Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Dans Azure Machine Learning, vous pouvez utiliser la surveillance des modèles pour suivre en continu les performances des modèles Machine Learning en production. La surveillance des modèles vous offre une vue étendue des signaux de surveillance. Il vous avertit également des problèmes potentiels. Lorsque vous surveillez les signaux et les métriques de performances des modèles en production, vous pouvez évaluer de manière critique les risques inhérents à vos modèles. Vous pouvez également identifier les taches aveugles susceptibles d’affecter votre entreprise.
Dans cet article, vous voyez comment effectuer les tâches suivantes :
- Configurer une surveillance prête à l’emploi et avancée pour les modèles déployés sur des points de terminaison en ligne Azure Machine Learning
- Analyser les métriques des performances pour les modèles en production
- Surveiller les modèles déployés en dehors d’Azure Machine Learning ou sur des points de terminaison en lots Azure Machine Learning
- Configurer des signaux et des métriques personnalisés à utiliser dans la surveillance des modèles
- Interpréter les résultats de la surveillance
- Intégrer la surveillance des modèles Azure Machine Learning à Azure Event Grid
Prérequis
Azure CLI et l’extension
mld’Azure CLI, installées et configurées. Pour plus d’informations, consultez Installer et configurer l’interface CLI (v2).Un interpréteur de commandes Bash ou un interpréteur de commandes compatible, par exemple, un interpréteur de commandes sur un système Linux ou un sous-système Windows pour Linux. Les exemples Azure CLI de cet article supposent que vous utilisez ce type d’interpréteur de commandes.
Un espace de travail Azure Machine Learning. Pour obtenir des instructions sur la création d’un espace de travail, consultez Configurer.
Un compte d’utilisateur qui a au moins l’un des rôles de contrôle d’accès en fonction du rôle Azure (Azure RBAC) suivants :
- Rôle propriétaire de l’espace de travail Azure Machine Learning
- Rôle Contributeur pour l’espace de travail Azure Machine Learning
- Rôle personnalisé disposant d’autorisations
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*
Pour plus d’informations, consultez Gérer l’accès aux espaces de travail Azure Machine Learning.
Pour surveiller un point de terminaison en ligne managé Azure Machine Learning ou un point de terminaison en ligne Kubernetes :
Modèle déployé sur le point de terminaison en ligne Azure Machine Learning. Les points de terminaison en ligne managés et les points de terminaison en ligne Kubernetes sont pris en charge. Pour obtenir des instructions sur le déploiement d’un modèle sur un point de terminaison en ligne Azure Machine Learning, consultez Déployer et noter un modèle Machine Learning à l’aide d’un point de terminaison en ligne.
Collecte de données activée pour votre déploiement de modèle. Vous pouvez activer la collecte de données pendant l’étape de déploiement pour les points de terminaison en ligne Azure Machine Learning. Pour plus d’informations, consultez Collecter des données de production à partir de modèles déployés pour l’inférence en temps réel.
Pour surveiller un modèle déployé sur un point de terminaison de lot Azure Machine Learning ou déployé en dehors d’Azure Machine Learning :
- Un moyen de collecter des données de production et de l’inscrire en tant que ressource de données Azure Machine Learning
- Un moyen de mettre à jour la ressource de données inscrite en continu pour la surveillance du modèle
- (Recommandé) Inscription du modèle dans un espace de travail Azure Machine Learning, pour le suivi de traçabilité
Configurer un pool de calcul Spark sans serveur
Les travaux de surveillance des modèles sont planifiés pour s’exécuter sur des pools de calcul Spark serverless. Les types d’instances de machines virtuelles Azure suivants sont pris en charge :
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
Pour spécifier un type d’instance de machine virtuelle lorsque vous suivez les procédures décrites dans cet article, procédez comme suit :
Lorsque vous utilisez Azure CLI pour créer un moniteur, vous utilisez un fichier de configuration YAML. Dans ce fichier, définissez la valeur create_monitor.compute.instance_type sur le type que vous souhaitez utiliser.
Configurer la supervision des modèles prêtes à l’emploi
Envisagez un scénario dans lequel vous déployez votre modèle en production dans un point de terminaison en ligne Azure Machine Learning et activez la collecte de données au moment du déploiement. Dans ce cas, Azure Machine Learning collecte les données d’inférence de production et les stocke automatiquement dans stockage Blob Azure. Vous pouvez utiliser la surveillance des modèles Azure Machine Learning pour surveiller en continu ces données d’inférence de production.
Vous pouvez utiliser l’interface Azure CLI, le SDK Python ou le studio pour une configuration prête à l’emploi de la surveillance des modèles. La configuration de la surveillance des modèles prête à l’emploi fournit les fonctionnalités de surveillance suivantes :
- Azure Machine Learning détecte automatiquement la ressource de données d’inférence de production associée à un déploiement en ligne Azure Machine Learning et utilise la ressource de données pour la surveillance du modèle.
- La ressource de données de référence de comparaison est définie comme ressource de données d’inférence de production récente et passée.
- La configuration de la supervision inclut et suit automatiquement les signaux de surveillance intégrés suivants : dérive de données, dérive de prédiction et qualité des données. Pour chaque signal de supervision, Azure Machine Learning utilise :
- La ressource de données d’inférence de production récente et passée comme ressource de données de référence de comparaison.
- Valeurs par défaut intelligentes pour les métriques et les seuils.
- Un travail de surveillance est configuré pour s’exécuter selon une planification régulière. Ce travail acquiert des signaux de surveillance et évalue chaque résultat de métrique par rapport à son seuil correspondant. Par défaut, quand un seuil est dépassé, Azure Machine Learning envoie un e-mail d’alerte à l’utilisateur qui a configuré le moniteur.
Pour configurer la surveillance des modèles prêts à l’emploi, procédez comme suit.
Dans Azure CLI, vous utilisez az ml schedule pour planifier un travail de surveillance.
Créez une définition de surveillance dans un fichier YAML. Pour obtenir un exemple de définition prête à l’emploi, consultez le code YAML suivant, qui est également disponible dans le référentiel azureml-examples.
Avant d’utiliser cette définition, ajustez les valeurs pour qu’elles correspondent à votre environnement. Pour
endpoint_deployment_id, utilisez une valeur au formatazureml:<endpoint-name>:<deployment-name>.# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.comExécutez la commande suivante pour créer le modèle :
az ml schedule create -f ./out-of-box-monitoring.yaml


Configurer la supervision de modèle avancée
Azure Machine Learning fournit de nombreuses fonctionnalités pour la supervision continue des modèles. Pour obtenir la liste complète de cette fonctionnalité, consultez Fonctionnalités de la surveillance des modèles. Dans de nombreux cas, vous devez configurer la supervision de modèle qui prend en charge les tâches de supervision avancées. La section suivante fournit quelques exemples de surveillance avancée :
- Utilisation de plusieurs signaux de surveillance pour une vue générale
- Utilisation de données d’apprentissage de modèle historique ou de données de validation comme ressource de données de référence de comparaison
- Surveillance des fonctionnalités N les plus importantes et des fonctionnalités individuelles
Configurer l’importance d’une caractéristique
L’importance des caractéristiques représente l’importance relative de chaque caractéristique entrée dans la sortie d’un modèle. Par exemple, la température peut être plus importante pour la prédiction d’un modèle que l’élévation. Lorsque vous activez l'importance des caractéristiques, vous pouvez fournir une visibilité sur les caractéristiques dont vous souhaitez éviter la dérive ou les problèmes de qualité des données en production.
Pour activer l’importance des caractéristiques pour l’un de vos signaux, tels que la dérive des données ou la qualité des données, vous devez fournir :
- Votre ressource de données d’apprentissage en tant que ressource de
reference_datadonnées. - Propriété
reference_data.data_column_names.target_column, qui est le nom de la colonne de sortie de votre modèle ou colonne de prédiction.
Une fois que vous avez activé l’importance des fonctionnalités, vous voyez une importance de fonctionnalité pour chaque fonctionnalité que vous surveillez dans Azure Machine Learning Studio.
Vous pouvez activer ou désactiver les alertes pour chaque signal en définissant la alert_enabled propriété lorsque vous utilisez le Kit de développement logiciel (SDK) Python ou Azure CLI.
Vous pouvez utiliser Azure CLI, le Kit de développement logiciel (SDK) Python ou studio pour configurer la surveillance avancée des modèles.
Créez une définition de surveillance dans un fichier YAML. Pour obtenir un exemple de définition avancée, consultez le code YAML suivant, qui est également disponible dans le référentiel azureml-examples.
Avant d’utiliser cette définition, ajustez les paramètres suivants et tous les autres pour répondre aux besoins de votre environnement :
- Pour
endpoint_deployment_id, utilisez une valeur au formatazureml:<endpoint-name>:<deployment-name>. - Pour les sections de données d’entrée de référence
path, utilisez une valeur au formatazureml:<reference-data-asset-name>:<version>. - Pour
target_column, utilisez le nom de la colonne de sortie qui contient des valeurs prédites par le modèle, telles queDEFAULT_NEXT_MONTH. - Pour
features, répertoriez les fonctionnalités telles queSEX,EDUCATIONetAGEque vous souhaitez utiliser dans un signal de qualité des données avancée. - Indiquez les adresses e-mail sous
emailsque vous souhaitez utiliser pour les notifications.
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com- Pour
Exécutez la commande suivante pour créer le modèle :
az ml schedule create -f ./advanced-model-monitoring.yaml






Configurer le monitoring des performances
Lorsque vous utilisez la surveillance des modèles Azure Machine Learning, vous pouvez suivre les performances de vos modèles en production en calculant leurs métriques de performances. Les métriques de performances des modèles suivantes sont actuellement prises en charge :
- Pour les modèles de classification :
- Précision
- Exactitude
- Rappel
- Pour les modèles de régression :
- Erreur absolue moyenne (MAE)
- Erreur carrée moyenne (MSE)
- Racine carrée de l’erreur quadratique moyenne (RMSE)
Conditions préalables à l’analyse des performances du modèle
Données de sortie pour le modèle de production (prédictions du modèle) avec un ID unique pour chaque ligne. Si vous utilisez le collecteur de données Azure Machine Learning pour collecter des données de production, un ID de corrélation est fourni pour chaque demande d’inférence pour vous. Le collecteur de données offre également la possibilité de journaliser votre propre ID unique à partir de votre application.
Remarque
Pour la surveillance des performances des modèles Azure Machine Learning, nous vous recommandons d’utiliser le collecteur de données Azure Machine Learning pour consigner votre ID unique dans sa propre colonne.
Données de vérité de base (réelles) avec un ID unique pour chaque ligne. L’ID unique d’une ligne donnée doit correspondre à l’ID unique pour les données de sortie du modèle pour cette demande d’inférence particulière. Cet ID unique est utilisé pour joindre votre ressource de données de vérité au sol avec les données de sortie du modèle.
Si vous n’avez pas de données de vérité de base, vous ne pouvez pas effectuer d’analyse des performances de modèle. Les données de vérité de base sont rencontrées au niveau de l’application. Il vous incombe donc de les collecter dès qu’elles sont disponibles. Il est également recommandé de conserver une ressource de données dans Azure Machine Learning contenant ces données réelles.
(Facultatif) Une ressource de données tabulaire pré-jointe avec des données de sortie de modèle et des données de vérité au sol déjà jointes.
Conditions requises pour l’analyse des performances du modèle lorsque vous utilisez le collecteur de données
Azure Machine Learning génère un ID de corrélation pour vous lorsque vous remplissez les critères suivants :
- Vous utilisez le collecteur de données Azure Machine Learning pour collecter des données d’inférence de production.
- Vous ne fournissez pas votre propre ID unique pour chaque ligne en tant que colonne distincte.
L’ID de corrélation généré est inclus dans l’objet JSON journalisé. Toutefois, le collecteur de données regroupe les lignes qui sont envoyées dans des intervalles de temps courts et proches les uns des autres. Les lignes par lots se trouvent dans le même objet JSON. Dans chaque objet, toutes les lignes ont le même ID de corrélation.
Pour différencier les lignes d’un objet JSON, la surveillance des performances du modèle Azure Machine Learning utilise l’indexation pour déterminer l’ordre des lignes dans l’objet. Par exemple, si un lot contient trois lignes et que l’ID de corrélation est test, la première ligne a un ID test_0, la deuxième ligne a un ID de test_1, et la troisième ligne a un ID de test_2. Pour faire correspondre vos ID uniques de ressource de données de base avec les ID de vos données de sortie de modèle d’inférence de production collectées, appliquez un index à chaque ID de corrélation de manière appropriée. Si votre objet JSON journalisé n’a qu’une seule ligne, utilisez correlationid_0 comme valeur correlationid.
Pour éviter d’utiliser cette indexation, nous vous recommandons de consigner votre ID unique dans sa propre colonne. Mettez cette colonne dans la trame de données pandas que le collecteur de données Azure Machine Learning enregistre. Dans votre configuration de surveillance de modèle, vous pouvez ensuite spécifier le nom de cette colonne pour joindre vos données de sortie de modèle à vos données de vérité au sol. Tant que les ID de chaque ligne dans les deux ensembles de données sont identiques, la surveillance des modèles d'Azure Machine Learning peut surveiller les performances des modèles.
Exemple de workflow pour le monitoring des performances des modèles
Pour comprendre les concepts associés à l’analyse des performances du modèle, considérez l’exemple de flux de travail suivant. Il s’applique à un scénario dans lequel vous déployez un modèle pour prédire si les transactions de carte de crédit sont frauduleuses :
- Configurez votre déploiement pour collecter les données d’inférence de production du modèle (données d’entrée et de sortie) à l’aide du collecteur de données. Stockez les données de sortie dans une colonne appelée
is_fraud. - Pour chaque ligne des données d’inférence collectées, journalisez un ID unique. L’ID unique peut provenir de votre application, ou vous pouvez utiliser la
correlationidvaleur générée de manière unique par Azure Machine Learning pour chaque objet JSON journalisé. - Lorsque les données de vérité au sol (ou réelles)
is_fraudsont disponibles, journalisent et mappent chaque ligne au même ID unique enregistré pour la ligne correspondante dans les données de sortie du modèle. - Inscrivez une ressource de données dans Azure Machine Learning et utilisez-la pour collecter et maintenir les données de vérité
is_fraudau sol. - Créez un signal de monitoring des performances du modèle qui utiliser l’identifiant unique des colonnes pour joindre les ressources d’inférence de production et de données réelles du modèle.
- Calculez les métriques de performances du modèle.
Une fois que vous avez satisfait les conditions préalables à l’analyse des performances du modèle, procédez comme suit pour configurer la surveillance des modèles :
Créez une définition de surveillance dans un fichier YAML. L’exemple de spécification suivant définit la surveillance des modèles avec des données d’inférence de production. Avant d’utiliser cette définition, ajustez les paramètres suivants et tous les autres pour répondre aux besoins de votre environnement :
- Pour
endpoint_deployment_id, utilisez une valeur au formatazureml:<endpoint-name>:<deployment-name>. - Pour chaque
pathvaleur d’une section de données d’entrée, utilisez une valeur au formatazureml:<data-asset-name>:<version>. - Pour la
predictionvaleur, utilisez le nom de la colonne de sortie qui contient des valeurs prédites par le modèle. - Pour la
actualvaleur, utilisez le nom de la colonne de vérité au sol qui contient les valeurs réelles que le modèle tente de prédire. - Pour les
correlation_idvaleurs, utilisez les noms des colonnes utilisées pour joindre les données de sortie et les données de vérité au sol. - Sous
emails, répertoriez les adresses e-mail que vous souhaitez utiliser pour les notifications.
