Déployer des modèles pour scoring dans des points de terminaison par lots
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Les points de terminaison de traitement par lots offrent un moyen pratique de déployer des modèles qui exécutent l’inférence sur de grands volumes de données. Ces points de terminaison simplifient le processus d’hébergement de vos modèles pour le scoring par lots. Ainsi, vous pouvez vous concentrer sur le Machine Learning plutôt que sur l’infrastructure.
Utilisez des points de terminaison de traitement par lots pour le déploiement de modèles dans les cas suivants :
- Vous disposez de modèles coûteux qui nécessitent plus de temps pour exécuter l’inférence.
- Vous devez effectuer une inférence sur de grandes quantités de données distribuées dans plusieurs fichiers.
- Vous n’avez pas d’exigences de faible latence.
- Vous pouvez tirer parti de la parallélisation.
Dans cet article, vous utilisez un point de terminaison de traitement par lots pour déployer un modèle Machine Learning qui résout le problème classique de reconnaissance des chiffres du MNIST (Modified National Institute of Standards and Technology). Votre modèle déployé effectue ensuite une inférence par lots sur de grandes quantités de données, dans le cas présent, des fichiers image. Vous commencez par créer un déploiement par lots d’un modèle conçu à l’aide de Torch. Ce déploiement devient le déploiement par défaut du point de terminaison. Plus tard, vous allez créer un deuxième déploiement d’un modèle conçu avec TensorFlow (Keras), tester le deuxième déploiement, puis le définir en tant que déploiement par défaut du point de terminaison.
Pour accéder aux exemples de code et aux fichiers nécessaires à l’exécution locale des commandes de cet article, consultez la section Cloner le référentiel d’exemples. Les exemples de code et les fichiers sont contenus dans le référentiel azureml-examples.
Prérequis
Pour pouvoir suivre les étapes décrites dans cet article, vérifiez que vous disposez des prérequis suivants :
Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning.
Un espace de travail Azure Machine Learning. Si vous n’en avez pas, suivez les étapes décrites dans l’article Comment gérer des espaces de travail pour en créer un.
Pour effectuer les tâches suivantes, vérifiez que vous disposez des autorisations suivantes dans l’espace de travail :
Pour créer/gérer des points de terminaison et des déploiements par lots : utilisez un rôle de propriétaire, un rôle de contributeur ou un rôle personnalisé autorisant
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Pour créer des déploiements ARM dans le groupe de ressources de l’espace de travail : utilisez un rôle de propriétaire, un rôle de contributeur ou un rôle personnalisé autorisant
Microsoft.Resources/deployments/writedans le groupe de ressources où l’espace de travail est déployé.
Vous devez installer les logiciels suivants pour utiliser Azure Machine Learning :
S’APPLIQUE À :
Extension Azure ML CLI v2 (actuelle)L’interface Azure CLI et l’
mlextension pour Azure Machine Learning.az extension add -n ml
Cloner le référentiel d’exemples
L’exemple de cet article est basé sur des extraits de code contenus dans le référentiel azureml-examples. Pour exécuter les commandes localement sans avoir à copier/coller le fichier YAML et d’autres fichiers, clonez d’abord le référentiel, puis modifiez les répertoires dans le dossier :
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Préparer votre système
Se connecter à un espace de travail
Connectez-vous d'abord à l'espace de travail Azure Machine Learning dans lequel vous allez travailler.
Si vous n’avez pas encore défini les paramètres par défaut pour l’interface CLI Azure, enregistrez vos paramètres par défaut. Pour éviter de passer les valeurs liées à votre abonnement, votre espace de travail, votre groupe de ressources et votre emplacement, exécutez ce code :
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Créer une capacité de calcul
Les points de terminaison de traitement par lots s’exécutent sur des clusters de calcul, et prennent en charge à la fois les clusters de calcul Azure Machine Learning (AmlCompute) et les clusters Kubernetes. Les clusters sont une ressource partagée. Un même cluster peut donc héberger un ou plusieurs déploiements par lots (avec d’autres charges de travail, le cas échéant).
