Questions fréquentes sur les prévisions dans AutoML
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Cet article répond aux questions courantes sur les prévisions dans Machine Learning automatisé (AutoML). Pour obtenir des informations générales sur la méthodologie de prévision dans AutoML, consultez l’article Vue d’ensemble des méthodes de prévision dans AutoML .
Comment faire pour commencer à créer des modèles de prévision dans AutoML ?
Vous pouvez commencer par lire l’article Configurer AutoML pour entraîner un modèle de prévision de série chronologique. Vous pouvez également trouver des exemples pratiques dans plusieurs notebooks Jupyter :
- Exemple de partage de vélos
- Prévisions à l’aide du Deep Learning
- Solution De nombreux modèles
- Recettes de prévision
- Scénarios de prévision avancés
Pourquoi le traitement d’AutoML est-il lent pour mes données ?
Nous nous efforçons continuellement de rendre AutoML plus rapide et plus évolutif. Pour fonctionner en tant que plateforme de prévision générale, AutoML effectue des validations de données étendues ainsi qu’une ingénierie de caractéristiques complexes et des recherches sur un grand espace de modèles. Cette complexité peut nécessiter beaucoup de temps selon les données et la configuration.
Une exécution lente est couramment due à l’apprentissage de AutoML avec des paramètres par défaut sur les données contenant de nombreuses séries chronologiques. Le coût de nombreuses méthodes de prévision est mis à l’échelle en fonction du nombre de séries. Par exemple, des méthodes comme que le lissage exponentiel et Prophet effectuent l’apprentissage d’un modèle pour chaque série chronologique des données d’apprentissage.
La fonctionnalité Nombreux modèles de AutoML est mise à l’échelle selon ces scénarios en répartissant les travaux d’apprentissage dans un cluster de calcul. Il a été appliqué avec succès aux données avec des millions de séries chronologiques. Pour plus d’informations, consultez la section plusieurs modèles de l’article. Vous pouvez également en savoir plus sur le succès de Nombreux modèles sur un jeu de données de concours de haut niveau.
Comment accélérer le traitement AutoML ?
Consultez la réponse à la question Pourquoi le traitement de AutoML est-il lent pour mes données ? pour comprendre pourquoi AutoML peut être lent dans votre cas.
Prenez en compte les modifications de configuration suivantes susceptibles d’accélérer votre travail :
- Bloquer les modèles de séries chronologiques comme ARIMA et Prophet.
- Désactiver les fonctionnalités de rétrospection comme les décalages/fenêtres dynamiques.
- Réduire :
- Le nombre d’essais/itérations.
- Délai d’expiration des essais/itérations.
- Délai d’expiration de l’expérience.
- Le nombre de replis de validation croisée.
- Assurez-vous que l’arrêt anticipé est activé.
Quelle configuration de modélisation dois-je utiliser ?
Les prévisions AutoML prennent en charge quatre configurations de base :
| Configuration | Scénario | Avantages | Inconvénients |
|---|---|---|---|
| AutoML par défaut | Recommandé si le jeu de données a un petit nombre de séries chronologiques dont le comportement historique est quasiment similaire. | - Simple à configurer à partir de du code/SDK ou de Azure Machine Learning Studio. - AutoML peut apprendre de manière croisée dans différentes séries chronologiques, car les modèles de régression regroupent toutes les séries dans l’entraînement. Pour plus d’informations, consultez regroupement de modèle. |
- Les modèles de régression peuvent être moins exacts si les séries chronologiques des données d’entraînement ont un comportement différent. - L’entraînement des modèles de séries chronologiques peut prendre du temps si les données de formation contiennent un grand nombre de séries. Pour plus d’informations, consultez la réponse à la question « Pourquoi le traitement de AutoML est-il lent pour mes données ? ». |
| AutoML avec le deep learning | Recommandé pour les jeux de données de plus de 1000 observations et, potentiellement, qui ont de nombreuses séries chronologiques présentant des modèles complexes. Quand l’option est activée, AutoML effectue un balayage des modèles de réseau neuronal convolutif temporel (TCN) pendant l’entraînement. Pour plus d’informations, consultez Activer deep learning. | - Simple à configurer à partir de du code/SDK ou de Azure Machine Learning Studio. - Opportunités d’entraînement croisé, car le réseau TCN regroupe les données de toutes les séries. - Une précision potentiellement plus élevée en raison de la grande capacité des modèles de réseau neuronal profond (DNN). Pour plus d’informations, consultez Modèles de prévision dans AutoML. |
- L’entraînement peut prendre plus de temps en raison de la complexité des modèles DNN. - Les séries avec de petites quantités d’historique sont moins susceptibles de bénéficier de ces modèles. |
