Inférence et évaluation des modèles de prévision (aperçu)
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Cet article présente les concepts liés à l’inférence et à l’évaluation de modèles dans les tâches de prévision. Vous trouverez des instructions et des exemples pour l’apprentissage des modèles de prévision dans AutoML dans notre article Configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique.
Une fois que vous avez utilisé AutoML pour former et sélectionner un meilleur modèle, l’étape suivante consiste à générer des prévisions. Ensuite, il s’agit le cas échéant d’évaluer leur précision sur un jeu de test retenu à partir des données d’apprentissage. Pour savoir comment configurer et exécuter l’évaluation des modèles de prévision dans le Machine Learning automatisé, consultez notre guide sur les composants d’inférence et d’évaluation.
Scénarios d’inférence
Dans le Machine Learning, l’inférence est le processus de génération de prédictions de modèle pour les nouvelles données non utilisées dans l’apprentissage. Il existe plusieurs façons de générer des prédictions dans les prévisions en raison de la dépendance temporelle des données. Le scénario le plus simple se présente lorsque la période d’inférence suit immédiatement la période d’apprentissage et que nous générons des prédictions jusqu’à l’horizon de prévision. Ce scénario est illustré dans le diagramme suivant :
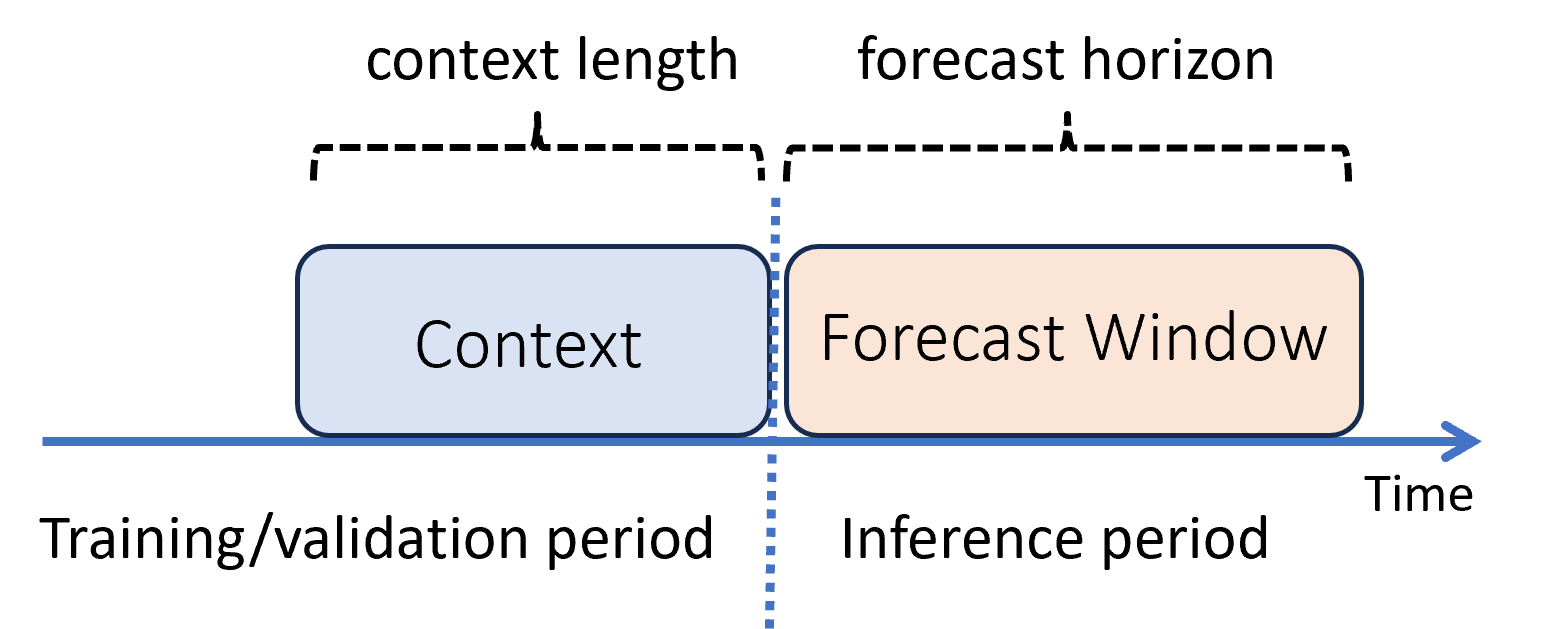
Le schéma montre deux paramètres d’inférence importants :
- La longueur du contexte ou la quantité d’historique dont le modèle a besoin pour effectuer une prévision,
- L’horizon de prévision, c’est-à-dire jusqu’à quel point dans le futur le prévisionniste est formé à anticiper.