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- Pour
Exécutez la commande suivante pour créer le modèle :
az ml schedule create -f ./model-performance-monitoring.yaml





Configurer la surveillance des modèles des données de production
Vous pouvez également surveiller les modèles que vous déployez sur des points de terminaison de lot Azure Machine Learning ou que vous déployez en dehors d’Azure Machine Learning. Si vous n’avez pas de déploiement, mais que vous avez des données de production, vous pouvez utiliser les données pour effectuer une surveillance continue des modèles. Pour surveiller ces modèles, vous devez pouvoir :
- Collecter les données d’inférence de production des modèles déployés en production.
- Inscrire les données d’inférence de production en tant que ressource de données Azure Machine Learning et garantir des mises à jour continues des données.
- Fournissez un composant de prétraitement des données personnalisé et inscrivez-le en tant que composant Azure Machine Learning si vous n’utilisez pas le collecteur de données pour collecter des données. Sans ce composant de prétraitement des données personnalisé, le système de surveillance de modèle Azure Machine Learning ne peut pas traiter vos données dans un formulaire tabulaire qui prend en charge le fenêtrage temporel.
Votre composant de prétraitement personnalisé doit avoir les signatures d’entrée et de sortie suivantes :
| Entrée ou sortie | Nom de la signature | Catégorie | Descriptif | Exemple de valeur |
|---|---|---|---|---|
| saisie | data_window_start |
littéral, chaîne | Heure de début de la fenêtre de données au format ISO8601 | 2023-05-01T04:31:57.012Z |
| saisie | data_window_end |
littéral, chaîne | Heure de fin de la fenêtre de données au format ISO8601 | 2023-05-01T04:31:57.012Z |
| saisie | input_data |
uri_folder | Données d’inférence de production collectées, inscrites en tant que ressource de données Azure Machine Learning | azureml:myproduction_inference_data:1 |
| résultat | preprocessed_data |
mltable | Ressource de données tabulaire qui correspond à un sous-ensemble du schéma de données de référence |
Pour obtenir un exemple de composant de prétraitement de données personnalisé, consultez custom_preprocessing dans le dépôt GitHub azuremml-examples.
Pour obtenir des instructions sur l’inscription d’un composant Azure Machine Learning, consultez Inscrire un composant dans votre espace de travail.
Après avoir inscrit vos données de production et votre composant de prétraitement, vous pouvez configurer la surveillance des modèles.
Créez un fichier YAML de définition de surveillance similaire à celui qui suit. Avant d’utiliser cette définition, ajustez les paramètres suivants et tous les autres pour répondre aux besoins de votre environnement :
- Pour
endpoint_deployment_id, utilisez une valeur au formatazureml:<endpoint-name>:<deployment-name>. - Pour
pre_processing_component, utilisez une valeur au formatazureml:<component-name>:<component-version>. Spécifiez la version exacte, telle que1.0.0, et non1. - Pour chaque
path, utilisez une valeur au formatazureml:<data-asset-name>:<version>. - Pour la
target_columnvaleur, utilisez le nom de la colonne de sortie qui contient des valeurs prédites par le modèle. - Sous
emails, inscrivez les adresses e-mail que vous souhaitez utiliser pour les notifications.
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com- Pour
Exécutez la commande suivante pour créer le modèle.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Configurer la surveillance du modèle avec des signaux et des indicateurs de performance personnalisés
Lorsque vous utilisez la surveillance du modèle Azure Machine Learning, vous pouvez définir un signal personnalisé et implémenter n’importe quelle métrique de votre choix pour surveiller votre modèle. Vous pouvez inscrire votre signal personnalisé en tant que composant Azure Machine Learning. Lorsque votre travail de surveillance de modèle s’exécute selon sa planification spécifiée, il calcule les métriques définies dans votre signal personnalisé, tout comme pour la dérive des données, la dérive de prédiction et les signaux prédéfinis de qualité des données.
Pour configurer un signal personnalisé à utiliser pour la surveillance des modèles, vous devez d’abord définir le signal personnalisé et l’inscrire en tant que composant Azure Machine Learning. Le composant Azure Machine Learning doit avoir les signatures d’entrée et de sortie suivantes.
Signature d'entrée de composant
La trame de données d’entrée du composant doit contenir les éléments suivants :
- Structure
mltablequi contient les données traitées du composant de prétraitement. - Des littéraux, chacun représentant une métrique implémentée dans le cadre du composant de signal personnalisé. Par exemple, si vous implémentez la
std_deviationmétrique, vous avez besoin d’une entrée pourstd_deviation_threshold. En règle générale, il doit y avoir une entrée avec le nom<metric-name>_thresholdpar métrique.
| Nom de la signature | Catégorie | Descriptif | Exemple de valeur |
|---|---|---|---|
production_data |
mltable | Ressource de données tabulaire qui correspond à un sous-ensemble du schéma de données de référence | |
std_deviation_threshold |
littéral, chaîne | Seuil respectif de la métrique implémentée | 2 |
Signature de sortie du composant
Le port de sortie du composant doit avoir la signature suivante :
| Nom de la signature | Catégorie | Descriptif |
|---|---|---|
signal_metrics |
mltable | Structure mltable qui contient les métriques calculées. Pour le schéma de cette signature, consultez la section suivante signal_metrics schema. |
schéma signal_metrics
La trame de données de sortie du composant doit contenir quatre colonnes : group, , metric_namemetric_value, et threshold_value.
| Nom de la signature | Catégorie | Descriptif | Exemple de valeur |
|---|---|---|---|
group |
littéral, chaîne | Regroupement logique de niveau supérieur à appliquer à la métrique personnalisée | Montant de la transaction |
metric_name |
littéral, chaîne | Nom de la métrique personnalisée | std_deviation |
metric_value |
numérique | Valeur de la métrique personnalisée | 44 896,082 |
threshold_value |
numérique | Le seuil de la métrique personnalisée | 2 |
Le tableau suivant montre un exemple de sortie à partir d’un composant de signal personnalisé qui calcule la std_deviation métrique :
| groupe | valeur_métrique | metric_name | threshold_value |
|---|---|---|---|
| MONTANT DE LA TRANSACTION | 44 896,082 | std_deviation | 2 |
| Heure Locale | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54 004,902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
Pour voir un exemple de définition de composant de signal personnalisé et de code de calcul de métrique, consultez custom_signal dans le référentiel azureml-examples.
Pour obtenir des instructions sur l’inscription d’un composant Azure Machine Learning, consultez Inscrire un composant dans votre espace de travail.
Après avoir créé et inscrit votre composant de signal personnalisé dans Azure Machine Learning, procédez comme suit pour configurer la surveillance des modèles :
Créez une définition de surveillance dans un fichier YAML similaire à celui-ci. Avant d’utiliser cette définition, ajustez les paramètres suivants et tous les autres pour répondre aux besoins de votre environnement :
- Pour
component_id, utilisez une valeur au formatazureml:<custom-signal-name>:1.0.0. - Dans
pathla section données d’entrée, utilisez une valeur au formatazureml:<production-data-asset-name>:<version>. - Pour
pre_processing_component:- Si vous utilisez le collecteur de données pour collecter vos données, vous pouvez omettre la
pre_processing_componentpropriété. - Si vous n’utilisez pas le collecteur de données et que vous souhaitez utiliser un composant pour prétraiter les données de production, utilisez une valeur au format
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>.
- Si vous utilisez le collecteur de données pour collecter vos données, vous pouvez omettre la
- Sous
emails, répertoriez les adresses e-mail que vous souhaitez utiliser pour les notifications.
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- Pour
Exécutez la commande suivante pour créer le modèle :
az ml schedule create -f ./custom-monitoring.yaml
Interpréter les résultats de la surveillance
Une fois que vous avez configuré votre moniteur de modèle et que la première exécution s’est terminée, vous pouvez afficher les résultats dans Azure Machine Learning Studio.
Dans le studio, sous Gérer, sélectionnez Supervision. Dans la page Surveillance, sélectionnez le nom de votre moniteur de modèle pour afficher sa page de vue d’ensemble. Cette page affiche le modèle de surveillance, le point de terminaison et le déploiement. Il fournit également des informations détaillées sur les signaux configurés. L’image suivante montre une page de vue d’ensemble de la surveillance qui inclut la dérive des données et les signaux de qualité des données.
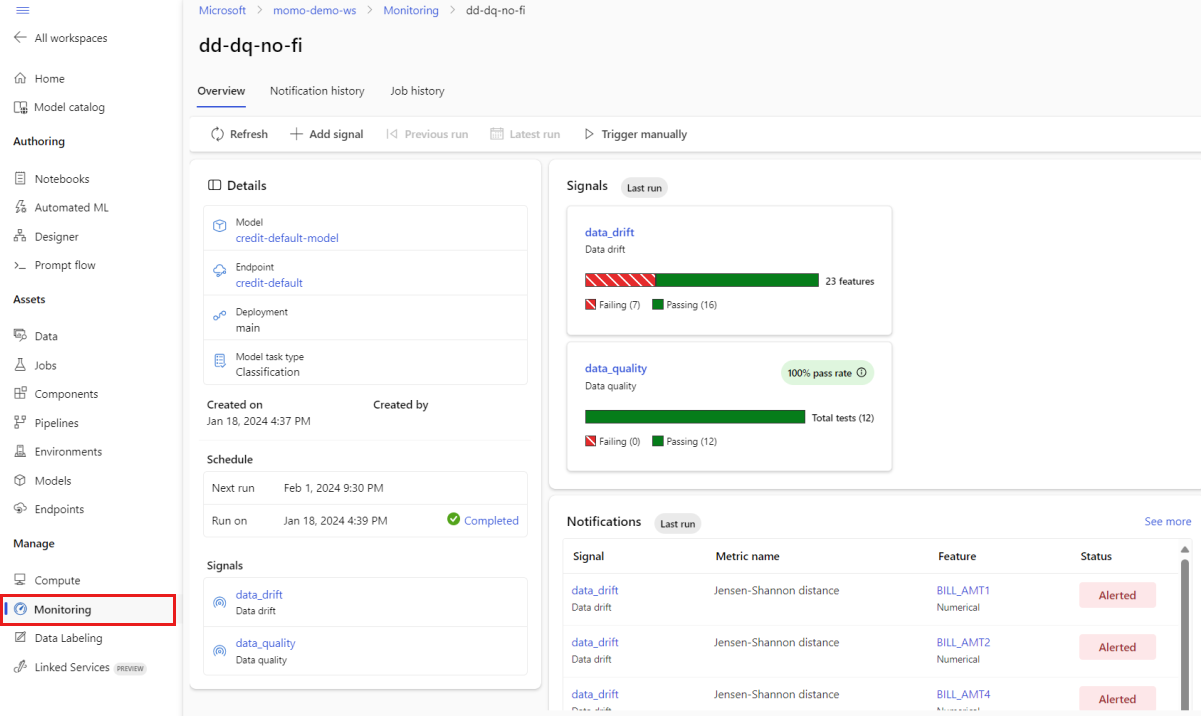
Consultez la section Notifications de la page de vue d’ensemble. Dans cette section, vous pouvez voir la fonctionnalité de chaque signal qui enfreint le seuil configuré pour sa métrique respective.
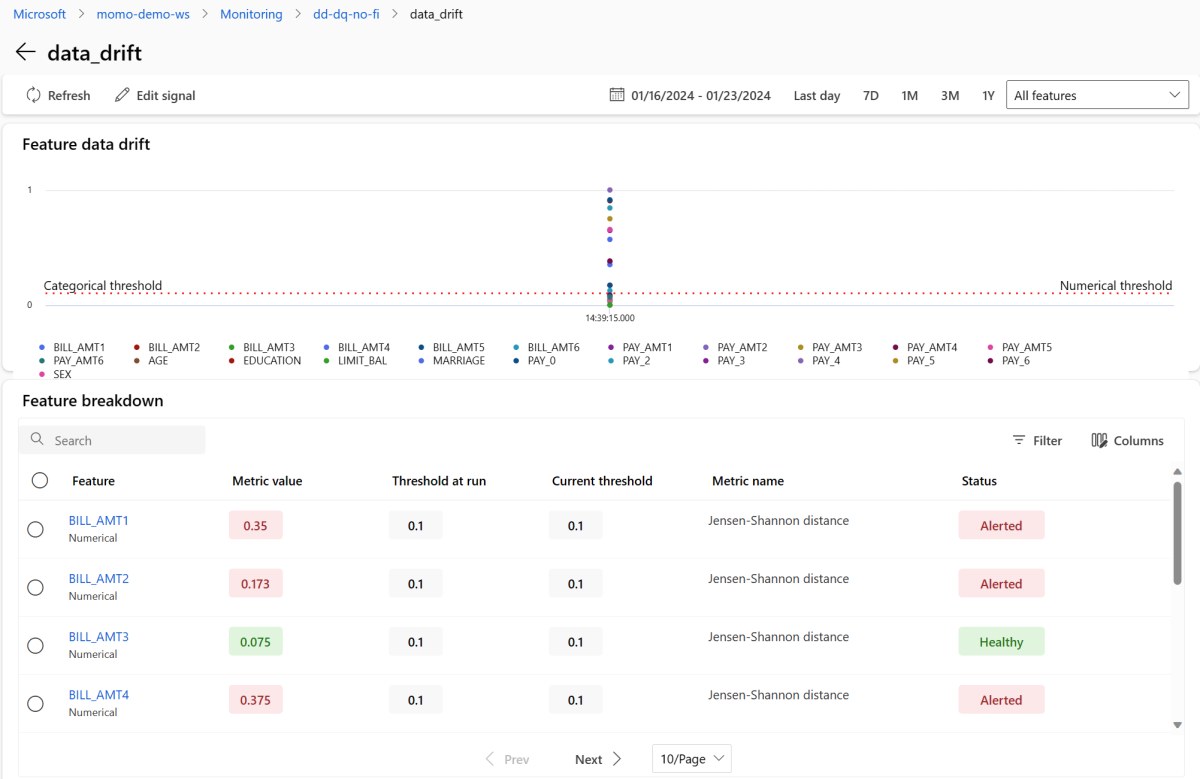
Dans la section Signaux , sélectionnez data_drift pour afficher des informations détaillées sur le signal de dérive de données. Dans la page d’informations, vous pouvez voir la valeur de métrique de dérive de données pour chaque fonctionnalité numérique et catégorielle incluse dans votre configuration de supervision. Si votre moniteur a plusieurs exécutions, vous voyez une courbe de tendance pour chaque fonctionnalité.
