Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
APPLIES TO : Extension Azure ML CLI v2 (actuelle)
Extension Azure ML CLI v2 (actuelle)
Dans cet article, vous allez apprendre à créer et exécuter un pipeline Machine Learning à l’aide d'Azure CLI et les composants. Vous pouvez créer des pipelines sans utiliser de composants, mais les composants offrent une flexibilité et permettent la réutilisation. Les pipelines Azure Machine Learning peuvent être définis dans YAML et s’exécuter à partir de l’interface CLI, créées en Python ou composées dans le Concepteur Azure Machine Learning Studio via une interface utilisateur glisser-déplacer. Cet article se concentre sur l’interface CLI.
Prérequis
Un abonnement Azure. Si vous n’en avez pas, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
Extension Azure CLI pour Machine Learning, installée et configurée.
Clone du référentiel d’exemples. Vous pouvez utiliser ces commandes pour cloner le dépôt :
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Lecture préalable suggérée
- Que sont les pipelines Microsoft Azure Machine Learning ?
- Qu’est-ce qu’un composant Azure Machine Learning ?
Créer votre premier pipeline avec des composants
Tout d’abord, vous allez créer un pipeline avec des composants à l’aide d’un exemple. Cela vous donne une impression initiale de l’apparence d’un pipeline et d’un composant dans Azure Machine Learning.
Dans le répertoire cli/jobs/pipelines-with-components/basics du azureml-examples référentiel, accédez au sous-répertoire 3b_pipeline_with_data. Il existe trois types de fichiers dans ce répertoire. Il s’agit des fichiers que vous devez créer lorsque vous générez votre propre pipeline.
pipeline.yml. Ce fichier YAML définit le pipeline Machine Learning. Il décrit comment découper une tâche d'apprentissage automatique complète en un flux de travail à plusieurs étapes. Par exemple, considérez la tâche d’apprentissage automatique simple de l’utilisation de données historiques pour entraîner un modèle de prévision des ventes. Vous souhaiterez peut-être créer un flux de travail séquentiel qui contient des étapes de traitement des données, d’entraînement de modèle et d’évaluation de modèle. Chaque étape est un composant qui a une interface bien définie et peut être développé, testé et optimisé indépendamment. Le fichier YAML du pipeline définit également comment les sous-étapes se connectent aux autres étapes du pipeline. Par exemple, l’étape d’entraînement du modèle génère un fichier de modèle et le fichier de modèle est passé à une étape d’évaluation du modèle.
component.yml. Ces fichiers YAML définissent les composants. Ils contiennent les informations suivantes :
- Métadonnées : nom, nom complet, version, description, type, et ainsi de suite. Les métadonnées permettent de décrire et de gérer le composant.
- Interface : entrées et sorties. Par exemple, un composant d’entraînement de modèle prend les données d’apprentissage et le nombre d’époques en tant qu’entrée et génère un fichier de modèle entraîné en tant que sortie. Une fois l’interface définie, différentes équipes peuvent développer et tester le composant indépendamment.
- Commande, code et environnement : commande, code et environnement pour exécuter le composant. La commande est la commande shell pour exécuter le composant. Le code fait généralement référence à un répertoire de code source. L’environnement peut être un environnement Azure Machine Learning (organisé ou client créé), une image Docker ou un environnement conda.
component_src. Il s’agit des répertoires de code source pour des composants spécifiques. Ils contiennent le code source exécuté dans le composant. Vous pouvez utiliser votre langage préféré, y compris Python, R et d’autres. Le code doit être exécuté par une commande shell. Le code source peut prendre quelques entrées de la ligne de commande shell pour contrôler la façon dont cette étape est exécutée. Par exemple, une étape de formation peut prendre des données de formation, un taux d’apprentissage et le nombre d’époques pour contrôler le processus de formation. L’argument d’une commande shell permet de transmettre des entrées et des sorties au code.
Vous allez maintenant créer un pipeline à l’aide de l’exemple 3b_pipeline_with_data . Chaque fichier est expliqué plus loin dans les sections suivantes.
Commencez par répertorier vos ressources de calcul disponibles en utilisant la commande suivante :
az ml compute list
Si vous ne l’avez pas, créez un cluster appelé cpu-cluster en exécutant cette commande :
Remarque
Ignorez cette étape pour utiliser le calcul serverless.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Créez maintenant un travail de pipeline défini dans le fichier pipeline.yml en exécutant la commande suivante. La cible de calcul est référencée dans le fichier pipeline.yml en tant que azureml:cpu-cluster. Si votre cible de calcul utilise un autre nom, n’oubliez pas de le mettre à jour dans le fichier pipeline.yml.
az ml job create --file pipeline.yml
Vous devez recevoir un dictionnaire JSON avec des informations sur la tâche de pipeline, notamment :
| Clé | Descriptif |
|---|---|
name |
Le nom du travail basé sur le GUID. |
experiment_name |
Le nom sous lequel les travaux seront organisés dans studio. |
services.Studio.endpoint |
L’URL pour la surveillance et l’examen du travail de pipeline. |
status |
État du travail. Il sera probablement Preparing à ce stade. |
Accédez à l’URL services.Studio.endpoint pour afficher une visualisation du pipeline :
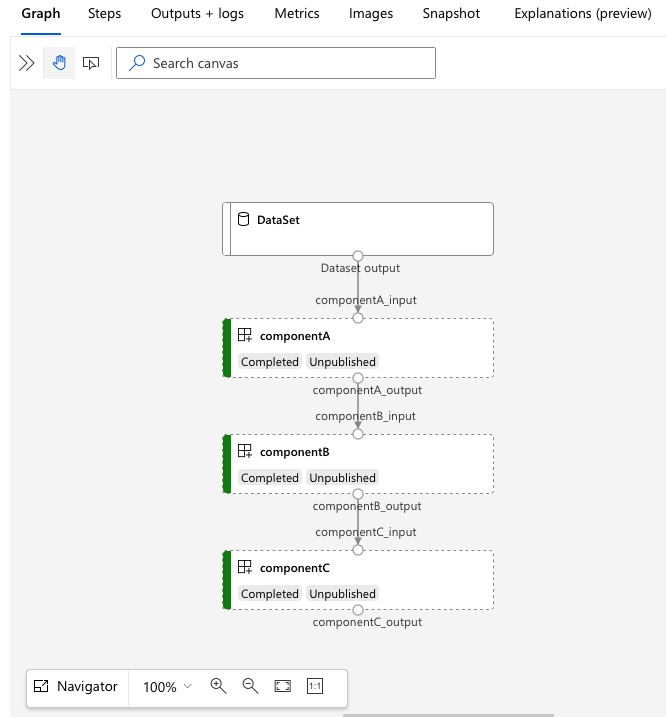
Comprendre le YAML de définition de pipeline
Vous allez maintenant examiner la définition du pipeline dans le fichier 3b_pipeline_with_data/pipeline.yml .
Remarque
Pour utiliser le calcul serverless, remplacez default_compute: azureml:cpu-cluster par default_compute: azureml:serverless dans ce fichier.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
Le tableau suivant décrit les champs les plus couramment utilisés du schéma YAML du pipeline. Pour plus d’informations, consultez le schéma YAML de pipeline complet.
| Clé | Descriptif |
|---|---|
type |
Requis. Le type de tâche. Il doit être pipeline pour les travaux de pipeline. |
display_name |
Le nom complet du travail de pipeline dans l’interface utilisateur de studio. Modifiable dans l’interface utilisateur de Studio. Cela ne doit pas être unique pour tous les travaux dans l’espace de travail. |
jobs |
Requis. Dictionnaire de l’ensemble de travaux individuels à exécuter en tant qu’étapes dans le pipeline. Ces tâches sont considérées comme des tâches enfants du travail de pipeline parent. Dans la version actuelle, les types de travaux pris en charge dans le pipeline sont command et sweep. |
inputs |
Un dictionnaire d’entrées du travail de pipeline. La clé est un nom pour l’entrée dans le contexte du travail et la valeur est la valeur d’entrée. Vous pouvez référencer ces entrées de pipeline par les entrées d'un travail d'étape individuel dans le pipeline en utilisant l'expression ${{ parent.inputs.<input_name> }}. |
outputs |
Un dictionnaire des configurations de sortie du travail de pipeline. La clé est un nom pour la sortie dans le contexte du travail, et la valeur est la configuration de sortie. Vous pouvez référencer ces sorties de pipeline par les sorties d’une tâche d’étape individuelle dans le pipeline à l’aide de l’expression ${{ parents.outputs.<output_name> }} . |
L’exemple 3b_pipeline_with_data contient un pipeline en trois étapes.