Les modèles de prévision utilisent généralement certaines informations historiques (le contexte) pour effectuer des prédictions dans le futur jusqu’à l’horizon de prévision. Lorsque le contexte fait partie des données d’apprentissage, AutoML enregistre ce dont il a besoin pour effectuer des prévisions. Il n’est donc pas nécessaire de le fournir explicitement.
Il existe deux autres scénarios d’inférence plus complexes :
- La génération de prédictions plus loin dans l’avenir que l’horizon de prévision,
- L’obtention de prédictions en cas d’écart entre les périodes d’apprentissage et d’inférence.
Ces cas sont examinés dans les sous-sections suivantes.
Prédiction au-delà de l’horizon de prévision : prévision récursive
Lorsque vous avez besoin de prévisions au-delà de l’horizon, AutoML applique le modèle de manière récursive sur la période d’inférence. Cela signifie que les prédictions du modèle sont renvoyées en tant qu’entrée afin de générer des prédictions pour les fenêtres de prévision suivantes. Le schéma suivant présente un exemple simple :
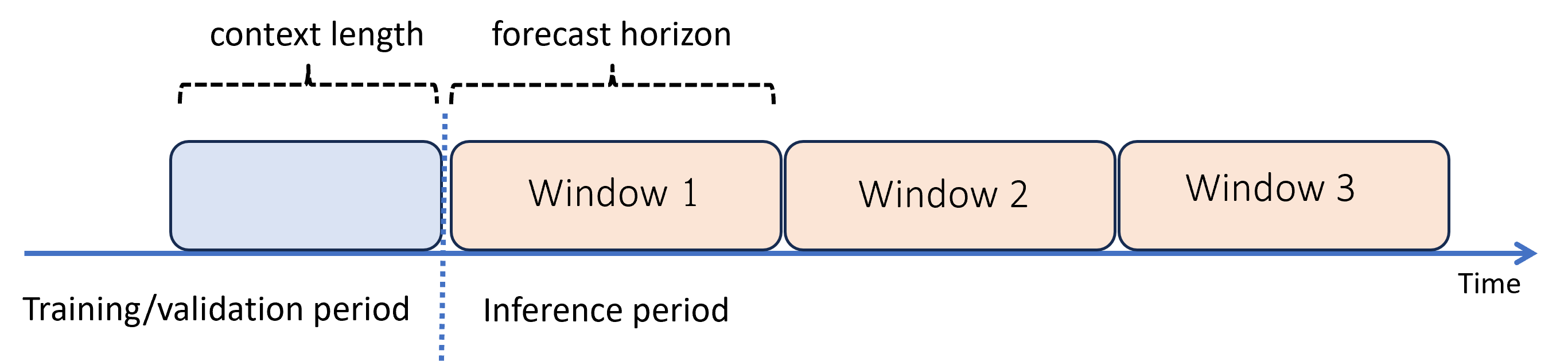
Ici, nous générons des prévisions sur une période trois fois plus longue que l’horizon en utilisant des prédictions d’une fenêtre comme contexte pour la fenêtre suivante.
Avertissement
La prévision récursive exacerbe les erreurs de modélisation, de sorte que les prédictions sont moins précises plus elles s’éloignent de l’horizon de prévision d’origine. Dans ce cas, vous trouverez peut-être un modèle plus précis en effectuant de nouveau l’apprentissage avec un horizon plus long.