Créez un calcul nommé batch-cluster, comme indiqué dans le code suivant. Vous pouvez effectuer des ajustements selon les besoins, et référencer votre calcul en utilisant azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Remarque
Le calcul ne vous est pas facturé à ce stade, car le cluster reste à 0 nœud jusqu’à ce qu’un point de terminaison de traitement par lots soit appelé, et qu’un travail de scoring par lots soit envoyé. Pour plus d’informations sur les coûts de calcul, consultez Gérer et optimiser les coûts pour AmlCompute.
Créer un point de terminaison de traitement de lots
Un point de terminaison de traitement par lots est un point de terminaison HTTPS que les clients peuvent appeler pour déclencher un travail de scoring par lots. Un travail de scoring par lots est un travail qui effectue le scoring de plusieurs entrées. Un déploiement par lots est un ensemble de ressources de calcul hébergeant le modèle qui effectue le scoring par lots (ou l’inférence par lots). Un point de terminaison de traitement de lots peut avoir plusieurs déploiements de lot. Pour plus d’informations sur les points de terminaison de traitement par lots, consultez Que sont les points de terminaison de traitement de lots ?.
Conseil
L’un des déploiements par lots sert de déploiement par défaut pour le point de terminaison. Quand le point de terminaison est appelé, le déploiement par défaut effectue le scoring par lots. Pour plus d’informations sur les points de terminaison de traitement par lots et les déploiements par lots, consultez Points de terminaison de traitement par lots et déploiement par lots.
Nommez le point de terminaison. Le nom du point de terminaison doit être unique au sein d’une région Azure, car le nom est inclus dans l’URI du point de terminaison. Par exemple, il ne peut y avoir qu’un seul point de terminaison de traitement par lots avec le nom
mybatchendpointdanswestus2.Configurer le point de terminaison de traitement par lots
Le fichier YAML suivant définit un point de terminaison de lot. Vous pouvez utiliser ce fichier avec la commande CLI pour la création du point de terminaison de traitement par lots.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningLe tableau suivant décrit les propriétés de clé du point de terminaison. Pour le schéma YAML du point de terminaison de lot complet, consultez la page Schéma YAML du point de terminaison de lot CLI (v2).
Clé Description nameNom du point de terminaison de lot. Doit être unique au niveau de la région Azure. descriptionDescription du point de terminaison de traitement par lots. Cette propriété est facultative. tagsBalises à inclure dans le point de terminaison. Cette propriété est facultative. Créez le point de terminaison :
Créer un déploiement par lots
Un déploiement de modèle est un ensemble de ressources nécessaires pour héberger le modèle qui effectue l’inférence réelle. Pour créer un déploiement de modèle par lots, vous avez besoin des éléments suivants :
- Un modèle inscrit dans l’espace de travail
- Le code permettant d’effectuer un scoring du modèle
- Un environnement dans lequel les dépendances du modèle sont installées
- Le calcul créé au préalable et les paramètres de ressource
Commencez par inscrire le modèle à déployer : un modèle Torch pour le célèbre problème de reconnaissance de chiffres (MNIST). Les déploiements par lots peuvent uniquement déployer des modèles inscrits dans l’espace de travail. Vous pouvez ignorer cette étape si le modèle à déployer est déjà inscrit.
Conseil
Les modèles sont associés au déploiement plutôt qu’au point de terminaison. Cela signifie qu’un même point de terminaison peut mettre à disposition différents modèles (ou différentes versions de modèle), à condition que les différents modèles (ou différentes versions de modèle) soient déployés dans des déploiements distincts.
