Configurer un projet d’étiquetage d’images
Découvrez comment créer et exécuter des projets d’étiquetage des données de façon à étiqueter des images dans Azure Machine Learning. Utilisez l’étiquetage des données assisté par machine learning (ML) ou l’étiquetage avec humain dans la boucle pour faciliter la tâche.
Configurez des étiquettes pour la classification, la détection d’objets (cadre englobant), la segmentation d’instance (polygone) ou la segmentation sémantique (préversion).
Vous pouvez également utiliser l’outil d’étiquetage des données dans Azure Machine Learning pour créer un projet d’étiquetage de texte.
Important
Les éléments marqués (préversion) dans cet article sont actuellement en préversion publique. La préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail en production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Fonctionnalités d’étiquetage des images
L’étiquetage des données Azure Machine Learning est un outil dont vous pouvez vous servir pour créer, gérer et superviser les projets d’étiquetage des données. Utilisez-le pour :
- Coordonnez les données, les étiquettes et les membres de l’équipe pour gérer efficacement les tâches d’étiquetage.
- Suivez la progression et gérez la file d’attente des tâches d’étiquetage incomplètes.
- Démarrez et arrêtez le projet pour contrôler la progression de l’étiquetage.
- Passez en revue les données étiquetées et exportez-les en tant que jeu de données Azure Machine Learning.
Important
Les images de données dont vous sous servez dans l’outil d’étiquetage des données Azure Machine Learning doivent être disponibles dans un magasin de données Stockage Blob Azure. Si vous ne disposez pas de magasin de données, vous pouvez charger vos fichiers de données dans un nouveau magasin de données lors de la création du projet.
Les données image peuvent être n’importe quel fichier avec l’une des extensions de fichier suivantes :
.jpg.jpeg.png.jpe.jfif.bmp.tif.tiff.dcm.dicom
Chaque fichier est un élément à étiqueter.
Vous pouvez également utiliser une ressource de données MLTable comme entrée dans un projet d’étiquetage d’images, tant que le format des images du tableau correspond à ceux indiqués ci-dessus. Pour découvrir plus d’informations, consultez Comment utiliser des ressources de données MLTable.
Prérequis
Vous employez ces éléments pour configurer l’étiquetage des images dans Azure Machine Learning :
- Les données à étiqueter, dans des fichiers locaux ou un stockage Blob Azure.
- L’ensemble d’étiquettes à appliquer.
- Des instructions pour l’étiquetage.
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Un espace de travail Azure Machine Learning. Consultez Créer un espace de travail Microsoft Azure Machine Learning.
Créer un projet d’étiquetage d’images
Les projets d’étiquetage sont administrés dans Azure Machine Learning. Pour la gestion de vos projets, utilisez la page Étiquetage des données dans Machine Learning.
Si vos données se trouvent déjà dans le Stockage Blob Azure, assurez-vous qu’elles sont disponibles sous la forme d’un magasin de données avant de créer le projet d’étiquetage.
Pour créer un projet, sélectionnez Ajouter un projet.
Pour Nom du projet, entrez un nom pour le projet.
Vous ne pouvez pas réutiliser le nom du projet, même après la suppression du projet.
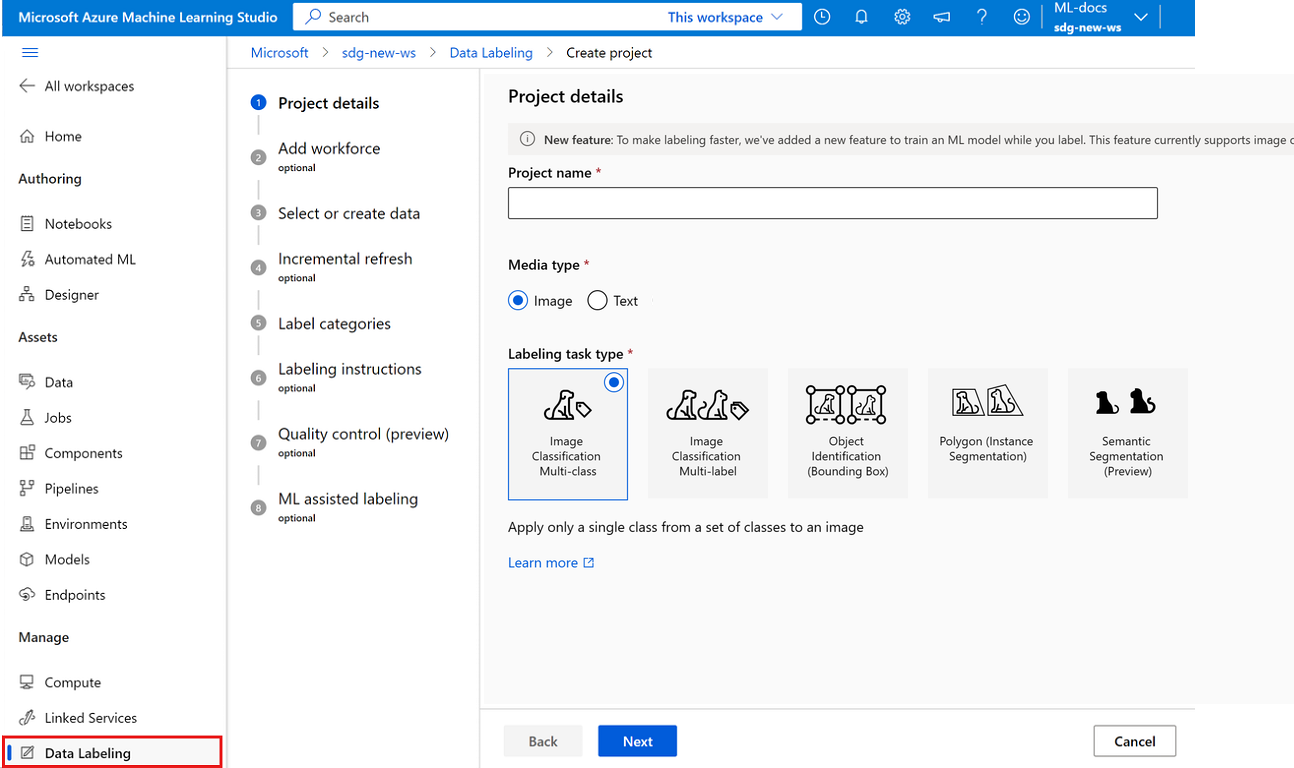
Pour créer un projet d’étiquetage d’image, pour Type de média, choisissez Image.
Pour Type de tâche d’étiquetage, choisissez une option pour votre scénario :
- Pour appliquer une unique étiquette à une image depuis un ensemble d’étiquettes, choisissez Classification d’images à plusieurs classes.
- Pour appliquer une ou plusieurs étiquettes à une image depuis un ensemble d’étiquettes, sélectionnez Classification d’images à plusieurs étiquettes. Par exemple, vous pouvez étiqueter la photo d’un chien avec dog (chien) et daytime (jour).
- Pour affecter une étiquette à chaque objet dans une image et ajouter des cadres englobants, choisissez Identification de l’objet (cadre englobant).
- Pour affecter une étiquette à chaque objet dans une image et dessiner un polygone autour de chaque objet, sélectionnez Polygone (Segmentation d’instance).
- Pour dessiner des masques sur une image et affecter une classe d’étiquette au niveau du pixel, sélectionnez Segmentation sémantique (préversion).
Sélectionnez Suivant pour continuer.
Ajouter du personnel (facultatif)
Ne sélectionnez utiliser une société d’étiquetage des fournisseurs de la Place de marché Azure que si vous avez engagé une société d’étiquetage des données à partir de la Place de marché Azure. Sélectionnez ensuite le fournisseur. Si votre fournisseur ne figure pas dans la liste, effacez cette option.