Prédiction avec un écart entre les périodes d’apprentissage et d’inférence
Supposons que vous avez entraîné un modèle dans le passé et que vous souhaitez l’utiliser pour effectuer des prédictions à partir de nouvelles observations qui n’étaient pas encore disponibles pendant l’apprentissage. Dans ce cas, il existe un intervalle de temps entre les périodes d’apprentissage et d’inférence :
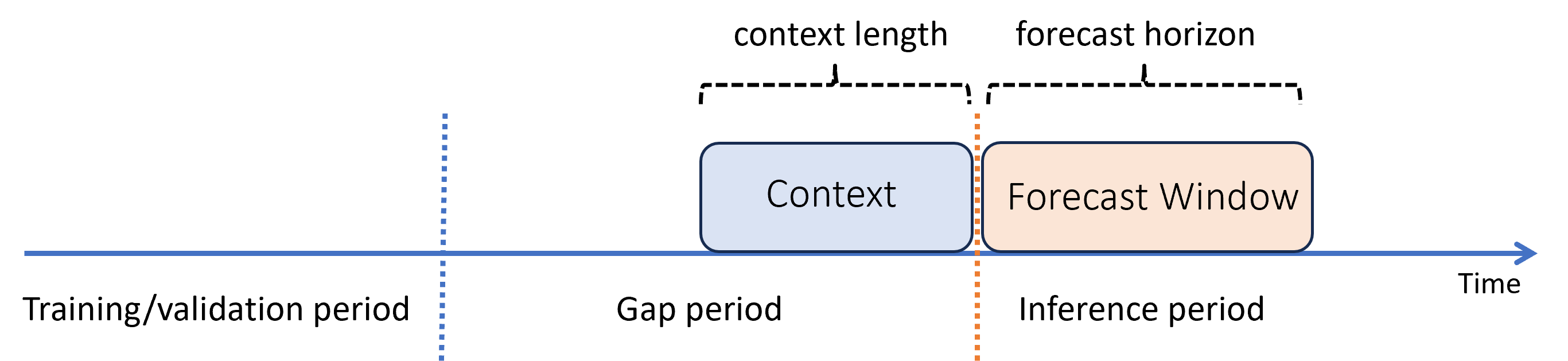
AutoML prend en charge ce scénario d’inférence, mais vous devez fournir les données de contexte dans la période d’intervalle, tel qu’illustré dans le schéma. Les données de prédiction passées au composant d’inférence ont besoin de valeurs pour les caractéristiques, de valeurs cibles observées dans l’intervalle et de valeurs manquantes ou « NaN » pour la cible dans la période d’inférence. Le tableau suivant fournit un exemple de cette tendance :
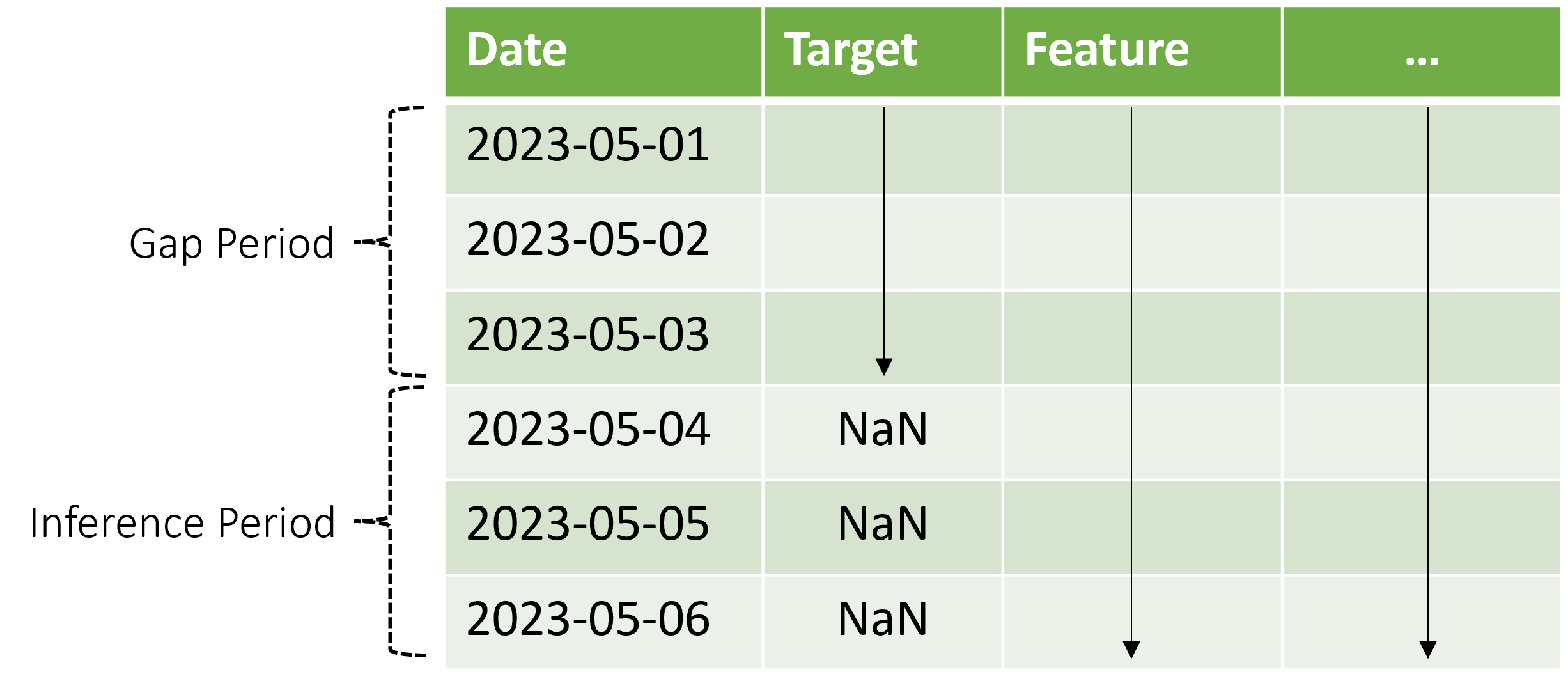
Ici, les valeurs connues pour la cible et les caractéristiques sont fournies du 01-05-2023 au 03-05-2023. Les valeurs cibles manquantes à compter du 04-05-2023 indiquent que la période d’inférence commence à cette date.
AutoML utilise les nouvelles données de contexte pour mettre à jour le décalage et d’autres fonctionnalités d’antériorité, ainsi que pour mettre à jour des modèles qui conservent un état interne, comme ARIMA. Cette opération ne met pas à jour et n’ajuste pas les paramètres du modèle.
