Deep Learning avec prévision AutoML
Cet article se concentre sur les méthodes d’apprentissage profond pour la prévision de série chronologique dans AutoML. Vous trouverez des instructions et des exemples pour l’apprentissage des modèles de prévision dans AutoML dans notre article Configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique.
Le deep learning a un impact majeur dans des domaines allant de la modélisation du langage au pliage des protéines, entre autres. Les prévisions de séries chronologiques ont également bénéficié des progrès récents de la technologie de Deep Learning. Par exemple, les modèles de réseau neuronal profond (DNN) figurent en bonne place dans les modèles les plus performants des quatrième et cinquième itérations de la compétition de prévision makridakis de haut niveau.
Dans cet article, nous allons décrire la structure et le fonctionnement du modèle TCNForecaster dans AutoML pour vous aider à appliquer au mieux le modèle à votre scénario.
Présentation de TCNForecaster
TCNForecaster est un réseau convolutif temporel, ou TCN, qui a une architecture DNN spécifiquement conçue pour les données de série chronologique. Le modèle utilise des données historiques pour une quantité cible, ainsi que des fonctionnalités apparentées, pour établir des prévisions probabilistes de la cible jusqu’à un horizon de prévision spécifié. L’image suivante montre les principaux composants de l’architecture TCNForecaster :
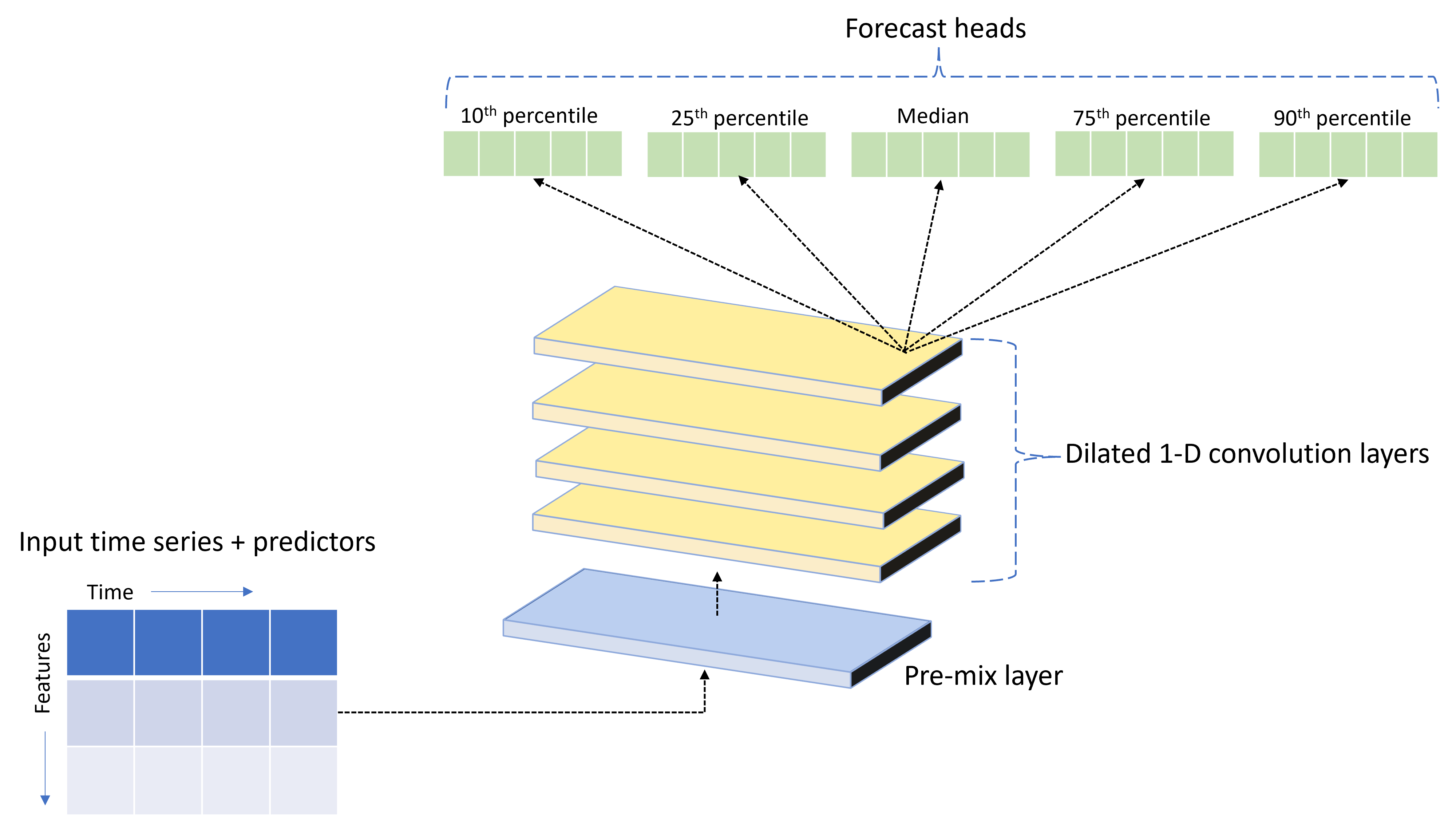
TCNForecaster possède les composants principaux suivants :
- Une couche de pré-mixage qui mélange les données de série chronologique et de caractéristique d’entrée dans un tableau de canaux de signal que la pile convolutive traitera.