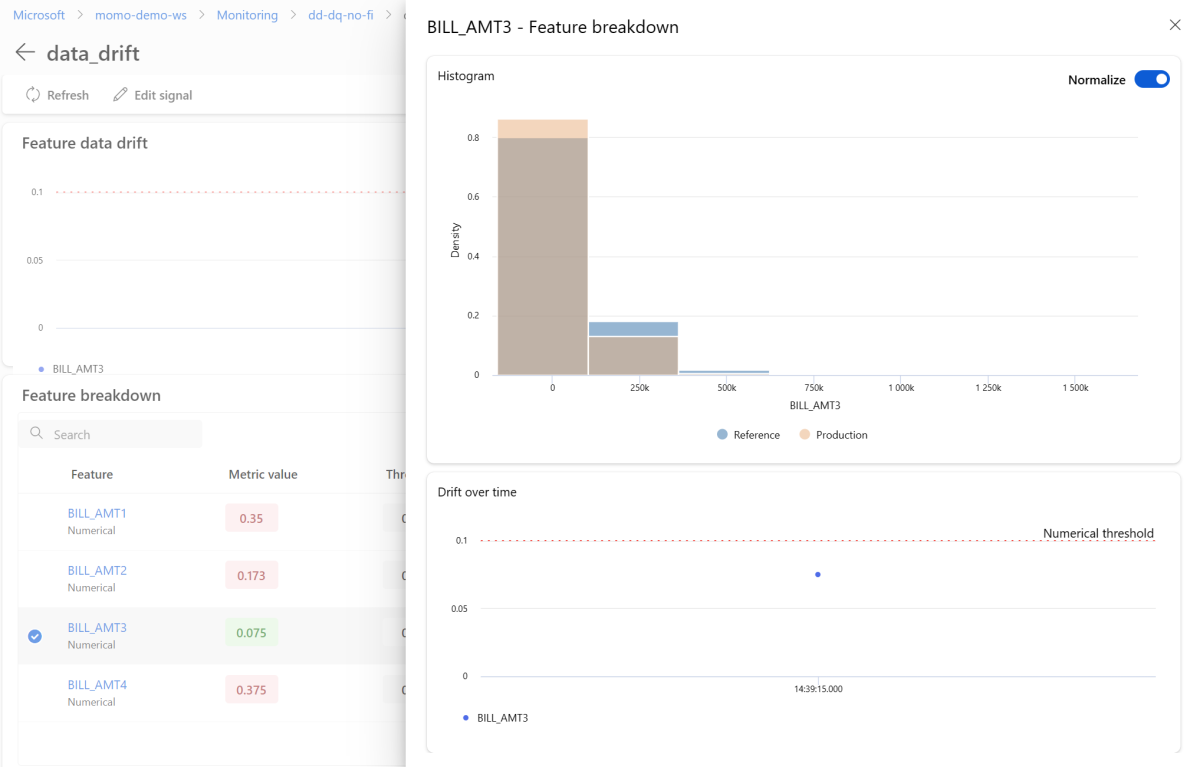
Dans la page de détails, sélectionnez le nom d’une fonctionnalité individuelle. Une vue détaillée s’ouvre pour afficher la distribution de production par rapport à la distribution de référence. Vous pouvez également utiliser cette vue pour suivre la dérive au fil du temps pour la fonctionnalité.
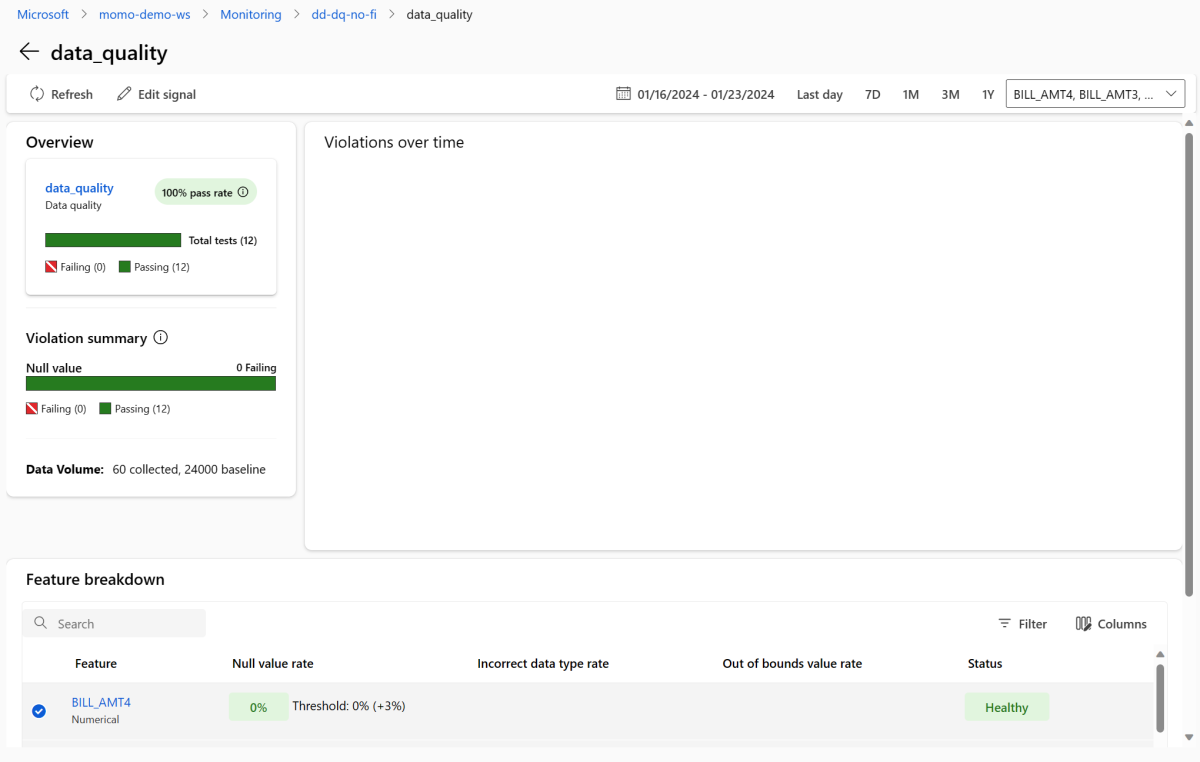
Revenez à la page vue d’ensemble de la surveillance. Dans la section Signaux , sélectionnez data_quality pour afficher des informations détaillées sur ce signal. Sur cette page, vous pouvez voir les taux de valeurs nulles, les taux d'erreur hors limites et les taux d'erreur de type de données pour chaque caractéristique que vous surveillez.




