Machine Learning automatisé (AutoML) ?
S’APPLIQUE À : Kit de développement logiciel (SDK) Python azureml v1
Kit de développement logiciel (SDK) Python azureml v1
Le Machine Learning automatisé, également appelé ML automatisé ou AutoML, est le processus d’automatisation des tâches fastidieuses et itératives de développement de modèle Machine Learning. Il permet aux chercheurs de données, analystes et développeurs de créer des modèles ML à grande échelle, efficaces et productifs, tout en maintenant la qualité du modèle. L’apprentissage automatique automatisé dans Azure Machine Learning se base sur une innovation de notre division Microsoft Research.
Le développement de modèle Machine Learning traditionnel consomme beaucoup de ressources, nécessitant une connaissance significative du domaine et du temps pour produire et comparer des dizaines de modèles. Le Machine Learning automatisé permet de réduire le temps nécessaire pour obtenir des modèles ML prêts pour la production avec une facilité et une efficacité extraordinaires.
Façons d’utiliser AutoML dans Azure Machine Learning
Azure Machine Learning offre les deux expériences suivantes pour utiliser le Machine Learning automatisé. Consultez les sections suivantes pour comprendre la disponibilité des fonctionnalités dans chaque expérience (v1).
Pour les clients expérimentés en codage, Kit SDK Python d’Azure Machine Learning. Lancez-vous avec Tutoriel : utiliser le Machine Learning automatisé pour prédire le prix des tarifs de taxi (v1).
Pour les clients avec une expérience limitée ou inexistante en codage, Azure Machine Learning studio sur https://ml.azure.com. Démarrage avec ces tutoriels :
Paramètres de l’expérience
Les paramètres suivants vous permettent de configurer votre expérience de machine learning automatisé.
| SDK Python | L’expérience web Studio | |
|---|---|---|
| Division des données en jeux d’entraînement/de validation | ✓ | ✓ |
| Prise en charge des tâches de Machine Learning : classification, régression et prévision | ✓ | ✓ |
| Prise en charge des tâches de vision par ordinateur : classification d’images, détection d’objet et segmentation d’instance | ✓ | |
| Optimisation basée sur une métrique principale | ✓ | ✓ |
| Prend en charge le calcul Azure Machine Learning comme cible de calcul | ✓ | ✓ |
| Configuration de l’horizon de prévision, des décalages de cibles et de la fenêtre dynamique | ✓ | ✓ |
| Définition des critères de sortie | ✓ | ✓ |
| Définition des itérations simultanées | ✓ | ✓ |
| Suppression de colonnes | ✓ | ✓ |
| Blocage des algorithmes | ✓ | ✓ |
| Validation croisée | ✓ | ✓ |
| Prise en charge de la formation sur les clusters Azure Databricks | ✓ | |
| Affichage des noms de caractéristiques traités | ✓ | |
| Résumé de la caractérisation | ✓ | |
| Caractérisation des congés | ✓ | |
| Niveaux de verbosité des fichiers journaux | ✓ |
Paramètres du modèle
Ces paramètres peuvent être appliqués au meilleur modèle à la suite de votre expérience de machine learning automatisé.
| SDK Python | L’expérience web Studio | |
|---|---|---|
| Inscription, déploiement et description du meilleur modèle | ✓ | ✓ |
| Activation des modèles de l’ensemble de vote et de l’ensemble d’empilement | ✓ | ✓ |
| Affichage du meilleur modèle selon une métrique non principale | ✓ | |
| Activation/désactivation de la compatibilité du modèle ONNX | ✓ | |
| Tester le modèle | ✓ | ✓ (préversion) |
Paramètres de contrôle des tâches
Ces paramètres vous permettent d’examiner et de contrôler les tâches de votre expérience et ses tâches enfants.
| SDK Python | L’expérience web Studio | |
|---|---|---|
| Tableau récapitulatif des tâches | ✓ | ✓ |
| Annuler les tâches et les tâches enfants | ✓ | ✓ |
| Obtenir des garde-fous | ✓ | ✓ |
| Mettre en pause et reprendre les travaux | ✓ |
Quand utiliser AutoML : classification, régression, prévision et vision par ordinateur et NLP
Appliquez le Machine Learning automatisé lorsque vous souhaitez qu’Azure Machine Learning effectue l’apprentissage d’un modèle et le règle à votre place à l’aide de la métrique cible que vous spécifiez. Le ML automatisé démocratise le processus de développement de modèle Machine Learning et permet à ses utilisateurs, quel que soit leur expertise en matière de science des données, d’identifier un pipeline de Machine Learning de bout en bout pour tout problème.
Les professionnels et développeurs du Machine Learning de différents secteurs peuvent utiliser le Machine Learning automatisé pour ce qui suit :
- Implémenter des solutions ML sans disposer d’une connaissance approfondie de la programmation.
- Économiser du temps et des ressources.
- Tirer parti des bonnes pratiques de science des données.
- Fournir une résolution de problème agile.
classification ;
La classification est une tâche Machine Learning courante. Il s’agit d’un type d’apprentissage supervisé dans lequel des modèles apprennent à utiliser des données d’apprentissage et appliquent ces apprentissages à de nouvelles données. Azure Machine Learning offre des caractérisations spécifiquement pour ces tâches, telles que des caractériseurs de réseau neuronal profond pour la classification. En savoir plus sur les optons de caractérisation (v1).
L’objectif principal des modèles de classification est de prédire les catégories dans lesquelles les nouvelles données seront classées, sur la base des apprentissages de leurs données d’apprentissage. Les exemples de classification courants incluent la détection des fraudes, la reconnaissance de l’écriture manuscrite et la détection d’objets. Pour plus d’informations et voir un exemple, consultez Créer un modèle de classification avec ML automatisé (v1).
Pour obtenir des exemples de classification et de Machine Learning automatisé, consultez les notebooks Python suivants : Détection des fraudes, Prédictions marketing et Classification des données de groupe de discussion
régression ;
À l’instar de la classification, les tâches de régression sont également une tâche d’apprentissage supervisé courante.
À la différence d’une classification dans laquelle les valeurs de sortie prédites sont catégoriques, les modèles de régression prédisent des valeurs de sortie numériques en fonction de prédictions indépendantes. Dans une régression, l’objectif est d’aider à établir la relation entre ces variables de prédiction indépendantes en estimant l’impact d’une variable sur les autres. Par exemple, le coût de l’automobile basé sur des caractéristiques telles que la consommation de carburant, la cote de sécurité, etc. Apprenez-en davantage et découvrez un exemple de Régression avec Machine Learning automatisé (v1).
Pour obtenir des exemples de régression et de Machine Learning automatisé pour les prédictions, consultez les notebooks Python suivants : Prédiction des performances du processeur
Prévision de série chronologique
L’établissement de prévisions fait partie intégrante de toute entreprise, qu’il s’agisse du chiffre d’affaires, de l’inventaire, des ventes ou de la demande des clients. Vous pouvez utiliser le Machine Learning automatisé pour combiner des techniques et approches, et obtenir une prévision de série chronologique recommandée de haute qualité. Pour en savoir plus, consultez Machine Learning automatisé pour la prévision de séries chronologiques (v1).
Une expérience de série chronologique automatisée est traitée comme un problème de régression multivariable. Les valeurs de série chronologique passées « pivotent » afin de devenir des dimensions supplémentaires pour le régresseur, avec d’autres prédicteurs. Contrairement aux méthodes de séries chronologiques classique, cette méthode présente l’avantage d’incorporer naturellement plusieurs variables contextuelles et leurs relations entre elles pendant l’apprentissage. Le Machine Learning automatisé effectue l’apprentissage d’un modèle unique, mais souvent ramifié en interne, pour tous les éléments du jeu de données et les horizons de prédiction. Plus de données sont ainsi disponibles pour estimer les paramètres du modèle et la généralisation en séries invisibles devient possible.
La configuration de prévisions avancée inclut les éléments suivants :
- détection et personnalisation de congé
- série chronologique et apprenants DNN (Auto-ARIMA, Prophet, ForecastTCN)
- prise en charge de plusieurs modèles via le regroupement
- validation croisée d’origine
- Décalages configurables
- caractéristiques des agrégations des fenêtres dynamiques
Consultez des exemples de régression et de Machine Learning automatisés pour les prédictions dans ces notebooks Python : Prévisions des ventes, Prévision de la demande et Prévision des utilisateurs actifs quotidiens de GitHub.
Vision par ordinateur
La prise en charge des tâches de vision par ordinateur vous permet de générer facilement des modèles ayant fait l’objet d’un apprentissage sur des données d’image pour des scénarios comme la classification d’images et la détection d’objets.
Avec cette fonctionnalité, vous pouvez :
- Réaliser une intégration fluide à la fonctionnalité d’étiquetage des données Azure Machine Learning
- Utiliser des données étiquetées pour générer des modèles d’image
- Optimiser les performances du modèle en spécifiant l’algorithme du modèle et en réglant les hyperparamètres
- Télécharger ou déployer le modèle obtenu en tant que service web dans Azure Machine Learning
- Rendre les modèles opérationnels à grande échelle, en tirant parti des fonctionnalités d’Azure Machine Learning MLOps et Pipelines ML (v1).
La création de modèles Auto Machine Learning pour les tâches de vision est prise en charge via le kit SDK Azure Machine Learning Python. Vous pouvez accéder aux tâches, aux modèles et aux sorties de l’expérimentation obtenus à partir de l’interface utilisateur Azure Machine Learning Studio.
Découvrez comment configurer l’apprentissage AutoML pour les modèles de vision par ordinateur.

La fonctionnalité de ML automatisé pour les images prend en charge les tâches de vision par ordinateur suivantes :
| Tâche | Description |
|---|---|
| Classification d’images multiclasse | Tâches où une image est classifiée avec une seule étiquette d’un ensemble de classes. Chaque image est classifiée par exemple en tant qu’image de « chat », de « chien » ou de « canard » |
| Classification d’images multiétiquette | Tâches où une image peut avoir une ou plusieurs étiquettes d’un ensemble d’étiquettes. Une image peut être étiquetée par exemple « chat » et « chien » |
| Détection d’objets | Tâches permettant d’identifier des objets dans une image et de localiser chaque objet avec un rectangle englobant. On peut par exemple rechercher tous les chiens et tous les chats dans une image et les entourer d’un cadre englobant. |
| Segmentation d’instance | Tâches permettant d’identifier des objets dans une image au niveau des pixels, en dessinant un polygone autour de chaque objet dans l’image. |
Traitement du langage naturel : NLP
La prise en charge des tâches de traitement en langage naturel (NLP) dans le ML automatisé vous permet de générer facilement des modèles formés sur des données texte pour la classification de texte et les scénarios de reconnaissance d’entités nommées. La création de modèles de NLP formés par ML automatisé est prise en charge via le kit de développement logiciel (SDK) Python Azure Machine Learning. Vous pouvez accéder aux tâches, aux modèles et aux sorties de l’expérimentation obtenus à partir de l’interface utilisateur Azure Machine Learning Studio.
La fonction NLP prend en charge les éléments suivants :
- Formation NLP avec réseau neuronal profond de bout en bout avec les derniers modèles BERT pré-formés
- Intégration transparente avec l’étiquetage des données Azure Machine Learning
- Utiliser des données étiquetées pour générer des modèles NLP
- Prise en charge multilingue avec 104 langues
- Formation dispensée à l’aide de Horovod
Découvrez comment configurer la formation par ML automatisé pour les modèles de NLP (v1).
Fonctionnement du Machine Learning automatisé
Pendant l’entraînement, Azure Machine Learning crée un certain nombre de pipelines en parallèle qui testent différents algorithmes et paramètres pour vous. Le service effectue des itérations dans les algorithmes de Machine Learning associés aux sélections de fonctionnalités, où chaque itération produit un modèle avec un score d’apprentissage. Plus le score est élevé, plus le modèle est considéré comme « adapté » à vos données. Il s’arrête une fois qu’il réunit les critères de sortie définis dans l’expérience.
Azure Machine Learning vous permet de concevoir et d’exécuter vos expériences d’entraînement de Machine Learning automatisé en effectuant les étapes suivantes :
Identifier le problème de Machine Learning à résoudre : classification, prévision, régression ou vision par ordinateur.
Indiquez si vous souhaitez utiliser le SDK Python ou l’expérience web Studio : apprenez-en davantage sur la parité entre le SDK Python et l’expérience web Studio.
- Si vous disposez d’une expérience limitée ou inexistante en programmation, essayez l’expérience web Azure Machine Learning Studio sur https://ml.azure.com.
- Pour les développeurs Python, consultez le SDK Python Azure Machine Learning (v1)
Spécifier la source et le format des données d’apprentissage étiquetées : tableaux NumPy ou cadre de données Pandas.