- Une pile de couches de convolutions dilatées qui traite séquentiellement le tableau de canaux. Chaque couche de la pile traite la sortie de la couche précédente pour produire un nouveau tableau de canaux. Chaque canal de cette sortie contient un mélange de signaux filtrés par convolution provenant des canaux d’entrée.
- Une collection d’unités de tête de prévision qui fusionnent les signaux de sortie des couches de convolution et génèrent des prévisions de la quantité cible à partir de cette représentation latente. Chaque unité de tête produit des prévisions jusqu’à l’horizon pour un quantile de la distribution de prédiction.
Convolution causale dilatée
L’opération centrale d’un TCN est une convolution causale dilatée le long de la dimension temporelle d’un signal d’entrée. Intuitivement, la convolution combine les valeurs des points de temps proches dans l’entrée. Les proportions dans le mélange correspondent au noyau, ou les poids, de la convolution tandis que la séparation entre les points dans le mélange correspond à la dilatation. Le signal de sortie est généré à partir de l’entrée en faisant glisser le noyau dans le temps le long de l’entrée et en accumulant le mélange à chaque position. Une convolution causale est une convolution dans laquelle le noyau mélange uniquement les valeurs d’entrée dans le passé par rapport à chaque point de sortie, empêchant la sortie de « regarder » vers l’avenir.
L’empilement des convolutions dilatées permet au TCN de modéliser des corrélations sur de longues durées dans des signaux d’entrée avec relativement peu de pondérations de noyau. Par exemple, l’image suivante montre trois couches empilées avec un noyau de deux poids dans chaque couche et des facteurs de dilatation en augmentation exponentielle :
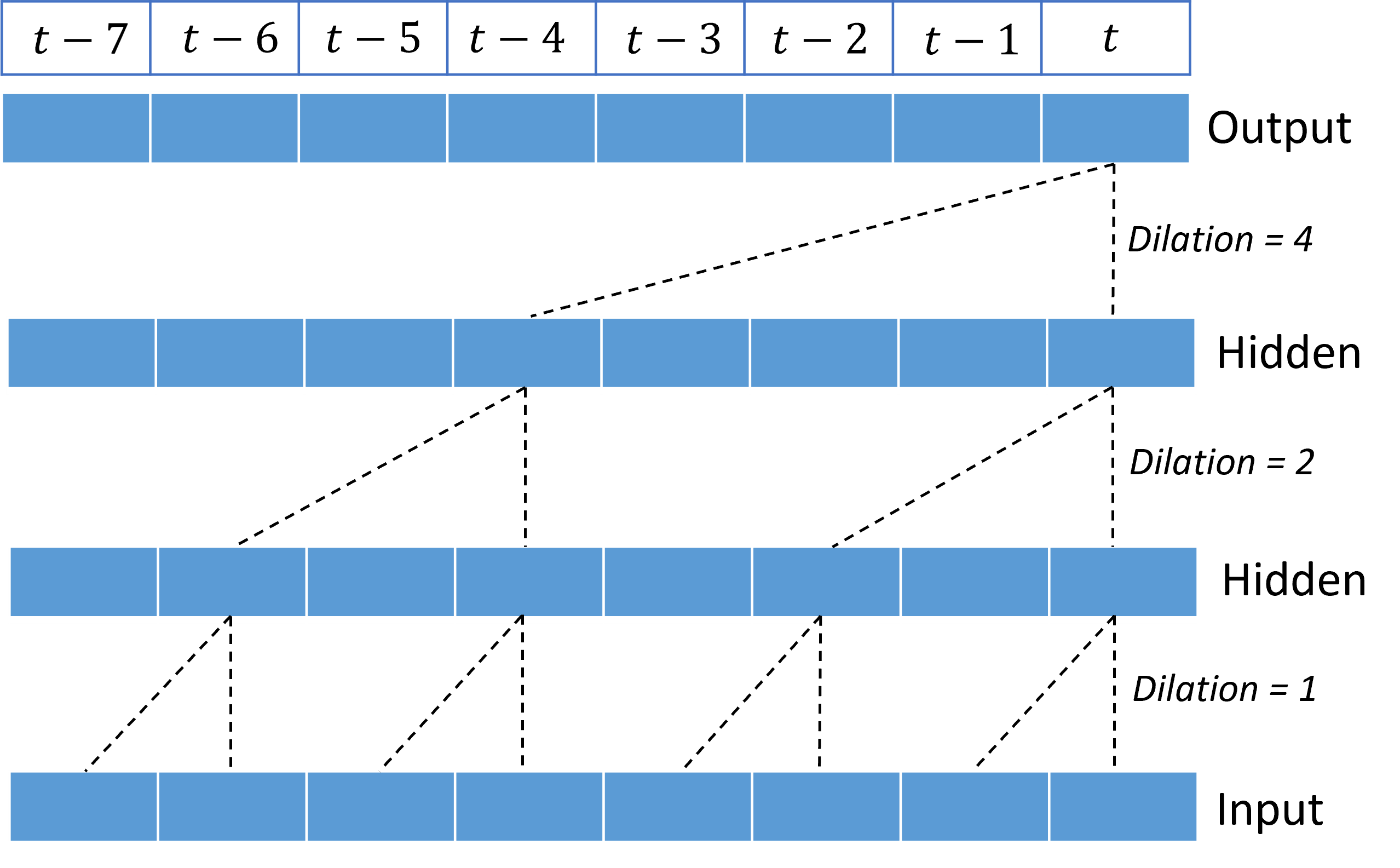
