Tutoriel : Entraînement d’un modèle de classification avec AutoML sans code dans Azure Machine Learning studio
Dans ce tutoriel, vous apprenez à entraîner un modèle de classification avec le Machine Learning automatisé (AutoML) sans code en utilisant Azure Machine Learning dans Azure Machine Learning studio. Ce modèle de classification prédit si un client va souscrire à un compte à terme auprès d’une institution financière.
Avec le Machine Learning automatisé, vous pouvez automatiser les tâches chronophages. Le machine learning automatisé itère rapidement sur de nombreuses combinaisons d’algorithmes et d’hyperparamètres pour vous aider à trouver le meilleur modèle basé sur une métrique de réussite de votre choix.
Vous n’écrivez pas de code dans ce tutoriel. Vous utilisez l’interface du studio pour effectuer l’entraînement. Vous apprenez à effectuer les tâches suivantes :
- Création d’un espace de travail Microsoft Azure Machine Learning
- Exécuter une expérience de Machine Learning automatisé
- Explorer les détails du modèle
- Déployer le modèle recommandé
Prérequis
Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit.
Téléchargez le fichier de données bankmarketing_train.csv. La colonne y indique si un client a souscrit à un compte à terme, qui est ensuite identifié comme colonne cible pour les prédictions de ce tutoriel.
Remarque
Ce jeu de données Bank Marketing est disponible sous licence Creative Commons (CCO : domaine public). Tous les droits du contenu individuel de la base de données sont concédés sous licence du contenu de base de données et sont disponibles sur Kaggle. Ce jeu de données était initialement disponible dans la base de données Machine Learning UCI.
[Moro et al., 2014] S. Moro, P. Cortez et P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, Juin 2014.
Créer un espace de travail
Un espace de travail Azure Machine Learning est une ressource fondamentale du cloud que vous utilisez pour expérimenter, entraîner et déployer des modèles Machine Learning. Il lie votre abonnement Azure et votre groupe de ressources à un objet facile à consommer dans le service.
Effectuez les étapes suivantes pour créer un espace de travail et poursuivez le tutoriel.
Connectez-vous à Azure Machine Learning Studio.
Sélectionnez Créer un espace de travail.
Fournissez les informations suivantes pour configurer votre nouvel espace de travail :
Champ Description Nom de l’espace de travail Entrez un nom unique qui identifie votre espace de travail. Dans le groupe de ressources, les noms doivent être uniques. Utilisez un nom dont il est facile de se rappeler et que vous pouvez facilement différencier des autres espaces de travail. Le nom de l’espace de travail n’est pas sensible à la casse. Abonnement Sélectionnez l’abonnement Azure que vous souhaitez utiliser. Resource group Utilisez un groupe de ressources existant dans votre abonnement, ou entrez un nom pour créer un groupe de ressources. Un groupe de ressources contient les ressources associées d’une solution Azure. Pour utiliser un groupe de ressources existant, vous devez disposer du rôle de contributeur ou de propriétaire. Pour plus d’informations, consultez Gérer l’accès à un espace de travail Azure Machine Learning. Région Sélectionnez la région Azure la plus proche de vos utilisateurs et des ressources de données pour créer votre espace de travail. Sélectionnez Créer pour créer l’espace de travail.
Pour plus d’informations sur les ressources Azure, consultez Créer l’espace de travail.
Pour obtenir d’autres façons de créer un espace de travail dans Azure, consultez Gérer les espaces de travail Azure Machine Learning dans le portail ou avec le SDK Python (v2).
Créer une tâche Machine Learning automatisé
Procédez à la configuration d’expérience suivante et effectuez les étapes en utilisant Azure Machine Learning studio à l’adresse https://ml.azure.com. Machine Learning Studio est une interface web centralisée qui comprend des outils de Machine Learning permettant de mettre en œuvre des scénarios de science des données pour les professionnels de tous niveaux de compétences en la matière. Ce studio n’est pas pris en charge par les navigateurs Internet Explorer.
Sélectionnez votre abonnement et l’espace de travail que vous avez créé.
Dans le volet de navigation, sélectionnez Création>ML automatisé.
Étant donné que ce tutoriel est votre première expérience de ML automatisé, vous voyez une liste vide et des liens vers la documentation.
Sélectionnez Nouveau travail ML automatisé.
Dans Méthode d’entraînement, sélectionnez Entraîner automatiquement, puis Commencer le travail de configuration.
