Utiliser Azure Pipelines avec Azure Machine Learning
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2019
Vous pouvez utiliser un pipeline Azure DevOps pour automatiser le cycle de vie du Machine Learning. Certaines des opérations que vous pouvez automatiser sont les suivantes :
- Préparation des données (opérations d’extraction, de transformation et de chargement)
- Formation de modèles Machine Learning avec scale-out et scale-up à la demande
- Déploiement de modèles Machine Learning en tant que services web publics ou privés
- Surveillance des modèles Machine Learning déployés (par exemple, pour l’analyse des performances ou de la dérive des données)
Cet article va vous apprendre à créer un pipeline Azure qui génère et déploie un modèle Machine Learning sur Azure Machine Learning.
Ce tutoriel utilise le SDK Python Azure Machine Learning v2 et l’extension Azure CLI ML v2.
Prérequis
- Effectuez la commande Créer des ressources pour commencer à :
- Créer un espace de travail
- Créer un cluster de calcul basé sur le cloud à utiliser pour entraîner votre modèle
- Extension Azure Machine Learning pour Azure Pipelines. Vous pouvez installer cette extension à partir de la Place de marché Visual Studio à l’adresse https://marketplace.visualstudio.com/items?itemName=ms-air-aiagility.azureml-v2.
Étape 1 : Obtenir le code
Effectuez une duplication (fork) du dépôt suivant sur GitHub :
https://github.com/azure/azureml-examples
Étape 2 : Se connecter à Azure Pipelines
Connectez-vous à Azure Pipelines. Une fois que vous êtes connecté, votre navigateur accède à https://dev.azure.com/my-organization-name et affiche votre tableau de bord Azure DevOps.
Dans votre organisation sélectionnée, créez un projet. Si votre organisation ne compte aucun projet, l’écran Pour commencer, créez un projet s’affiche. Dans le cas contraire, sélectionnez le bouton Nouveau projet dans l’angle supérieur droit du tableau de bord.
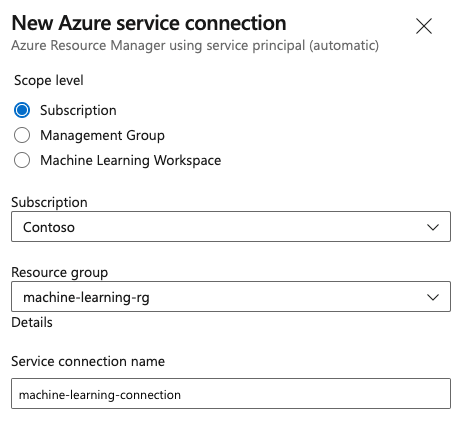
Étape 3 : créer une connexion de service
Vous pouvez utiliser une connexion de service existante.
Vous avez besoin d’une connexion Azure Resource Manager pour vous authentifier auprès du Portail Azure.
Dans Azure DevOps, sélectionnez Paramètres du projet, puis ouvrez la page Connexions de service.
Choisissez Créer une connexion de service, puis sélectionnez Azure Resource Manager.
Sélectionnez la méthode d’authentification par défaut, Principal de service (automatique).
Créez votre connexion de service. Définissez votre niveau d’étendue préféré, votre abonnement, votre groupe de ressources et votre nom de connexion.
Étape 4 : Créer un pipeline
Accédez à Pipelines, puis sélectionnez Créer un pipeline.
Effectuez les étapes de l’Assistant en sélectionnant d’abord GitHub comme emplacement du code source.
Vous serez peut-être redirigé vers GitHub pour vous connecter. Si c’est le cas, entrez vos informations d’identification GitHub.
Quand la liste des dépôts s’affiche, sélectionnez le vôtre.
Vous serez peut-être redirigé vers GitHub pour pouvoir installer l’application Azure Pipelines. Si c’est le cas, sélectionnez Approuver et installer.
Sélectionnez le Pipeline de démarrage. Vous allez mettre à jour le modèle de pipeline de démarrage.
Étape 5 : créer votre pipeline YAML pour envoyer le travail Azure Machine Learning
Supprimez le pipeline de démarrage et remplacez-le par le code YAML suivant. Dans ce pipeline, vous allez :
- Utiliser la tâche de version de Python pour configurer Python 3.8 et installer les exigences du SDK.
- Utiliser la tâche Bash pour exécuter des scripts bash pour le SDK Azure Machine Learning et l’interface CLI.
- Utilisez la tâche Azure CLI pour envoyer un travail Azure Machine Learning.
Sélectionnez les onglets suivants selon que vous utilisez une connexion de service Azure Resource Manager ou une connexion de service générique. Dans le pipeline YAML, remplacez la valeur des variables par vos ressources.
- Utilisation d’une connexion de service Azure Resource Manager
- Utilisation d’une connexion de service générique
name: submit-azure-machine-learning-job
trigger:
- none
variables:
service-connection: 'machine-learning-connection' # replace with your service connection name
resource-group: 'machinelearning-rg' # replace with your resource group name
workspace: 'docs-ws' # replace with your workspace name
jobs:
- job: SubmitAzureMLJob
displayName: Submit AzureML Job
timeoutInMinutes: 300
pool:
vmImage: ubuntu-latest
steps:
- task: UsePythonVersion@0
displayName: Use Python >=3.8
inputs:
versionSpec: '>=3.8'
- bash: |
set -ex
az version
az extension add -n ml
displayName: 'Add AzureML Extension'
- task: AzureCLI@2
name: submit_azureml_job_task
displayName: Submit AzureML Job Task
inputs:
azureSubscription: $(service-connection)
workingDirectory: 'cli/jobs/pipelines-with-components/nyc_taxi_data_regression'
scriptLocation: inlineScript
scriptType: bash
inlineScript: |
# submit component job and get the run name
job_name=$(az ml job create --file single-job-pipeline.yml -g $(resource-group) -w $(workspace) --query name --output tsv)
# Set output variable for next task
echo "##vso[task.setvariable variable=JOB_NAME;isOutput=true;]$job_name"
Étape 6 : attendre la fin du travail Azure Machine Learning
À l’étape 5, vous avez ajouté un travail pour envoyer un travail Azure Machine Learning. Dans cette étape, vous ajoutez un autre travail qui attend la fin du travail Azure Machine Learning.
- Utilisation d’une connexion de service Azure Resource Manager
- Utilisation d’une connexion de service générique
Si vous utilisez une connexion de service Azure Resource Manager, vous pouvez utiliser l’extension « Machine Learning ». Vous pouvez rechercher cette extension dans la Place de marché des extensions Azure DevOps ou accéder directement à l’extension. Installez l’extension « Machine Learning ».
Important
N’installez pas l’extension Machine Learning (classique) par erreur. Il s’agit d’une extension plus ancienne qui ne fournit pas la même fonctionnalité.
Dans la fenêtre de révision du pipeline, ajoutez un travail de serveur. Dans la partie des étapes du travail, sélectionnez Afficher l’Assistant et recherchez AzureML. Sélectionnez la tâche d’Attente du travail AzureML et renseignez les informations relatives au travail.
La tâche dispose de quatre entrées : Service Connection, Azure Resource Group Name, AzureML Workspace Name et AzureML Job Name. Remplissez ces entrées. Le YAML obtenu pour ces étapes est similaire à l’exemple suivant :
Notes
- La tâche d’attente du travail Azure Machine Learning s’exécute sur un travail de serveur, qui n’utilise aucune ressource coûteuse de pool d’agents et n’exige pas de frais supplémentaires. Les travaux de serveur (indiqués par
pool: server) s’exécutent sur la même machine que votre pipeline. Si vous souhaitez obtenir plus d’informations, consultez Travaux de serveur. - Une tâche d’attente de travail Azure Machine Learning ne peut attendre qu’un seul travail. Vous devez configurer une tâche distincte pour chaque travail pour lequel vous souhaitez attendre.
- La tâche d’attente de travail Azure Machine Learning peut attendre pendant 2 jours au maximum. Il s’agit d’une limite stricte définie par Azure DevOps Pipelines.
- job: WaitForAzureMLJobCompletion
displayName: Wait for AzureML Job Completion
pool: server
timeoutInMinutes: 0
dependsOn: SubmitAzureMLJob
variables:
# We are saving the name of azureMl job submitted in previous step to a variable and it will be used as an inut to the AzureML Job Wait task
azureml_job_name_from_submit_job: $[ dependencies.SubmitAzureMLJob.outputs['submit_azureml_job_task.JOB_NAME'] ]
steps:
- task: AzureMLJobWaitTask@1
inputs:
serviceConnection: $(service-connection)
resourceGroupName: $(resource-group)
azureMLWorkspaceName: $(workspace)
azureMLJobName: $(azureml_job_name_from_submit_job)
Étape 7 : envoyer votre pipeline et vérifier qu’il fonctionne
Sélectionnez Enregistrer et exécuter. Le pipeline attend la fin du travail Azure Machine Learning et termine la tâche sous WaitForJobCompletion avec le même état que le travail Azure Machine Learning. Par exemple : travail Azure Machine Learning Succeeded == Tâche Azure DevOps sous travail WaitForJobCompletionSucceeded travail Azure Machine Learning Failed == Tâche Azure DevOps sous travail WaitForJobCompletionFailed Travail Azure Machine Learning Cancelled == Tâche Azure DevOps sous travailWaitForJobCompletionCancelled
Conseil
Vous pouvez afficher le travail Azure Machine Learning terminé dans Azure Machine Learning studio.
Nettoyer les ressources
Si vous ne prévoyez pas de continuer à utiliser votre pipeline, supprimez votre projet Azure DevOps. Dans le Portail Azure, supprimez votre groupe de ressources et votre instance Azure Machine Learning.