Les lignes en pointillés affichent les chemins d’accès à travers le réseau qui se terminent sur la sortie à un moment $t$. Ces chemins couvrent les huit derniers points de l’entrée, illustrant que chaque point de sortie est une fonction des huit points les plus récents de l’entrée. La longueur de l’historique, ou « regard en arrière », qu’un réseau convolutif utilise pour effectuer des prédictions est appelée champ réceptive et elle est entièrement déterminée par l’architecture TCN.
Architecture TCNForecaster
Le cœur de l’architecture TCNForecaster est la pile de couches convolutives entre le pré-mélange et les têtes de prévision. La pile est logiquement divisée en unités répétées appelées blocs qui sont, à leur tour, composés de cellules résiduelles. Une cellule résiduelle applique des convolutions causales à une dilatation définie, ainsi que la normalisation et l’activation non linéaire. Il est important de noter que chaque cellule résiduelle ajoute sa sortie à son entrée à l’aide d’une connexion dite résiduelle. Il a été démontré que ces connexions profitent à la formation DNN, peut-être parce qu’elles facilitent le flux d’informations plus efficace à travers le réseau. L’image suivante montre l’architecture des couches convolutives pour un exemple de réseau avec deux blocs et trois cellules résiduelles dans chaque bloc :
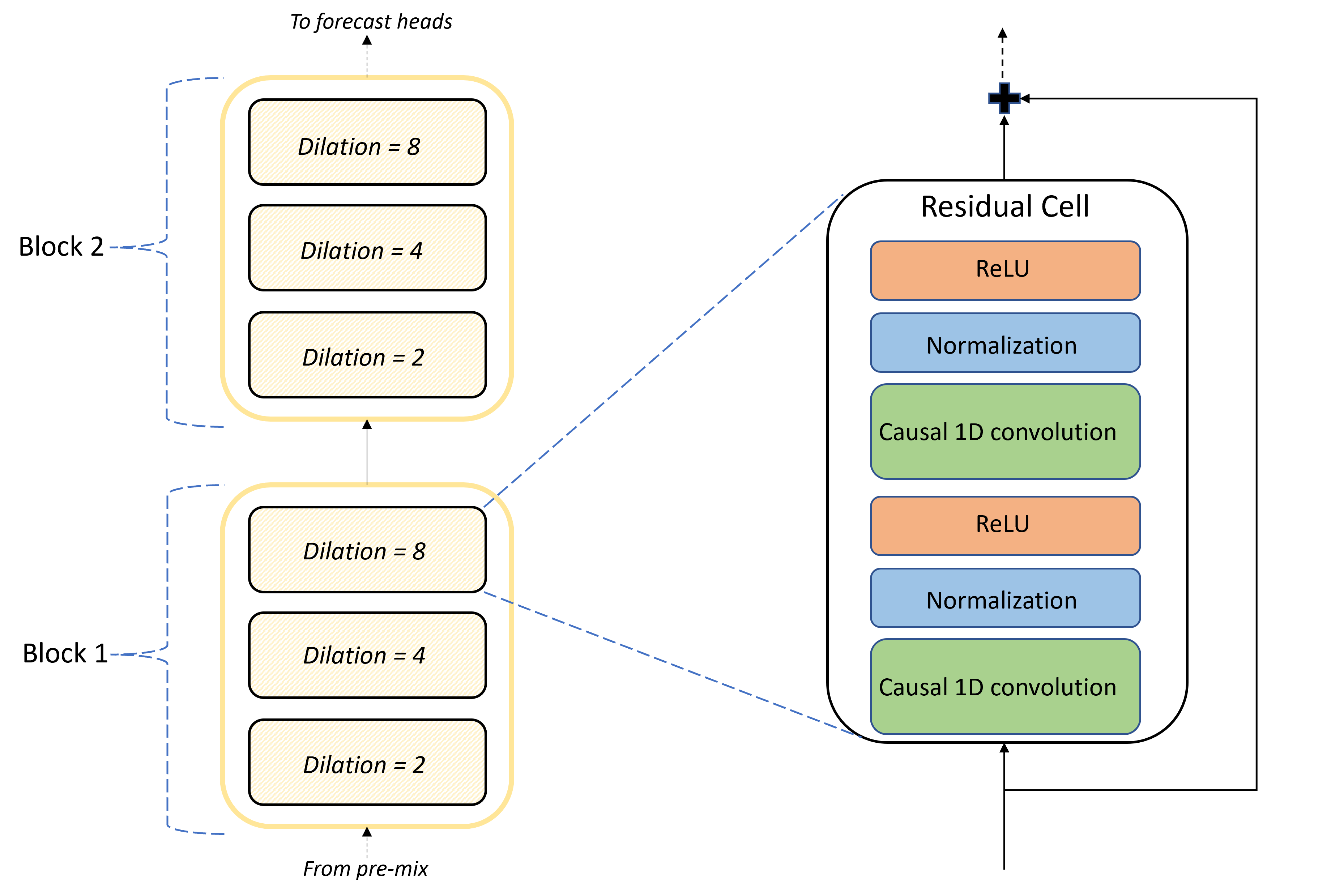
Le nombre de blocs et de cellules, ainsi que le nombre de canaux de signal dans chaque couche, contrôlent la taille du réseau. Les paramètres architecturaux de TCNForecaster sont résumés dans le tableau suivant :
| Paramètre | Description |
|---|---|
| $n_{b}$ | Nombre de blocs dans le réseau, également appelé la profondeur |
| $n_{c}$ | Nombre de cellules dans chaque bloc |
| $n_{\text{ch}}$ | Nombre de canaux dans les couches masquées |