Dans Paramètres de base, sélectionnez Créer, puis pour Nom de l’expérience, entrez my-1st-automl-experiment.
Sélectionnez Suivant pour charger votre jeu de données.

Créer et charger un jeu de données en tant que ressource de données
Avant de configurer votre expérience, chargez le fichier de données dans votre espace de travail sous la forme d’une ressource de données Azure Machine Learning. Pour ce tutoriel, vous pouvez considérer une ressource de données comme votre jeu de données pour le travail de ML automatisé. De cette façon, vous pouvez vérifier que la mise en forme de vos données convient à votre expérience.
Dans Type de tâche et données, pour Sélectionner un type de tâche, choisissez Classification.
Sous Sélectionner des données, choisissez Créer.
Dans le formulaire Type de données, donnez un nom à votre ressource de données et fournissez éventuellement une description.
Pour Type, sélectionnez Tabulaire. Actuellement, l’interface du ML automatisé prend uniquement en charge TabularDatasets.
Cliquez sur Suivant.
Dans le formulaire Source de données, sélectionnez À partir de fichiers locaux. Cliquez sur Suivant.
Dans Type de stockage de destination, sélectionnez le magasin de données par défaut qui a été automatiquement configuré durant la création de votre espace de travail : workspaceblobstore. Vous chargez votre fichier de données à cet emplacement pour le mettre à disposition dans votre espace de travail.
Cliquez sur Suivant.
Dans Sélection de fichier ou de dossier, sélectionnez Charger un fichier ou un dossier>Charger les fichiers.
Choisissez le fichier bankmarketing_train.csv sur votre ordinateur local. Vous avez téléchargé ce fichier en tant que prérequis.
Cliquez sur Suivant.
Une fois le chargement terminé, la zone Aperçu des données est remplie en fonction du type de fichier.
Dans le formulaire Paramètres, passez en revue les valeurs de vos données. Sélectionnez ensuite Suivant.
Champ Description Valeur pour le tutoriel Format de fichier Définit la disposition et le type des données stockées dans un fichier. Delimited Délimiteur Un ou plusieurs caractères utilisés pour spécifier la limite entre des régions indépendantes et séparées dans du texte brut ou d’autres flux de données. Comma Encodage Identifie la table de schéma bits/caractères à utiliser pour lire votre jeu de données. UTF-8 En-têtes de colonne Indique la façon dont les éventuels en-têtes du jeu de données sont traités. Tous les fichiers ont les mêmes en-têtes Ignorer les lignes Indique le nombre éventuel de lignes ignorées dans le jeu de données. None Le formulaire Schema permet de configurer davantage vos données pour cette expérience. Pour cet exemple, sélectionnez le bouton bascule correspondant à day_of_week, afin de ne pas l’inclure. Cliquez sur Suivant.
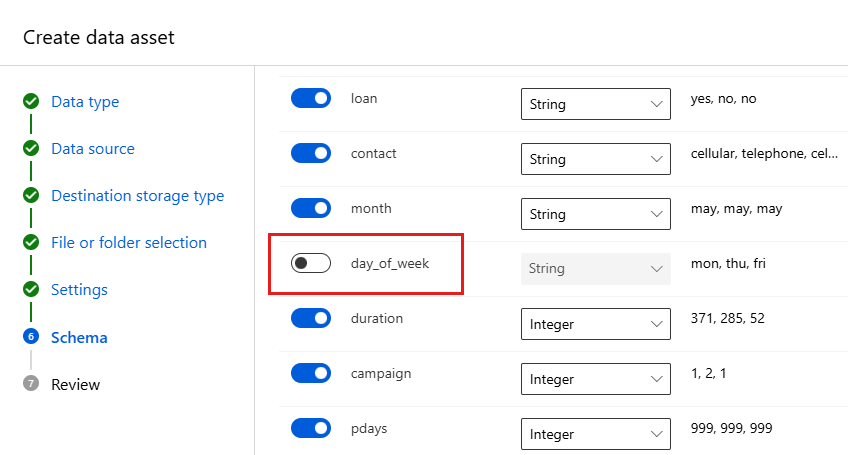
Dans le formulaire Vérifier, vérifiez vos informations et sélectionnez Créer.
Sélectionnez votre jeu de données dans la liste.
Passez en revue les données en sélectionnant la ressource de données et en examinant l’onglet aperçu. Vérifiez qu’elle n’inclut pas day_of_week et sélectionnez Fermer.