Évaluation du modèle
L’évaluation est le processus de génération de prédictions sur un jeu de test exclu des données d’apprentissage et sur des métriques de calcul de ces prédictions qui guident les décisions de déploiement du modèle. En conséquence, il existe un mode d’inférence spécifiquement adapté à l’évaluation du modèle : la prévision évolutive. Nous l’examinons dans la sous-section suivante.
Prévision évolutive
Pour évaluer un modèle de prévision, il est recommandé de faire avancer le prévisionniste formé dans le futur sur le jeu de test, en faisant la moyenne des métriques d’erreur sur plusieurs fenêtres de prédiction. Cette procédure est parfois appelée « backtest », selon le contexte. Dans l’idéal, le jeu de test pour l’évaluation est long par rapport à l’horizon de prévision du modèle. Dans le cas contraire, les estimations des erreurs de prévision peuvent être statistiquement bruyantes et, par conséquent, moins fiables.
Le schéma suivant fournit un exemple simple avec trois fenêtres de prévision :
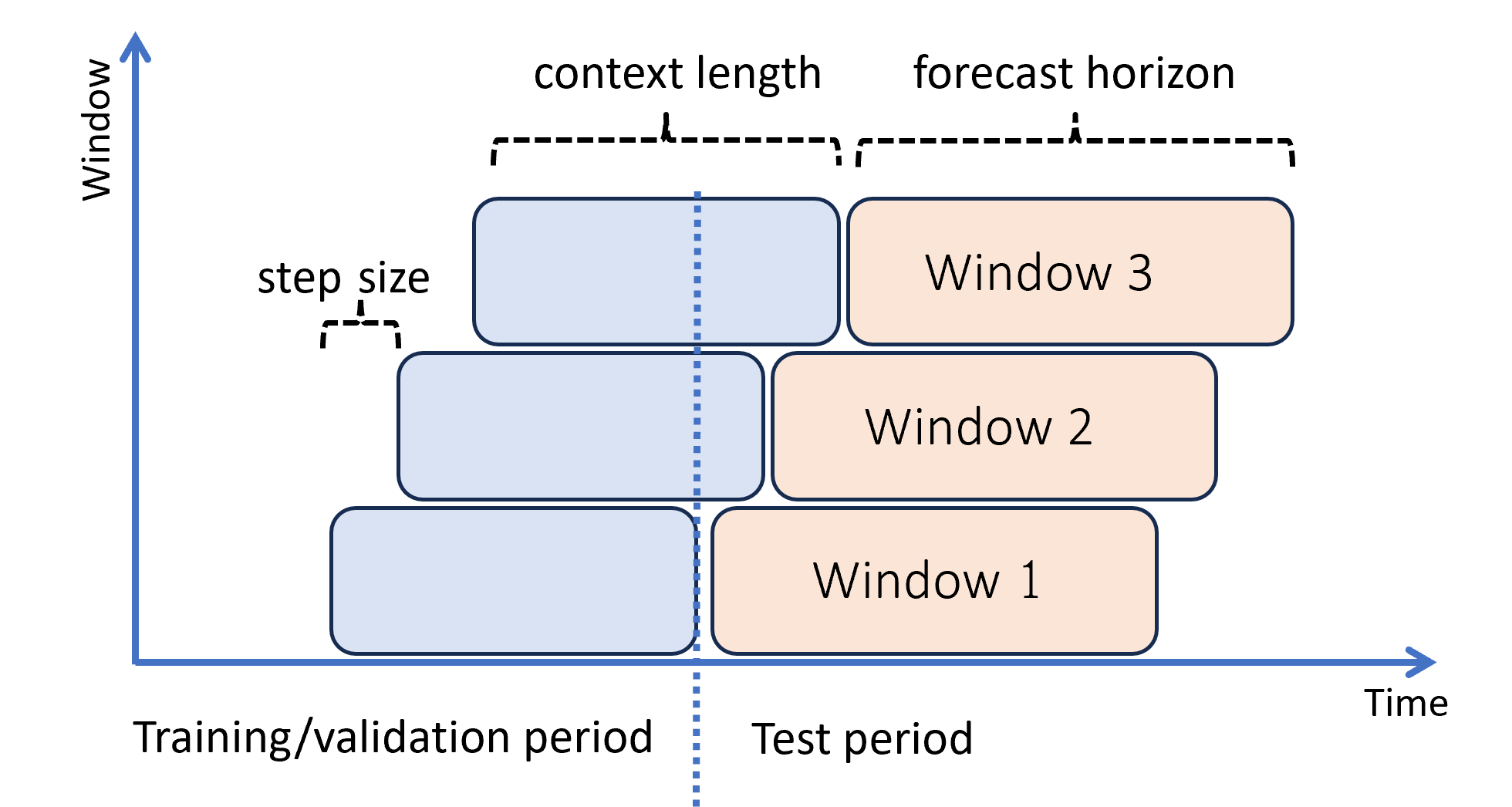
Le schéma illustre trois paramètres d’évaluation évolutive :
- La longueur du contexte ou la quantité d’historique dont le modèle a besoin pour effectuer une prévision,