- Les trois étapes sont définies sous
jobs. Les trois étapes sont de typecommand. La définition de chaque étape se trouve dans un fichier correspondantcomponent*.yml. Vous pouvez voir les fichiers YAML du composant dans le répertoire 3b_pipeline_with_data .componentA.ymlest décrit dans la section suivante. - Ce pipeline a une dépendance de données, qui est courante dans les pipelines réels. Le composant A prend l’entrée de données d’un dossier local sous
./data(lignes 18-21) et transmet sa sortie au composant B (ligne 29). La sortie du composant A peut être référencée en tant que${{parent.jobs.component_a.outputs.component_a_output}}. -
default_computedéfinit le calcul par défaut du pipeline. Si un composant sousjobsdéfinit un autre calcul, les paramètres spécifiques aux composants sont respectés.

Lire et écrire des données dans un pipeline
Un scénario courant consiste à lire et écrire des données dans un pipeline. Dans Azure Machine Learning, vous utilisez le même schéma pour lire et écrire des données pour tous les types de travaux (travaux de pipeline, travaux de commande et travaux de balayage). Voici des exemples d’utilisation de données dans des pipelines pour des scénarios courants :
- Données locales
- Fichier web avec une URL publique
- magasin de données Azure Machine Learning et chemin d'accès
- Ressources de données Azure Machine Learning
Comprendre le YAML de définition de composant
Voici le fichier componentA.yml , exemple de YAML qui définit un composant :
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Ce tableau définit les champs les plus couramment utilisés du composant YAML. Pour plus d’informations, consultez le schéma YAML de composant complet.
| Clé | Descriptif |
|---|---|
name |
Requis. Nom du composant. Il doit être unique dans l’espace de travail Azure Machine Learning. Il doit commencer par une lettre minuscule. Les lettres minuscules, les chiffres et les traits de soulignement (_) sont autorisés. La longueur maximale est de 255 caractères. |
display_name |
Le nom complet du composant dans l’interface utilisateur de Studio. Il n’est pas obligé d’être unique dans l’espace de travail. |
command |
Requis. La commande à exécuter. |
code |
Chemin d’accès local au répertoire de code source à charger et utiliser pour le composant. |
environment |
Requis. Environnement utilisé pour exécuter le composant. |
inputs |
Dictionnaire des entrées de composant. La clé est un nom pour l’entrée dans le contexte du composant, et la valeur est la définition d’entrée du composant. Vous pouvez référencer des entrées dans la commande à l’aide de l’expression ${{ inputs.<input_name> }} . |
outputs |
Dictionnaire de sorties de composant. La clé est un nom pour la sortie dans le contexte du composant, et la valeur est la définition de sortie du composant. Vous pouvez référencer des sorties dans la commande à l’aide de l’expression ${{ outputs.<output_name> }} . |
is_deterministic |
Indique s’il faut réutiliser le résultat du travail précédent si les entrées du composant ne changent pas. La valeur par défaut est true. Ce paramètre est également appelé réutilisation par défaut. Le scénario courant lorsqu’il est défini false est de forcer le rechargement des données à partir du stockage cloud ou d’une URL. |
Dans l’exemple de 3b_pipeline_with_data/componentA.yml, le composant A a une entrée de données et une sortie de données, qui peuvent être connectées à d’autres étapes du pipeline parent. Tous les fichiers de la code section du composant YAML sont chargés dans Azure Machine Learning lorsque la tâche de pipeline est envoyée. Dans cet exemple, les fichiers sous ./componentA_src seront chargés. (Ligne 16 dans componentA.yml.) Vous pouvez voir le code source chargé dans l’interface utilisateur studio : double-cliquez sur l’étape componentA dans le graphique et accédez à l’onglet Code , comme illustré dans la capture d’écran suivante. Vous pouvez voir qu'il s'agit d'un script "hello-world" qui effectue une opération d'impression simple et qu'il écrit la date et l'heure actuelles dans le chemin componentA_output. Le composant prend l’entrée et fournit une sortie via la ligne de commande. Il est géré dans hello.py via argparse.

Entrée et sortie
L’entrée et la sortie définissent l’interface d’un composant. L’entrée et la sortie peuvent être des valeurs littérales (de type string, numberou integer) ou booleanun objet qui contient un schéma d’entrée.
L’entrée d’objet (de type uri_file, , uri_foldermltable, mlflow_modelou custom_model) peut se connecter à d’autres étapes du travail de pipeline parent pour passer des données/modèles à d’autres étapes. Dans le graphique de pipeline, l’entrée de type objet s’affiche en tant que point de connexion.
Les entrées de valeur littérale (string, , numberinteger, boolean) sont les paramètres que vous pouvez passer au composant au moment de l’exécution. Vous pouvez ajouter une valeur par défaut d’entrées littérales dans le default champ. Pour les types number et integer, vous pouvez également ajouter des valeurs minimales et maximales à l’aide des champs min et max. Si la valeur d’entrée est inférieure à la valeur minimale ou supérieure à la valeur maximale, le pipeline échoue à la validation. La validation se produit avant d’envoyer un travail de pipeline, ce qui peut gagner du temps. La validation fonctionne pour l’interface CLI, le Kit de développement logiciel (SDK) Python et l’interface utilisateur du concepteur. La capture d’écran suivante montre un exemple de validation dans l’interface utilisateur du concepteur. De même, vous pouvez définir des valeurs autorisées dans des enum champs.

Si vous souhaitez ajouter une entrée à un composant, vous devez apporter des modifications à trois emplacements :
- Champ
inputsdu composant YAML. - Champ
commanddu composant YAML. - Dans le code source du composant, pour traiter les entrées de la ligne de commande.
Ces emplacements sont marqués avec des zones vertes dans la capture d’écran précédente.
Pour en savoir plus sur les entrées et sorties, consultez Gérer les entrées et sorties pour les composants et les pipelines.
Environnements
L’environnement est l’environnement dans lequel le composant s’exécute. Ce pourrait être un environnement Azure Machine Learning (organisé ou inscrit par le client), une image Docker ou un environnement conda. Consultez les exemples suivants :
-
Ressource d’environnement Azure Machine Learning inscrite. L’environnement est référencé dans le composant avec la syntaxe
azureml:<environment-name>:<environment-version>. - Image Docker publique.
- Fichier Conda. Le fichier conda doit être utilisé avec une image de base.
Inscrire un composant pour la réutilisation et le partage
Bien que certains composants soient spécifiques à un pipeline particulier, l’avantage réel des composants provient de la réutilisation et du partage. Vous pouvez inscrire un composant dans votre espace de travail Machine Learning pour le rendre disponible à des fins de réutilisation. Les composants inscrits prennent en charge le contrôle de version automatique afin de pouvoir mettre à jour le composant, mais assurez-vous que les pipelines qui nécessitent une version antérieure continueront de fonctionner.
Dans le référentiel azureml-examples, accédez au cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components répertoire.
Pour inscrire un composant, utilisez la commande az ml component create :
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Une fois ces commandes exécutées jusqu’à la fin, vous pouvez voir les composants dans Studio, sous Composants de ressources> :

Sélectionnez un composant. Vous voyez des informations détaillées pour chaque version du composant.
L’onglet Détails affiche des informations de base telles que le nom du composant, qui l’a créée et la version. Il existe des champs modifiables pour les balises et la description. Vous pouvez utiliser des balises pour ajouter des mots clés de recherche. Le champ description prend en charge la mise en forme Markdown. Vous devez l’utiliser pour décrire les fonctionnalités et l’utilisation de base de votre composant.
Sous l’onglet Travaux , vous voyez l’historique de tous les travaux qui utilisent le composant.
Utiliser des composants inscrits dans un fichier YAML de travail de pipeline
Vous allez maintenant utiliser 1b_e2e_registered_components comme exemple d’utilisation d’un composant inscrit dans YAML de pipeline. Accédez au 1b_e2e_registered_components répertoire et ouvrez le pipeline.yml fichier. Les clés et les valeurs des champs inputs et outputs sont similaires à celles déjà traitées. La seule différence significative réside dans les valeurs du champ component dans les entrées jobs.<job_name>.component. La component valeur est au format azureml:<component_name>:<component_version>. La train-job définition, par exemple, spécifie que la dernière version du composant my_train inscrit doit être utilisée :
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Gérer les composants
Vous pouvez vérifier les détails du composant et gérer les composants à l’aide de l’interface CLI v2. Utilisez az ml component -h pour obtenir des instructions détaillées sur les commandes de composant. Le tableau suivant répertorie toutes les commandes disponibles. Pour plus d’exemples, consultez Référence Azure CLI.
| Commande | Descriptif |
|---|---|
az ml component create |
Créer un composant. |
az ml component list |
Répertoriez les composants d’un espace de travail. |
az ml component show |
Afficher les détails d’un composant. |
az ml component update |
Mettre à jour un composant Seuls quelques champs (description, display_name) prennent en charge la mise à jour. |
az ml component archive |
Archivez un conteneur de composants. |
az ml component restore |
Restaurer un composant archivé. |
Étape suivante
- Essayez l’exemple de composant CLI v2