Il est temps de créer un script de scoring. Les déploiements par lots nécessitent un script de scoring qui indique comment un modèle donné doit être exécuté et comment les données d’entrée doivent être traitées. Les points de terminaison de traitement par lots prennent en charge les scripts créés en Python. Dans le cas présent, vous déployez un modèle qui lit des fichiers image représentant des chiffres, et génère le chiffre correspondant. Le script de scoring se présente comme suit :
Notes
Pour les modèles MLflow, Azure Machine Learning génère automatiquement le script de scoring : vous n’êtes donc pas obligé d’en fournir un. Si votre modèle est un modèle MLflow, vous pouvez ignorer cette étape. Pour plus d’informations sur le fonctionnement des points de terminaison de traitement par lots avec les modèles MLflow, consultez l’article Utilisation de modèles MLflow dans les déploiements par lots.
Avertissement
Si vous déployez un modèle AutoML (Machine Learning automatisé) sous un point de terminaison de traitement par lots, notez que le script de scoring fourni par AutoML fonctionne uniquement pour les points de terminaison en ligne, et qu’il n’est pas conçu pour l’exécution par lots. Pour plus d’informations sur la création d’un script de scoring pour votre déploiement par lots, consultez Créer des scripts de scoring pour les déploiements par lots.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Créez un environnement dans lequel votre déploiement par lots s’exécutera. L’environnement doit inclure les packages
azureml-coreetazureml-dataset-runtime[fuse], nécessaires aux points de terminaison de traitement par lots ainsi que les dépendances nécessaires à l’exécution de votre code. Dans le cas présent, les dépendances ont été capturées dans un fichierconda.yaml:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Important
Les packages
azureml-coreetazureml-dataset-runtime[fuse]sont requis par les déploiements par lots et doivent être inclus dans les dépendances d’environnement.Spécifiez l’environnement de la façon suivante :
La définition d’environnement sera incluse dans la définition de déploiement elle-même en tant qu’environnement anonyme. Vous verrez dans les lignes suivantes du déploiement :
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlAvertissement
Les environnements organisés ne sont pas pris en charge dans les déploiements par lots. Vous devez spécifier votre propre environnement. Vous pouvez toujours utiliser l’image de base d’un environnement organisé comme la vôtre pour simplifier le processus.
Créer une nouvelle définition de déploiement
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoLe tableau suivant décrit les propriétés clés du déploiement par lots. Pour le schéma YAML complet du déploiement par lots, consultez la page Schéma YAML de déploiement par lots CLI (v2).
Clé Description nameLe nom du déploiement. endpoint_nameNom du point de terminaison sous lequel créer le déploiement. modelModèle à utiliser pour le scoring par lots. L’exemple définit un modèle inclus à l’aide de path. Cette définition permet de charger et d’inscrire automatiquement les fichiers de modèles avec un nom et une version générés automatiquement. Pour plus d’options, consultez le Schéma de modèle. En guise de meilleure pratique pour les scénarios de production, vous devez créer le modèle séparément et le référencer ici. Pour référencer un modèle existant, utilisez la syntaxeazureml:<model-name>:<model-version>.code_configuration.codeRépertoire local qui contient tout le code source Python de scoring du modèle. code_configuration.scoring_scriptFichier Python dans le répertoire code_configuration.code. Ce fichier doit avoir une fonctioninit()et une fonctionrun(). Utilisez la fonctioninit()pour toute préparation coûteuse ou courante (par exemple charger le modèle en mémoire).init()n’est appelé qu’une seule fois au début du processus. Utilisezrun(mini_batch)pour effectuer le scoring de chaque entrée. La valeur demini_batchest une liste de chemins de fichiers. La fonctionrun()doit retourner un dataframe pandas ou un tableau. Chaque élément retourné indique une exécution réussie d’un élément d’entrée dans lemini_batch. Pour plus d’informations sur la création d’un script de scoring, consultez Compréhension du script de scoring.environmentL’environnement pour évaluer le modèle. L’exemple définit un environnement inline à l’aide de conda_fileetimage. Les dépendancesconda_fileseront installées au-dessus deimage. L’environnement sera automatiquement inscrit avec un nom et une version générés automatiquement. Pour plus d’options, consultez le Schéma d’environnement. En guise de meilleure pratique pour les scénarios de production, vous devez créer l’environnement séparément et le référencer ici. Pour référencer un environnement existant, utilisez la syntaxeazureml:<environment-name>:<environment-version>.computeLe calcul pour exécuter le scoring par lots. L’exemple utilise le batch-clustercréé au début, et le référence à l’aide de la syntaxeazureml:<compute-name>.resources.instance_countNombre d’instances à utiliser pour chaque travail de scoring par lots. settings.max_concurrency_per_instance[Facultatif] Nombre maximal d’exécutions scoring_scriptparallèles par instance.settings.mini_batch_size[Facultatif] Nombre de fichiers qu’un scoring_scriptpeut traiter en un appelrun().settings.output_action[Facultatif] Mode d’organisation de la sortie dans le fichier de sortie. append_rowfusionne tous les résultats de sortierun()retournés dans un seul fichier nomméoutput_file_name.summary_onlyne fusionne pas les résultats de sortie, et calcule uniquementerror_threshold.settings.output_file_name[Facultatif] Nom du fichier de sortie de scoring par lots pour append_rowoutput_action.settings.retry_settings.max_retries[Facultatif] Nombre maximal de tentatives pour un échec d’un scoring_scriptrun().settings.retry_settings.timeout[Facultatif] Délai d’attente, en secondes, pour un scoring_scriptrun()de scoring d’un mini-lot.settings.error_threshold[Facultatif] Nombre d’échecs de scoring de fichier d’entrée qui doivent être ignorés. Si le nombre d’erreurs présentes dans la totalité de l’entrée dépasse cette valeur, le travail de scoring par lots va se terminer. L’exemple utilise -1, qui indique que tout nombre d’échecs est autorisé sans terminer le travail de scoring par lots.settings.logging_level[Facultatif] Niveau de détail des journaux. Les valeurs permettant d’augmenter le niveau de détail sont : WARNING, INFO et DEBUG. settings.environment_variables[Facultatif] Dictionnaire de paires nom-valeur de variable d’environnement à définir pour chaque tâche de scoring par lots. Créez le déploiement :
Exécutez le code suivant pour créer un déploiement par lots sous le point de terminaison de traitement par lots, et le définir en tant que déploiement par défaut.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultConseil
Le paramètre
--set-defaultdéfinit le déploiement nouvellement créé comme déploiement par défaut du point de terminaison. C’est un moyen pratique de créer un nouveau déploiement de point de terminaison par défaut, en particulier pour la première création d’un déploiement. Conformément aux meilleures pratiques dans les scénarios de production, vous pouvez être amené à créer un déploiement sans le définir en tant que déploiement par défaut. Vérifiez que le déploiement fonctionne comme prévu, puis mettez-le à jour plus tard en tant que déploiement par défaut. Pour plus d’informations sur l’implémentation de ce processus, consultez la section Déployer un nouveau modèle.Vérifiez les détails du point de terminaison de traitement par lots et du déploiement.

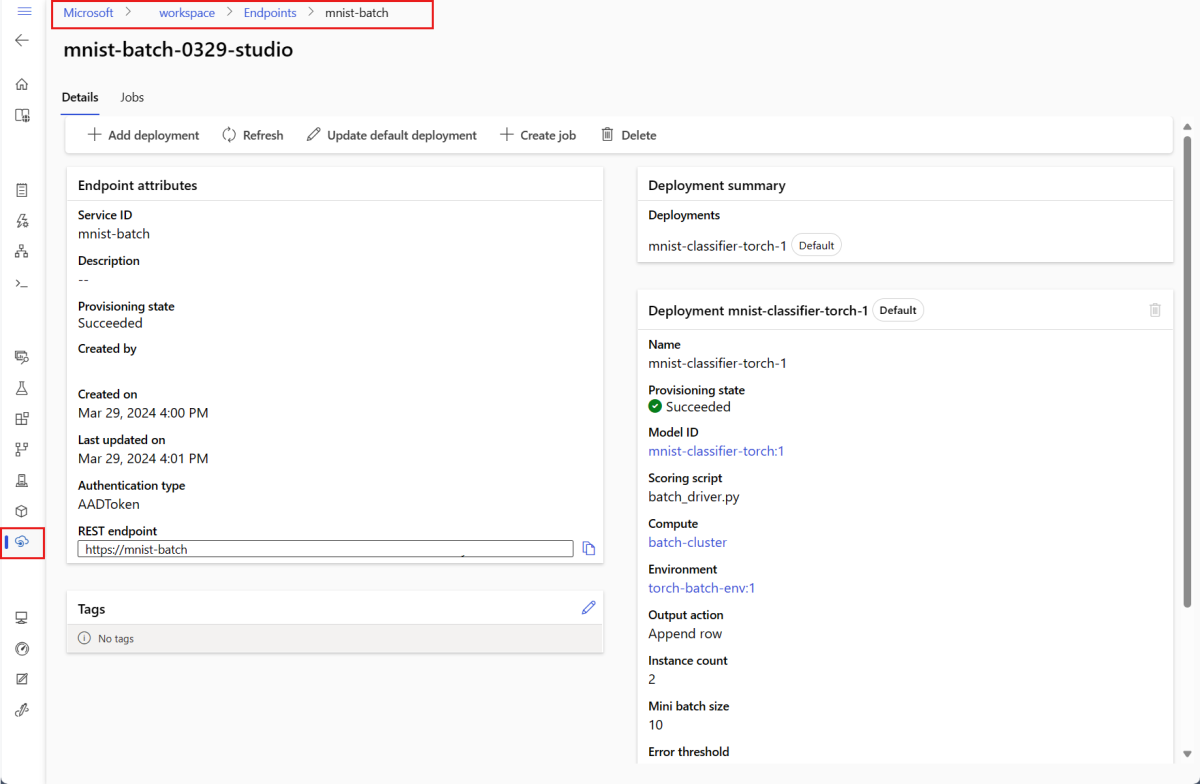
Exécuter des points de terminaison de lot et accéder aux résultats
L’appel d’un point de terminaison de lot déclenche un travail de scoring par lots. Le travail name est retourné à partir de la réponse à l’appel, et peut être utilisé pour suivre la progression du scoring par lots. Quand vous exécutez des modèles à des fins de scoring dans les points de terminaison de traitement par lots, vous devez spécifier le chemin d’accès des données d’entrée pour permettre aux points de terminaison de trouver les données devant faire l’objet d’un scoring. L’exemple suivant montre comment démarrer une nouvelle tâche sur un exemple de données du jeu de données MNIST stocké dans un compte de stockage Azure.
Vous pouvez exécuter et appeler un point de terminaison de traitement par lots à l’aide d’Azure CLI, du KIT de développement logiciel (SDK) Azure Machine Learning ou de points de terminaison REST. Pour plus d’informations sur ces options, consultez Créer des travaux et des données d’entrée pour les points de terminaison de lot.
Remarque
Comment fonctionne la parallélisation ?
Les déploiements par lots distribuent le travail au niveau des fichiers, ce qui signifie qu’un dossier contenant 100 fichiers avec des mini-lots de 10 fichiers génère 10 lots de 10 fichiers chacun. Notez que cela se produit quelle que soit la taille des fichiers impliqués. Si vos fichiers sont trop volumineux pour être traités dans de grands mini-lots, nous vous suggérons de les fractionner en fichiers plus petits pour atteindre un niveau de parallélisme plus élevé, ou de réduire le nombre de fichiers par mini-lot. Pour le moment, les déploiements par lots ne peuvent pas gérer les asymétries dans la distribution des tailles de fichier.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Les points de terminaison de traitement par lots prennent en charge la lecture de fichiers ou de dossiers situés à différents emplacements. Pour en savoir plus sur les types pris en charge et sur la façon de les spécifier, consultez Accès aux données à partir de travaux de points de terminaison de traitement par lots.