| Many Models | Recommandé si vous devez entraîner et gérer un grand nombre de modèles de prévision de manière scalable. Pour plus d’informations, consultez la section plusieurs modèles de l’article. | - Évolutif. - Exactitude potentiellement supérieure quand les séries chronologiques ont des comportements différents les unes par rapport aux autres. |
- Aucun entraînement entre les séries chronologiques. - Vous ne pouvez pas configurer ou exécuter les diverses tâches de modèles à partir de Azure Machine Learning studio. Seule l’expérience code/SDK est actuellement disponible. |
| Série chronologique hiérarchique (HTS) | La série chronologique hiérarchique (HTS) est recommandée si les séries de vos données ont une structure hiérarchique imbriquée, et que vous devez entraîner ou faire des prévisions à des niveaux agrégés de la hiérarchie. Pour plus d’informations, consultez la section de l’article Prévision de séries chronologiques hiérarchiques. | - L’entraînement à des niveaux agrégés peut réduire le bruit dans les séries chronologiques de nœud terminal et générer potentiellement des modèles plus exacts. - Vous pouvez récupérer les prévisions pour n’importe quel niveau de la hiérarchie de votre choix en agrégeant ou en désagrégeant les prévisions dans le niveau d’apprentissage. |
- Vous devez fournir le niveau d’agrégation pour l’entraînement. AutoML ne dispose actuellement pas d’algorithme permettant de trouver un niveau optimal. |
Notes
Nous vous recommandons d’utiliser des nœuds de calcul avec des GPU quand le Deep Learning est activé afin de tirer le meilleur parti des capacités DNN élevées. L’apprentissage peut être beaucoup plus rapide par rapport aux nœuds avec des processeurs. Pour plus d’informations, voir l’article Tailles de machine virtuelle à GPU optimisé.
Notes
Les séries chronologiques sont conçues pour les travaux où l’apprentissage ou la prédiction sont requis à des niveaux agrégés dans la hiérarchie. Pour les données hiérarchiques nécessitant uniquement l’apprentissage et la prédiction des nœuds terminaux, utilisez plutôt de Nombreux modèles.
Comment éviter le sur-ajustement et la fuite de données ?
AutoML utilise les meilleures pratiques de Machine Learning, comme la sélection de modèles à validation croisée, qui atténuent de nombreux problèmes de sur-ajustement. Toutefois, le sur-ajustement peut avoir d’autres sources :
Les données d’entrée contiennent des colonnes de caractéristiques dérivées de la cible avec une formule simple. Par exemple, une caractéristique qui est un multiple exact de la cible peut entraîner un score d’apprentissage presque parfait. Toutefois, le modèle n’est probablement pas généralisé aux données hors échantillon. Nous vous conseillons d’explorer les données avant l’apprentissage du modèle et de supprimer les colonnes qui entraînent des « fuites » d’informations cibles.
Les données d’apprentissage utilisent des caractéristiques qui ne sont pas connues à l’avenir, jusqu’à l’horizon de prévision. Les modèles de régression de AutoML supposent actuellement que toutes les caractéristiques sont connues à l’horizon de prévision. Il est recommandé d’explorer les données avant l’apprentissage et de supprimer toutes les colonnes de caractéristiques qui ne sont connues qu’historiquement.
Il existe des différences structurelles importantes (changements de régime) entre les parties d’apprentissage, de validation ou de test des données. Prenons l’exemple de l’effet de la pandémie de COVID-19 sur la demande de quasiment tous les biens en 2020 et 2021. Il s’agit d’un exemple classique de changement de régime. Le sur-ajustement dû à un changement de régime constitue le problème le plus difficile à résoudre, car il dépend fortement du scénario et des connaissances approfondies peuvent être nécessaires pour l’identifier.
En tant que première ligne de défense, essayez de réserver 10 à 20 pourcent de l’historique total des données pour la validation ou la validation croisée. Il n’est pas toujours possible de réserver cette quantité de données de validation si l’historique d’entraînement est court, mais il s’agit d’une bonne pratique. Pour plus d’informations, consultez Données d’entraînement et de validation.
Que signifie obtenir des scores de validation parfaits pour mon travail de formation ?
Il est possible de voir des scores parfaits lorsque vous regardez les métriques de validation d’un travail de formation. Un score parfait signifie que les prévisions et les données réelles sur le jeu de validation sont identiques ou presque identiques. Par exemple, vous avez une erreur quadratique moyenne égale à 0,0 ou un score R2 de 1,0.
Un score de validation parfait indique généralement que le modèle est fortement sur-ajusté, probablement en raison d’une fuite de données. La meilleure procédure consiste à inspecter les données pour détecter les fuites et supprimer la ou les colonnes qui en sont à l’origine.
Que se passe-t-il si mes données de séries chronologiques n’ont pas d’observations régulièrement espacées ?
Tous les modèles de prévision de AutoML nécessitent que les données d’apprentissage comportent des observations régulièrement espacées dans le temps. Cette exigence concerne par exemple des observations mensuelles ou annuelles, avec un nombre de jours variable entre les observations. Les données dépendantes du temps peuvent ne pas répondre à cette exigence dans deux cas :
Les données ont une fréquence bien définie, mais des observations manquantes créent des lacunes dans la série. Dans ce cas, AutoML tente de détecter la fréquence, de renseigner de nouvelles observations au niveau des lacunes et d’y imputer des valeurs de cible et de caractéristique manquantes. Facultativement, l’utilisateur peut configurer les méthodes d’imputation via les paramètres du kit SDK ou via l’interface utilisateur web. Pour plus d’informations, consultez Caractérisation personnalisée.
Les données n’ont pas de fréquence bien définie. Autrement dit, la durée entre les observations n’a pas de modèle identifiable. On peut citer par exemple les données transactionnelles, comme celles d’un système de point de vente. Dans ce cas, vous pouvez définir AutoML afin que vos données soient agrégées selon une fréquence choisie. Vous pouvez choisir une fréquence régulière optimale selon vos données et objectifs de modélisation. Pour plus d’informations, consultez la section Agrégation des données.
Comment faire pour choisir la métrique principale ?
La métrique principale est importante car sa valeur sur les données de validation détermine le meilleur modèle lors du balayage et de la sélection. L’erreur quadratique moyenne racine normalisée (NRMSE) et l’erreur absolue moyenne normalisée (NMAE) sont généralement les meilleures options pour la métrique principale dans les tâches de prévision.
Lors de la sélection, notez que les erreurs NRMSE pénalisent plus sévèrement les valeurs hors norme des données d’apprentissage que les erreurs NMAE, car elles utilisent le carré de l’erreur. NMAE peut constituer une meilleure option si vous souhaitez que le modèle soit moins sensible aux valeurs hors norme. Pour plus d’informations, consultez le guide des métriques de régression et de prévision.
Notes
Nous vous déconseillons d’utiliser le score R2, ou R2, comme métrique principale pour la prévision.
Notes
AutoML ne prend pas en charge les fonctions personnalisées ou fournies par l’utilisateur pour la métrique principale. Vous devez choisir l’une des métriques principales prédéfinies prises en charge par AutoML.
Comment améliorer la précision de mon modèle ?
- Assurez-vous de configurer AutoML de façon optimale selon vos données. Pour plus d’informations, consultez la réponse Quelle configuration de modélisation dois-je utiliser ?.
- Consultez le notebook des recettes de prévision pour obtenir des guides détaillés sur la procédure pour créer et améliorer les modèles de prévision.
- Évaluez le modèle à l’aide de back-tests sur plusieurs cycles de prévision. Cette procédure fournit une estimation plus robuste de l’erreur de prévision et vous donne une base de référence permettant de mesurer les améliorations. Pour obtenir un exemple, consultez notre notebook de back-test.
- Si les données présentent du bruit, envisagez de les agréger à une fréquence plus élevée pour augmenter le rapport signal/bruit. Pour plus d’informations, consultez Agrégation de données fréquence et cible.
- Ajoutez de nouvelles caractéristiques susceptibles de prédire la cible. Une expertise technique est très utile quand vous sélectionnez les données d’apprentissage.
- Comparez les valeurs de métriques de validation et de test. Déterminez si les données du modèle sélectionné sont sous-ajustées ou sur-ajustées. Ces connaissances vous aident à définir une meilleure configuration de l’apprentissage. Vous pouvez par exemple déterminer que vous devez utiliser davantage de replis de validation croisée en réponse au sur-ajustement.
AutoML sélectionne-t-il toujours le même meilleur modèle à partir des mêmes données d’entraînement et la même configuration ?
Le processus de recherche de modèle AutoML n’étant pas déterministe, il ne sélectionne pas toujours le même modèle à partir des mêmes données et de la même configuration.
Comment faire pour corriger une erreur de mémoire insuffisante ?
Il existe deux types de problèmes liés à la mémoire :
- Mémoire RAM insuffisante
- Mémoire de disque insuffisante
Tout d’abord, vérifiez que vous configurez AutoML de manière optimale pour vos données. Pour plus d’informations, consultez la réponse Quelle configuration de modélisation dois-je utiliser ?.
Pour les paramètres AutoML par défaut, vous pouvez corriger la mémoire RAM insuffisante à l’aide de nœuds de calcul offrant plus de RAM. En règle générale, la quantité de RAM libre doit être au moins 10 fois supérieure à la taille des données brutes pour exécuter AutoML avec les paramètres par défaut.
Il est possible de résoudre les erreurs de mémoire insuffisante du disque en supprimant le cluster de calcul et en créant un nouveau cluster.
Quels sont les scénarios de prévision avancés pris en charge par AutoML ?