- L’horizon de prévision, c’est-à-dire jusqu’à quel point dans le futur le prévisionniste est formé à anticiper,
- La longueur d’étape, c’est-à-dire jusqu’à quel point dans le futur la fenêtre évolutive avance sur chaque itération sur le jeu de test.
Il est important de noter que le contexte évolue avec la fenêtre de prévision. Cela signifie que les valeurs réelles du jeu de test sont utilisées pour effectuer des prévisions lorsqu’elles se trouvent dans la fenêtre de contexte actuelle. La date la plus récente des valeurs réelles utilisées pour une fenêtre de prévision donnée est appelée heure d’origine de la fenêtre. Le tableau suivant montre un exemple de sortie de la prévision évolutive à trois fenêtres avec un horizon de trois jours et une longueur d’étape d’un jour :
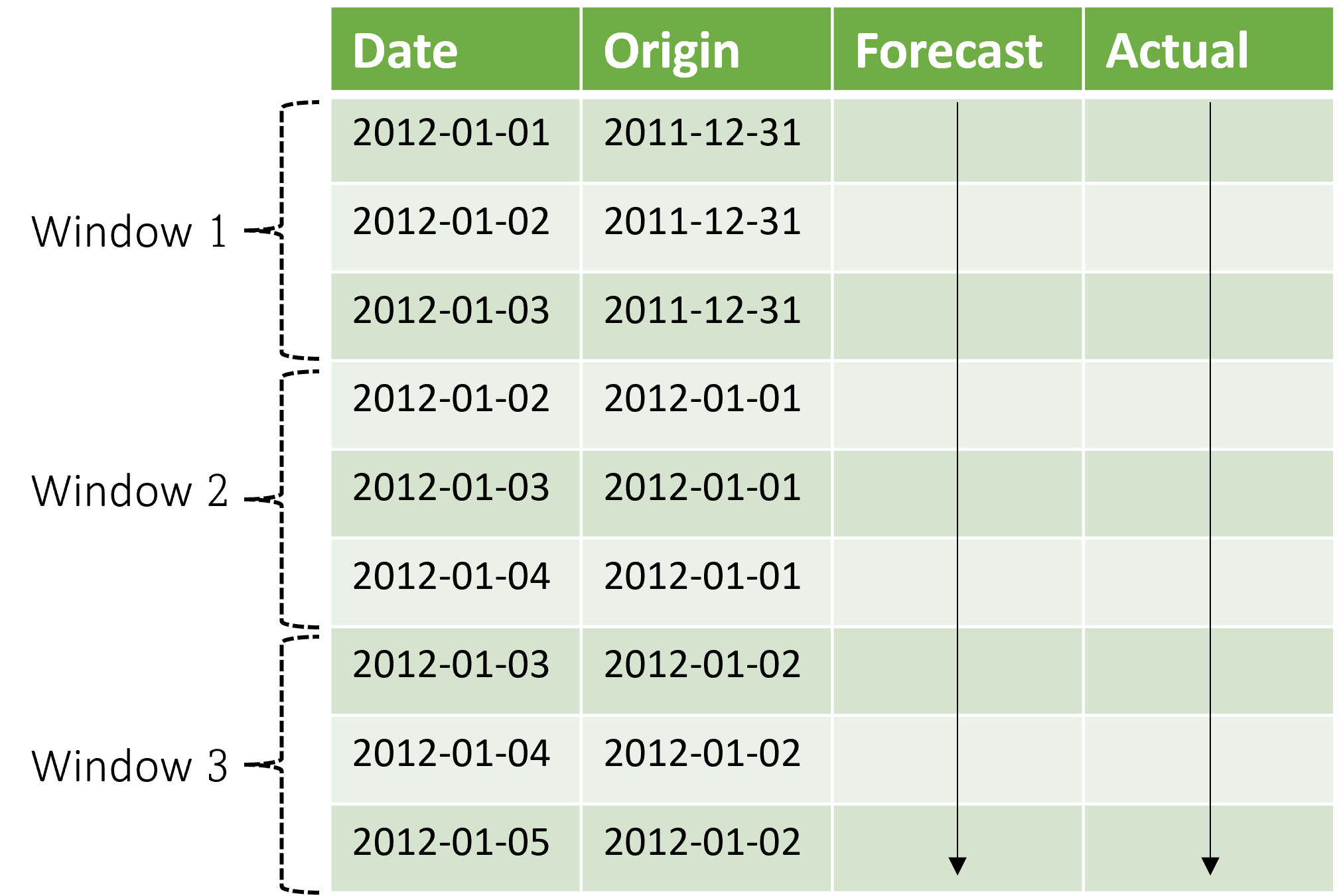
Avec un tableau comme celui-ci, nous pouvons visualiser les prévisions par rapport aux résultats réels et calculer les métriques d’évaluation souhaitées. Les pipelines AutoML peuvent générer des prévisions évolutives sur un jeu de test avec un composant d’inférence.
Notes
Lorsque la période de test est équivalente en longueur à l’horizon de prévision, une prévision évolutive donne une fenêtre unique de prévisions jusqu’à l’horizon.
Mesures d’évaluation
Le choix de résumé ou de métrique de l’évaluation est généralement déterminé par le scénario métier spécifique. Certains choix courants comprennent :
- Des tracés de valeurs cibles observées par rapport aux valeurs prévues pour vérifier que certaines dynamiques des données sont capturées par le modèle,
- La MAPE (erreur de pourcentage absolu moyen) entre les valeurs réelles et prévues,
- La RMSE (erreur quadratique moyenne), éventuellement avec normalisation, entre les valeurs réelles et prévues,
- La MAE (erreur absolue moyenne), éventuellement avec normalisation, entre les valeurs réelles et prévues.
Il existe beaucoup d’autres possibilités selon le scénario métier. Il se peut que vous deviez créer vos propres utilitaires de post-traitement pour le calcul des métriques d’évaluation à partir des résultats d’inférence ou des prévisions évolutives. Pour plus d’informations sur les métriques, consultez la section métriques de régression et de prévision de notre article.
Étapes suivantes
- En savoir plus sur la procédure pour configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique.
- Découvrez comment AutoML utilise le Machine Learning pour créer des modèles de prévision.
- Lisez les réponses à la FAQ sur les prévisions dans AutoML.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour