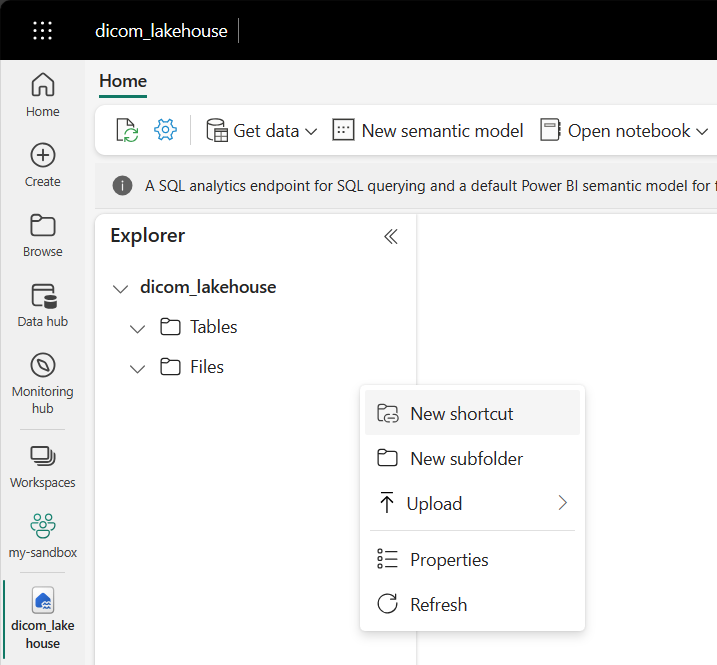
Sélectionnez Azure Data Lake Storage Gen2 en tant que source du raccourci.
Sous Paramètres de connexion, entrez l’URL que vous avez utilisée dans la section Services liés.
Sélectionnez une connexion existante, ou créez une connexion en sélectionnant le Type d’authentification à utiliser.
Cliquez sur Suivant.
Entrez un Nom de raccourci qui décrit les données DICOM. Par exemple, contoso-dicom-files.
Entrez le sous-chemin qui correspond au nom du conteneur de stockage et du dossier utilisé par le service DICOM. Par exemple, si vous souhaitez établir un lien vers le dossier racine, le sous-chemin d’accès est /dicom/AHDS. Notez que le dossier racine est toujours
AHDS, mais vous pouvez éventuellement créer un lien vers un dossier enfant pour un espace de travail ou une instance de service DICOM spécifique.Sélectionnez Créer pour créer le raccourci.


Exécuter des blocs-notes
Une fois les tables créées dans le lakehouse, vous pouvez les interroger à partir de notebooks Fabric. Vous pouvez créer des notebooks directement à partir du lakehouse en sélectionnant Ouvrir un notebook dans la barre de menus.
Dans la page du notebook, le contenu du lakehouse est toujours visible sur le côté gauche, notamment les tables récemment ajoutées. En haut de la page, sélectionnez la langue du notebook. La langue peut également être configurée pour des cellules individuelles. L’exemple suivant utilise Spark SQL.
Interroger des tables à l’aide de Spark SQL
Dans l’éditeur de cellule, entrez une requête Spark SQL, par exemple une instruction SELECT.
SELECT * from instance
Cette requête sélectionne tout le contenu de la table instance. Quand vous êtes prêt, sélectionnez Exécuter la cellule pour exécuter la requête.

Après quelques secondes, les résultats de la requête s’affichent dans un tableau sous la cellule, comme dans l’exemple présenté ici. La durée peut être plus longue si cette requête Spark est la première de la session, car le contexte Spark doit être initialisé.

Accéder aux données des fichiers DICOM dans les carnets de notes
Si vous avez utilisé le modèle pour créer le pipeline et créé un raccourci vers les données de fichier DICOM, vous pouvez utiliser la colonne filePath de la table instance pour mettre en corrélation les métadonnées d’instance aux données de fichier.
SELECT sopInstanceUid, filePath from instance

Résumé
Dans cet article, vous avez appris à effectuer les opérations suivantes :
- Utiliser des modèles Data Factory pour créer un pipeline entre le service DICOM et un compte Data Lake Storage Gen2.
- Configurer un déclencheur pour extraire des métadonnées DICOM selon une planification horaire.
- Utiliser des raccourcis pour connecter les données DICOM d’un compte de stockage à un lakehouse Fabric.
- Utiliser des notebooks pour interroger les données DICOM dans le lakehouse.
Étapes suivantes
Remarque
DICOM® est une marque déposée de la National Electrical Manufacturers Association pour ses publications de standards relatifs aux communications numériques des informations médicales.