La surveillance des modèles est un processus continu. Lorsque vous utilisez la surveillance des modèles Azure Machine Learning, vous pouvez configurer plusieurs signaux de surveillance pour obtenir une vue générale des performances de vos modèles en production.
Intégrer la surveillance des modèles Azure Machine Learning à Event Grid
Lorsque vous utilisez Event Grid, vous pouvez configurer des événements générés par la surveillance du modèle Azure Machine Learning pour déclencher des applications, des processus et des flux de travail CI/CD. Vous pouvez utiliser des événements via différents gestionnaires d’événements, tels qu’Azure Event Hubs, Azure Functions et Azure Logic Apps. Lorsque vos moniteurs détectent la dérive, vous pouvez prendre des mesures par programme, par exemple en exécutant un pipeline Machine Learning pour réentraîner un modèle et le redéployer.
Pour intégrer la surveillance des modèles Azure Machine Learning à Event Grid, procédez comme suit.
Créer une rubrique système
Si vous n’avez pas de rubrique système Event Grid à utiliser pour la surveillance, créez-en une. Pour obtenir des instructions, consultez Créer, afficher et gérer des rubriques système Event Grid dans le portail Azure.
Créer un abonnement d’événement
Dans le portail Azure, accédez à votre espace de travail Azure Machine Learning.
Sélectionnez Événements, puis Abonnement à l’événement.
En regard de Name, entrez un nom pour votre abonnement aux événements, tel que MonitoringEvent.
Sous Types d’événements, sélectionnez uniquement l’état d’exécution modifié.
Avertissement
Sélectionnez uniquement changement de statut d'exécution pour le type d’événement. Ne sélectionnez pas Dérivation du jeu de données détectée, qui s’applique à la dérive de données v1, mais pas à la surveillance du modèle Azure Machine Learning.
Sélectionnez l’onglet Filtres . Sous Filtres avancés, sélectionnez Ajouter un nouveau filtre, puis entrez les valeurs suivantes :
- Sous Clé, entrez des données.RunTags.azureml_modelmonitor_threshold_breached.
- Sous Opérateur, sélectionnez Chaîne contient.
- Sous Valeur, l’entrée a échoué en raison d’une ou de plusieurs fonctionnalités qui ne respectent pas les seuils de métrique.

Lorsque vous utilisez ce filtre, les événements sont générés lorsque l’état d’exécution d’un moniteur dans votre espace de travail Azure Machine Learning change. L’état de l’exécution peut passer de l’état terminé à l’échec ou de l’échec de l’exécution.
Pour filtrer au niveau de l’analyse, sélectionnez à nouveau ajouter un nouveau filtre , puis entrez les valeurs suivantes :
- Sous Clé, entrez des données.RunTags.azureml_modelmonitor_threshold_breached.
- Sous Opérateur, sélectionnez Chaîne contient.
- Sous Valeur, entrez le nom d’un signal de surveillance pour lequel vous souhaitez filtrer les événements, tels que credit_card_fraud_monitor_data_drift. Le nom que vous entrez doit correspondre au nom de votre signal de surveillance. Tout signal que vous utilisez dans le filtrage doit avoir un nom au format
<monitor-name>_<signal-description>qui inclut le nom du moniteur et une description du signal.
Sélectionnez l’onglet Informations de base . Configurez le point de terminaison que vous souhaitez servir de gestionnaire d’événements, comme Event Hubs.
Sélectionnez Créer pour créer l’abonnement aux événements.

Afficher les événements
Après avoir capturé des événements, vous pouvez les afficher sur la page de point de terminaison du gestionnaire d’événements :

Vous pouvez également voir les événements sous l’onglet Métriques dans Azure Monitor :