Assurez-vous au préalable de contacter le fournisseur et de signer un contrat. Pour plus d’informations, consultez Utiliser une société d’étiquetage de données (préversion).
Sélectionnez Suivant pour continuer.
Spécifier les données à étiqueter
Si vous avez déjà créé un jeu de données qui contient vos données, sélectionnez le jeu de données dans la liste déroulante Sélectionner un jeu de données existant.
Vous pouvez aussi choisir Créer un jeu de données pour utiliser un magasin de données Azure existant ou pour charger des fichiers locaux.
Notes
Un projet ne peut contenir plus de 500 000 fichiers. Si votre jeu de données est supérieur à ce nombre de fichiers, seuls les 500 000 premiers fichiers sont chargés.
Mappage de colonnes de données (préversion)
Si vous sélectionnez une ressource de données MLTable, une autre étape intitulée Mappage des colonnes de données apparaît pour vous permettre de spécifier la colonne qui contient les URL d’images.
Vous devez spécifier une colonne qui est mappée au champ Image. Vous pouvez également mapper d’autres colonnes présentes dans les données. Par exemple, si vos données contiennent une colonne Étiquette, vous pouvez la mapper au champ Catégorie. Si vos données contiennent une colonne Confiance, vous pouvez la mapper au champ Confiance.
Si vous importez des étiquettes à partir d’un projet précédent, elles doivent être au même format que celles que vous créez. Par exemple, si vous créez des étiquettes de cadre englobant, les étiquettes importées doivent être de même nature.
Options d’importation (préversion)
Lorsque vous incluez une colonne Catégorie à l’étape Mappage des colonnes de données, utilisez Options d’importation pour spécifier comment traiter les données étiquetées.
Vous devez spécifier une colonne à mapper au champ Image. Vous pouvez également mapper d’autres colonnes présentes dans les données. Par exemple, si vos données contiennent une colonne Étiquette, vous pouvez la mapper au champ Catégorie. Si vos données contiennent une colonne Confiance, vous pouvez la mapper au champ Confiance.
Si vous importez des étiquettes à partir d’un projet précédent, elles doivent être au même format que celles que vous créez. Par exemple, si vous créez des étiquettes de cadre englobant, les étiquettes importées doivent être de même nature.
Créer un jeu de données à partir d’un magasin de données Azure
Dans de nombreux cas, vous pouvez charger des fichiers locaux. Cependant, l’Explorateur Stockage Azure constitue un moyen plus rapide et plus robuste de transférer une grande quantité de données. Nous recommandons l’Explorateur Stockage en tant que méthode par défaut pour déplacer des fichiers.
Pour créer un jeu de données à partir de données que vous avez déjà stockées dans le Stockage Blob :
- Sélectionnez Create (Créer).
- Pour Nom, indiquez un nom pour votre jeu de données. Si vous le souhaitez, entrez une description.
- Assurez-vous que le type de jeu de données est défini sur Fichier. Seuls les jeux de données de type fichier sont pris en charge pour les images.
- Sélectionnez Suivant.
- Choisissez À partir du stockage Azure, puis Suivant.
- Sélectionnez le magasin de données, ensuite Suivant.
- Si vos données sont dans un sous-dossier de votre Stockage Blob, choisissez Parcourir pour sélectionner le chemin d'accès.
- Pour inclure tous les fichiers des sous-dossiers du chemin d'accès sélectionné, ajoutez
/**au chemin d'accès. - Pour inclure toutes les données figurant dans le conteneur actuel et ses sous-dossiers, ajoutez
**/*.*au chemin d'accès.
- Pour inclure tous les fichiers des sous-dossiers du chemin d'accès sélectionné, ajoutez
- Sélectionnez Create (Créer).
- Sélectionnez la ressource de données que vous avez créée.
Créer un jeu de données à partir des données chargées
Pour charger directement vos données :
- Sélectionnez Create (Créer).
- Pour Nom, indiquez un nom pour votre jeu de données. Si vous le souhaitez, entrez une description.
- Assurez-vous que le type de jeu de données est défini sur Fichier. Seuls les jeux de données de type fichier sont pris en charge pour les images.
- Sélectionnez Suivant.
- Sélectionnez À partir de fichiers locaux, ensuite Suivant.
- (Facultatif) Sélectionnez un magasin de données. Vous pouvez également garder la sélection par défaut pour charger dans le magasin blob par défaut (workspaceblobstore) de votre espace de travail Machine Learning.
- Sélectionnez Suivant.
- Choisissez Charger > Charger des fichiers ou Charger>Charger un dossier pour sélectionner les fichiers ou dossiers locaux à charger.
- Dans la fenêtre du navigateur, retrouvez vos fichiers ou dossiers, ensuite sélectionnez Ouvrir.
- Continuez à sélectionner Charger jusqu’à spécifier tous vos fichiers et dossiers.
- Au besoin, vous pouvez cocher la case Remplacer s’il existe déjà. Vérifiez la liste des fichiers et des dossiers.
- Sélectionnez Suivant.
- Vérifiez les détails. Sélectionnez Précédent pour modifier les paramètres, ou choisissez Créer pour créer le jeu de données.
- Enfin, sélectionnez la ressource de données que vous avez créée.
Configurer une actualisation incrémentielle
Si vous envisagez d’ajouter de nouveaux fichiers de données à votre jeu de données, utilisez l’actualisation incrémentielle pour ajouter les fichiers à votre projet.
Quand Activer l’actualisation incrémentielle à intervalles réguliers est défini, des recherches sont régulièrement effectuées dans le jeu de données pour que de nouveaux fichiers soient ajoutés à un projet, en fonction du taux de progression de l’étiquetage. La recherche de nouvelles données s’arrête quand le projet contient le nombre maximal de 500 000 fichiers.
Sélectionnez Activer l’actualisation incrémentielle à intervalles réguliers quand vous souhaitez que votre projet supervise en continu les nouvelles données dans le magasin de données.
Effacez la sélection si vous ne voulez pas que les nouveaux fichiers du magasin de données soient ajoutés automatiquement à votre projet.
Important
Lorsque vous activez l’actualisation incrémentielle, ne créez pas de nouvelle version pour le jeu de données que vous souhaitez mettre à jour. Si vous le faites, les mises à jour ne vont pas être visibles, parce que le projet d’étiquetage des données est rattaché à la version initiale. Utilisez plutôt l’Explorateur Stockage Azure pour modifier vos données dans le dossier approprié du Stockage Blob.
Par ailleurs, ne supprimez pas de données. La suppression de données du jeu de données utilisé par votre projet va provoquer une erreur dans le projet.
Une fois le projet créé, utilisez l’onglet Détails pour modifier l’actualisation incrémentielle, afficher l’horodatage de la dernière actualisation et demander une actualisation immédiate des données.
Spécifier des classes d’étiquettes
À la page Catégories d’étiquettes, indiquez un ensemble des classes permettant de catégoriser vos données.
La précision et la vitesse de vos étiqueteurs dépendent de leur capacité à choisir entre les classes. Par exemple, au lieu d’indiquer le genre et l’espèce complets de plantes ou d’animaux, utilisez un code de champ ou abrégez le genre.
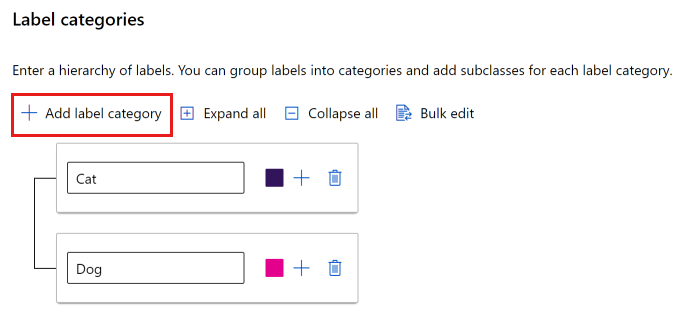
Vous pouvez utiliser une liste plate ou créer des groupes d’étiquettes.
Pour créer une liste plate, sélectionnez Ajouter une catégorie d’étiquette pour créer chaque étiquette.
Pour créer des étiquettes dans des groupes différents, sélectionnez Ajouter une catégorie d’étiquette pour créer les étiquettes de premier niveau. Sélectionnez ensuite le signe plus + sous chaque premier niveau pour créer le niveau suivant d’étiquettes pour cette catégorie. Vous pouvez créer jusqu’à six niveaux dans chaque groupe.
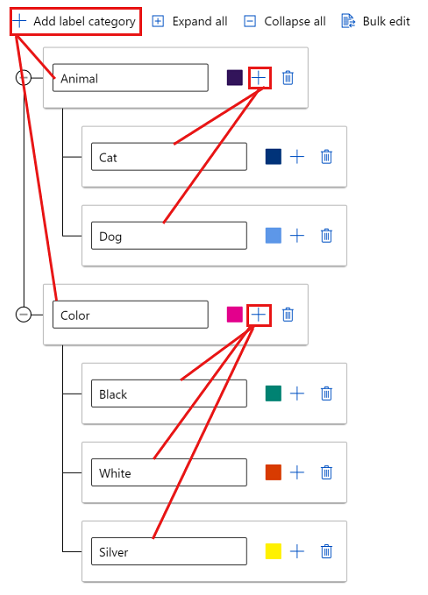
Vous pouvez sélectionner des étiquettes à tous les niveaux pendant le processus d’étiquetage. Par exemple, les étiquettes Animal, Animal/Cat, Animal/Dog, Color, Color/Black, Color/White et Color/Silver sont toutes des choix possibles pour une étiquette. Dans un projet à plusieurs étiquettes, il n’est pas nécessaire de choisir une étiquette de chaque catégorie. Si c’est votre intention, veillez à inclure cette information dans vos instructions.
Décrire la tâche d’étiquetage d’image
Il est important d’expliquer clairement la tâche d’étiquetage. Dans la page Instructions d’étiquetage, vous pouvez soit ajouter un lien vers un site externe contenant des instructions d’étiquetage, soit fournir des instructions dans la zone d’édition de la page. Veillez à ce que les instructions soient axées sur la tâche et appropriées pour le public. Prenez en compte les questions suivantes :
- Quelles sont les étiquettes que les étiqueteurs vont voir, et comment vont-ils entre celles-ci ? Existe-t-il un texte de référence à consulter ?
- Que doivent-ils faire si aucune étiquette ne semble appropriée ?
- Que doivent-ils faire si plusieurs étiquettes semblent appropriées ?
- Quel seuil de confiance doivent-ils appliquer à une étiquette ? Voulez-vous la meilleure approximation de l'étiqueteur s'il n'est pas certain ?
- Que doivent-ils faire avec des objets partiellement masqués ou qui se chevauchent ?
- Que doivent-ils faire si un objet est coupé par le bord de l’image ?
- Que doivent-ils faire après avoir soumis une étiquette, s'ils estiment s'être trompés ?
- Que doivent-ils faire, s’ils découvrent des problèmes liés à la qualité de l’image, notamment des conditions d’éclairage médiocres, des reflets, une perte de focus, un arrière-plan indésirable inclus, des angles de photo anormaux, etc. ?
- Que doivent-ils faire, si plusieurs réviseurs ont des opinions différentes sur l’application d’une étiquette ?
Pour les cadres englobants, les questions importantes sont les suivantes :
- Comment le rectangle englobant est-il défini pour cette tâche ? Est-ce que cela doit rester entièrement dans les objets, ou être à l’extérieur ? Doivent-ils être rognés le plus fidèlement possible, ou une certaine approximation est-elle acceptable ?
- Quel niveau de soin et de cohérence attendez-vous des étiqueteurs dans la définition des cadres englobants ?
- Quelle est la définition visuelle de chaque classe d’étiquette ? Pourriez-vous fournir une liste de cas normaux, périphériques et de compteur pour chaque classe ?
- Que doivent faire les étiqueteurs si l’objet est petit ? Doit-il être étiqueté comme objet ou être ignoré en tant qu’arrière-plan ?
- Comment les étiqueteurs doivent-ils gérer un objet qui n’est que partiellement affiché dans l’image ?
- Comment les étiqueteurs doivent-ils gérer un objet qui est partiellement couvert par un autre objet ?
- Comment les étiqueteurs doivent-ils gérer un objet qui n’a pas de limite claire ?
- Comment les étiqueteurs doivent-ils gérer un objet qui n’est pas dans la classe d’objets d’intérêt, mais présente des similitudes visuelles avec un type d’objet pertinent ?
Notes
Les étiqueteurs peuvent choisir les neuf premières étiquettes à l’aide des touches numériques 1 à 9. Il est possible que vous souhaitiez inclure cette information dans vos instructions.
Contrôle qualité (préversion)
Pour obtenir des étiquettes plus précises, accédez à la page Contrôle qualité pour envoyer chaque élément à plusieurs étiqueteurs.
Important
L’étiquetage de consensus est actuellement en préversion publique.
La préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail en production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Pour que chaque élément soit envoyé à plusieurs étiqueteurs, sélectionnez Activer l’étiquetage par consensus (préversion). Ensuite, définissez les valeurs du Nombre minimal d’étiqueteurs et du Nombre maximal d’étiqueteurs pour indique combien d’étiqueteurs utiliser. Assurez-vous de disposer d'autant d'étiqueteuses que votre nombre maximum. Vous ne pouvez plus modifier ces paramètres une fois le projet démarré.
Si un consensus est atteint à partir du nombre minimal d’étiqueteurs, l’élément est étiqueté. Dans le cas où aucun consensus n’est atteint, l’élément est envoyé à plus d’étiqueteurs. En l’absence de consensus, une fois que l’élément a atteint le nombre maximal d’étiqueteurs, son état devient Nécessite un avis ; le propriétaire du projet est alors responsable de l’étiquetage de l’élément.
Notes
Les projets de segmentation d’instance ne peuvent pas utiliser l’étiquetage par consensus.
Utiliser l’étiquetage des données assisté par ML
Sur la page Étiquetage assisté par ML vous permet de déclencher des modèles automatiques de Machine Learning pour accélérer les tâches d’étiquetage. Les images médicales (fichiers avec une extension .dcm) ne sont pas incluses dans l’étiquetage assisté. Si le type de projet est segmentation sémantique (préversion), l’étiquetage assisté par ML n’est pas disponible.
Au début de votre projet d’étiquetage, les éléments sont mélangés dans un ordre aléatoire pour réduire le biais potentiel. Le modèle formé reflète toutefois tous les biais présents dans le jeu de données. Par exemple, si 80 pour cent de vos éléments appartiennent à une unique classe, environ 80 pour cent des données utilisées pour effectuer l'apprentissage du modèle feront partie de cette classe.
Choisissez Activer l’étiquetage assisté par ML et indiquez un GPU pour activer l’étiquetage assisté. Si votre espace de travail ne contient pas de GPU, un cluster de GPU (nom de ressource : DefLabelNC6v3, taille de VM : Standard_NC6s_v3) est créé pour vous, puis ajouté à votre espace de travail. Le cluster est créé avec un minimum de zéro nœud, ce qui signifie qu’il ne coûte rien quand il n’est pas utilisé.
L’étiquetage ML est constitué de deux phases :
- Clustering
- Préétiquetage
Le nombre d’éléments de données étiquetés requis pour le démarrage de l’étiquetage assisté n’est pas un nombre défini. Ce nombre peut varier considérablement d’un projet d’étiquetage à un autre. Pour certains projets, il est parfois possible de voir des tâches de pré-étiquetage ou de cluster après l’étiquetage manuel de 300 éléments. L’étiquetage assisté par ML se sert d’une technique appelée apprentissage par transfert. L’apprentissage de transfert utilise un modèle pré-entraîné pour lancer le processus d’apprentissage. Si les classes de votre jeu de données ressemblent aux classes du modèle pré-entraîné, les pré-étiquettes peuvent être disponibles après l’étiquetage manuel de quelques centaines d’éléments étiquetés seulement. Si votre jeu de données diffère considérablement des données utilisées pour pré-entraîner le modèle, le processus peut prendre plus de temps.
Dans le cadre de l’étiquetage par consensus, l’étiquette de consensus est utilisée pour l’apprentissage.
Dans la mesure où les étiquettes finales dépendent encore de l’entrée de l’étiqueteur, cette technologie est parfois appelée étiquetage avec humain dans la boucle.
Notes
L’étiquetage des données assisté par ML ne prend pas en charge les comptes de stockage par défaut qui sont sécurisés derrière un réseau virtuel. Vous devez utiliser un compte de stockage différent de celui par défaut pour l’étiquetage des données assisté par ML. Le compte de stockage autre que celui par défaut peut être sécurisé derrière le réseau virtuel.
Clustering
Après l’envoi de quelques étiquettes, le modèle de classification commence à regrouper les éléments similaires. Ces images similaires sont montrées aux étiqueteurs sur la même page pour améliorer l’efficacité de l’étiquetage manuel. Le clustering est particulièrement utile lorsqu’un étiqueteur affiche une grille de quatre, six ou neuf images.
Après l’apprentissage du modèle Machine Learning avec vos données étiquetées manuellement, le modèle est tronqué à sa dernière couche entièrement connectée. Les images non étiquetées transitent ensuite par le modèle tronqué dans un processus appelé incorporation ou caractérisation. Ce processus incorpore chaque image dans un espace à haute dimension que la couche de modèle définit. D’autres images dans l’espace le plus proche de l’image sont utilisées pour les tâches de clustering.
La phase de clustering n’apparaît pas pour les modèles de détection d’objets, ni pour la classification de texte.
Préétiquetage
Lorsque vous avez soumis suffisamment d’étiquettes pour l’apprentissage, un modèle de classification détermine les étiquettes ou un modèle de détection d’objets détermine les cadres englobants. L’étiqueteur voit dès lors les pages qui contiennent les étiquettes prédites déjà présentes dans chaque élément. Pour la détection d’objets, des zones prédites sont également affichées. La tâche implique la révision de ces prédictions et la correction de toutes les images mal étiquetées, avant l’envoi de la page.
Après la formation d’un modèle Machine Learning avec vos données étiquetées manuellement, le modèle est évalué sur un ensemble de tests des éléments étiquetés manuellement. L’évaluation permet de connaître la précision du modèle à différents seuils de confiance. Le processus d’évaluation établit le seuil de confiance au-delà duquel le modèle est suffisamment précis pour afficher des pré-étiquettes. Le modèle est ensuite évalué par rapport aux données non étiquetées. Les éléments dont les prédictions sont plus fiables que le seuil sont utilisés pour le pré-étiquetage.
Initialiser le projet d’étiquetage d’image
Une fois le projet d’étiquetage initialisé, certains de ses aspects sont non modifiables. Vous ne pouvez pas changer le type de tâche ou le jeu de données. Vous pouvez modifier les étiquettes et l’URL de la description de la tâche. Passez en revue attentivement les paramètres avant de créer le projet. Après avoir envoyé le projet, vous revenez à la page vue d’ensemble de l’étiquetage des données, qui affiche le projet comme En cours d’initialisation.
Remarque
L’actualisation automatique de cette page n’est pas possible. Après une pause, actualisez manuellement la page pour que l’état du projet indique Créé.
Dépannage
Si vous rencontrez des problèmes liés à la création d’un projet ou à l’accès aux données, consultez Résoudre les problèmes d’étiquetage des données.