Qu’est-ce que le Concepteur (v1) dans Azure Machine Learning ?
Le Concepteur dans Azure Machine Learning est une interface par glisser-déposer utilisée pour entraîner et déployer des modèles dans Azure Machine Learning studio. Cet article décrit les tâches que vous pouvez effectuer dans le concepteur.
Important
Le Concepteur dans Azure Machine Learning prend en charge deux types de pipelines, qui utilisent des composants prédéfinis classiques (v1) ou personnalisés (v2). Les deux types de composants ne sont pas compatibles dans les pipelines, et le Concepteur v1 n’est pas compatible avec l’interface CLI v2 et le SDK v2. Cet article s’applique aux pipelines qui utilisent des composants prédéfinis classiques (v1).
Les composants prédéfinis classiques (v1) comprennent le traitement de données standard et les tâches de Machine Learning telles que la régression et la classification. Azure Machine Learning continue de prendre en charge les composants prédéfinis classiques existants, mais aucun nouveau composant prédéfini n’est ajouté. De plus, le déploiement de composants prédéfinis classiques (v1) ne prend pas en charge les points de terminaison en ligne gérés (v2).
Les composants personnalisés (v2) vous permettent d’envelopper votre propre code en tant que composants, permettant le partage entre les espaces de travail et la création fluide sur les interfaces Azure Machine Learning studio, CLI v2 et SDK v2. Il est préférable d’utiliser des composants personnalisés pour de nouveaux projets, car ils sont compatibles avec Azure Machine Learning v2 et continuent de recevoir de nouvelles mises à jour. Pour plus d’informations sur les composants personnalisés et le Concepteur (v2), consultez Concepteur Azure Machine Learning (v2).
L’image GIF animée suivante montre comment créer un pipeline visuellement dans le Concepteur en faisant un glisser-déposer des composants et en les connectant.

Pour découvrir les composants disponibles dans le concepteur, consultez les informations de référence sur les algorithmes et les composants. Pour commencer avec le concepteur, consultez Tutoriel : Entraîner un modèle de régression sans code.
Formation et déploiement du modèle
Le concepteur utilise votre espace de travail Azure Machine Learning pour organiser des ressources partagées telles que :
- Pipelines
- Données
- Ressources de calcul
- Modèles inscrits
- Travaux de pipeline publiés
- Points de terminaison en temps réel
Le diagramme suivant montre comment utiliser le Concepteur pour créer un workflow de machine learning de bout en bout. Vous pouvez entraîner, tester et déployer des modèles, le tout dans l’interface du Concepteur.
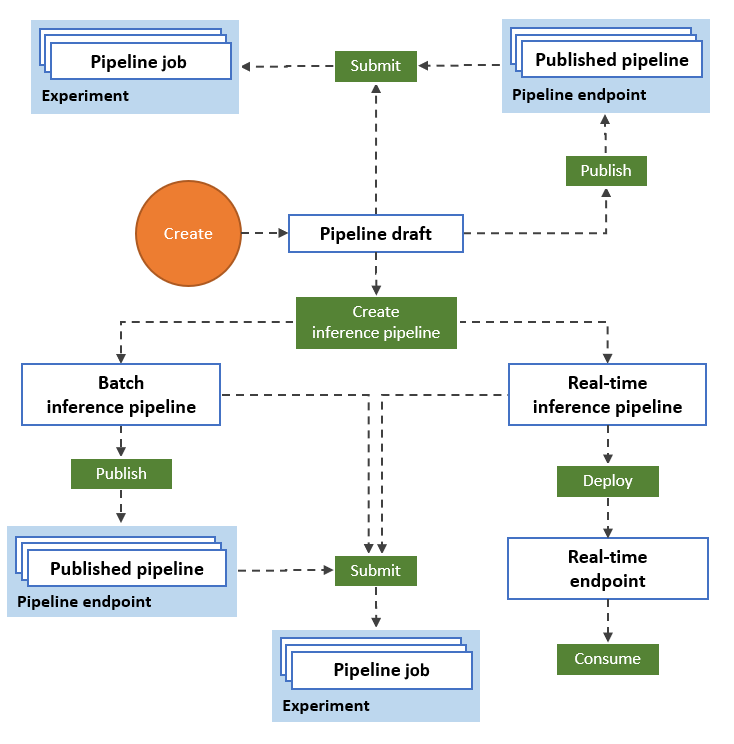
- Faites un glisser-déposer des ressources de données et des composants sur le canevas visuel du Concepteur et connectez les composants pour créer un brouillon de pipeline.
- Envoyez un travail de pipeline qui utilise les ressources de calcul de votre espace de travail Azure Machine Learning.
- Convertir vos pipelines de formation en pipelines d’inférence.
- Publiez vos pipelines sur un point de terminaison de pipeline REST pour soumettre les nouveaux pipelines qui s’exécutent avec des paramètres et des ressources de données différents.
- Publier un pipeline d’entraînement pour réutiliser un pipeline unique afin d’entraîner plusieurs modèles tout en modifiant les paramètres et les ressources de données.
- Publier un pipeline d’inférence par lot pour effectuer des prédictions sur de nouvelles données à l’aide d’un modèle préalablement formé.
- Déployer un pipeline d’inférence en temps réel vers un point de terminaison en ligne pour effectuer des prédictions sur de nouvelles données en temps réel.
Données
Une ressource de données de machine learning facilite l’accès aux données et leur utilisation. Le Concepteur comprend plusieurs exemples de ressources de données pour que vous puissiez les tester. Vous pouvez inscrire plusieurs ressources de données en fonction de vos besoins.
Composants
Un composant est un algorithme que vous pouvez exécuter sur vos données. Le concepteur comporte plusieurs composants, allant de fonctions d’entrée des données à des processus d’entraînement, de scoring et de validation.
Un composant peut avoir des paramètres que vous utilisez pour configurer les algorithmes internes du composant. Quand vous sélectionnez un composant sur le canevas, ses paramètres, ainsi que d’autres paramètres, s’affichent dans un volet de propriétés à droite du canevas. Vous pouvez modifier les paramètres et définir les ressources de calcul pour des composants individuels dans ce volet.
Pour plus d’informations sur la bibliothèque d’algorithmes Machine Learning disponibles, consultez Informations de référence sur les algorithmes et les composants. Pour obtenir de l’aide sur le choix d’un algorithme, consultez Aide-mémoire de l’algorithme Machine Learning.
Pipelines
Un pipeline est constitué de ressources de données et de composants analytiques que vous connectez. Les pipelines vous aident à réutiliser votre travail et à organiser vos projets.
Les pipelines ont de nombreuses utilisations. Vous pouvez créer des pipelines qui :
- Entraînent un seul modèle.
- Entraînent plusieurs modèles.
- Font des prédictions en temps réel ou en lots.
- Nettoient les données uniquement.
Brouillons de pipeline
Lorsque vous modifiez un pipeline dans le concepteur, votre progression est enregistrée en tant que brouillon de pipeline. Vous pouvez modifier un brouillon de pipeline à tout moment en ajoutant ou en supprimant des composants, en configurant des cibles de calcul ou en définissant des paramètres.
Un pipeline valide a les caractéristiques suivantes :
- Les ressources de données peuvent uniquement se connecter à des composants.
- Les composants peuvent uniquement se connecter à des ressources de données ou à d’autres composants.
- Tous les ports d’entrée des composants doivent comporter une connexion au flux de données.
- Tous les paramètres obligatoires de chaque composant doivent être configurés.
Lorsque vous êtes prêt à exécuter votre brouillon de pipeline, enregistrez le pipeline et soumettez un travail de pipeline.
Tâches du pipeline
Chaque fois que vous exécutez un pipeline, la configuration du pipeline et ses résultats sont stockés dans votre espace de travail sous la forme d’un travail de pipeline. Les travaux de pipeline sont regroupés en expériences afin d’organiser l’historique des travaux.
Vous pouvez revenir à n’importe quel travail de pipeline pour l’inspecter à des fins de dépannage ou d’audit. Clonez un travail de pipeline pour créer un brouillon de pipeline à modifier.
Ressources de calcul
Les cibles de calcul sont associées à votre espace de travail Azure Machine Learning dans Azure Machine Learning studio. Utilisez les ressources de calcul de votre espace de travail pour exécuter votre pipeline et héberger vos modèles déployés en tant que points de terminaison en ligne ou points de terminaison de pipeline pour l’inférence par lots. Les cibles de calcul prises en charge sont les suivantes :
| Cible de calcul | Entrainement | Déploiement |
|---|---|---|
| Capacité de calcul Azure Machine Learning | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
Déployer
Pour procéder à une inférence en temps réel, vous devez déployer un pipeline en tant que point de terminaison en ligne. Le point de terminaison en ligne crée une interface entre une application externe et votre modèle de scoring. Le point de terminaison s’appuie sur l’architecture populaire REST, souvent choisie pour les projets de programmation web. Un appel à un point de terminaison en ligne renvoie les résultats de prédiction à l’application en temps réel.
Pour générer un appel vers un point de terminaison en ligne, vous transmettez la clé API créée au moment du déploiement du point de terminaison. Les points de terminaison en ligne doivent être déployés sur un cluster AKS. Pour savoir comment déployer votre modèle, consultez Tutoriel : Déployez un modèle Machine Learning avec le concepteur.
Publish
Vous pouvez également publier un pipeline sur un point de terminaison de pipeline. Semblable à un point de terminaison en ligne, un point de terminaison de pipeline vous permet de soumettre de nouveaux travaux de pipeline à partir d’applications externes à l’aide d’appels REST. Toutefois, vous ne pouvez pas envoyer ni recevoir de données en temps réel à l’aide d’un point de terminaison de pipeline.
Les points de terminaison de pipeline publiés sont flexibles et peuvent être utilisés pour entraîner ou réentraîner des modèles, procéder à des inférences par lots ou traiter de nouvelles données. Vous pouvez publier plusieurs pipelines sur un point de terminaison de pipeline unique et spécifier la version de pipeline à exécuter.
Un pipeline publié s’exécute sur les ressources de calcul que vous définissez dans le brouillon de pipeline pour chaque composant. Le concepteur crée le même objet PublishedPipeline que le Kit de développement logiciel (SDK).
Contenu connexe
- Apprenez les bases de l’analytique prédictive et du Machine Learning à l’aide du Tutoriel : Prédire le prix de voitures avec le Concepteur.
- Découvrez comment modifier les exemples de concepteur pour les adapter à vos besoins.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour