Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans la pratique, l’implémentation de l’IA responsable demande une ingénierie rigoureuse. Toutefois, une ingénierie rigoureuse peut s’avérer fastidieuse, manuelle et chronophage à défaut de disposer des outils et de l’infrastructure appropriés.
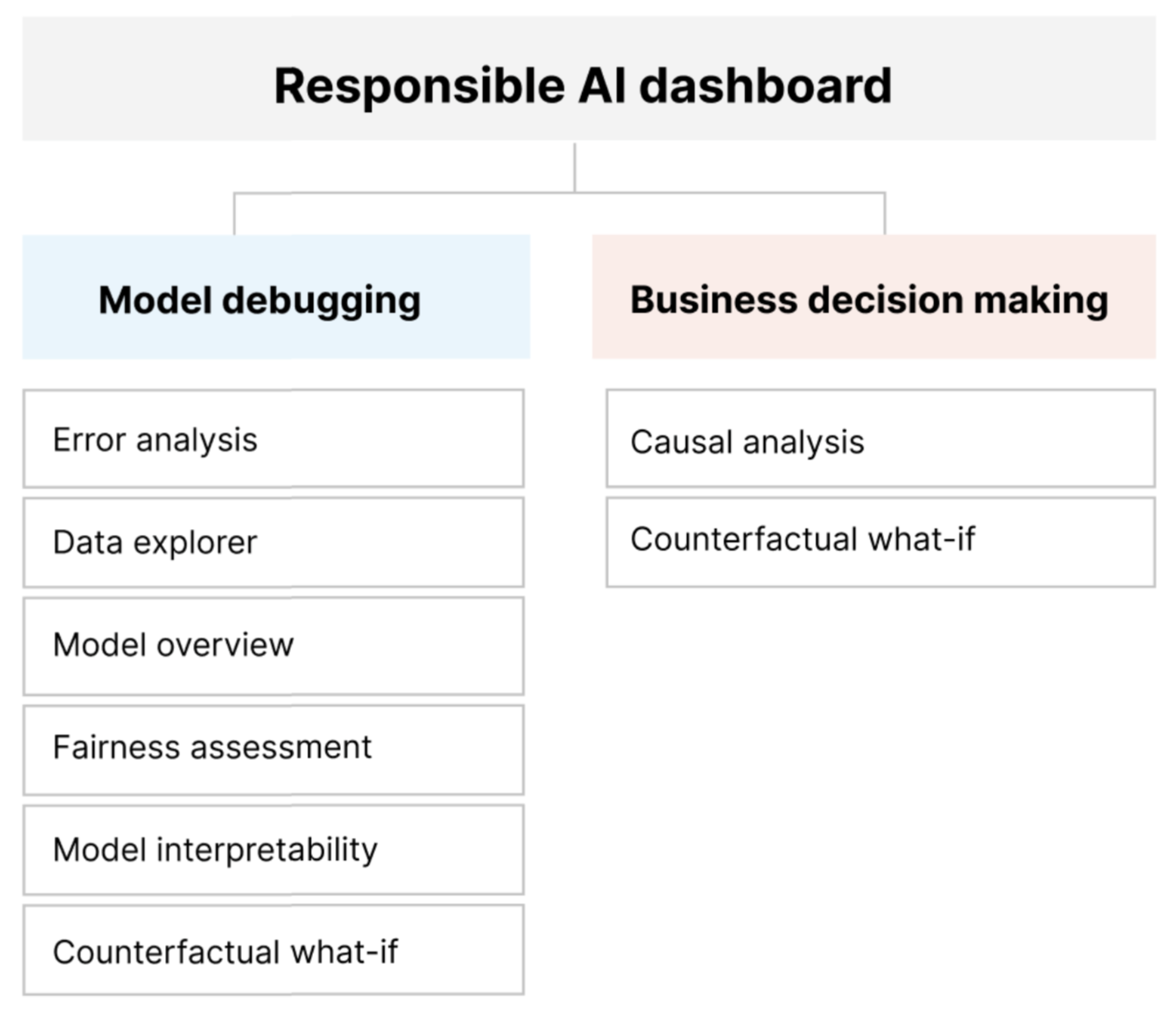
Le tableau de bord IA responsable fournit une interface unique pour vous aider à implémenter l’IA responsable en pratique de façon effective et efficace. Il réunit plusieurs outils d’IA responsable matures dans les domaines suivants :
- Performances des modèles et évaluation de l’impartialité
- Exploration des données
- Interprétabilité du machine learning
- Analyse des erreurs
- Analyse et perturbations contrefactuelles
- Inférence causale
Le tableau de bord offre une évaluation et un débogage holistiques des modèles afin que vous puissiez prendre des décisions éclairées pilotées par les données. L’accès à tous ces outils dans une seule interface vous permet de :
Évaluer et déboguer vos modèles Machine Learning en identifiant les erreurs de modèle et les problèmes d’impartialité, en diagnostiquant leur cause et en documentant vos étapes d’atténuation.
Améliorer vos capacités à prendre des décisions pilotées par les données en répondant aux questions comme :
« Quel est le changement minimal que les utilisateurs peuvent appliquer à leurs caractéristiques pour obtenir un résultat différent du modèle ? »
« Quel est l’effet causal de la réduction ou de l’augmentation d’une caractéristique (par exemple, la consommation de viande rouge) sur un résultat concret (par exemple, la progression du diabète) ? »
Vous pouvez personnaliser le tableau de bord pour inclure uniquement la partie des outils appropriée à votre cas d’usage.
Le tableau de bord IA responsable s’accompagne d’une carte de performance en PDF. La carte de performance vous permet d’exporter des métadonnées et des insights d’IA responsable dans vos données et modèles. Vous pouvez ensuite les partager hors connexion avec les parties prenantes du produit et de la conformité.
Composants du tableau de bord d’IA responsable
Le tableau de bord IA responsable réunit, dans une vue complète, divers outils nouveaux et pré-existants. Le tableau de bord intègre ces outils à Azure Machine Learning CLI v2, au SDK Python Azure Machine Learning v2 et au studio Azure Machine Learning. Ces outils sont les suivants :
- Analyse de données, pour comprendre et explorer les distributions et statistiques de votre jeu de données.
- Vue d’ensemble du modèle et évaluation de l’impartialité, pour évaluer les performances de votre modèle et les problèmes d’impartialité de groupe de celui-ci (dans quelle mesure les prédictions de votre modèle affectent divers groupes de personnes).
- Analyse des erreurs, pour voir et comprendre comment les erreurs sont distribuées dans votre jeu de données.
- Interprétabilité du modèle (valeurs d’importance pour les caractéristiques agrégées et individuelles) pour comprendre les prédictions de votre modèle et comment ces prédictions globales et individuelles sont établies.
- Simulations contrefactuelles, pour observer dans quelle mesure des perturbations de caractéristiques affectent les prédictions de votre modèle tout en fournissant les points de données les plus proches avec des prédictions de modèle opposées ou différentes.
- Analyse causale, pour utiliser les données historiques afin de voir les effets de causalité de caractéristiques de traitement sur des résultats concrets.
Ensemble, ces outils vous permettent de déboguer des modèles Machine Learning, tout en documentant vos décisions métier pilotées par les données et les modèles. Le diagramme suivant montre comment les incorporer dans le cycle de vie de votre IA pour améliorer vos modèles et obtenir des insights solides sur les données.
Débogage de modèle
L’évaluation et le débogage des modèles Machine Learning sont essentiels pour la fiabilité, l’interprétation, l’impartialité et la conformité des modèles. Ils permettent de déterminer comment et pourquoi les systèmes d’IA se comportent comme ils le font. Vous pouvez ensuite utiliser cette connaissance pour améliorer les performances du modèle. Conceptuellement, le débogage de modèle se déroule en trois phases :
Identifier, pour comprendre et reconnaître les erreurs de modèle et/ou les problèmes d’impartialité en répondant aux questions suivantes :
« Quels types d’erreurs mon modèle rencontre-t-il ? »
« Dans quels domaines les erreurs sont-elles les plus courantes ? »
Diagnostiquer pour explorer les raisons derrière les erreurs identifiées en répondant aux questions suivantes :
« Quelles sont les causes de ces erreurs ? »
« Où dois-je concentrer mes ressources pour améliorer mon modèle ? »
Atténuer en utilisant les insights d’identification et de diagnostic des étapes précédentes afin de prendre des mesures d’atténuation ciblées, et en répondant à des questions telles que les suivantes :
« Comment améliorer mon modèle ? »
« Quelles solutions sociales ou techniques existent pour ces problèmes ? »

Le tableau suivant décrit quand utiliser les composants du tableau de bord IA responsable pour prendre en charge le débogage de modèle :
| Étape | Composant | Descriptif |
|---|---|---|
| Identifier | Analyse des erreurs | Le composant d’analyse des erreurs vous aide à mieux comprendre la distribution des erreurs du modèle et à identifier rapidement les cohortes erronées (sous-groupes) de données. Les fonctionnalités de ce composant dans le tableau de bord viennent du package Error Analysis. |
| Identifier | Analyse de l’impartialité | Le composant d’impartialité définit des groupes en termes d’attributs sensibles tels que le genre, l’origine ethnique et l’âge. Il évalue ensuite dans quelle mesure les prédictions de votre modèle affectent ces groupes et comment vous pouvez atténuer les disparités. Il évalue les performances de votre modèle en explorant la distribution de vos valeurs de prédiction et les valeurs des métriques de performances de votre modèle parmi les groupes. Les fonctionnalités de ce composant dans le tableau de bord viennent du package Fairlearn. |
| Identifier | Vue d’ensemble des modèles | Le composant de vue d’ensemble du modèle agrège les métriques d’évaluation du modèle dans une vue générale de la distribution de prédictions du modèle pour améliorer l’investigation de ses performances. Ce composant permet aussi d’évaluer l’impartialité de groupe, en mettant en évidence la répartition des performances du modèle entre des groupes sensibles. |
| Diagnostiquer | Analyse des données | L’analyse de données permet de visualiser les jeux de données en fonction des résultats prédits et réels, des groupes d’erreurs et de caractéristiques spécifiques. Vous pouvez ensuite identifier les problèmes de sur-représentation et de sous-représentation, et voir comment les données sont clusterisées dans le jeu de données. |
| Diagnostiquer | Interprétabilité de modèles | Le composant d’interprétabilité génère des explications compréhensibles par l’homme des prédictions d’un modèle Machine Learning. Il fournit plusieurs perspectives sur le comportement d’un modèle : - Explications globales (par exemple, quelles caractéristiques affectent le comportement général d’un modèle d’allocation de prêt) - Explications locales (par exemple, pourquoi la demande de prêt d’un client a été approuvée ou rejetée) Les fonctionnalités de ce composant dans le tableau de bord viennent du package InterpretML. |
| Diagnostiquer | Analyse et simulation de contrefactuels | Ce composant comprend deux fonctionnalités pour améliorer le diagnostic des erreurs : - Génération d’un ensemble d’exemples dans lesquels les changements minimaux apportés à un point particulier modifient la prédiction du modèle. Autrement dit, les exemples montrent les points de données les plus proches avec des prédictions de modèle opposées. - Activation de perturbations de simulation interactives et personnalisées pour des points de données individuels afin de comprendre comment le modèle réagit aux modifications de caractéristiques. Les fonctionnalités de ce composant dans le tableau de bord viennent du package DiCE. |
Les étapes d’atténuation sont disponibles via des outils autonomes tels que Fairlearn. Pour plus d’informations, consultez les algorithmes d’atténuation de la partialité.
Prise de décision responsable
La prise de décision est l’une des plus grandes promesses de l’apprentissage automatique. Le tableau de bord IA responsable peut vous aider à prendre des décisions métier éclairées par le biais :
D’insights pilotées par les données pour mieux comprendre les effets de causalité du traitement sur un résultat, en utilisant uniquement des données historiques. Par exemple :
« Dans quelle mesure un médicament affecterait-il la tension artérielle d’un patient ? »
« Dans quelle mesure une offre de valeurs promotionnelles à certains clients affecte-t-elle les recettes ? »
Ces insights sont fournis via le composant Inférence causale du tableau de bord.
D’insights basés sur des modèles, afin de répondre aux questions des utilisateurs (telles que « Que puis-je faire pour obtenir un résultat différent de votre IA la prochaine fois ? ») afin qu’ils puissent entreprendre une action. Ces insights sont fournis aux scientifiques des données via le composant Simulation contrefactuelle.

Les fonctionnalités d’analyse exploratoire des données, d’inférence causale et d’analyse contrefactuelle peuvent vous aider à prendre des décisions éclairées pilotées par les données et les modèles de manière responsable.
Ces composants du tableau de bord IA responsable prennent en charge une prise de décision responsable :
Analyse de données : Vous pouvez réutiliser le composant d’analyse de données ici pour comprendre les distributions des données et identifier la surreprésentation et la sous-représentation. L’exploration de données est un aspect essentiel de la prise de décision parce qu’il n’est pas possible de prendre des décisions éclairées sur une cohorte qui est sous-représentée dans les données.
Inférence causale : Le composant d’inférence causale estime dans quelle mesure un résultat concret change en présence d’une intervention. Il permet également de construire des interventions prometteuses en simulant les réponses de caractéristiques à diverses interventions et en créant des règles pour déterminer quelles cohortes de population bénéficieraient d’une intervention particulière. Collectivement, ces fonctionnalités vous permettent d’appliquer de nouvelles stratégies et de rendre effectif un changement réel.
Les fonctionnalités de ce composant viennent du package EconML, qui estime les effets de traitement hétérogènes des données observationnelles via le machine learning.
Analyse contrefactuelle : Vous pouvez réutiliser le composant d’analyse contrefactuelle ici pour générer des changements minimaux appliqués aux caractéristiques d’un point de données qui entraînent des prédictions de modèle opposées. Par exemple : Selon l’IA, Taylor aurait obtenu le prêt s’il avait gagné 10 000 USD de plus de revenus annuels et s’il avait eu deux cartes de crédit.
Fournir ces informations aux utilisateurs leur donne un éclairage sur leur perspective. Ils apprennent ainsi comment ils peuvent prendre des mesures pour obtenir le résultat souhaité avec l’IA.
Les fonctionnalités de ce composant viennent du package DiCE.
Raisons d’utiliser le tableau de bord IA responsable
Même si des progrès ont été réalisés sur des outils individuels dans des domaines spécifiques de l’IA responsable, les scientifiques des données ont souvent besoin d’utiliser divers outils afin d’évaluer leurs modèles et leurs données de manière holistique. Par exemple : Ils peuvent avoir besoin d’utiliser ensemble l’interprétabilité de modèle et l’évaluation de l’impartialité.
Si les scientifiques des données découvrent un problème d’impartialité avec un outil, ils doivent passer à un autre outil pour comprendre les facteurs de données ou de modèle à l’origine du problème avant de prendre des mesures d’atténuation. Les facteurs suivants compliquent davantage ce processus difficile :
- L’absence d’emplacement central pour découvrir et apprendre des outils rend la recherche et l’apprentissage de nouvelles techniques plus longs.
- Les différents outils ne communiquent pas entre eux. Les scientifiques des données doivent composer avec les jeux de données, modèles et autres métadonnées lorsqu’ils les font circuler d’un outil à l’autre.
- Les métriques et visualisations ne sont pas facilement comparables, et les résultats difficiles à partager.
Le tableau de bord IA responsable met au défi ce statu quo. Il s’agit d’un outil complet tout en étant personnalisable qui réunit des expériences fragmentées dans un même endroit. Il vous permet d’intégrer de façon fluide une infrastructure personnalisable unique pour déboguer des modèles et prendre des décisions pilotées par les données.
En utilisant le tableau de bord IA responsable, vous pouvez créer des cohortes de jeux de données, transmettre ces cohortes à tous les composants pris en charge et observer l’intégrité de votre modèle pour vos cohortes identifiées. Vous pouvez approfondir la comparaison des insights de tous les composants pris en charge dans diverses cohortes prédéfinies pour effectuer une analyse décomposée et trouver les faiblesses de votre modèle.
Lorsque vous êtes prêt à partager ces insights avec d’autres parties prenantes, vous pouvez les extraire facilement à l’aide de la carte de performance en PDF de l’IA responsable. Joignez le rapport PDF à vos rapports de conformité ou partagez-le avec vos collègues pour gagner leur confiance et obtenir leur approbation.
Comment personnaliser le tableau de bord IA responsable
La force du tableau de bord IA responsable réside dans son potentiel de personnalisation. Il permet aux utilisateurs de concevoir des flux de travail de débogage de modèle et de prise de décision de bout en bout qui répondent à leurs besoins particuliers.
Vous avez besoin d’inspiration ? Voici quelques exemples de combinaisons de composants du tableau de bord pour analyser des scénarios de différentes manières :
| Flux du tableau de bord IA responsable | Cas d’utilisation |
|---|---|
| Vue d’ensemble du modèle > Analyse des erreurs > Analyse de données | Pour identifier des erreurs de modèle et les diagnostiquer en comprenant la distribution de données sous-jacente |
| Vue d’ensemble du modèle > Évaluation de l’impartialité > Analyse de données | Pour identifier des problèmes d’impartialité de modèle et les diagnostiquer en comprenant la distribution de données sous-jacente |
| Vue d’ensemble du modèle > Analyse des erreurs > Analyse et simulation contrefactuelles | Pour diagnostiquer des erreurs dans des instances individuelles avec une analyse contrefactuelle (modification minimale pour conduire à une prédiction de modèle différente) |
| Vue d’ensemble du modèle > Analyse de données | Pour comprendre la cause racine d’erreurs et de problèmes d’impartialité introduits via des déséquilibres de données ou un manque de représentation d’une cohorte de données particulière |
| Vue d’ensemble du modèle > Interprétabilité | Pour diagnostiquer des erreurs de modèle en comprenant comment le modèle a fait ses prédictions |
| Analyse de données > Inférence causale | Pour opérer une distinction entre des corrélations et des causalités dans les données ou décider des meilleurs traitements à appliquer pour avoir un résultat positif |
| Interprétabilité > Inférence causale | Pour savoir si les facteurs qu’un modèle utilise pour la réalisation de prédictions ont un effet de causalité sur le résultat concret |
| Analyse de données > Analyse et simulation contrefactuelles | Pour répondre aux questions de clients sur ce qu’ils peuvent faire la prochaine fois pour obtenir un résultat différent d’un système IA. |
Personnes qui devraient utiliser le tableau de bord IA responsable
Les personnes suivantes peuvent utiliser le tableau de bord IA responsable et sa carte de performance IA responsable pour établir une confiance dans les systèmes IA :
- Professionnels du machine learning et scientifiques des données qui s’intéressent au débogage et à l’amélioration de leurs modèles Machine Learning avant leur déploiement.
- Professionnels du machine learning et scientifiques des données qui sont intéressés par le partage des informations d’intégrité de leur modèle avec un gestionnaire de produits et les parties prenantes pour gagner leur confiance et recevoir les autorisations de déployer.
- Gestionnaires de produits et parties prenantes qui examinent les modèles Machine Learning avant leur déploiement.
- Responsables de la gestion des risques qui examinent les modèles Machine Learning pour comprendre les problèmes d’impartialité et de fiabilité
- Fournisseurs de solutions IA qui souhaitent expliquer les décisions de modèle aux utilisateurs ou les aider à améliorer le résultat
- Professionnels dans des espaces très réglementés qui doivent examiner les modèles Machine Learning avec des régulateurs et des auditeurs
Scénarios pris en charge et limitations
- Le tableau de bord IA responsable prend actuellement en charge les modèles de régression et de classification (binaires et multiclasses) entraînés sur des données structurées tabulaires.
- Le tableau de bord IA responsable prend actuellement en charge les modèles MLflow inscrits dans Azure Machine Learning de type sklearn (scikit-learn) uniquement. Les modèles scikit-learn doivent implémenter les méthodes
predict()/predict_proba(), ou doivent être wrappés dans une classe implémentant les méthodespredict()/predict_proba(). Les modèles doivent être chargeables dans l’environnement de composant et doivent être « pickleables » (convertis en représentation binaire simple). - Le tableau de bord IA responsable visualise actuellement jusqu’à 5 000 de vos points de données dans son interface utilisateur. Vous devez réduire l’échantillonnage de votre jeu de données à 5 000 ou moins avant de le transmettre au tableau de bord.
- Les entrées de jeu de données dans le tableau de bord IA responsable doivent être des dataFrames pandas au format Parquet. Les données éparses NumPy et SciPy ne sont pas prises en charge pour l’instant.
- Le tableau de bord IA responsable prend actuellement en charge les caractéristiques numériques ou catégorielles. Pour les caractéristiques catégorielles, l’utilisateur doit spécifier explicitement les noms des caractéristiques.
- Le tableau de bord IA responsable ne prend pas en charge les jeux de données avec plus de 10 000 colonnes pour l’instant.
- Le tableau de bord IA responsable ne prend actuellement pas en charge le modèle MLFlow d’AutoML.
- Le tableau de bord de l’IA responsable ne prend actuellement pas en charge les modèles AutoML inscrits à partir de l’interface utilisateur.
Étapes suivantes
- Découvrez comment générer le tableau de bord d’IA responsable par le biais de CLIv2 et SDKv2 ou de l’interface utilisateur d’Azure Machine Learning studio.
- Découvrez comment générer une carte de performance IA responsable basée sur des insights observées dans le tableau de bord IA responsable.