Voici les scénarios de prédiction avancés pris en charge par AutoML :
- Prévisions quantiles
- Évaluation robuste du modèle via des prévisions dynamiques
- Prévision au-delà de l’horizon de prévision
- Prévision en cas de décalage entre les périodes d’entraînement et de prévision
Pour obtenir des exemples et des détails, consultez le notebook des scénarios de prévision avancés.
Comment faire pour afficher les métriques des travaux d’apprentissage de prévision ?
Pour trouver des valeurs de métriques d’entraînement et de validation, consultez Afficher les informations sur les travaux ou les exécutions dans le studio. Pour consulter les métriques d’un modèle de prévision entraîné dans AutoML, accédez à un modèle à partir de l’interface utilisateur du travail AutoML dans le studio et sélectionnez l’onglet Métriques.

Comment faire pour déboguer les défaillances des travaux d’apprentissage de prévision ?
En cas d’échec de votre travail de prévision AutoML, un message d’erreur dans l’interface utilisateur de Studio permettra de diagnostiquer et de résoudre le problème. Hormis le message d’erreur, la meilleure source d’informations concernant l’échec est le journal du pilote du travail. Pour obtenir des instructions sur la recherche des journaux de pilotes, consultez Afficher les informations sur les travaux/exécutions avec MLflow.
Notes
Pour un travail Nombreux modèles ou HTS, l’apprentissage s’effectue généralement sur des clusters de calcul à plusieurs nœuds. Les journaux de ces travaux sont présents pour chaque adresse IP de nœud. Dans ce cas, vous devez rechercher les journaux d’erreurs dans chaque nœud. Les journaux d’erreurs, ainsi que les journaux des pilotes, se trouvent dans le dossier user_logs de chaque adresse IP de nœud.
Comment faire pour déployer un modèle à partir des travaux d’apprentissage de prévision ?
Vous pouvez déployer un modèle à partir de la prévision des travaux d’entraînement de l’une des manières suivantes :
- Point de terminaison en ligne : vérifiez le fichier de scoring utilisé dans le déploiement ou cliquer sur l’onglet Test sur la page du point de terminaison dans le studio pour comprendre la structure d’entrée attendue par le déploiement. Consultez ce notebook pour voir un exemple. Pour plus d’informations sur le déploiement en ligne, consultez Déployer un modèle AutoML sur un point de terminaison en ligne.
- Point de terminaison Batch : cette méthode de déploiement vous oblige à développer un script de scoring personnalisé. Reportez-vous à ce notebook pour voir un exemple. Pour plus d’informations sur le déploiement par lots, consultez Utiliser des points de terminaison de lot pour le scoring par lots.
Pour les déploiements d’interface utilisateur, nous vous encourageons à utiliser l’une des options suivantes :
- Points de terminaison en temps réel
- Point de terminaison de lot
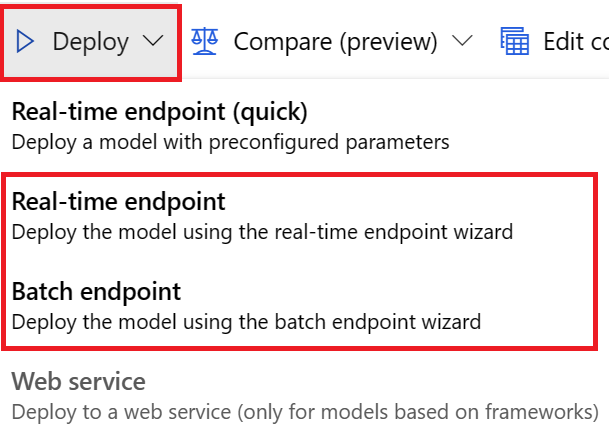
N’utilisez pas la première option, Point de terminaison en temps réel (rapide).
Notes
Pour le moment, nous ne prenons pas en charge le déploiement d’un modèle MLflow à partir des travaux d’apprentissage de prévision via le kit SDK, l’interface CLI ou l’interface utilisateur. Vous obtiendrez des erreurs si vous essayez.
Qu’est-ce qu’un espace de travail, un environnement, une expérience, une instance de calcul ou une cible de calcul ?
Si vous n’êtes pas familiarisé avec les concepts de Azure Machine Learning, commencez par consulter les articles Qu’est-ce que Azure Machine Learning ? et Qu’est-ce qu’un espace de travail Azure Machine Learning ?.
Étapes suivantes
- En savoir plus sur la procédure pour configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de séries chronologiques.
- Découvrez les fonctionnalités de calendrier pour la prévision de séries chronologiques dans AutoML.
- Découvrez comment AutoML utilise le Machine Learning pour créer des modèles de prévision.
- En savoir plus sur les Caractéristiques de décalage de Prévisions AutoML.