Sélectionnez Suivant pour passer aux paramètres de tâche.
Configurer le travail
Une fois que vous avez chargé et configuré vos données, vous pouvez configurer votre expérience. Cette configuration comprend des tâches de conception d’expérience, comme la sélection de la taille de votre environnement de calcul et la spécification de la colonne que vous voulez prédire.
Remplissez le formulaire Paramètres de tâche comme suit :
Sélectionnez y (Chaîne) comme colonne cible, qui correspond à ce que vous souhaitez prédire. Cette colonne indique si le client a souscrit à un compte de dépôt à terme.
Sélectionnez Afficher des paramètres de configuration supplémentaires et renseignez les champs comme suit. Ces paramètres permettent de mieux contrôler le travail d’entraînement. Sinon, les valeurs par défaut sont appliquées en fonction de la sélection de l’expérience et des données.
Configurations supplémentaires Description Valeur pour le tutoriel Métrique principale Métrique d’évaluation utilisée pour mesurer l’algorithme de Machine Learning. AUCWeighted Expliquer le meilleur modèle Montre automatiquement l’explicabilité sur le meilleur modèle créé par le ML automatisé. Enable Modèles bloqués Algorithmes que vous souhaitez exclure du travail de formation Aucune Cliquez sur Enregistrer.
Sous Valider et tester :
- Pour Type de validation, sélectionnez Validation croisée k-fold.
- Pour Nombre de validations croisées, sélectionnez 2.
Cliquez sur Suivant.
Sélectionnez Cluster de calcul comme type de calcul.
Une cible de calcul est un environnement de ressources local ou informatique utilisé pour exécuter votre script d’entraînement ou pour héberger votre déploiement de service. Pour cette expérience, vous pouvez essayer un calcul serverless basé sur le cloud (préversion) ou créer votre propre calcul basé sur le cloud.
Remarque
Pour utiliser le calcul serverless, activez la fonctionnalité en préversion, sélectionnez Serverless et ignorez cette procédure.
Pour créer votre propre cible de calcul, dans Sélectionner le type de calcul, sélectionnez Cluster de calcul pour configurer votre cible de calcul.
Remplissez le formulaire Machine virtuellepour configurer votre calcul. Cliquez sur Nouveau.
Champ Description Valeur pour le tutoriel Emplacement La région à partir de laquelle vous souhaitez exécuter la machine USA Ouest 2 Niveau de machine virtuelle Sélectionnez la priorité que doit avoir votre expérience Dédié Type de machine virtuelle Sélectionnez le type de machine virtuelle pour votre calcul. Processeur (CPU) Taille de la machine virtuelle Sélectionnez la taille de la machine virtuelle pour votre calcul. La liste des tailles recommandées qui est fournie dépend de vos données et du type de l’expérience. Standard_DS12_V2 Sélectionnez Suivant pour passer au formulaire Paramètres avancés.
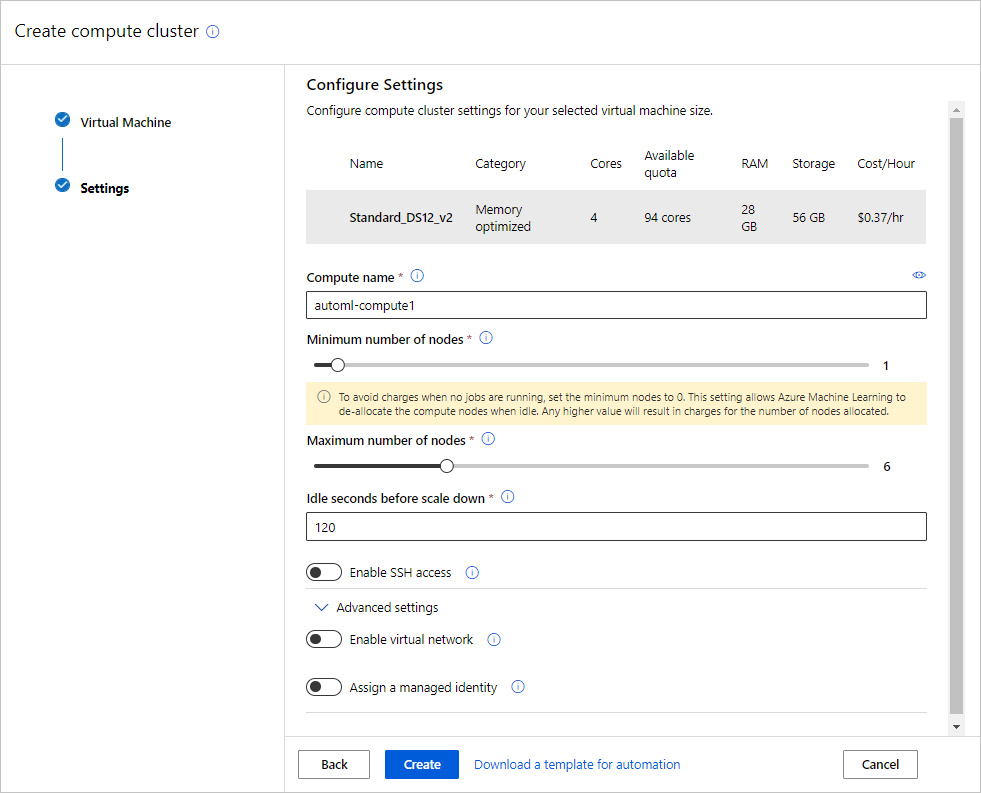
Champ Description Valeur pour le tutoriel Nom du calcul Nom unique qui identifie votre contexte de calcul. automl-compute Nombre minimal/maximal de nœuds Pour profiler des données, vous devez spécifier un ou plusieurs nœuds. Nœuds min. : 1
Nœuds max. : 6Secondes d’inactivité avant le scale-down Durée d’inactivité avant que le cluster ne fasse l’objet d’un scale-down vers le nombre de nœuds minimal. 120 (par défaut) Paramètres avancés Paramètres pour configurer et autoriser un réseau virtuel pour votre expérience. Aucune Sélectionnez Créer.
La création d’un calcul peut prendre quelques minutes.
Une fois la création terminée, sélectionnez votre nouvelle cible de calcul dans la liste. Cliquez sur Suivant.
Sélectionnez Soumettre un travail d’apprentissage pour exécuter l’expérience. L’écran Vue d’ensemble s’ouvre avec l’État dans la partie supérieure au début de la préparation de l’expérience. Cet état est mis à jour à mesure que l’expérience progresse. Les notifications s’affichent également dans le studio pour vous informer de l’état de votre expérience.

Important
La préparation nécessaire à l’exécution de l’expérience prend 10 à 15 minutes. Une fois que l’exécution a commencé, 2-3 minutes supplémentaires sont nécessaires pour chaque itération.
Dans un environnement de production, cette durée est un peu plus longue. Toutefois, dans le cadre de ce tutoriel, vous pouvez commencer à explorer les algorithmes testés sous l’onglet Modèles une fois qu’ils ont fini, pendant que les autres continuent de s’exécuter.
Explorer les modèles
Accédez à l’onglet Modèles + travaux enfants pour voir les algorithmes (modèles) testés. Par défaut, le travail trie les modèles par score de métrique à mesure qu’ils s’exécutent. Pour ce tutoriel, le modèle qui obtient le score le plus élevé d’après la métrique AUCWeighted choisie figure en haut de la liste.
En attendant que toutes les modèles d’expérience se terminent, sélectionnez le Nom de l’algorithme d’un modèle terminé pour explorer ses performances en détail. Sélectionnez la Vue d’ensemble et les onglets Métriques pour plus d’informations sur le travail.
L’animation suivante affiche les propriétés, les métriques et les graphiques de performances du modèle sélectionné.

Afficher les explications de modèle
Pendant l’exécution des modèles, vous pouvez en profiter pour examiner les explications de modèle et constater quelles fonctionnalités de données (brutes ou générées) ont influencé les prédictions d’un modèle spécifique.
Ces explications de modèle peuvent être générées à la demande. Le tableau de bord des explications de modèle qui fait partie de l’onglet Explications (préversion) récapitule ces explications.
Pour générer des explications de modèle :
Dans les liens de navigation en haut de la page, sélectionnez le nom du travail pour revenir à l’écran Modèles.
Sélectionnez l’onglet Modèles + travaux enfants.
Pour ce tutoriel, sélectionnez le premier modèle MaxAbsScaler, LightGBM.
Sélectionnez Expliquer le modèle. À droite, le volet Expliquer le modèle s’affiche.
Sélectionnez votre type de calcul, puis l’instance ou le cluster automl-compute que vous avez créé précédemment. Ce calcul démarre un travail enfant pour générer les explications de modèle.
Sélectionnez Créer. Un message de réussite en vert apparaît.
Remarque
La tâche d’explicabilité dure généralement de 2 à 5 minutes.
Sélectionnez Explications (préversion). Cet onglet se remplit après l’exécution d’explicabilité.
Sur la gauche, développez le volet. Sous Caractéristiques, sélectionnez la ligne qui indique raw.
Sélectionnez l’onglet Importance des caractéristiques agrégées. Ce graphique montre les fonctionnalités de données qui ont influencé les prédictions du modèle sélectionné.
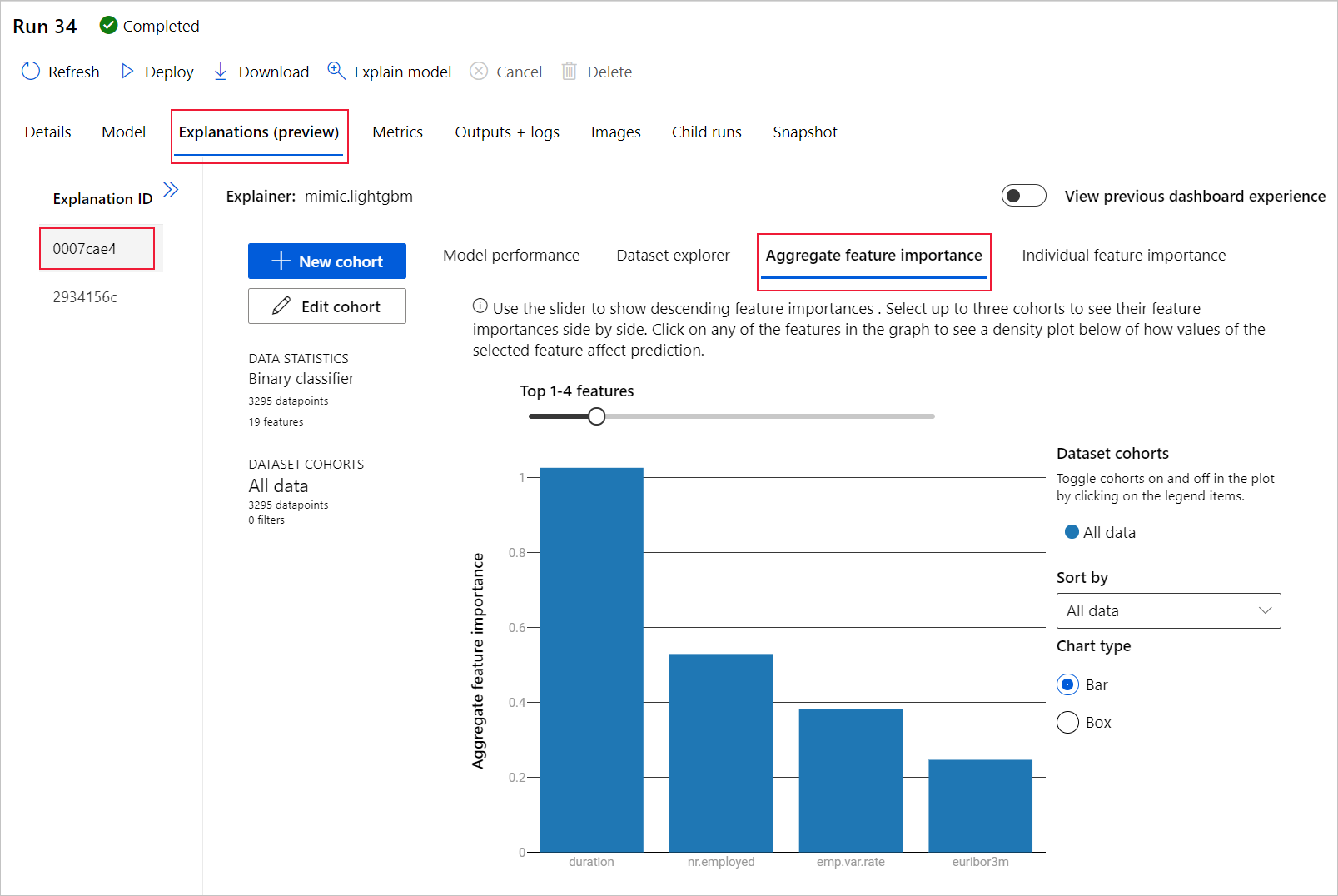
Dans cet exemple, c’est la durée qui semble avoir le plus influencé les prédictions de ce modèle.

Déployer le meilleur modèle
L’interface du Machine Learning automatisé vous permet de déployer le meilleur modèle comme service web. Le déploiement consiste à intégrer le modèle pour qu’il puisse prédire de nouvelles données et identifier les domaines potentiels d’opportunités. Dans le cadre de cette expérience, le déploiement sur un service web signifie que l’établissement financier dispose désormais d’une solution web itérative et scalable pour identifier les clients potentiels d’un compte à terme.
Vérifiez si l’exécution de votre expérience est terminée. Pour cela, revenez à la page du travail parent en sélectionnant le nom du travail en haut de votre écran. Un état Terminé est affiché en haut à gauche de l’écran.
Une fois l’expérience terminée, la page Détails est renseignée avec une section Résumé du meilleur modèle. Dans ce contexte d’expérience, VotingEnsemble est considéré comme le meilleur modèle d’après la métrique AUCWeighted.
Déployez ce modèle. Le déploiement prend environ 20 minutes. Le processus de déploiement comporte plusieurs étapes, notamment l’inscription du modèle, la génération de ressources et leur configuration pour le service web.
Sélectionnez VotingEnsemble pour ouvrir la page spécifique au modèle.
Sélectionnez Déployer>Service web.
Renseignez le volet Déployer un modèle de la façon suivante :
Champ Valeur Nom my-automl-deploy Description Déploiement de ma première expérience de Machine Learning automatisé Type de capacité de calcul Sélectionner Instance de conteneur Azure Activer l’authentification Désactivez. Utiliser les ressources d’un déploiement personnalisé Désactiver. Permet de générer automatiquement le fichier de pilote par défaut (script de score) et le fichier d’environnement. Pour cet exemple, utilisez les valeurs par défaut fournies dans le menu Options avancées.
Sélectionnez Déployer.
Un message de réussite en vert s’affiche en haut de l’écran Travail. Dans le volet Résumé du modèle, un message d’état s’affiche sous État du déploiement. Cliquez régulièrement sur Actualiser pour vérifier l’état du déploiement.
Vous disposez d'un service web opérationnel pour générer des prédictions.
Passez au Contenu associé pour en savoir plus sur la consommation de votre nouveau service web et testez vos prédictions à l’aide de la prise en charge d’Azure Machine Learning intégrée à Power BI.
Nettoyer les ressources
Les fichiers de déploiement sont plus volumineux que les fichiers de données et d’expérimentation. Le coût de leur stockage est donc plus élevé. Si vous souhaitez conserver vos fichiers d’expérience et d’espace de travail, supprimez uniquement les fichiers de déploiement pour réduire les coûts associés à votre compte. Si vous n’envisagez pas d’utiliser les fichiers, supprimez l’intégralité du groupe de ressources.
Supprimer l’instance de déploiement
Supprimez juste l’instance de déploiement d’Azure Machine Learning sur https://ml.azure.com/.
Accéder à Azure Machine Learning. Accédez à votre espace de travail et dans le volet Ressources, sélectionnez Points de terminaison.
Sélectionnez le déploiement à supprimer et sélectionnez Supprimer.
Sélectionnez Continuer.
Supprimer le groupe de ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans la zone de recherche du Portail Azure, saisissez Groupes de ressources, puis sélectionnez-le dans les résultats.
Dans la liste, sélectionnez le groupe de ressources créé.
Dans la page Vue d’ensemble, sélectionnez Supprimer le groupe de ressources.
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Contenu connexe
Dans ce tutoriel sur le machine learning automatisé, vous avez utilisé l’interface de ML automatisé d’Azure Machine Learning pour créer et déployer un modèle de classification. Pour plus d’informations et pour connaître les étapes suivantes, consultez ces ressources :
- En savoir plus sur le Machine Learning automatisé.
- Découvrir les graphiques et les métriques de classification : Évaluer les résultats d’une expérience de Machine Learning automatisé.
- Découvrez plus d’informations sur la configuration d’AutoML pour NLP.
Essayez également le machine learning automatisé pour ces autres types de modèles :
- Pour un exemple sans code de prévisions, consultez Tutoriel : Prévoir la demande avec le Machine Learning automatisé sans code dans Azure Machine Learning studio.
- Pour obtenir un premier exemple de code d’un modèle de détection d’objet, consultez le Tutoriel : Effectuer l’apprentissage d’un modèle de détection d’objet avec AutoML et Python.