Configurer la cible de calcul pour l’apprentissage du modèle : ordinateur local, calculs Azure Machine Learning, machines virtuelles à distance ou Azure Databricks avec le Kit de développement logiciel (SDK) (v1).
Configurer les paramètres de Machine Learning automatisé qui déterminent le nombre d’itérations sur les différents modèles, les réglages d’hyperparamètre, le prétraitement et la personnalisation avancés, ainsi que les métriques à examiner lors du choix du meilleur modèle.
Soumettre la tâche d’apprentissage.
Passer en revue les résultats
Le diagramme suivant illustre ce processus.
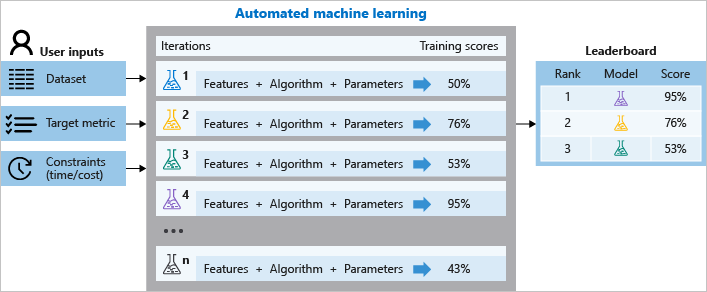
Vous pouvez également inspecter les informations des tâches journalisées qui contiennent les métriques collectées pendant la tâche. Le travail de formation produit un objet sérialisé Python (fichier .pkl) contenant le modèle et le prétraitement des données.
Bien que la création de modèles soit automatisée, vous pouvez également découvrir l’importance ou la pertinence des fonctionnalités pour les modèles générés.
Conseils concernant les cibles de calcul de Machine Learning managées locales et distantes
L’interface web pour le Machine Learning automatisé utilise toujours une cible de calcul distante. Toutefois, lorsque vous utilisez le Kit de développement logiciel (SDK) Python, vous devez choisir une cible de calcul locale ou distante pour un apprentissage de Machine Learning automatisé.
- Calcul local : l’apprentissage se produit sur votre ordinateur portable ou votre machine virtuelle locaux.
- Calcul distant : l’apprentissage se produit sur des clusters de calcul Machine Learning.
Choisir une cible de calcul
Lors du choix de votre cible de calcul, considérez les facteurs suivants :
- Choisir un calcul local : si votre scénario concerne des explorations initiales ou des démonstrations utilisant des données de petite taille et des apprentissages courts (de quelques secondes à quelques minutes par tâche enfant), un apprentissage sur votre ordinateur local peut constituer un meilleur choix. Il n’y a pas de temps de configuration. Les ressources d’infrastructure (votre PC ou votre machine virtuelle) sont directement disponibles.
- Choisir un cluster de calcul de Machine Learning distant : si vous effectuez un apprentissage avec des jeux de données plus volumineux, tel un apprentissage de production créant des modèles nécessitant des apprentissages plus longs, un calcul distant offre des performances de temps de bout en bout bien meilleures, car
AutoMLparallélise les apprentissages dans les nœuds du cluster. Sur un calcul distant, le temps de démarrage de l’infrastructure interne ajoute environ 1,5 minute par tâche enfant, et des minutes supplémentaires pour l’infrastructure du cluster si les machines virtuelles ne sont pas encore opérationnelles.
Avantages et inconvénients
Tenez compte des avantages et des inconvénients suivants lorsque au moment de choisir entre le calcul local ou distant.
| Avantages (avantages) | Inconvénients (handicaps) | |
|---|---|---|
| Cible de calcul locale | ||
| Clusters de calcul ML distants |
Disponibilité des fonctionnalités
D’autres fonctionnalités sont disponibles lorsque vous utilisez le calcul distant, comme indiqué dans le tableau ci-dessous.
| Fonctionnalité | Remote | Local |
|---|---|---|
| Streaming de données (prise en charge de données volumineuses jusqu’à 100 Go) | ✓ | |
| Caractérisation de texte et apprentissage basés sur DNN-BERT | ✓ | |
| Prise en charge de GPU prêt à l’emploi (apprentissage et inférence) | ✓ | |
| Prise en charge de la classification d’image et de l’étiquetage | ✓ | |
| Modèles auto-ARIMA, Prophet et ForecastTCN pour les prévisions | ✓ | |
| Tâches/itérations multiples en parallèle | ✓ | |
| Créer des modèles avec interprétabilité dans l’interface utilisateur de l’expérience web du studio AutoML | ✓ | |
| Personnalisation de l’ingénierie des fonctionnalités dans l’interface utilisateur de l’expérience web du studio | ✓ | |
| Réglage des hyperparamètres Azure Machine Learning | ✓ | |
| Prise en charge du flux de travail du pipeline Azure Machine Learning | ✓ | |
| Continuer une tâche | ✓ | |
| Prévisions | ✓ | ✓ |
| Créer et exécuter des expériences dans des blocs-notes | ✓ | ✓ |
| Inscrire et visualiser les informations et les métriques de l’expérience dans l’interface utilisateur | ✓ | ✓ |
| Garde-fous des données | ✓ | ✓ |
Formation, validation et test des données
Avec le ML automatisé, vous fournissez les données d’apprentissage pour former des modèles de ML, et vous pouvez spécifier le type de validation de modèle à effectuer. Le ML automatisé effectue une validation de modèle dans le cadre de la formation. Autrement dit, le ML automatisé utilise des données de validation pour régler les hyperparamètres de modèle en fonction de l’algorithme appliqué afin de trouver la combinaison la plus appropriée qui correspond le mieux aux données d’apprentissage. Toutefois, les mêmes données de validation sont utilisées pour chaque itération de paramétrage, ce qui introduit le biais de l’évaluation du modèle, puisque le modèle continue à s’améliorer et à s’ajuster par rapport aux données de validation.
Pour vous aider à confirmer que ce biais n’est pas appliqué au modèle recommandé final, le ML automatisé prend en charge l’utilisation de données de test pour évaluer le modèle final que le ML automatisé recommande à la fin de votre expérience. Lorsque vous fournissez des données de test dans le cadre de votre configuration d’expérimentation AutoML, ce modèle recommandé est testé par défaut à la fin de votre expérience (préversion).
Important
Le test de vos modèles avec un jeu de données de test pour évaluer les modèles générés est une fonctionnalité en préversion. Cette capacité est une caractéristique expérimentale en préversion qui peut évoluer à tout moment.
Découvrez comment Configurer les expériences AutoML pour utiliser des données de test (préversion) avec le Kit de développement logiciel (SDK) (v1) ou avec Azure Machine Learning studio.
Vous pouvez également tester n’importe quel modèle de ML automatisé (préversion) (v1) existant, y compris les modèles de travaux enfants, en fournissant vos propres données de test ou en mettant de côté une partie de vos données d’apprentissage.
Ingénierie des caractéristiques
L’ingénierie des caractéristiques est le processus qui consiste à utiliser la connaissance du domaine des données pour créer des fonctionnalités qui aident les algorithmes de ML à améliorer leur apprentissage. Dans Azure Machine Learning, des techniques de mise à l’échelle et de normalisation sont appliquées pour faciliter l’ingénierie de caractéristiques. Collectivement, ces techniques et l’ingénierie de caractéristiques sont appelées caractérisation.
Pour les expériences de Machine Learning automatisé, la caractérisation s’applique automatiquement, mais peut également être personnalisée en fonction de vos données. Découvrez plus en détail quelle caractérisation est incluse (v1) et comment AutoML permet d’empêcher le surajustement et le déséquilibrage des données dans vos modèles.
Notes
Les étapes de caractérisation du Machine Learning automatisé (normalisation des fonctionnalités, gestion des données manquantes, conversion de texte en valeurs numériques, etc.) font partie du modèle sous-jacent. Lorsque vous utilisez le modèle pour des prédictions, les étapes de caractérisation qui sont appliquées pendant la formation sont appliquées automatiquement à vos données d’entrée.
Personnaliser la caractérisation
Des techniques de caractérisation supplémentaires, telles que l’encodage et les transformations, sont également disponibles.
Activez ce paramètre avec :
Azure Machine Learning studio : Activez Caractérisation automatique dans la section Afficher des configurations supplémentairesen suivant ces étapes (v1).
Kit de développement logiciel (SDK) Python : Spécifiez
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'dans votre objet AutoMLConfig. En savoir plus sur l’activation de la caractérisation (v1).
Modèles d’ensemble
Le Machine Learning automatisé prend en charge les modèles ensemblistes, qui sont activés par défaut. L’apprentissage ensembliste améliore les résultats de Machine Learning et les performances prédictives en combinant plusieurs modèles. Les itérations d’ensembles apparaissent comme les dernières itérations de votre tâche. Le Machine Learning automatisé utilise des méthodes ensemblistes de vote et d’empilement pour combiner les modèles :
- Vote : prédictions basées sur la moyenne pondérée des probabilités de classe prédites (pour les tâches de classification) ou des cibles de régression prédites (pour les tâches de régression).
- Empilement : l’empilement combine des modèles hétérogènes et entraîne un métamodèle basé sur la sortie de différents modèles. Actuellement, les métamodèles par défaut sont LogisticRegression pour les tâches de classification, et ElasticNet pour les tâches de régression et de prévision.
L’algorithme de sélection d’ensemble Caruana, avec initialisation des ensembles triés, est utilisé pour déterminer les modèles qui doivent être utilisés au sein de l’ensemble. Pour résumer, cet algorithme initialise l’ensemble avec un maximum de cinq modèles ayant obtenu les meilleurs scores, puis vérifie que ces scores se situent dans une marge de plus ou moins 5 % par rapport au meilleur score, afin d’éviter un ensemble de niveau médiocre. Ensuite, pour chaque itération d’ensemble, un nouveau modèle est ajouté à l’ensemble existant et le score est calculé. Si un nouveau modèle a amélioré le score existant de l’ensemble, l’ensemble est mis à jour pour inclure le nouveau modèle.
Pour savoir comment modifier les paramètres par défaut de l’ensemble au niveau du Machine Learning automatisé, consultez cette procédure (v1).
AutoML et ONNX
Avec Azure Machine Learning, vous pouvez utiliser le Machine Learning automatisé pour générer un modèle Python et le convertir au format ONNX. Une fois que les modèles sont au format ONNX, ils peuvent s’exécuter sur une multitude de plateformes et d’appareils. Apprenez-en davantage sur l’accélération des modèles ML avec ONNX.
Découvrez comment convertir au format ONNX dans cet exemple de notebook Jupyter. Découvrez quels sont les algorithmes pris en charge dans ONNX (v1).
Le runtime ONNX prenant également en charge C#, vous pouvez utiliser le modèle généré automatiquement dans vos applications C# sans avoir besoin de recodage ou des latences réseau introduites par les points de terminaison REST. En savoir plus sur l’utilisation d’un modèle ONNX AutoML dans une application .NET avec ML.NET et sur l’inférence de modèles ONNX avec l’API C# du runtime ONNX.
Étapes suivantes
Plusieurs ressources sont disponibles pour vous aider à utiliser AutoML.
Tutoriels et guides pratiques
Les tutoriels sont des exemples illustrant de bout en bout des scénarios d’utilisation d’AutoML.
Pour une première expérience de code, suivez le Tutoriel : effectuer l’apprentissage d’un modèle de régression avec AutoML et Python (v1).
Pour une expérience avec peu de code ou sans code, consultez le Tutoriel : Entraînement d’un modèle de classification avec AutoML sans code dans Azure Machine Learning studio.
Pour utiliser AutoML pour l’apprentissage des modèles de vision par ordinateur, consultez Tutoriel : apprentissage d’un modèle de détection d’objets avec AutoML et Python (v1).
Des articles de guide pratique fournissent des détails supplémentaires sur les fonctionnalités du Machine Learning automatisé. Par exemple,
Configurez les paramètres pour des expériences d’entraînement automatique
Découvrez comment effectuer l'apprentissage des modèles de prévision avec des données de série chronologique (v1).
Découvrez comment effectuer l’apprentissage des modèles de vision par ordinateur avec Python (v1).
Découvrez comment afficher le code généré à partir de vos modèles de ML automatisés.
Exemples de blocs-notes Jupyter
Passez en revue les exemples de code détaillé et les cas d’usage disponibles dans le dépôt GitHub d’exemples de blocs-notes pour le Machine Learning automatisé.
Référence du Kit de développement logiciel (SDK) Python
Approfondissez votre expertise des modèles de conception de Kit de développement logiciel (SDK) et des spécifications de classe avec la documentation de référence sur la classe AutoML.
Notes
Des fonctionnalités de machine learning automatisé sont également disponible dans d’autres solutions Microsoft telles que ML.NET, HDInsight, Power BI et SQL Server