Monitorer la progression de l’exécution du travail par lots
Les travaux de scoring par lots prennent généralement un certain temps pour traiter l’ensemble des entrées.
Le code suivant vérifie l’état du travail et génère un lien vers Azure Machine Learning Studio pour plus d’informations.
az ml job show -n $JOB_NAME --web

Vérifier les résultats du scoring par lots
Les sorties du travail sont stockées dans le stockage cloud, soit dans l’instance par défaut du service Stockage Blob de l’espace de travail, soit dans le stockage que vous avez spécifié. Pour savoir comment changer les valeurs par défaut, consultez Configurer l’emplacement de sortie. Les étapes suivantes vous permettent de voir les résultats du scoring dans l’Explorateur Stockage Azure, une fois le travail effectué :
Exécutez le code suivant pour ouvrir le travail de scoring par lots dans Azure Machine Learning studio. Le lien Studio du travail est également inclus dans la réponse de
invoke, en tant que valeur deinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webDans le graphique du travail, sélectionnez l’étape
batchscoring.Sélectionnez l’onglet Sorties + journaux, puis sélectionnez Afficher les sorties de données.
À partir des Sorties de données, sélectionnez l’icône pour ouvrir l’Explorateur Stockage.

Les résultats du scoring dans l’Explorateur Stockage sont similaires à l’exemple de page suivant :



Configurer l’emplacement de sortie
Par défaut, les résultats de scoring par lots sont stockés dans le magasin d’objets blob par défaut de l’espace de travail, dans un dossier nommé en fonction du nom de travail (GUID généré par le système). Vous pouvez configurer l’emplacement où stocker les sorties de scoring lorsque vous appelez le point de terminaison de lot.
Utilisez output-path pour configurer n’importe quel dossier dans un magasin de données Azure Machine Learning inscrit. La syntaxe de --output-path est identique à celle de --input quand vous spécifiez un dossier, c’est-à-dire azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. Utilisez --set output_file_name=<your-file-name> pour configurer un nouveau nom de fichier de sortie.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Avertissement
Vous devez utiliser un emplacement de sortie unique. Si le fichier de sortie existe, le travail de scoring par lots échouera.
Important
Contrairement aux entrées, les sorties peuvent être stockées uniquement dans les magasins de données Azure Machine Learning qui s’exécutent sur des comptes Stockage Blob.
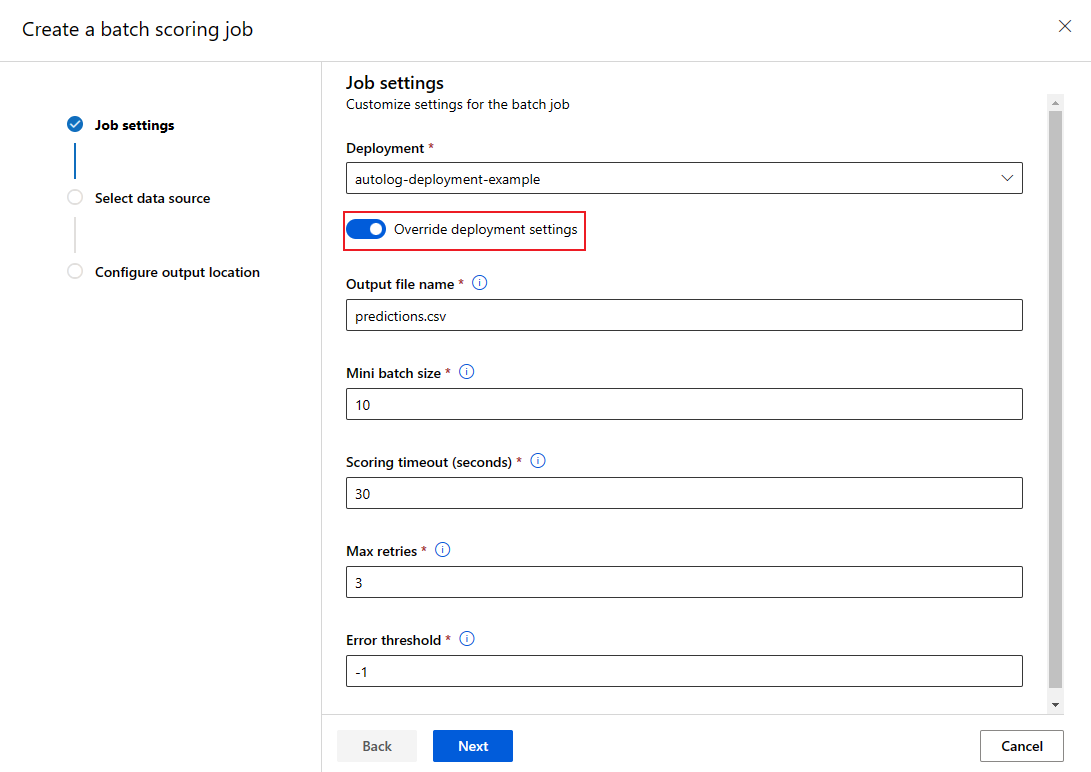
Remplacer la configuration de déploiement pour chaque travail
Quand vous appelez un point de terminaison de traitement par lots, vous pouvez remplacer certains paramètres pour optimiser l’utilisation des ressources de calcul et améliorer les performances. Les paramètres suivants peuvent être configurés en fonction du travail :
- Nombre d’instances : utilisez ce paramètre pour remplacer le nombre d’instances à demander au cluster de calcul. Par exemple, pour un plus grand volume d’entrées de données, vous souhaiterez peut-être utiliser plus d’instances pour accélérer le scoring par lots de bout en bout.
- Taille minimale de lot : utilisez ce paramètre pour remplacer le nombre de fichiers à inclure dans chaque mini-lot. Le nombre de mini-lots est déterminé en fonction du nombre total de fichiers d’entrée et de la taille du mini-lot. Une taille de mini-lot plus petite génère davantage de mini-lots. Les mini-lots peuvent être exécutés en parallèle, mais il peut y avoir des surcharges de planification et d’invocation supplémentaires.
- Les autres paramètres, par exemple le nombre maximal de nouvelles tentatives, le délai d’expiration et le seuil d’erreur peuvent être remplacés. Ces paramètres peuvent avoir un impact sur la durée du scoring par lots de bout en bout pour différentes charges de travail.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Ajouter des déploiements à un point de terminaison
Une fois que vous avez un point de terminaison de traitement par lots avec un déploiement, vous pouvez continuer à affiner votre modèle et ajouter de nouveaux déploiements. Les points de terminaison de traitement par lots continuent de servir le déploiement par défaut pendant que vous développez et déployez de nouveaux modèles sous le même point de terminaison. Les déploiements ne s’affectent pas les uns les autres.
Dans cet exemple, vous ajoutez un deuxième déploiement qui utilise un modèle créé avec Keras et TensorFlow pour résoudre le même problème MNIST.
Ajouter un deuxième déploiement
Créez un environnement dans lequel votre déploiement par lots s’exécutera. Incluez dans l’environnement toute dépendance dont votre code a besoin pour s’exécuter. Vous devez également ajouter la bibliothèque
azureml-core, car elle est nécessaire au bon fonctionnement des déploiements par lots. La définition d’environnement suivante contient les bibliothèques nécessaires pour exécuter un modèle avec TensorFlow.La définition d’environnement est incluse dans la définition de déploiement elle-même en tant qu’environnement anonyme.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlLe fichier conda utilisé se présente comme suit :
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Créez un script de scoring pour le modèle :
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Créer une nouvelle définition de déploiement
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvCréez le déploiement :
Exécutez le code suivant pour créer un déploiement par lots sous le point de terminaison de traitement par lots et le définir comme déploiement par défaut.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMEConseil
Le paramètre
--set-defaultest manquant dans ce cas. Conformément aux meilleures pratiques dans les scénarios de production, créez un déploiement sans le définir en tant que déploiement par défaut. Vérifiez-le ensuite, puis mettez-le à jour plus tard en tant que déploiement par défaut.
Tester un déploiement par lots autre que celui par défaut
Pour tester le nouveau déploiement non défini par défaut, vous devez connaître le nom du déploiement à exécuter.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Notez que --deployment-name est utilisé pour spécifier le déploiement à exécuter. Avec ce paramètre, vous pouvez invoke un déploiement non défini par défaut sans mettre à jour le déploiement par défaut du point de terminaison de traitement par lots.
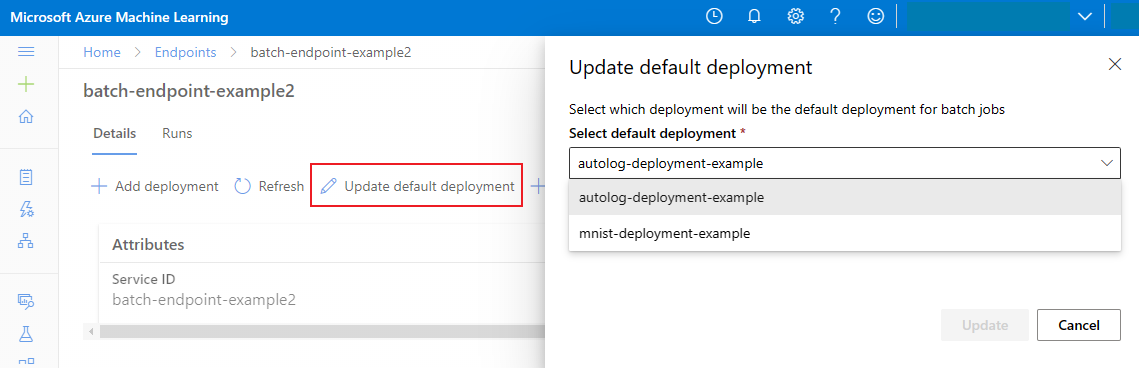
Mettre à jour le déploiement par lots par défaut
Bien que vous puissiez appeler un déploiement spécifique dans un point de terminaison, vous appelez généralement le point de terminaison lui-même, et le laissez décider du déploiement à utiliser, à savoir le déploiement par défaut. Vous pouvez changer le déploiement par défaut (et, ainsi, changer le modèle prenant en charge le déploiement) sans changer votre contrat avec l’utilisateur qui appelle le point de terminaison. Utilisez le code suivant pour mettre à jour le déploiement par défaut :
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Supprimez le point de terminaison de lot et le déploiement
Si vous n’utilisez pas l’ancien déploiement par lots, supprimez-le en exécutant le code suivant. Utilisez --yes pour confirmer la suppression.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Exécutez le code suivant pour supprimer le point de terminaison de traitement par lots et tous ses déploiements sous-jacents. Les travaux de scoring par lots ne seront pas supprimés.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes
Contenu connexe
- Accès aux données à partir de travaux de points de terminaison de traitement par lots.
- Authentification sur les points de terminaison de traitement par lots.
- Isolement réseau dans les points de terminaison de traitement par lots.
- Résolution des problèmes de points de terminaison de traitement par lots.