Le champ réceptive dépend des paramètres de profondeur et est donné par la formule,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Nous pouvons donner une définition plus précise de l’architecture TCNForecaster en termes de formules. Laissez $X$ être un tableau d’entrée où chaque ligne contient des valeurs de fonctionnalité des données d’entrée. Nous pouvons diviser $X$ en tableaux de caractéristiques numériques et catégorielles, $X_{\text{num}}$ et $X_{\text{cat}}$. Ensuite, le TCNForecaster est donné par les formules,
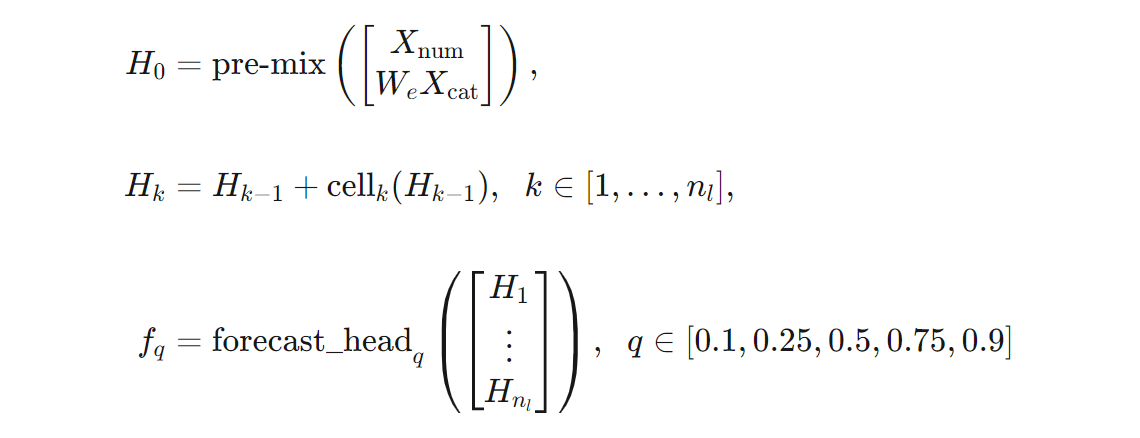
où $W_{e}$ est une matrice d’incorporation pour les caractéristiques catégorielles, $n_{l} = n_{b}n_{c}$ est les nombre total de cellules résiduelles, le $H_{k}$ désigne les sorties de couche masquées, et les $f_{q}$ sont des sorties de prévision pour des quantiles donnés de la distribution de prédiction. Pour faciliter la compréhension, les dimensions de ces variables se trouvent dans le tableau suivant :
| Variable | Description | Dimensions |
|---|---|---|
| $X$ | Tableau d’entrée | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Sortie de couche masquée pour $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Sortie de prévision pour le quantile $q$ | $h$ |
Dans le tableau, $n_{\text{input}} = n_{\text{features}} + 1$, le nombre de variables de prédicteur/fonctionnalité plus la quantité cible. Les têtes de prévision génèrent toutes les prévisions jusqu’à l’horizon maximal, $h$, en un seul passage, de sorte que TCNForecaster est un prévisionniste direct.
TCNForecaster dans AutoML
TCNForecaster est un modèle facultatif dans AutoML. Pour savoir comment l’utiliser, consultez Activer le deep learning.
Dans cette section, nous allons décrire comment AutoML génère des modèles TCNForecaster avec vos données, y compris des explications du prétraitement des données, de l’entraînement et de la recherche de modèles.
Étapes de prétraitement des données
AutoML exécute plusieurs étapes de prétraitement sur vos données pour préparer l’apprentissage du modèle. Le tableau suivant décrit ces étapes dans l’ordre dans lequel elles sont effectuées :
| Étape | Description |
|---|---|
| Remplir les données manquantes | Imputer des valeurs manquantes et des lacunes d’observation et éventuellement remplir ou annuler de courtes séries chronologiques |
| Créer des fonctionnalités de calendrier | Augmentez les données d’entrée avec des fonctionnalités dérivées du calendrier comme le jour de la semaine et, éventuellement, les jours fériés d’un pays/d’une région spécifique. |
| Encoder des données de catégorie | Encodez des chaînes et d’autres types catégoriels, cela inclut toutes les colonnes d’ID de série chronologique. |
| Transformation cible | Appliquez éventuellement la fonction de logarithme naturel à la cible en fonction des résultats de certains tests statistiques. |
| Normalisation | Le score Z normalise toutes les données numériques. La normalisation est effectuée par fonctionnalité et par groupe de série chronologique, comme défini par les colonnes d’ID de série chronologique. |
Ces étapes sont incluses dans les pipelines de transformation d’AutoML. Elles sont donc appliquées automatiquement si nécessaire au moment de l’inférence. Dans certains cas, l’opération inverse à une étape est incluse dans le pipeline d’inférence. Par exemple, si AutoML a appliqué une transformation $\log$ à la cible pendant l’entraînement, les prévisions brutes sont exposées dans le pipeline d’inférence.
Entrainement
Le TCNForecaster suit les meilleures pratiques de formation DNN communes à d’autres applications dans les images et le langage. AutoML divise les données d’entraînement prétraitées en exemples qui sont mélangés et combinés en lots. Le réseau traite les lots de manière séquentielle, en utilisant la propagation arrière et la descente de gradient stochastique pour optimiser les pondérations du réseau par rapport à une fonction de perte. La formation peut nécessiter de nombreuses passes à travers les données de formation complètes, chaque passage est appelé une époque.
Le tableau suivant répertorie et décrit les paramètres d’entrée et les paramètres pour la formation TCNForecaster :
| Entrée de formation | Description | Value |
|---|---|---|
| Données de validation | Une partie des données qui est conservée lors de la formation pour guider l’optimisation du réseau et atténuer le surajustement. | Fourni par l’utilisateur ou créé automatiquement à partir des données de formation si elles ne sont pas fournies. |
| Métrique principale | Métrique calculée à partir de prévisions de valeur médiane sur les données de validation à la fin de chaque époque de formation, utilisée pour l’arrêt précoce et la sélection du modèle. | Choisi par l’utilisateur, erreur quadratique moyenne normalisée ou erreur absolue moyenne normalisée. |
| Époques de formation | Nombre maximal d’époques à exécuter pour l’optimisation du poids du réseau. | 100, la logique d’arrêt précoce automatisée peut mettre fin à la formation à un plus petit nombre d’époques. |
| Arrêt précoce de la patience | Nombre d’époques à attendre l’amélioration des métriques principales avant d’arrêter la formation. | 20 |
| Fonction de perte | Fonction objective pour l’optimisation du poids du réseau. | Perte quantile en moyenne sur les prévisions des 10e, 25e, 50e, 75e et 90e centiles. |
| Taille du lot | Nombre d’exemples dans un lot. Chaque exemple a des dimensions $n_{\text{input}} \times t_{\text{rf}}$ pour l’entrée et $h$ pour la sortie. | Déterminé automatiquement à partir du nombre total d’exemples dans les données de la formation, valeur maximale de 1 024. |
| Incorporation des dimensions | Dimensions des espaces d’incorporation pour les fonctionnalités catégorielles. | Défini automatiquement sur la quatrième racine du nombre de valeurs distinctes dans chaque fonctionnalité, arrondi à l’entier le plus proche. Les seuils sont appliqués à une valeur minimale de 3 et à une valeur maximale de 100. |
| Architecture réseau* | Paramètres qui contrôlent la taille et la forme du réseau : la profondeur, le nombre de cellules et le nombre de canaux. | Déterminé par la recherche de modèle. |
| Pondérations réseau | Paramètres contrôlant les mélanges de signaux, les incorporations catégorielles, les pondérations de noyau de convolution et les mappages aux valeurs de prévision. | Initialisé de manière aléatoire, puis optimisé par rapport à la fonction de perte. |
| Taux d’apprentissage* | Contrôle la quantité de pondérations du réseau qui peut être ajustée à chaque itération de descente de gradient, réduit dynamiquement la quasi-convergence. | Déterminé par la recherche de modèle. |
| Proportions des abandons* | Contrôle le degré de régularisation des abandons appliqués aux pondérations réseau. | Déterminé par la recherche de modèle. |
Les entrées marquées d’un astérisque (*) sont déterminées par une recherche hyperparamètre décrite dans la section suivante.
Recherche de modèle
AutoML utilise des méthodes de recherche de modèle pour rechercher des valeurs pour les hyperparamètres suivants :
- Profondeur réseau, ou nombre de blocs convolutifs,
- Nombre de cellules par bloc,
- Nombre de canaux dans chaque couche masquée,
- Proportions d’abandons pour la régularisation réseau,
- Taux d’apprentissage.
Les valeurs optimales pour ces paramètres peuvent varier considérablement en fonction du scénario de problème et des données de formation, de sorte qu’AutoML forme plusieurs modèles différents dans l’espace des valeurs hyperparamètres et choisit le meilleur en fonction du score de métrique principal sur les données de validation.
La recherche de modèle comprend deux phases :
- AutoML effectue une recherche sur 12 modèles « repère ». Les modèles de repère sont statiques et choisis pour couvrir raisonnablement l’espace hyperparamètre.
- AutoML poursuit la recherche dans l’espace hyperparamètre à l’aide d’une recherche aléatoire.
La recherche se termine lorsque les critères d’arrêt sont remplis. Les critères d’arrêt dépendent de la configuration du travail de formation de prévision, mais certains exemples incluent les limites de temps, les limites du nombre d’essais de recherche à effectuer et la logique d’arrêt précoce lorsque la métrique de validation ne s’améliore pas.
Étapes suivantes
- Découvrez comment configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique.
- Découvrez la méthodologie de prévision dans AutoML.
- Parcourez les questions fréquentes sur les prévisions dans AutoML.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour